Python数据分析学习收获与心得_python数据分析心得体会-程序员宅基地
Python是一种功能强大的编程语言,它被广泛应用于数据科学和机器学习领域。Python的数据分析库非常丰富,包括NumPy、Pandas、Matplotlib、Scikit-learn等。在学习Python数据分析的过程中,我收获了很多,以下是我的心得体会。
第一,Python数据分析的基础知识非常重要。在学习Python数据分析之前,我们需要掌握Python的基础语法、数据类型、函数、控制结构等知识。只有掌握了这些基础知识,才能更好地理解和应用Python的数据分析库。
第二,NumPy是Python数据分析的基础。NumPy是Python的一个科学计算库,它提供了高效的多维数组操作和数学函数。在Python数据分析中,我们经常需要处理大量的数据,使用NumPy可以提高代码的运行效率。同时,NumPy还提供了一些统计函数和线性代数函数,方便我们进行数据分析和建模。
第三,Pandas是Python数据分析的核心。Pandas是Python的一个数据分析库,它提供了高效的数据结构和数据操作方法。Pandas的数据结构包括Series和DataFrame,分别用于表示一维和二维的带标签数据。Pandas提供了丰富的数据操作方法,包括数据的选择、过滤、排序、聚合等。Pandas的数据操作方法非常灵活,可以满足不同的数据分析需求。
第四,Matplotlib是Python数据分析的可视化工具。Matplotlib是Python的一个数据可视化库,它提供了丰富的绘图功能,可以绘制线图、散点图、柱状图、饼图等。Matplotlib的绘图风格可以自定义,可以满足不同的数据可视化需求。Matplotlib还可以与Pandas和NumPy结合使用,方便我们对数据进行可视化分析。
第五,Scikit-learn是Python数据分析的机器学习库。Scikit-learn是Python的一个机器学习库,它提供了丰富的机器学习算法和工具,包括分类、回归、聚类、降维等。Scikit-learn还提供了数据预处理、特征选择、模型评估等工具,方便我们进行机器学习建模和分析。
在学习Python数据分析的过程中,我还学到了一些技巧和注意事项。首先,Python数据分析需要良好的数据处理能力。在进行数据分析之前,我们需要对数据进行清洗、转换和处理,确保数据的质量和准确性。其次,Python数据分析需要良好的编程习惯。我们需要编写可读性强、可维护性强的代码,遵循良好的编程规范和风格。最后,Python数据分析需要不断学习和实践。数据科学和机器学习领域的技术和方法不断更新,我们需要不断学习和实践,保持自己的竞争力。
总之,Python数据分析是一项非常有挑战性和有意义的工作。通过学习Python数据分析,我们可以更好地理解和应用数据科学和机器学习的技术和方法,为实现数据驱动的决策和创新提供支持和帮助。
