Spark的部署与使用_spark部署-程序员宅基地
1 相关概念
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.1 与Hadoop区别
Spark与Hadoop中的MapReduce相似,都是用于进行并行计算的框架,二者根本差异是多个作业之间的数据通信问题 : Spark 的多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘,因此Spark作为MapReduce的升级改进,计算速度会更快。MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景下效率较低,而spark可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。此外Spark 采用 fork 线程的方式启动Task,速度更快。
但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark并不能完全替代 MR。
1.2 组成结构
框架结构
从整体上看,Spark框架由如下几个主要组成部分

- Spark Core 中提供了 Spark 最基础与最核心的功能,其他的组成模块都是在 Spark Core 的基础上进行扩展的
- Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL或者 Apache Hive SQL 来查询数据。
- Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
- MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语
- GraphX 是 Spark 面向图计算提供的框架与算法库。
核心组件

Spark 框架的核心是一个计算引擎,从计算的角度,spark可以分为Driver和Executor
- Driver 是驱使整个应用运行起来的程序,也称之为Driver 类。负责将用户程序转化为作业(job),将任务分配调度给Executor执行,同时跟踪任务执行情况,并将结果通过UI实时反馈给用户。如果有 Executor 节点发生了故障或崩溃,Driver会将出错节点上的任务调度到其他 Executor 节点上继续运行。
- Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),并将结果返回给Driver。另一方面它通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储
Spark可以单独作为集群进行运行,因此从资源分配的角度,spark可以分为Master和Worker
- Master 主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 ResourceManager
- Worker 是数据计算和处理的单元,一个 Worker 运行在集群中的一台服务器上,类似于 Yarn 环境中 NodeManager
ApplicationMaster是任务计算和资源分配之间的连接器,负责向资源调度器申请执行任务的资源容器 Container,运行计算任务 job,监控整个任务的执行,处理任务失败等异常情况。
并行度(Parallelism)
