CAFFE源码学习笔记之内积层-inner_product_layer_caffe innerproduct-程序员宅基地
技术标签: CAFFE源码
一、前言
内积层实际就是全连接。经过之前的卷积层、池化层和非线性变换层,样本已经被映射到隐藏层的特征空间之中,而全连接层就是将学习到的特征又映射到样本分类空间。虽然已经出现了全局池化可以替代全连接,但是仍然不能说全连接就不能用了。
二、源码分析
1、成员变量
全连接的输入时一个M*K的矩阵,权重是K*N的矩阵,所以输出是一个M*N的矩阵
int M_;//num_input
int K_;//C*H*W
int N_;//N_ = num_output
bool bias_term_;
Blob<Dtype> bias_multiplier_;
bool transpose_; ///< if true, assume transposed weights```
2、layersetup
权重是K*N的矩阵:(C*H*W)*num_output
template <typename Dtype>
void InnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int num_output = this->layer_param_.inner_product_param().num_output();//输出
bias_term_ = this->layer_param_.inner_product_param().bias_term();
transpose_ = this->layer_param_.inner_product_param().transpose();
N_ = num_output;
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
// Dimensions starting from "axis" are "flattened" into a single
// length K_ vector. For example, if bottom[0]'s shape is (N, C, H, W),
// and axis == 1, N inner products with dimension CHW are performed.
K_ = bottom[0]->count(axis);
// Check if we need to set up the weights
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
if (bias_term_) {
this->blobs_.resize(2);
} else {
this->blobs_.resize(1);
}
// Initialize the weights
vector<int> weight_shape(2);
if (transpose_) {
weight_shape[0] = K_;
weight_shape[1] = N_;
} else {
weight_shape[0] = N_;
weight_shape[1] = K_;
}
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
// fill the weights
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
// If necessary, intiialize and fill the bias term
if (bias_term_) {
vector<int> bias_shape(1, N_);
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
} // parameter initialization
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
3、reshape
输入是一个M*K的矩阵:num_input*(C*H*W)
经过转换:top_shape.resize(axis + 1)
输出是M*N的矩阵:
num_input∗num_output
template <typename Dtype>
void InnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Figure out the dimensions
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
const int new_K = bottom[0]->count(axis);
CHECK_EQ(K_, new_K)
<< "Input size incompatible with inner product parameters.";
// The first "axis" dimensions are independent inner products; the total
// number of these is M_, the product over these dimensions.
M_ = bottom[0]->count(0, axis);//num_input
// The top shape will be the bottom shape with the flattened axes dropped,
// and replaced by a single axis with dimension num_output (N_).
vector<int> top_shape = bottom[0]->shape();
top_shape.resize(axis + 1);
top_shape[axis] = N_;
top[0]->Reshape(top_shape);
// Set up the bias multiplier
if (bias_term_) {
