Java基础篇 | Java基础语法-程序员宅基地
技术标签: jvm Java从入门到精通 java 开发语言

作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人
个人主页:Leo的博客
当前专栏: Java从入门到精通
特色专栏: MySQL学习
本文内容:Java基础篇 | Java基础语法
️个人小站 :个人博客,欢迎大家访问
个人知识库: 知识库,欢迎大家访问
前言
Java以前自学过一写,现在工作了,时间太久有一些知识都遗忘了,今天开始就更新Java了,想着把之前的Java基础知识捡起来;从最基础的开始,打好Java基础,便于以后复习。也欢迎大家跟我一起复习。
1.1 注释(annotation)(掌握)
-
注释:就是对代码的解释和说明。其目的是让人们能够更加轻松地了解代码。为代码添加注释,是十分必须要的,它不影响程序的编译和运行。
-
Java中有
单行注释、多行注释和文档注释-
单行注释以
//开头,以换行结束,格式如下:// 注释内容 -
多行注释以
/*开头,以*/结束,格式如下:/* 注释内容 */ -
文档注释以
/**开头,以*/结束,Java特有的注释,结合/** 注释内容 *///单行注释 /* 多行注释 */ /** 文档注释演示 @author gaoziman */ public class Comments{ /** Java程序的入口 @param String[] args main方法的命令参数 */ public static void main(String[] args){ System.out.println("hello"); } }
-
常见的几个注释:
- @author 标明开发该类模块的作者,多个作者之间使用,分割
-
@version 标明该类模块的版本
-
@see 参考转向,也就是相关主题
-
@since 从哪个版本开始增加的
-
@param 对方法中某参数的说明,如果没有参数就不能写(后面再学)
-
@return 对方法返回值的说明,如果方法的返回值类型是void就不能写(后面再学)
-
@throws/@exception 对方法可能抛出的异常进行说明 ,如果方法没有用throws显式抛出的异常就不能写(后面再学)
其中 @param @return 和 @exception 这三个标记都是只用于方法的。
- @param的格式要求:@param 形参名 形参类型 形参说明
- @return 的格式要求:@return 返回值类型 返回值说明
- @exception 的格式要求:@exception 异常类型 异常说明
- @param和@exception可以并列多个
使用javadoc工具可以基于文档注释生成API文档。
用法: javadoc [options] [packagenames] [sourcefiles] [@files]
例如:
javadoc -author -d doc Comments.java

1.2 标识符( identifier)(掌握)
简单的说,凡是程序员自己命名的部分都可以称为标识符。
即给类、变量、方法、包等命名的字符序列,称为标识符。
Java中合法的标识符需要满足以下要求:
- 标识符可以由字母、数字、下划线(_)和美元符号($)组成,不能含有其他符号。(java支持全球所有语言,所以这里的 字母 指的是任何一个国家的语言都可以)
- 标识符不能以数字开头。
- 标识符不能是Java中的关键字,如public、class、void等。
- 标识符是区分大小写的,即Foo和foo是两个不同的标识符。
- 标识符的长度没有限制,但是Java建议使用有意义的、简短的标识符。
标识符的命名规范(建议遵守的软性规则,否则容易被鄙视和淘汰)
-
见名知意
-
类名、接口名等:每个单词的首字母都大写,形式:XxxYyyZzz,
例如:HelloWorld,String,System等
-
变量、方法名等:从第二个单词开始首字母大写,其余字母小写,形式:xxxYyyZzz,