并发是指在一段时间内多个任务同时存在,它们可能在交替执行;而并行是指在某一时刻多个任务在同时执行。由于分布式框架中任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,将整个集群并行执行任务的数量称之为并行度。
1.3 部署模式
Spark 应用程序提交到 Yarn 环境中执行的时候,一般会有两种部署执行的方式:Client和 Cluster。两种模式主要区别在于:Driver 程序的运行节点位置。
- Client 模式下将用于监控和调度的 Driver 模块在客户端执行,而不是在 Yarn 中,所以一般用于测试。
- Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。一般应用于实际生产环境。
Spark再Yarn上的运行不走如下所示
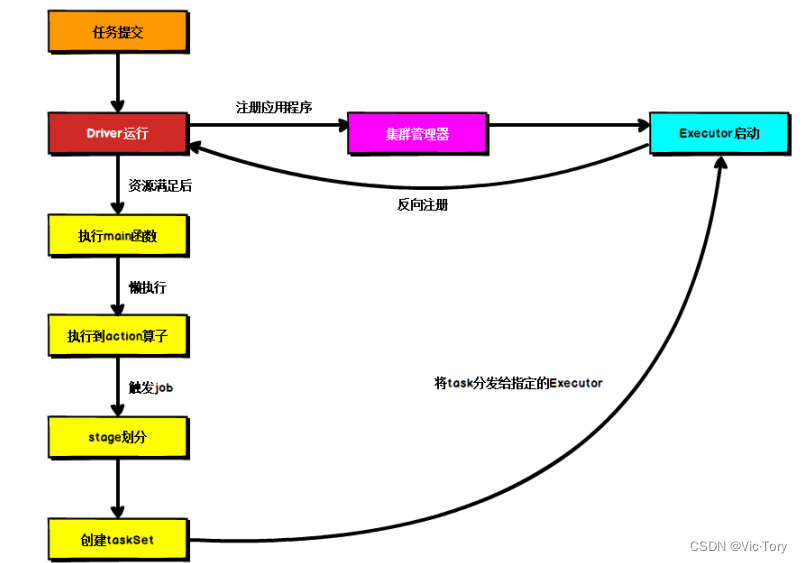
- 任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster,
- 随后 ResourceManager 调度一个 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是 Driver。
- Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动Executor 进程
- Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数,
- 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
1.4 WordCount
如下是一个经典的wordcount案例。
在Windows本地运行spark需要Hadoop客户端的支持,客户端环境配置如下
https://blog.csdn.net/theVicTory/article/details/124267672#t6
使用IDEA新建一个maven项目,在IDEA中添加Scala插件
在maven中引入spark插件,这里使用的是Scala版本2.12,spark版本3.0。详细信息可以查看Spark官网https://spark.apache.org/downloads.html
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
如下所示读取输入文件word.txt中的内容进行Map 、Reduce操作后将单词统计结果打印出来
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 创建 Spark 运行配置对象,在本地运行
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建 Spark 上下文环境对象(连接对象)
val sc: SparkContext = new SparkContext(sparkConf)
// 读取文件数据
val fileRDD: RDD[String] = sc.textFile("/input/word.txt")
// 将文件中的单词按照空格进行拆分
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