vector<int> bias_shape(1, M_);
bias_multiplier_.Reshape(bias_shape);
caffe_set(M_, Dtype(1), bias_multiplier_.mutable_cpu_data());
}
}
3、前向计算
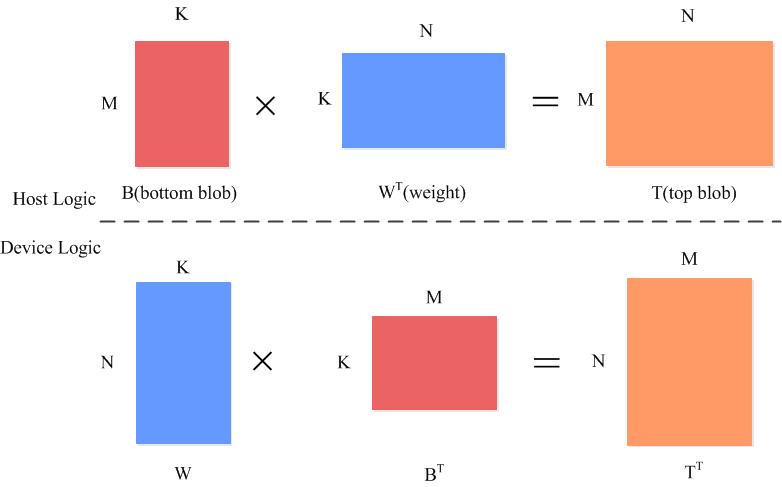
直接调用矩阵内积函数caffe_gpu_gemm
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->gpu_data();
Dtype* top_data = top[0]->mutable_gpu_data();
const Dtype* weight = this->blobs_[0]->gpu_data();
if (M_ == 1) {
caffe_gpu_gemv<Dtype>(CblasNoTrans, N_, K_, (Dtype)1.,weight, bottom_data, (Dtype)0., top_data);//这个是向量内积函数
if (bias_term_)
caffe_gpu_axpy<Dtype>(N_, bias_multiplier_.cpu_data()[0],this->blobs_[1]->gpu_data(), top_data);
} else {
caffe_gpu_gemm<Dtype>(CblasNoTrans,transpose_ ? CblasNoTrans : CblasTrans,M_, N_, K_, (Dtype)1.,bottom_data, weight, (Dtype)0., top_data);
if (bias_term_)
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, N_, 1, (Dtype)1.,bias_multiplier_.gpu_data(),this->blobs_[1]->gpu_data(), (Dtype)1., top_data);
}
}4、反向传播
对参数求偏导
∂loss∂wkj=∂loss∂zk∗∂zk∂wkj=∂loss∂zk∗uj
转换成向量:
∂loss∂Wj==∂loss∂Z∗uj
转换成矩阵:
∂loss∂W==∂loss∂ZT∗U
即 layer_blobs_=topdiff∗bottom_data
对输出求偏导:
公式:
∂loss∂uj=∑n=Mk∂loss∂zk∗∂zk∂uj
转化为向量
∂loss∂UT=∂loss∂ZT∗W
M为需要分的类别数
转换成矩阵的形式:
∂loss∂U=∂loss∂Z∗W
即
bottom_diff=top_diff∗layer_blobs_
template <typename Dtype>
void InnerProductLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (this->param_propagate_down_[0]) {
const Dtype* top_diff = top[0]->gpu_diff();
const Dtype* bottom_data = bottom[0]->gpu_data();
// Gradient with respect to weight
if (transpose_) {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
K_, N_, M_,
(Dtype)1., bottom_data, top_diff,
(Dtype)1., this->blobs_[0]->mutable_gpu_diff());
} else {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
N_, K_, M_,
(Dtype)1., top_diff, bottom_data,
(Dtype)1., this->blobs_[0]->mutable_gpu_diff());
}
}
if (bias_term_ && this->param_propagate_down_[1]) {
const Dtype* top_diff = top[0]->gpu_diff();
// Gradient with respect to bias
caffe_gpu_gemv<Dtype>(CblasTrans, M_, N_, (Dtype)1., top_diff,
bias_multiplier_.gpu_data(), (Dtype)1.,
this->blobs_[1]->mutable_gpu_diff());
}
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->gpu_diff();
// Gradient with respect to bottom data
if (transpose_) {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->gpu_data(),
(Dtype)0., bottom[0]->mutable_gpu_diff());
} else {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->gpu_data(),
(Dtype)0., bottom[0]->mutable_gpu_diff());
}
}
}智能推荐
leetcode 172. 阶乘后的零-程序员宅基地
文章浏览阅读63次。题目给定一个整数 n,返回 n! 结果尾数中零的数量。解题思路每个0都是由2 * 5得来的,相当于要求n!分解成质因子后2 * 5的数目,由于n中2的数目肯定是要大于5的数目,所以我们只需要求出n!中5的数目。C++代码class Solution {public: int trailingZeroes(int n) { ...