例如:age,name,bookName,main
-
包名等:每一个单词都小写,单词之间使用点.分割,形式:xxx.yyy.zzz,
例如:java.lang
-
常量名等:每一个单词都大写,单词之间使用下划线_分割,形式:XXX_YYY_ZZZ,
例如:MAX_VALUE,PI
例如,以下是合法的标识符:
- name
- _name
- $name
- name123
- Name
- MyClassName
而以下是不合法的标识符:
- 123name(以数字开头)
- public(关键字)
- my-name(中间包含横线)
- MyClassName!(包含非法字符)
1.3 关键字(keyword)(掌握)
关键字:是指在程序中,Java已经定义好的单词,具有特殊含义。
Java关键字是Java编程语言中预定义的具有特殊含义的保留字,这些保留字不能被用作标识符或变量名,而是在语法中有特定的用法和限制。Java关键字的作用是控制程序的逻辑和结构,这些关键字通常用于声明变量、定义类、控制程序流程、实现面向对象编程等。
Java关键字的种类有很多,包括基本数据类型关键字(如int、double、boolean等)、控制流程关键字(如if、for、while等)、访问权限关键字(如public、private、protected等)、类和对象关键字(如class、new、extends、super等)、异常处理关键字(如try、catch、finally等)等。不同的关键字有不同的作用和用法,程序员需要根据具体的需求选择合适的关键字来编写代码。
Java关键字的使用规则也有一些限制,例如关键字不能作为变量名、方法名等标识符的名称,也不能在不同的上下文中使用不同的含义。因此,在编写Java代码时,程序员需要遵守Java关键字的使用规则,以保证程序的正确性和可读性。
- HelloWorld案例中,出现的关键字有
public、class、static、void等,这些单词已经被Java定义好 - 关键字的特点:全部都是
小写字母。 - 关键字比较多,不需要死记硬背,学到哪里记到哪里即可。

关键字一共50个,其中const和goto是保留字。
true,false,null看起来像关键字,但从技术角度,它们是特殊的布尔值和空值。
1.4 字面量(理解)
什么是字面量
Java中,字面量指的是在程序中直接使用的数据,字面量是Java中最基本的表达式,不需要进行计算或转换,直接使用即可。
Java中都有哪些字面量
- 整数型:10、-5、0、100
- 浮点型:3.14、-0.5、1.0
- 布尔型:true、false
- 字符型:‘a’、‘b’、‘c’、‘1’、‘2’、‘国’
- 字符串型:“Hello”、“World”、“Java”、“你好呀”
1.5 初识数据类型(data type)(掌握)
Java数据类型概述
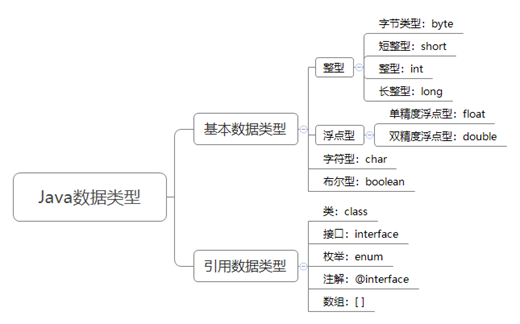
Java的数据类型分为两大类:
- 基本数据类型
- 整数类型:包括byte、short、int和long四种类型,用于表示整数。
- 浮点类型:包括float和double两种类型,用于表示带小数点的数值。
- 布尔类型:boolean类型,只有true和false两个值,用于表示逻辑值。
- 字符类型:char类型,用于表示单个字符,它是基于Unicode编码的。
- 引用数据类型
- 类、接口、数组、枚举等。(或者你也可以这样记:除了8种基本数据类型之外,其他都是引用数据类型,包括String。)
现阶段重点研究基本数据类型,以后再说引用数据类型。
下面详细介绍一下每种类型的特点和使用方法:
- 整数类型:
- byte类型:占用1个字节,范围是-128到127,常用于存储小整数。 (byte类型的1:00000001)
- short类型:占用2个字节,范围是-32768到32767,常用于存储中等大小的整数。 (short类型的1:00000000 00000001)