接下来我将详细介绍Python数据分析的各个方面,包括数据清洗、数据处理、数据可视化和机器学习建模等。希望这些内容能够对初学者有所帮助。
一、数据清洗
在进行Python数据分析之前,我们需要对数据进行清洗。数据清洗是指对数据进行预处理,包括缺失值处理、异常值处理、重复值处理等。数据清洗的目的是确保数据的质量和准确性,避免对数据分析结果产生影响。
1. 缺失值处理
在数据中,有些数据可能缺失或者为空。缺失值的处理是数据清洗中的一个重要环节。缺失值的处理方法包括删除、填充和插值等。
删除缺失值:当数据中的缺失值比例较少时,可以直接删除缺失值所在的行或列。删除缺失值的方法可以使用Pandas库中的dropna()函数。
填充缺失值:当数据中的缺失值比例较多时,可以使用填充缺失值的方法。填充缺失值的方法包括使用均值、中位数、众数等进行填充。填充缺失值的方法可以使用Pandas库中的fillna()函数。
插值缺失值:插值是一种将缺失值从已知数据中推断出来的方法。插值的方法包括线性插值、多项式插值、样条插值等。插值缺失值的方法可以使用Scipy库中的interpolate()函数。
2. 异常值处理
异常值是指数据中的异常点或者离群点。异常值的处理是数据清洗中的另一个重要环节。异常值的处理方法包括删除、替换和标记等。
删除异常值:当数据中的异常值比例较少时,可以直接删除异常值所在的行或列。删除异常值的方法可以使用Pandas库中的drop()函数。
替换异常值:当数据中的异常值比例较多时,可以使用替换异常值的方法。替换异常值的方法包括使用均值、中位数、众数等进行替换。替换异常值的方法可以使用Pandas库中的replace()函数。
标记异常值:标记异常值是指将异常值单独标记出来,以便后续的处理。标记异常值的方法可以使用Pandas库中的loc()函数。
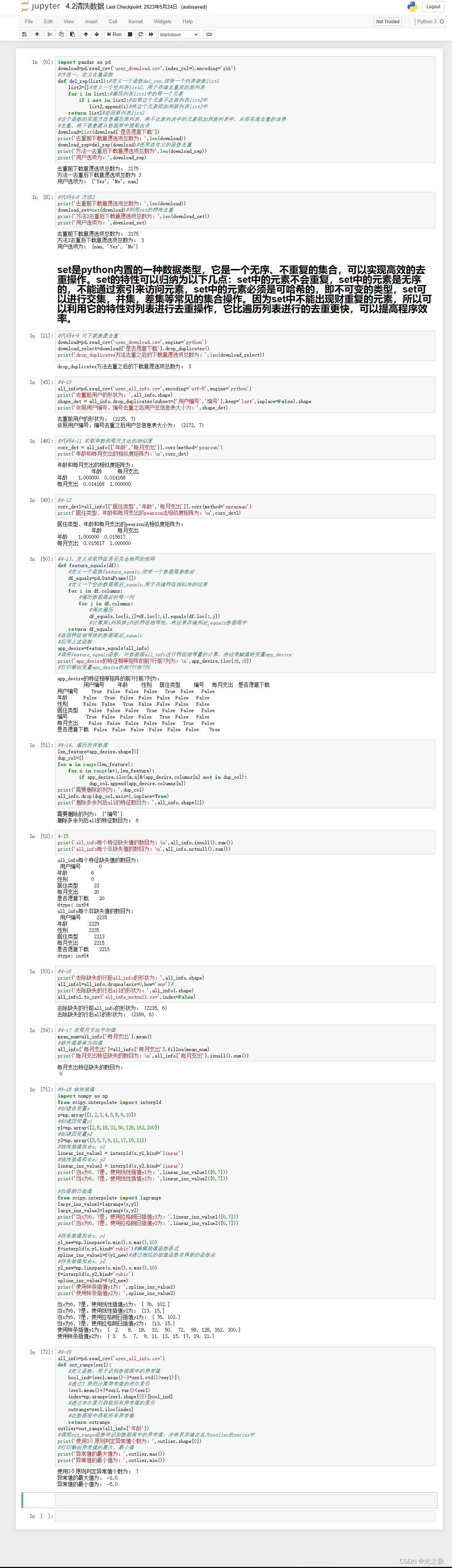
3. 重复值处理
重复值是指数据中存在相同的数据记录。重复值的处理是数据清洗中的另一个重要环节。重复值的处理方法包括删除、合并和标记等。
删除重复值:当数据中的重复值比例较少时,可以直接删除重复值所在的行或列。删除重复值的方法可以使用Pandas库中的drop_duplicates()函数。
合并重复值:当数据中的重复值比例较多时,可以使用合并重复值的方法。合并重复值的方法包括使用均值、中位数、众数等进行合并。合并重复值的方法可以使用Pandas库中的groupby()函数。
标记重复值:标记重复值是指将重复值单独标记出来,以便后续的处理。标记重复值的方法可以使用Pandas库中的duplicated()函数。
二、数据处理
在进行Python数据分析之前,我们需要对数据进行处理。数据处理是指对数据进行转换、归一化、标准化等。数据处理的目的是为了更好地进行数据分析和建模。