// 将单词转化为键值对 word => (word, 1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
// 将键值对按照相同的key值进行分组,然后将value值累加
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_ + _)
// 将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 打印结果
word2Count.foreach(println)
//关闭 Spark 连接
sc.stop()
}
}
2 运行模式
2.1 单节点模式
单节点Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于调试,演示等。
在spark官网选择和Hadoop、Scala版本相对应的安装包进行下载
将下载好的安装包解压到/opt/module目录,并在解压后的bin目录下启动spark shell脚本
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module/spark-3.0.0-bin-hadoop3.2
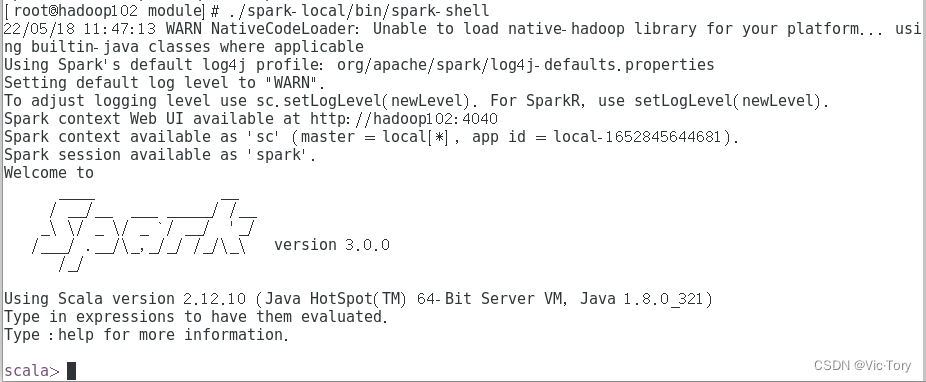
./bin/spark-shell
之后可以看到spark命令行启动,并且在4040端口可以看到UI交互界面
通过spark-submit提交jar包任务运行如下所示,其中--class指定执行程序的主类,--master指定部署模式,数字代表分配虚拟CPU核数
./bin/spark-submit /home/tory/wordcount.jar --class com.tory.spark.WordCount --master local[2]
2.2 独立集群模式
Spark独立组建集群模式(Standalone),即将应用提交到对应的集群中去执行。这里使用三台主机当作Worker,其中一台主机当作master来组建集群。
集群配置
将spark文件解压后先修改spark的节点配置文件,将conf/slaves.template重命名为slaves,然后在其中添加work节点的主机位置。这里的主机名已经作了IP映射,所以可以直接写主机名
hadoop102
hadoop103
hadoop104
之后修改spark环境配置文件,将conf/spark-env.sh.template 重命名为 spark-env.sh,并在文件末尾添加如下内容,设置Java路径、master节点和spark端口号。这里已经为每个节点安装好了Java环境,命令行通过echo $JAVA_HOME可以看到其安装路径。
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
通过sync命令将配置好的spark文件分发到其他节点。为了便于在节点之间进行文件同步,可以将该命令封装为一个脚本mysync,过程记录在:https://blog.csdn.net/theVicTory/article/details/124095680?spm=1001.2014.3001.5501#t10
mysync /opt/module/spark
启动集群
sbin/start-all.sh
在Master节点的8080端口可以看到集群运行情况