- int类型:占用4个字节,范围是-2147483648到2147483647,是Java中最常用的整数类型。
- long类型:占用8个字节,范围是-9223372036854775808到9223372036854775807,用于存储极大或极小的整数。
为什么设计出这么多整数?目的是合适的数据选择合适的类型,可以节省空间,但实际开发中不必斤斤计较,大部分采用int。另外,如果数据过大,超过了long,可以使用BigInteger,它就不是基本数据类型了,属于引用数据类型。后面再说。
- 浮点类型:
- float类型:占用4个字节,范围是1.4E-45到3.4028235E38,精度为7位小数,常用于科学计算和工程计算。
- double类型:占用8个字节,范围是4.9E-324到1.7976931348623157E308,精度为15位小数,是Java中最常用的浮点类型。 (如果超出了double,可以使用BigDecimal,同样它也是一种引用数据类型。)
- 布尔类型:
- boolean类型:只有两个值,true和false,用于表示逻辑值,例如判断语句、循环语句等。
- 字符类型:
- char类型:占用2个字节,用于表示单个字符,例如’A’、‘B’、'C’等,也可以表示Unicode编码中的任意字符。
这是一个直观的列表:
| 数据类型 | 占用字节数 | 取值范围 | 具体取值范围 | 默认值 |
|---|---|---|---|---|
| byte | 1 | -2^7 ~ 2^7-1 | -128 ~ 127 | 0 |
| short | 2 | -2^15 ~ 2^15-1 | -32768 ~ 32767 | 0 |
| int | 4 | -2^31 ~ 2^31-1 | -2147483648 ~ 2147483647 | 0 |
| long | 8 | -2^63 ~ 2^63-1 | -9223372036854775808 ~ 9223372036854775807 | 0L |
| float | 4 | 1.4E-45 ~ 3.4028235E38 | 1.4E-45 ~ 3.4028235E38 | 0.0f |
| double | 8 | 4.9E-324 ~ 1.7976931348623157E308 | 4.9E-324 ~ 1.7976931348623157E308 | 0.0d |
| boolean | 1 | true / false | true / false | false |
| char | 2 | 0 ~ 2^16-1 | 0 ~ 65535 | ‘\u0000’ |
关于默认值:Java语言中变量必须先声明,再赋值,才能使用。对于局部变量来说必须手动赋值,而对于成员变量来说,如果没有手动赋值,系统会自动赋默认值。例如:
public class DefaultValue {
// 成员变量有系统默认值
static int i;
public static void main(String[] args){
System.out.println(i); // 0
// 成员变量没有系统默认值
int k;
System.out.println(k); // 编译报错
}
}
注意:对于引用数据类型来说,默认值null,例如:
public class DefaultValue {
static String name;
public static void main(String[] args){
// String是引用数据类型。
System.out.println(name); // null
}
}
整数型详解
整数型字面量的四种表示形式
Java中整数型字面量有以下四种表示形式:
-
十进制表示法:以数字0-9组成的常数,默认为十进制表示法。
例如:int a = 10;
-
二进制表示法:以0b或0B开头的常数,由0和1组合而成。
例如:int b = 0b101;
-
八进制表示法:以0开头的常数,由数字0-7组成。
例如:int c = 012;