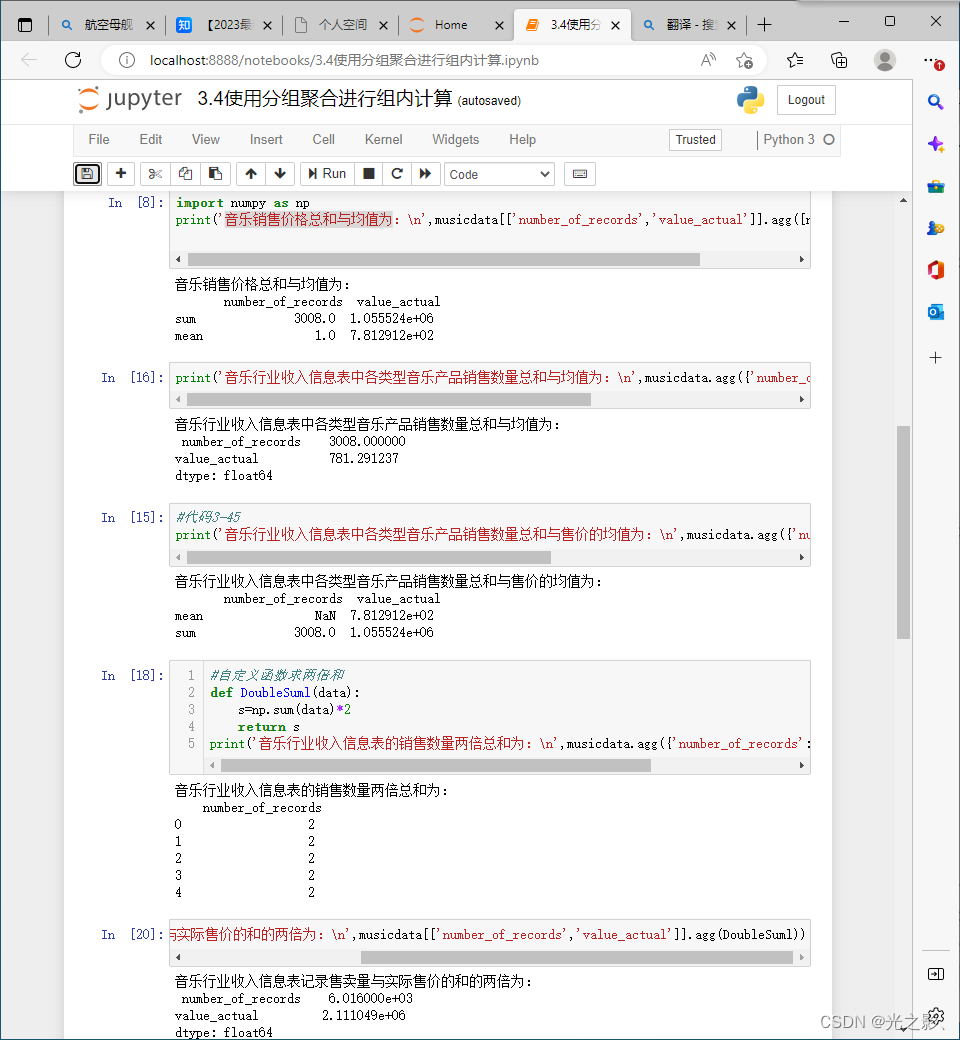
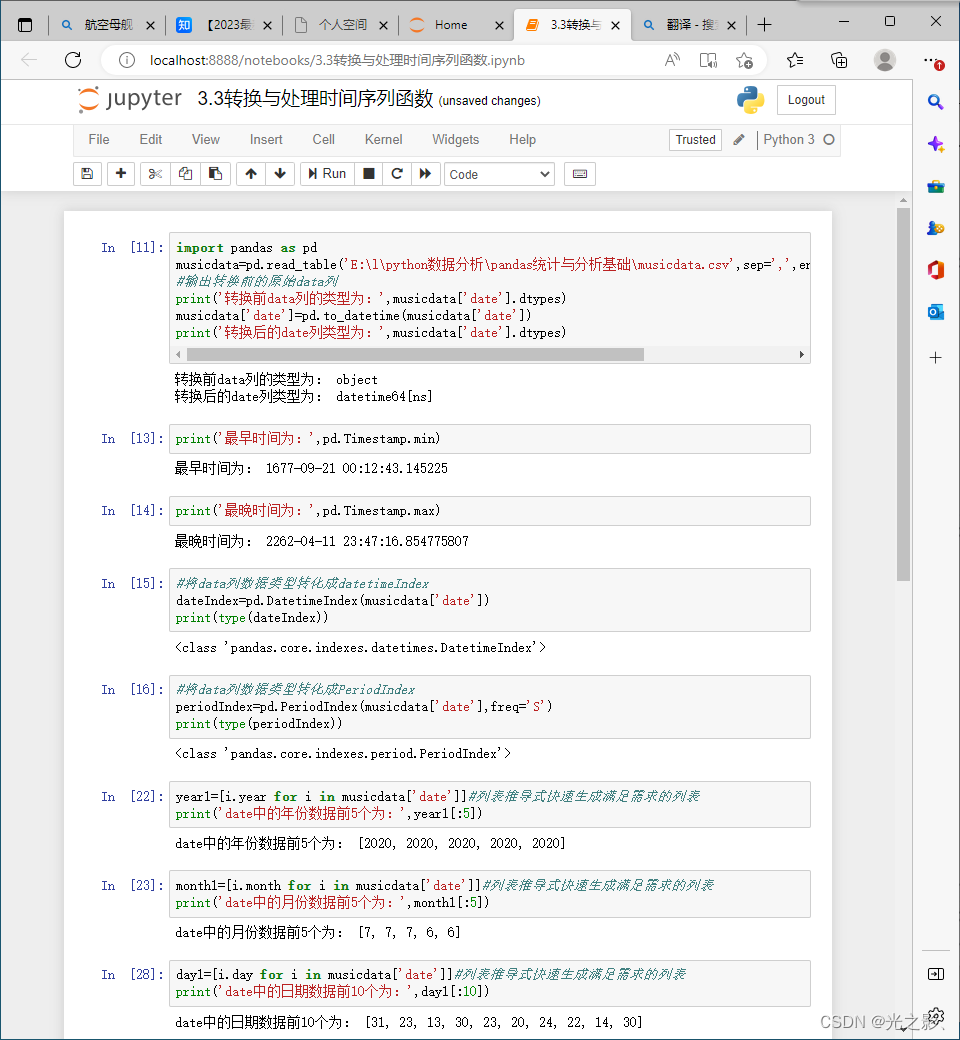

1. 数据转换
数据转换是指将数据从一种形式转换为另一种形式。数据转换的方法包括数据类型转换、数据结构转换、数据格式转换等。
数据类型转换:当数据类型不符合要求时,可以使用数据类型转换的方法进行转换。数据类型转换的方法可以使用Pandas库中的astype()函数。
数据结构转换:当数据结构不符合要求时,可以使用数据结构转换的方法进行转换。数据结构转换的方法可以使用Pandas库中的reshape()函数。
数据格式转换:当数据格式不符合要求时,可以使用数据格式转换的方法进行转换。数据格式转换的方法可以使用Pandas库中的to_csv()函数。
2. 数据归一化
数据归一化是指将数据缩放到一定范围内。数据归一化的目的是为了消除不同特征之间的量纲差异,避免对数据分析结果产生影响。数据归一化的方法包括最小-最大归一化、Z-Score归一化等。
最小-最大归一化:最小-最大归一化是指将数据缩放到[0,1]的范围内。最小-最大归一化的方法可以使用Scikit-learn库中的MinMaxScaler()函数。
Z-Score归一化:Z-Score归一化是指将数据缩放到均值为0,标准差为1的范围内。Z-Score归一化的方法可以使用Scikit-learn库中的StandardScaler()函数。
3. 数据标准化
数据标准化是指对数据进行处理,使得数据的均值为0,方差为1。数据标准化的目的是为了消除不同特征之间的量纲差异,避免对数据分析结果产生影响。数据标准化的方法包括Z-Score标准化、小数定标标准化等。
Z-Score标准化:Z-Score标准化是指将数据缩放到均值为0,标准差为1的范围内。Z-Score标准化的方法可以使用Scikit-learn库中的StandardScaler()函数。
小数定标标准化:小数定标标准化是指将数据缩放到[-1,1]或[0,1]的范围内。小数定标标准化的方法可以使用Pandas库中的apply()函数。
三、数据分析
在进行Python数据分析之前,我们需要对数据进行分析。数据分析是指对数据进行统计分析、可视化分析、模型分析等。数据分析的目的是为了发现数据中的规律和趋势,为后续的决策提供依据。
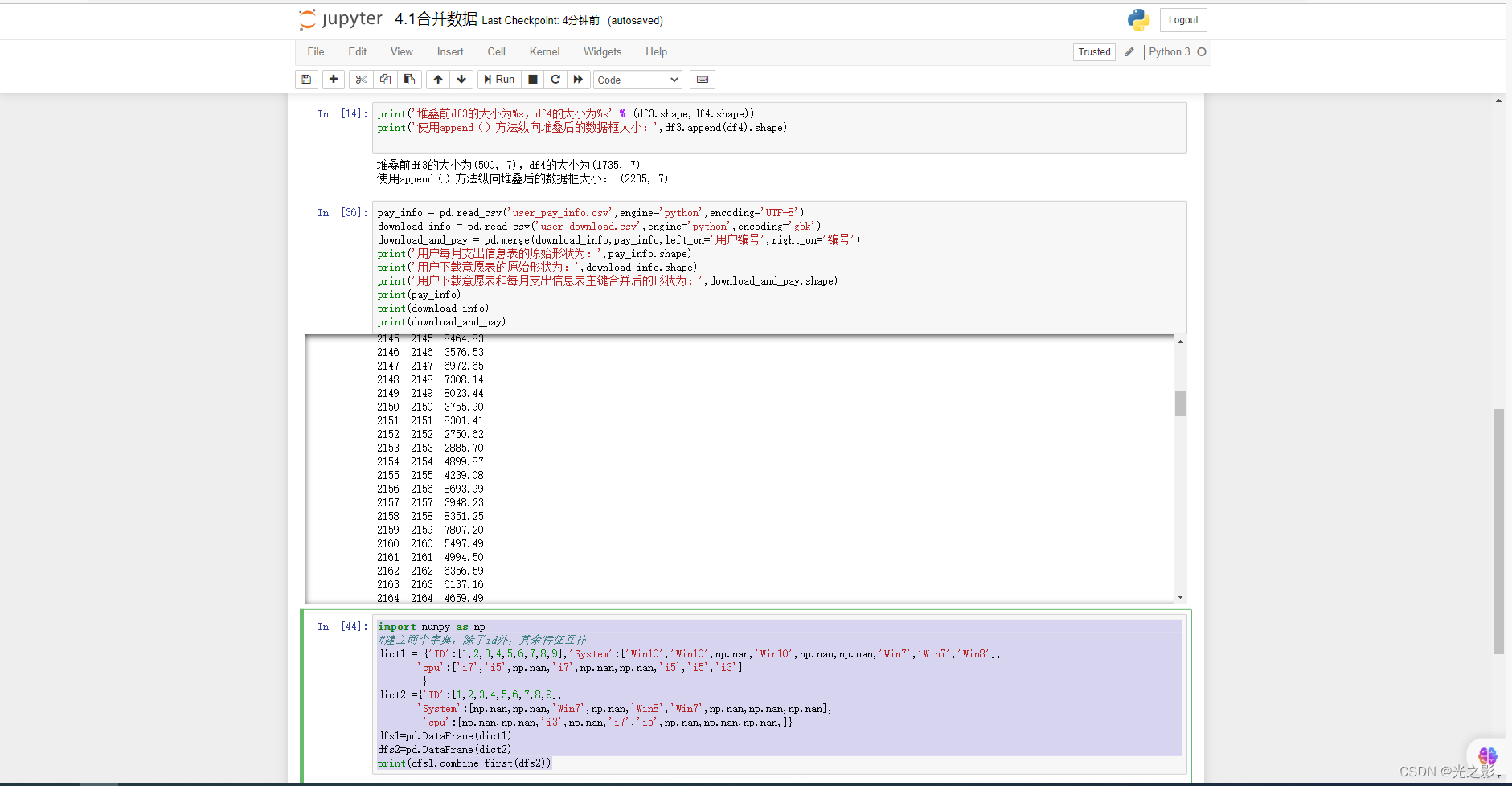
1. 统计分析
统计分析是指对数据进行描述性统计、推断性统计等。统计分析的方法包括基本统计量分析、假设检验分析、相关性分析等。
基本统计量分析:基本统计量分析是指对数据进行均值、中位数、众数、方差、标准差等的计算和分析。基本统计量分析的方法可以使用Pandas库中的describe()函数。