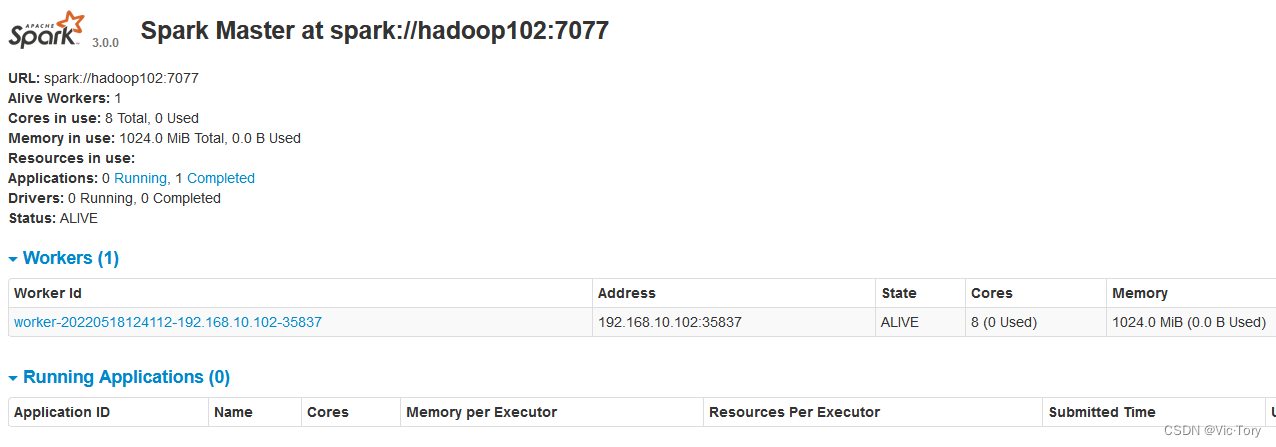
提交任务
通过spark-submit向集群提交任务。这里运行的是spark/examples目录下的样例文件spark-examples中的求PI任务SparkPi。通过参数--class指定任务的主类,通过--master指定任务提交到主机hadoop102的7077端口。最后10是程序入口参数。
bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://hadoop102:7077
./examples/jars/spark-examples_2.12-3.0.0.jar
10
提交任务时,还可以通过参数指定Executor 的内存大小和使用的虚拟 CPU 核(Core)数量
| 参数 | 说明 |
|---|---|
| –num-executors | 配置 Executor 的数量 |
| –executor-memory | 配置每个 Executor 的内存大小 |
| –executor-cores | 配置每个 Executor 的虚拟 CPU core 数量 |
历史服务
通过配置历史服务器可以记录任务运行情况
首先将spark/conf下的配置文件spark-defaults.conf.template修改为spark-defaults.conf,在其中开启日志服务并配置日志存储位置为hdfs文件系统的/directory目录(这里hdfs地址在hadoop102节点的8020端口),因此需要启动Hadoop集群并创建该目录
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory
之后在spark-env.sh文件中添加日志的配置,将UI端口设为18080,并设置日志位置,最后设置最大日志记录个数为30
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"
分发修改后的配置文件并重启集群
cd /opt/module/spark
mysync conf
sbin/stop-all.sh
sbin/start-all.sh
sbin/start-history-server.sh
此时,执行任务后就可以在18080端口看到历史日志了:http://hadoop102:18080/

Master备用节点
为了防止Master节点挂掉后集群异常,通过Zookeeper来配置备用Master节点来提高集群的可用性
首先停止spark集群并启动集群的zookeeper服务。
修改spark-env.sh,在其中首先注释掉之前spark master相关设置;修改WEBUI端口防止和zookeeper冲突;最后配置zookeeper高可用
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
# 修改监控页面默认访问端口,防止冲突,所以改成 8989
SPARK_MASTER_WEBUI_PORT=8989
# 配置Zookeeper高可用
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104
-Dspark.deploy.zookeeper.dir=/spark"
将上面的配置文件同步到其他几点。
在当前节点启动集群,则当前节点hadoop103就会被当作master