-
十六进制表示法:以0x或0X开头的常数,由0-9和A-F(大小写均可)组成。
例如:int d = 0x1F;
整数型字面量默认当做int处理
Java中整数型字面量默认被当做int类型来处理,如果要表示long类型的整数,需要在字面量后面加上’L’或’l’标记。例如,下面是表示int和long类型整数的字面量的示例:
int x = 10; // 10是一个int类型的字面量
long y = 10L; // 10L是一个long类型的字面量
需要注意的是,大小写字母’L’和’l’的使用没有区别,但是容易被误解为数字1,因此建议使用大写字母。
请看以下代码有什么问题吗?
long z = 2147483648;
编译报错,原因是2147483648被当做int类型处理,而该数字本身已经超出了int最大值,如何修改?
long z = 2147483648L;
自动类型转换
自动转换:
- 将
取值范围小的类型自动提升为取值范围大的类型。
基本数据类型的转换规则如图所示:

在Java中,对于基本数据类型来说,小容量是可以直接赋值给大容量的,这被称为自动类型转换。对于数字类型来说大小关系为:byte < short < int < long < float < double。
当把存储范围小的值(常量值、变量的值、表达式计算的结果值)赋值给了存储范围大的变量时。
int i = 'A';//char自动升级为int,其实就是把字符的编码值赋值给i变量了
double d = 10;//int自动升级为double
byte b = 127; //右边的整数常量值必须在-128~127范围内
//byte bigB = 130;//错误,右边的整数常量值超过byte范围
long num = 1234567; //右边的整数常量值如果在int范围呢,编译和运行都可以通过,这里涉及到数据类型转换
long bigNum = 12345678912L;//右边的整数常量值如果超过int范围,必须加L,否则编译不通过
(2)当存储范围小的数据类型与存储范围大的数据类型一起混合运算时,会按照其中最大的类型运算。
int i = 1;
byte b = 1;
double d = 1.0;
double sum = i + b + d;//混合运算,升级为double
(3)当byte,short,char数据类型进行算术运算时,按照int类型处理。
byte b1 = 1;
byte b2 = 2;
byte b3 = b1 + b2;//编译报错,b1 + b2自动升级为int
char c1 = '0';
char c2 = 'A';
System.out.println(c1 + c2);//113
需要注意的是,自动类型转换只适用于基本数据类型之间的转换。
强制类型转换
强制类型转换:Java中大容量是无法直接转换成小容量的。因为这种操作可能会导致精度损失,所以这种行为交给了程序员来决定,当然这种后果自然是程序员自己去承担。因此在代码中需要程序员自己亲手加上强制类型转换符,程序才能编译通过。
以下程序编译器就会报错:
int num = 10L;
解决方案两个:要么把L去掉,要么使用强制类型转换符,例如:
int num = (int)10L;
这样编译器就能编译通过了。
强制类型转换时,底层二进制是如何变化的?原则:砍掉左侧多余的二进制。例如以上程序的二进制变化是这样的:
long类型的10对应的二进制:00000000 00000000 00000000 00000000 00000000 00000000 00000000 00001010
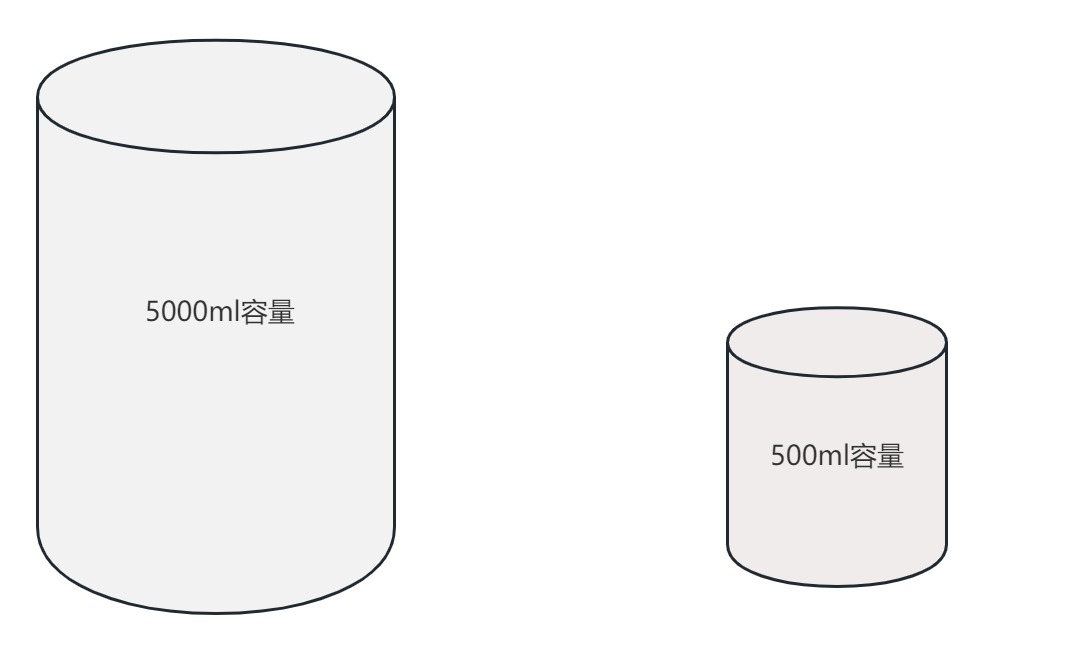
强制转换为int类型的10是这样的:00000000 00000000 00000000 00001010因此,强制类型转换时,精度可能会损失,也可能不会损失,这要看具体的数据是否真正的超出了强转后的类型的取值范围。如下图:水可能溢出,也可能不会溢出,这要看真实存放的水有多少!!!