假设检验分析:假设检验分析是指对数据进行假设检验,判断样本是否代表总体。假设检验分析的方法可以使用Scipy库中的ttest_1samp()函数。
相关性分析:相关性分析是指对数据进行相关性分析,判断不同特征之间的相关性。相关性分析的方法可以使用Pandas库中的corr()函数。
2. 可视化分析
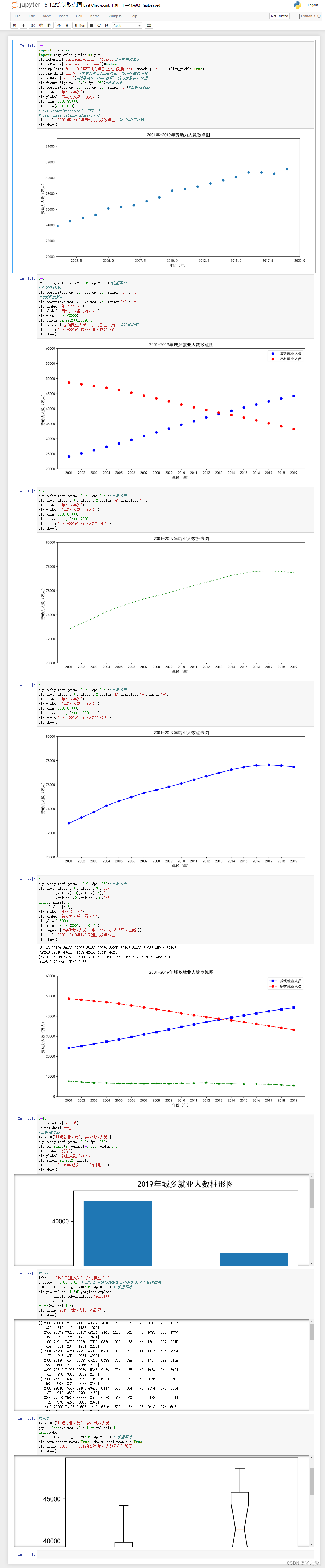
可视化分析是指通过可视化图表对数据进行分析。可视化分析的方法包括散点图、折线图、柱状图、饼图等。
散点图:散点图是指将数据以点的形式展示出来,用于判断不同特征之间的相关性。散点图的方法可以使用Matplotlib库中的scatter()函数。
折线图:折线图是指将数据以折线的形式展示出来,用于判断时间序列数据的趋势。折线图的方法可以使用Matplotlib库中的plot()函数。
柱状图:柱状图是指将数据以柱状的形式展示出来,用于比较不同特征之间的差异。柱状图的方法可以使用Matplotlib库中的bar()函数。
饼图:饼图是指将数据以饼状的形式展示出来,用于比较不同特征之间的占比。饼图的方法可以使用Matplotlib库中的pie()函数。



3. 模型分析
模型分析是指对数据进行建模和预测。模型分析的方法包括线性回归、逻辑回归、决策树等。
线性回归:线性回归是指对数据进行线性拟合,用于预测连续型数据。线性回归的方法可以使用Scikit-learn库中的LinearRegression()函数。
逻辑回归:逻辑回归是指对数据进行逻辑分类,用于预测离散型数据。逻辑回归的方法可以使用Scikit-learn库中的LogisticRegression()函数。
决策树:决策树是指对数据进行分类,用于预测离散型数据。决策树的方法可以使用Scikit-learn库中的DecisionTreeClassifier()函数。
四、数据可视化
数据可视化是指通过图表、图像等方式将数据呈现出来,以便于人们更好地理解和分析数据。Python中有多种数据可视化工具,包括Matplotlib、Seaborn、Plotly等。
1. Matplotlib
Matplotlib是Python中最常用的数据可视化工具之一,它提供了多种绘图方法,包括折线图、散点图、柱状图、饼图等。Matplotlib的绘图方法灵活、易于使用,可以满足大多数数据可视化需求。
2. Seaborn
Seaborn是基于Matplotlib的高级数据可视化工具,它提供了更多的绘图方法和更好的默认样式,可以快速生成高质量的图表。Seaborn适用于探索性数据分析和数据挖掘,可以帮助用户更好地理解数据。
3. Plotly
Plotly是一个交互式数据可视化工具,它可以生成交互式的图表和可视化界面。Plotly支持多种编程语言,包括Python、R、JavaScript等,可以方便地在不同平台上使用。Plotly的交互性和可定制性非常强,可以满足更高级的数据可视化需求。