[tory@hadoop103 spark]$ sbin/start-all.sh
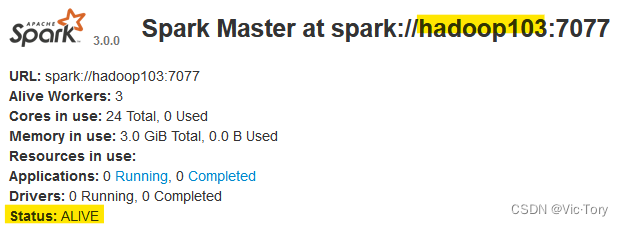
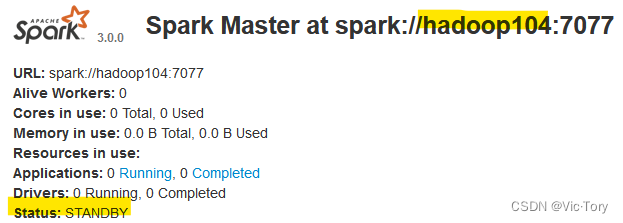
再在hadoop104上单独启动一个Master节点,可以看到这个节点处于备用状态STANDBY,当我们手动杀死当前Master节点后,备用节点的状态就会变为ALIVE,从而保证了集群的高可用。
[root@linux2 spark-standalone]# sbin/start-master.sh
2.3 Yarn集群
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架独立运行。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是Spark 主要是计算框架,本身提供的资源调度并不是它的强项,所以一般会和资源调度框架YARN集成使用。
由于yarn在运行中会对虚拟内存进行检查,从而关闭节点任务,导致spark运行报错如下
ERROR cluster.YarnClientSchedulerBackend: YARN application has exited unexpectedly with state UNDEFINED! Check the YARN application logs for more details.
ERROR cluster.YarnClientSchedulerBackend: Diagnostics message: Shutdown hook called before final status was reported.
为了使节点正常运行,需要在配置文件yarn-site.xml中关闭内存检查
<!-- 关闭物理内存使用量的检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 关闭虚拟内存使用量的检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
spark-env.sh文件在Standalone模式的基础上添加YARN配置文件目录,最终效果如下
export JAVA_HOME=/opt/module/jdk1.8.0_321
# SPARK_MASTER_HOST=hadoop102
# SPARK_MASTER_PORT=7077
# 修改监控页面默认访问端口,防止冲突,所以改成 8989
SPARK_MASTER_WEBUI_PORT=8989
# 配置Zookeeper高可用
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104
-Dspark.deploy.zookeeper.dir=/spark"
# 历史服务配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"
# yarn配置文件目录
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
如果需要开启yarn的spark历史服务记录,修改conf/spark-default.conf文件如下。和standalone模式的历史服务配置一样,需要保证hdfs上的/directory目录存在