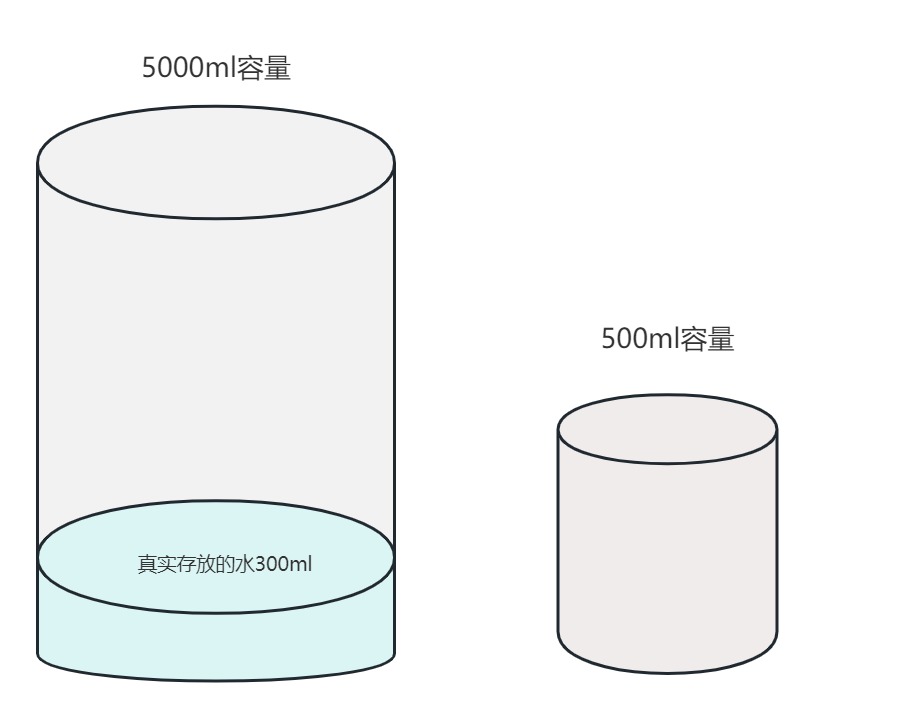
如果你理解了强制类型转换,那么下面这个程序的执行结果可以推算出来吗?
byte b = (byte)150;
int类型的150的补码(150是正数:原码反码补码一样):00000000 00000000 00000000 10010110
强转砍掉前三个多出的字节,结果是:10010110(这个是最终存储在计算机中的,注意:存储在计算机中的是补码)
将以上补码10010110推算出原码:11101010(结果是:-106)
因此int类型的150强转为byte类型之后,结果是-106
当整数字面量没有超出byte的范围
在Java中有这样一个规定,当整数型字面量没有超出byte的范围:可以直接赋值给byte类型的变量。
byte b = 127; // 这是允许的
很显然,这是一种编译优化。同时也是为了方便程序员写代码。
如果超出了范围,例如:
byte b = 128; // 编译报错
这样就会报错,需要做强制类型转换,例如:
byte b = (byte)128;
它的执行结果你知道吗?可以尝试推算一下,最终结果是:-128
在整数类型中,除了byte有这个待遇之外,short同样也是支持的。也就是说:如果整数型字面量没有超出short取值范围时,也是支持直接赋值的。
两个int类型做运算
两个int类型的数据做运算,最终的结果还是int类型:
int a = 10;
int b = 3;
int c = a / b;
System.out.println(c); // 3
多种数据类型混合运算
在Java中,多种数据类型混合运算时,各自先转换成容量最大的类型,再做运算。
byte a = 100;
int b = 200;
long c = 300L;
long d = a + b + c;
你可以测试一下,如果d变量是int类型则编译器会报错。
编译器的小心思
以下程序编译通过:
byte x = 10 / 3;
为什么编译通过?这种情况下都是字面量的时候,编译器可以在编译阶段得出结果是3,而3没有超出byte取值范围。可以直接赋值。
以下程序编译报错:
int a = 10;
int b = 3;
byte x = a / b;
为什么编译失败?这种a和b都是变量的情况下,编译器是无法在编译阶段得出结果的,编译器只能检测到结果是int类型。int类型不能直接赋值给byte类型变量。
怎么解决?要么把x变量声明为int类型,要么强制类型转换,例如:
int a = 10;
int b = 3;
byte x = (byte)(a / b);
这里需要注意的是:注意小括号的添加,如果不添加小括号,例如:
int a = 10;
int b = 3;
byte x = (byte)a / b;
这样还是编译报错,因为只是将a强转为byte了,b还是int。byte和int混合运算,结果还是int类型。
浮点型详解
浮点型类型包括:
- 单精度(float):4字节(32位)
- 双精度(double):8字节(64位),精度较高,实际开发中double用的多。
浮点型字面量默认被当做double
Java中,浮点型字面量默认被当做double类型,如果要当做float类型,需要在数字后面添加 F 或 f。
float f = 3.0; // 编译报错
报错原因是:3.0默认被当做double类型,大容量无法直接赋值给小容量。如何修改:
float f = 3.0F;
另外,可以通过以下程序的输出结果看到,double精度高于float:
double d = 1.5656856894;
System.out.println(d);
float f = 1.5656856894F;
System.out.println(f);
浮点型数据两种表示形式
第一种形式:十进制
double x = 1.23;
double y = 0.23;
double z = .23;
第二种形式:科学计数法
double x = 0.123E2; // 0.123 * 10的平方
double y = 123.34E-2; // 123.34 / 10的平方
浮点型数据存储原理