Day15-【Java SE进阶】IO流(一):File、IO流概述、File文件对象的创建、字节输入输出流FileInputStream FileoutputStream、释放资源。_outputstream释放-程序员宅基地
文章浏览阅读992次,点赞27次,收藏15次。UTF-8是Unicode字符集的一种编码方案,采取可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节。文件字节输入流:每次读取多个字节到字节数组中去,返回读取的字节数量,读取完毕会返回-1。注意1:字符编码时使用的字符集,和解码时使用的字符集必须一致,否则会出现乱码。定义一个与文件一样大的字节数组,一次性读取完文件的全部字节。UTF-8字符集:汉字占3个字节,英文、数字占1个字节。GBK字符集:汉字占2个字节,英文、数字占1个字节。GBK规定:汉字的第一个字节的第一位必须是1。_outputstream释放
jeecgboot重新登录_jeecg 登录自动退出-程序员宅基地
文章浏览阅读1.8k次,点赞3次,收藏3次。解决jeecgboot每次登录进去都会弹出请重新登录问题,在utils文件下找到request.js文件注释这段代码即可_jeecg 登录自动退出
数据中心供配电系统负荷计算实例分析-程序员宅基地
文章浏览阅读3.4k次。我国目前普遍采用需要系数法和二项式系数法确定用电设备的负荷,其中需要系数法是国际上普遍采用的确定计算负荷的方法,最为简便;而二项式系数法在确定设备台数较少且各台设备容量差..._数据中心用电负荷统计变压器
HTML5期末大作业:网页制作代码 网站设计——人电影网站(5页) HTML+CSS+JavaScript 学生DW网页设计作业成品 dreamweaver作业静态HTML网页设计模板_网页设计成品百度网盘-程序员宅基地
文章浏览阅读7k次,点赞4次,收藏46次。HTML5期末大作业:网页制作代码 网站设计——人电影网站(5页) HTML+CSS+JavaScript 学生DW网页设计作业成品 dreamweaver作业静态HTML网页设计模板常见网页设计作业题材有 个人、 美食、 公司、 学校、 旅游、 电商、 宠物、 电器、 茶叶、 家居、 酒店、 舞蹈、 动漫、 明星、 服装、 体育、 化妆品、 物流、 环保、 书籍、 婚纱、 军事、 游戏、 节日、 戒烟、 电影、 摄影、 文化、 家乡、 鲜花、 礼品、 汽车、 其他 等网页设计题目, A+水平作业_网页设计成品百度网盘
【Jailhouse 文章】Look Mum, no VM Exits_jailhouse sr-iov-程序员宅基地
文章浏览阅读392次。jailhouse 文章翻译,Look Mum, no VM Exits!_jailhouse sr-iov
随便推点
chatgpt赋能python:Python怎么删除文件中的某一行_python 删除文件特定几行-程序员宅基地
文章浏览阅读751次。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。AI职场汇报智能办公文案写作效率提升教程 专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具。_python 删除文件特定几行
Java过滤特殊字符的正则表达式_java正则表达式过滤特殊字符-程序员宅基地
文章浏览阅读2.1k次。【代码】Java过滤特殊字符的正则表达式。_java正则表达式过滤特殊字符
CSS中设置背景的7个属性及简写background注意点_background设置背景图片-程序员宅基地
文章浏览阅读5.7k次,点赞4次,收藏17次。css中背景的设置至关重要,也是一个难点,因为属性众多,对应的属性值也比较多,这里详细的列举了背景相关的7个属性及对应的属性值,并附上演示代码,后期要用的话,可以随时查看,那我们坐稳开车了······1: background-color 设置背景颜色2:background-image来设置背景图片- 语法:background-image:url(相对路径);-可以同时为一个元素指定背景颜色和背景图片,这样背景颜色将会作为背景图片的底色,一般情况下设置背景..._background设置背景图片
Win10 安装系统跳过创建用户,直接启用 Administrator_windows10msoobe进程-程序员宅基地
文章浏览阅读2.6k次,点赞2次,收藏8次。Win10 安装系统跳过创建用户,直接启用 Administrator_windows10msoobe进程
PyCharm2021安装教程-程序员宅基地
文章浏览阅读10w+次,点赞653次,收藏3k次。Windows安装pycharm教程新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入下载安装PyCharm1、进入官网PyCharm的下载地址:http://www.jetbrains.com/pycharm/downl_pycharm2021
《跨境电商——速卖通搜索排名规则解析与SEO技术》一一1.1 初识速卖通的搜索引擎...-程序员宅基地
文章浏览阅读835次。本节书摘来自异步社区出版社《跨境电商——速卖通搜索排名规则解析与SEO技术》一书中的第1章,第1.1节,作者: 冯晓宁,更多章节内容可以访问云栖社区“异步社区”公众号查看。1.1 初识速卖通的搜索引擎1.1.1 初识速卖通搜索作为速卖通卖家都应该知道,速卖通经常被视为“国际版的淘宝”。那么请想一下,普通消费者在淘宝网上购买商品的时候,他的行为应该..._跨境电商 速卖通搜索排名规则解析与seo技术 pdf