五、数据挖掘
数据挖掘是指从大量数据中发现规律和趋势,提取有价值的信息和知识。Python中有多种数据挖掘工具,包括Scikit-learn、TensorFlow、Keras等。
1. Scikit-learn
Scikit-learn是Python中最常用的机器学习库之一,它提供了多种机器学习算法,包括分类、回归、聚类等。Scikit-learn的算法实现简单、易于使用,可以快速构建和训练机器学习模型。
2. TensorFlow
TensorFlow是由Google开发的机器学习框架,它支持多种机器学习算法和深度学习算法,可以用于构建和训练复杂的神经网络模型。TensorFlow的计算速度非常快,适用于大规模数据处理和高性能计算。
3. Keras
Keras是一个基于TensorFlow的深度学习库,它提供了更高级的API和更简单的接口,可以快速构建和训练深度学习模型。Keras支持多种深度学习算法,包括卷积神经网络、循环神经网络等,可以满足不同的深度学习需求。
七、应用场景
Python的数据处理和分析功能广泛应用于各个行业和领域,包括金融、医疗、教育、工业等。下面列举几个常见的应用场景:
1. 金融行业
金融行业是数据处理和分析的重要应用场景之一,Python在金融数据分析、风险管理、投资组合优化等方面具有广泛应用。Python可以帮助金融机构更好地理解市场趋势和风险状况,提高投资决策的准确性和效率。
2. 医疗行业
医疗行业是另一个重要的数据分析应用场景,Python可以用于医疗数据分析、疾病预测、药物研发等方面。Python可以帮助医疗机构更好地理解疾病发展趋势和治疗效果,提高医疗服务的质量和效率。
3. 教育行业
教育行业也是数据分析的重要应用场景之一,Python可以用于学生数据分析、课程评估、教学质量监控等方面。Python可以帮助教育机构更好地理解学生学习情况和教学效果,提高教学质量和学生满意度。
4. 工业行业
工业行业是Python数据处理和分析的另一个应用场景,Python可以用于工业数据分析、设备监控、生产优化等方面。Python可以帮助企业更好地理解生产过程和设备状况,提高生产效率和产品质量。
八、总结
在学习Python数据分析的过程中,我深深感受到了数据分析的重要性和Python语言的强大之处。Python是一种非常流行的编程语言,它具有简单、易学、易读、易写的特点,可以帮助我们快速地开发数据分析程序。而数据分析则是一种非常重要的技能,它可以帮助我们从大量的数据中提取有用的信息,为企业、政府和个人提供决策支持。
在学习Python数据分析的过程中,我主要掌握了以下几个方面的知识:
-
Python编程语言:学习Python编程语言是Python数据分析的基础,我通过学习Python语法、函数、模块、类等知识,掌握了如何使用Python进行数据分析。