以单精度float为例:
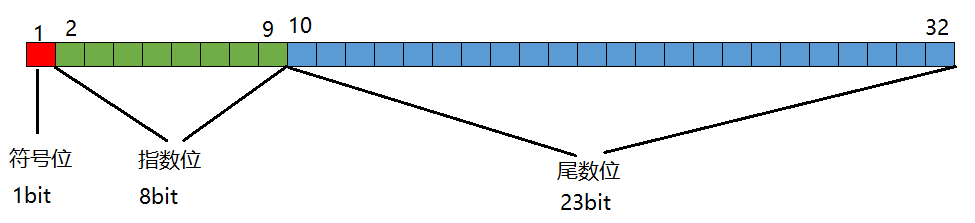
符号位:0表示整数。1表示负数。
指数位:比如小数0.123E30,其中30就是指数。表示0.123 * 10的30次幂。所以也有把指数位叫做偏移量的。最大偏移量127。
尾数位:浮点数的小数部分的有效数字。例如:0.00123,那么尾数位存储123对应的二进制。
从浮点型数据存储原理上可以看到,二进制中的指数位决定了数字呈指数级增大。因此float虽然是4个字节,但却可以表示比long更大的数值。因此float容量比long的容量大。
使用浮点数的注意事项
计算机的二进制位有限,现实世界中有无限循环的数字,例如3.333333333333333333…,因此计算机这种有限资源去存储无限数据是不可能的,所以浮点型数据在底层真实存储的时候都是采用近似值的方式存储的。尾数位越多精度越高。
实际上包括0.1这样简单的数字,浮点型数据也是无法精确存储的。(想了解更多,请查看相关文献)
这样就会有一个问题,请看以下程序:
double x = 6.9;
double y = 3.0;
double z = x / y;
System.out.println(z);
它的执行结果是:2.3000000000000003
并不是2.3
因此一旦有浮点型数据参与运算得出的结果,一定不要使用“==”与其它数字进行“相等比较”。例如,以下代码就存在问题:
double x = 6.9;
double y = 3.0;
double z = x / y;
if(z == 2.3){
System.out.println("相等");
}
执行发现并没有输出:相等。
原因是判断条件有问题。
如果确实需要进行比较,可以将代码修改为如下:
double x = 6.9;
double y = 3.0;
double z = x / y;
if(z - 2.3 < 0.000001){
System.out.println("相等");
}
也就是说,如果这两个数字之间的差小于0.000001,我就认为是相等的。
因此:如果有浮点型数据参与运算得出了结果,不要拿着这个结果和另一个数据进行“==”相等比较。
字符型详解
字符型详解
char:字符型,占用2个字节。取值范围065535。和short(-3276832767)所表示的个数相同。但char可以表示更大的整数。
字符型字面量采用单引号括起来,例如:‘a’、‘A’、‘0’、‘国’ 等。
字符型字面量只能是单个字符,不能是多个字符。
Java中char类型可以存储一个汉字。
char c1 = 'A';
char c2 = 'a';
char c3 = '0';
char c4 = '国';
char c5 = '¥';
// 编译报错
//char c6 = 'ab';
再看下面程序:
char x = '';
编译报错。由于单引号中没有任何字符,因此无法给 c 赋值,所以会导致编译报错,提示无效的字符字面量。
如果要赋给 c 一个空的字符,可以使用转义字符 ‘\u0000’ 来表示。如下所示:
char c = '\u0000'; // 赋给 c 一个空字符
注意:空字符与空格字符完全是两码事。
转义字符
Java 中的转义字符是一些在字符串中具有特殊含义的字符序列,它们以反斜线(\)开始。以下是 Java 中的一些常用转义字符:
- \t: 表示制表符,相当于按下 Tab 键
- \n: 表示换行符
- \r: 表示回车符
- “: 表示双引号(”)
- ‘: 表示单引号(’)
- \: 表示反斜线(\)本身
这些转义序列可以用于不同的 Java 数据类型,如字符串、字符等。在 Java 编程中,转义字符可以帮助我们在字符串中表示一些特殊的字符,例如制表符、换行符、引号等。例如,下面的代码演示了如何使用转义字符来创建包含制表符和换行符的字符串:
String str = "Hello\tworld\nHow are you?";
System.out.println(str);
这个例子中,\t 和 \n 分别表示字符串中的制表符和换行符。输出结果是:
Hello world
How are you?