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
之后启动Hadoop集群,保证HDFS和Yarn正常运行。
启动spark的历史服务sbin/start-history-server.sh
提交任务如下,通过--master指定提交到yarn集群,--deploy-mode 指定提交的模式为客户端模式
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
运行结束后可以在yarn集群管理页面看到任务运行结果
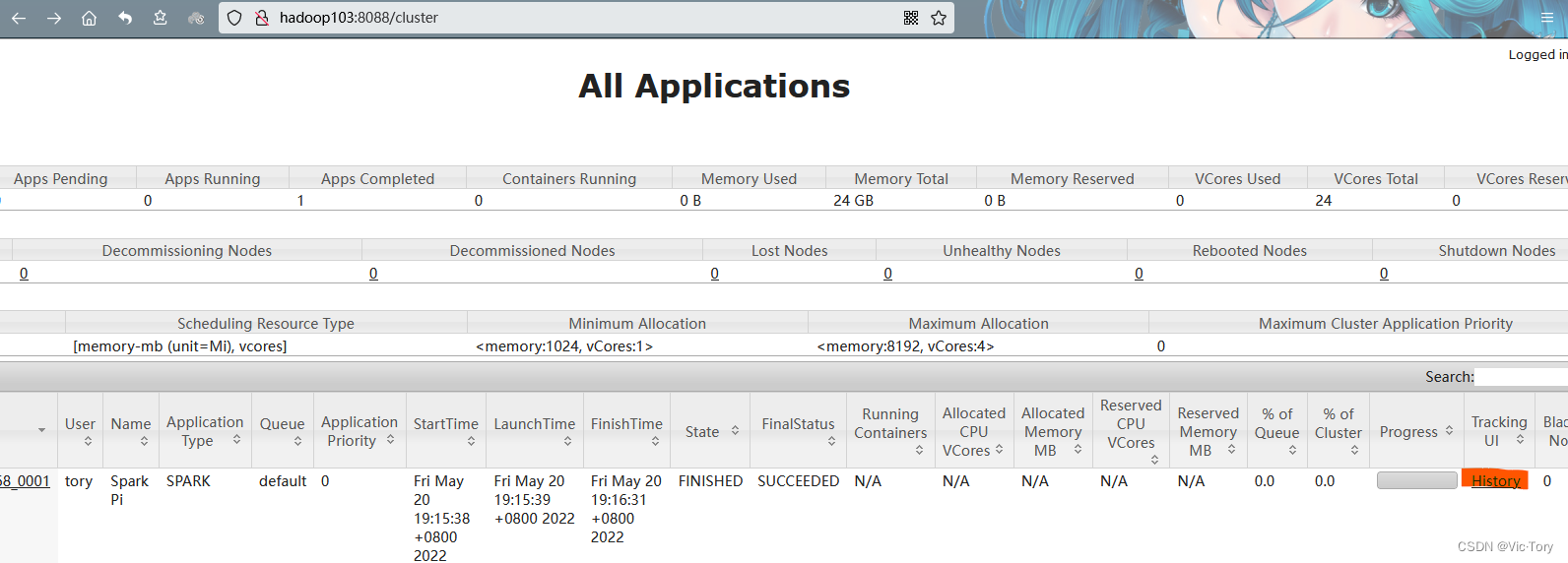 点击任务的Tracking UI一栏下面的History按钮可以跳转到Spark的历史服务记录页面
点击任务的Tracking UI一栏下面的History按钮可以跳转到Spark的历史服务记录页面
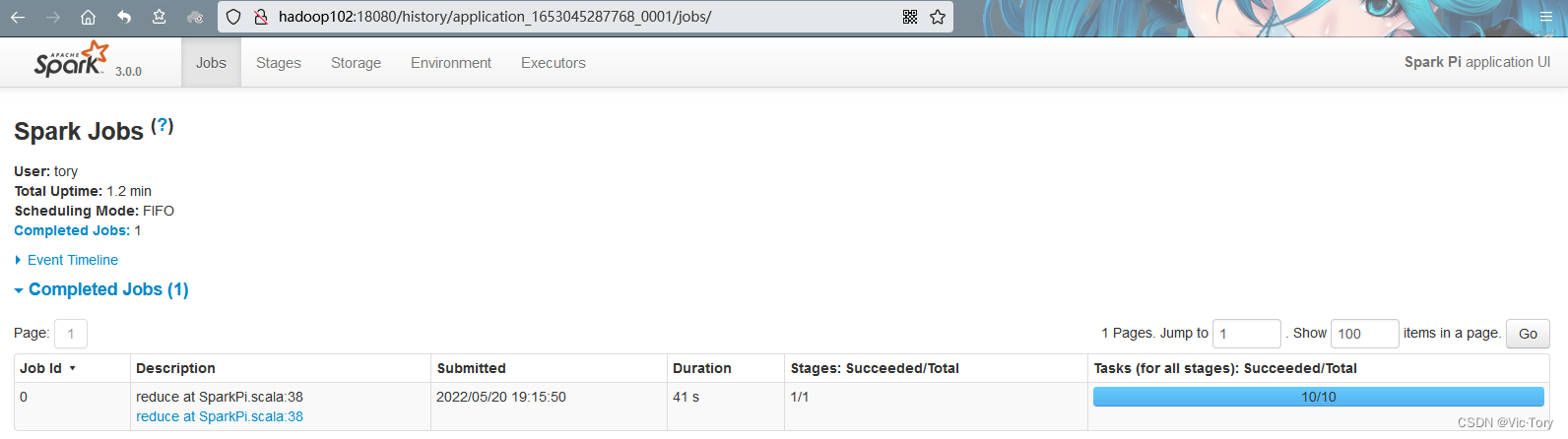
2.4 Windows
Spark也提供了直接在Windows下运行环境
双击spark目录下的bin/spark-shell.cmd,可以看到spark命令行启动,和2.1单节点中的命令行一样
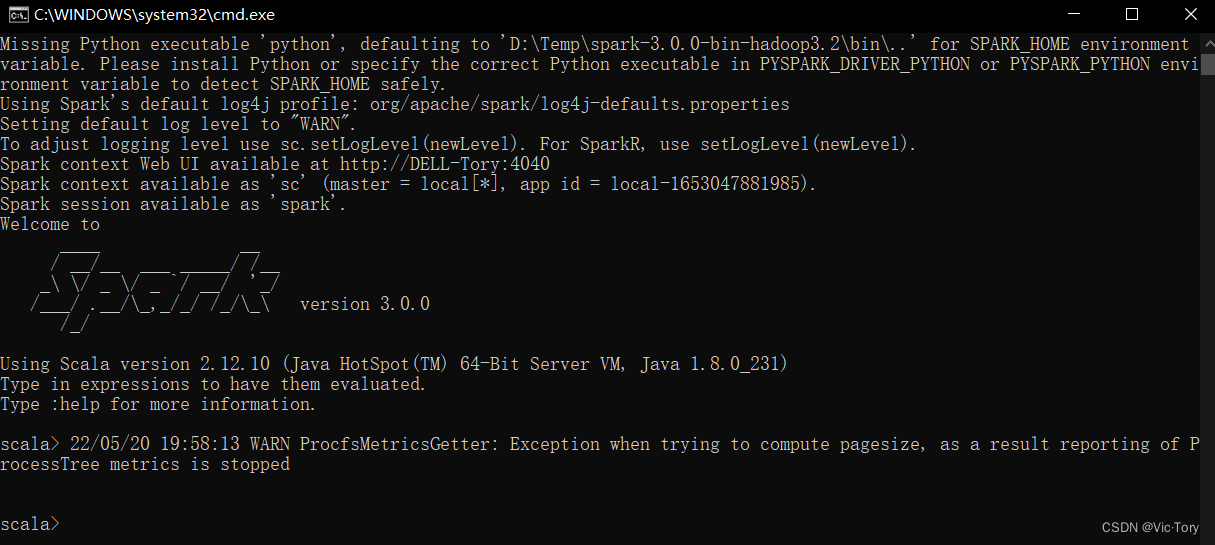
同样也可以进行任务提交,在spark的bin目录下打开Windows命令行工具,通过spark-submit提交任务
D:\Temp\spark-3.0.0-bin-hadoop3.2\bin>spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10
智能推荐
874计算机科学基础综合,2018年四川大学874计算机科学专业基础综合之计算机操作系统考研仿真模拟五套题...-程序员宅基地
文章浏览阅读1.1k次。一、选择题1. 串行接口是指( )。A. 接口与系统总线之间串行传送,接口与I/0设备之间串行传送B. 接口与系统总线之间串行传送,接口与1/0设备之间并行传送C. 接口与系统总线之间并行传送,接口与I/0设备之间串行传送D. 接口与系统总线之间并行传送,接口与I/0设备之间并行传送【答案】C2. 最容易造成很多小碎片的可变分区分配算法是( )。A. 首次适应算法B. 最佳适应算法..._874 计算机科学专业基础综合题型
XShell连接失败:Could not connect to '192.168.191.128' (port 22): Connection failed._could not connect to '192.168.17.128' (port 22): c-程序员宅基地
文章浏览阅读9.7k次,点赞5次,收藏15次。连接xshell失败,报错如下图,怎么解决呢。1、通过ps -e|grep ssh命令判断是否安装ssh服务2、如果只有客户端安装了,服务器没有安装,则需要安装ssh服务器,命令:apt-get install openssh-server3、安装成功之后,启动ssh服务,命令:/etc/init.d/ssh start4、通过ps -e|grep ssh命令再次判断是否正确启动..._could not connect to '192.168.17.128' (port 22): connection failed.