-
数据结构和算法:数据结构和算法是Python数据分析的基础,我通过学习列表、字典、集合、栈、队列、树、图等数据结构,以及排序、查找、遍历、递归等算法,掌握了如何对数据进行处理和分析。
-
数据库和SQL语言:数据库是Python数据分析的重要工具,我学习了如何使用Python连接数据库,以及如何使用SQL语言进行数据查询、分析和处理。
-
数据可视化:数据可视化是Python数据分析的重要环节,我学习了如何使用Python的Matplotlib、Seaborn、Plotly等库进行数据可视化,以便更好地展示数据和分析结果。
-
机器学习和深度学习:机器学习和深度学习是Python数据分析的高级技能,我学习了如何使用Python的Scikit-learn、TensorFlow、Keras等库进行机器学习和深度学习,以便更好地进行数据预测、分类、聚类等分析。
通过学习Python数据分析,我不仅掌握了Python编程语言和数据分析的基础知识,还学会了如何使用Python进行数据可视化和机器学习。同时,我还学会了如何使用Python连接数据库,以及如何使用SQL语言进行数据查询、分析和处理。这些知识对我今后的工作和学习都非常有帮助。
在学习Python数据分析的过程中,我还深刻认识到了数据分析的重要性。在当今信息化的时代,数据已经成为了企业、政府和个人决策的重要依据。通过对数据进行分析和处理,我们可以更好地了解市场、客户、竞争对手等情况,为企业、政府和个人提供决策支持。
总的来说,学习Python数据分析是一件非常有意义的事情。通过学习Python数据分析,我们可以掌握Python编程语言和数据分析的基础知识,学会如何使用Python进行数据可视化和机器学习,以及如何使用Python连接数据库和进行数据查询、分析和处理。同时,我们还可以深刻认识到数据分析的重要性,为企业、政府和个人提供决策支持。
智能推荐
微型计算机原理与接口实验报告,微型计算机原理及接口技术实验报告.docx-程序员宅基地
文章浏览阅读3.6k次。成都理工大学微型计算机原理及接口技术实验报告学 院 : 核技术与自动化工程学院专 业 : 电气工程及其自动化班 级 :学 号 :姓 名 :指导老师 :完成时间 :实验一 EMU 8086软件的使用1、实验目的通过对emu8086的使用,来理解《微型计算机原理及接口技术》课本上的理论知识,加深对知识的运用,以及emu8086交互式学习汇编语言(Assembly ..._微机原理与接口技术emu8086课题总结
如何在Vue中使用百度地图API来创建地图应用程序。_百度地图js api3.0怎么转换成vue-程序员宅基地
文章浏览阅读450次,点赞3次,收藏3次。Vue是一款流行的JavaScript框架,它提供了一种简单而灵活的方式来构建交互式的Web前端应用程序。在许多Web应用程序中,地图显示和地理位置信息都是必不可少的功能。而百度地图是一款流行的地图服务提供商,提供了一系列API来帮助开发者创建交互式的地图应用程序。本篇教程将介绍如何在Vue应用程序中使用百度地图API来创建地图应用程序。通过本篇教程,您将学习到如下内容:如何获得百度地图AK密钥如何在Vue中引入百度地图API如何在Vue中使用百度地图API来创建地图应用程序。_百度地图js api3.0怎么转换成vue
计算机毕业设计(77)php小程序毕设作品之维修保养汽车小程序系统_汽车保养php后台项目-程序员宅基地
文章浏览阅读326次。本课题主要目标是设计并能够实现一个基于微信汽车维修保养小程序系统,前台用户使用小程序,小程序使用微信开发者工具开发;后台管理使用基PP+MySql的B/S架构,开发工具使用phpstorm;:基于微信汽车维修保养小程序系统是计算机技术与汽修店维修保养管理相结合的产物,通过微信小程序维修和保养系统实现了对汽修店维修保养的高效管理。随着计算机技术的不断提高,计算机已经深入到社会生活的各个角落;而采用人工维修保养预约的方法,不仅效率低,易出错,手续繁琐,而且耗费大量人力。_汽车保养php后台项目
FPGA采集AD7606全网最细讲解 提供串行和并行2套工程源码和技术支持-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏270次。AD7606是一款非常受欢迎的AD芯片,因为他支持8通道同时采集数据,采样深度16位,已经很不错了,虽然采样率只有200 kSPS,但对电压等低速数据源的采集而言已经完全足够了,该芯片在电压检测等项目中有着广泛应用。本文详细描述了设计方案,工程代码编译通过后上板调试验证,可直接项目移植,适用于在校学生、研究生项目开发,也适用于在职工程师做项目开发,可应用于AD数据采集领域_ad7606
plc编程-程序员宅基地
文章浏览阅读647次。刚开始学习plc,感觉很难,不好入门。但是后来慢慢的接触到一些实例以后,我发现其实它是很有意思的一门功课,所以我对他的兴趣逐渐浓厚起来,现在,我已经是公司的编程高手了,希望可以结识到更多的喜欢plc的朋友。_plc编程
AndroidAPP更新升级完整实现Demo(搭建本地服务器)_android在线升级服务器搭建-程序员宅基地
文章浏览阅读7k次,点赞8次,收藏28次。市场上的Android应用都能够自动提示升级更新,这里就完整的来实现一下AndroidAPP,实现自动升级的功能。Demo地址:具体如何实现,其实不难,先看看流程:本地AndroidApp必须要先有一个版本号用于标识当前版本,再从服务器获取服务器最新版本,进行相比较。实现流程:1、Manifest.xml添加联网权限,读写SD卡权限,版本号version_android在线升级服务器搭建
随便推点