杰理之KeyPage【篇】_杰理 空白芯片 烧入key文件-程序员宅基地
文章浏览阅读209次。00000000_杰理 空白芯片 烧入key文件
一文读懂ChatGPT,满足你对chatGPT的好奇心_引发对chatgpt兴趣的表述-程序员宅基地
文章浏览阅读475次。2023年初,“ChatGPT”一词在社交媒体上引起了热议,人们纷纷探讨它的本质和对社会的影响。就连央视新闻也对此进行了报道。作为新传专业的前沿人士,我们当然不能忽视这一热点。本文将全面解析ChatGPT,打开“技术黑箱”,探讨它对新闻与传播领域的影响。_引发对chatgpt兴趣的表述
中文字符频率统计python_用Python数据分析方法进行汉字声调频率统计分析-程序员宅基地
文章浏览阅读259次。用Python数据分析方法进行汉字声调频率统计分析木合塔尔·沙地克;布合力齐姑丽·瓦斯力【期刊名称】《电脑知识与技术》【年(卷),期】2017(013)035【摘要】该文首先用Python程序,自动获取基本汉字字符集中的所有汉字,然后用汉字拼音转换工具pypinyin把所有汉字转换成拼音,最后根据所有汉字的拼音声调,统计并可视化拼音声调的占比.【总页数】2页(13-14)【关键词】数据分析;数据可..._汉字声调频率统计
linux输出信息调试信息重定向-程序员宅基地
文章浏览阅读64次。最近在做一个android系统移植的项目,所使用的开发板com1是调试串口,就是说会有uboot和kernel的调试信息打印在com1上(ttySAC0)。因为后期要使用ttySAC0作为上层应用通信串口,所以要把所有的调试信息都给去掉。参考网上的几篇文章,自己做了如下修改,终于把调试信息重定向到ttySAC1上了,在这做下记录。参考文章有:http://blog.csdn.net/longt..._嵌入式rootfs 输出重定向到/dev/console
随便推点
uniapp 引入iconfont图标库彩色symbol教程_uniapp symbol图标-程序员宅基地
文章浏览阅读1.2k次,点赞4次,收藏12次。1,先去iconfont登录,然后选择图标加入购物车 2,点击又上角车车添加进入项目我的项目中就会出现选择的图标 3,点击下载至本地,然后解压文件夹,然后切换到uniapp打开终端运行注:要保证自己电脑有安装node(没有安装node可以去官网下载Node.js 中文网)npm i -g iconfont-tools(mac用户失败的话在前面加个sudo,password就是自己的开机密码吧)4,终端切换到上面解压的文件夹里面,运行iconfont-tools 这些可以默认也可以自己命名(我是自己命名的_uniapp symbol图标
C、C++ 对于char*和char[]的理解_c++ char*-程序员宅基地
文章浏览阅读1.2w次,点赞25次,收藏192次。char*和char[]都是指针,指向第一个字符所在的地址,但char*是常量的指针,char[]是指针的常量_c++ char*
Sublime Text2 使用教程-程序员宅基地
文章浏览阅读930次。代码编辑器或者文本编辑器,对于程序员来说,就像剑与战士一样,谁都想拥有一把可以随心驾驭且锋利无比的宝剑,而每一位程序员,同样会去追求最适合自己的强大、灵活的编辑器,相信你和我一样,都不会例外。我用过的编辑器不少,真不少~ 但却没有哪款让我特别心仪的,直到我遇到了 Sublime Text 2 !如果说“神器”是我能给予一款软件最高的评价,那么我很乐意为它封上这么一个称号。它小巧绿色且速度非
对10个整数进行按照从小到大的顺序排序用选择法和冒泡排序_对十个数进行大小排序java-程序员宅基地
文章浏览阅读4.1k次。一、选择法这是每一个数出来跟后面所有的进行比较。2.冒泡排序法,是两个相邻的进行对比。_对十个数进行大小排序java
物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)_网络调试助手连接阿里云连不上-程序员宅基地
文章浏览阅读2.9k次。物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)其实作者本意是使用4G模块来实现与阿里云物联网平台的连接过程,但是由于自己用的4G模块自身的限制,使得阿里云连接总是无法建立,已经联系客服返厂检修了,于是我在此使用网络调试助手来演示如何与阿里云物联网平台建立连接。一.准备工作1.MQTT协议说明文档(3.1.1版本)2.网络调试助手(可使用域名与服务器建立连接)PS:与阿里云建立连解释,最好使用域名来完成连接过程,而不是使用IP号。这里我跟阿里云的售后工程师咨询过,表示对应_网络调试助手连接阿里云连不上
<<<零基础C++速成>>>_无c语言基础c++期末速成-程序员宅基地
文章浏览阅读544次,点赞5次,收藏6次。运算符与表达式任何高级程序设计语言中,表达式都是最基本的组成部分,可以说C++中的大部分语句都是由表达式构成的。_无c语言基础c++期末速成