使用pako.js压缩、解压数据-程序员宅基地
文章浏览阅读4.7k次。pako.js压缩和解压请求参数和响应数据_pako.js
markdown模板(个人使用)_markdown 模板-程序员宅基地
文章浏览阅读4.8k次,点赞6次,收藏25次。自用CSDN的markdown模板_markdown 模板
Playing with a Freight robot: Part 1-程序员宅基地
文章浏览阅读78次。1. Freight robotThe Fetch and Freight Research Edition Robots are indoor laboratory robots.Coordinate SystemThe coordinate frames for all links in the Fetch and Freight are defined with pos...
linux编程常用指令_linux实现代码的指令-程序员宅基地
文章浏览阅读154次。一、网络函数(1)htons(2)inet_addr 点格式转换为无符号长整型 ina.sin_addr.s_addr = inet_addr("132.241.5.10");(3)inet_ntoa 无符号长整型转换为点格式 struct in_addr addr1; ulong l1; l1= inet_addr("192.168.0.74"..._linux实现代码的指令
memmove函数_void *memmove(void *dest, const void *src, size_t -程序员宅基地
文章浏览阅读1.1k次。在这个例子中,字符串"hello world!"被移动,使得输出为 “hello hello world!是一个标准库函数,用于 C++ 中的内存操作。它主要用于在内存中移动或复制字节。可以处理源内存区和目标内存区重叠的情况。如果源内存区和目标内存区重叠,此函数会返回指向目标内存区的指针。仍然可以正确地复制字节,而。_void *memmove(void *dest, const void *src, size_t n);
2013最新版Subversion 1.7.10 for Windows x86 + Apache 2.4.4 x64 安装配置教程+错误解决方案...-程序员宅基地
文章浏览阅读140次。一 、工作环境 操作系统:Windows Server 2008 R2 SP1 x64 Apache版本:2.4.4 Subversion版本: Setup-Subversion-1.7.10.msi TortoiseSVN版本:TortoiseSVN-1.7.13.24257-x64-svn-1.7.10.msi +LanguagePack_1.7.13.24257..._windows subversion x64