字符编码的理解
字符编码(Character encoding)是计算机系统中使用的一种将字符集中的字符转换为二进制数据的方式,从而方便计算机的存储和传输。在计算机内部,所有的信息都是以二进制形式存储和处理的,因此字符编码是将字符和二进制数据之间的转换方式。每一个字符在计算机中都有其对应的二进制代码。不同的字符编码可以采用不同的编码方式将字符映射到二进制代码,最终这些二进制代码被存储在计算机内部。
在早期计算机系统中,字符编码主要采用的是 ASCII 编码,采用1个字节编码。最多可以表示256个字符。(实际上ASCII码表只用了128个。)
以下是ASCII码表:
| 十进制 | 字符 | 十进制 | 字符 | 十进制 | 字符 | 十进制 | 字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUL | 32 | SPACE | 64 | @ | 96 | ` |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | " | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | ’ | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DC1 | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | ETB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | |124 | ||
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ~ |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
作为程序员,我们应当记住以下几个常用字符的ASCII码:
- a 对应ASCII码 97(b是98,以此类推)
- A 对应ASCII码 65(B是66,以此类推)
- 0 对应ASCII码 48(1是49,以此类推)
什么是解码?什么是编码?乱码是如何产生的?
在计算机系统中,解码(Decoding)和编码(Encoding)是两个常用的概念,分别表示将二进制数据转换为字符和将字符转换为二进制数据。
编码是将字符转换为二进制数据的过程。解码是将二进制数据转换为字符的过程。例如:
- ‘a’ ---------按照ASCII码表编码-----------> 01100001
- 01100001 --------按照ASCII码表解码------------> ‘a’
乱码是指在字符编码和解码的过程中,由于编码和解码所采用的字符集不一致,或者编码和解码所采用的字符集不支持某些字符,导致最终显示的字符与原始字符不一致。为了避免乱码的问题,我们需要统一使用一个字符集,并且在进行字符编码和解码时要保持一致。
常见的字符编码
常见的字符编码方式如下:
- ASCII 编码(American Standard Code for Information Interchange:美国信息交换标准编码):采用1个字节编码,包括字母、数字、符号和控制字符等。
- Latin-1编码(ISO 8859-1),采用1个字节编码。该编码方式是为了表示欧洲语言(如荷兰语、西班牙语、法语、德语等)中的字符而设计的,共支持 256 个字符。
- ANSI 编码(American National Standards Institute:美国国家标准协会):采用1个字节编码,支持英文、拉丁文等字符。
- Unicode 编码:可表示所有语言的字符。采用了十六进制表示,占用 2 个字节或 4 个字节,最多可表示超过一百万个字符。 (使用这种方式是有点浪费空间的,例如英文字符’a’其实采用一个字节存储就够了。)
- UTF-8 编码(Unicode Transformation Format,8-bit):基于 Unicode 编码的可变长度字符编码,能够支持多语言和国际化的需求,使用 1~4 个字节来表示一个字符,是目前 Web 开发中最常用的字符编码方式。 (一个英文字母1个字节,一个汉字3个字节。)
- UTF-16 编码:基于 Unicode 编码的可变长度字符编码,使用 2 或 4 个字节来表示一个字符,应用于很多较早的系统和编程语言中。 (一个英文字母2个字节。一个汉字4个字节。)
- UTF-32编码:基于Unicode编码的固定长度字符编码,其特点是每个字符占用4个字节。
- GB2312 编码(小):是中国国家标准的简体中文字符集,使用 2 个字节来表示一个汉字,是 GBK 编码的前身。
- GBK 编码(Guo Biao Ku)(中):是针对中文设计的一个汉字编码方式,使用 2 个字节来表示一个汉字,能够表示中国内地的所有汉字。
- GB18030编码(大):是中国国家标准GB 18030-2005《信息技术 中文编码字符集》中规定的字符集编码方案,用于取代GB2312和GBK编码。
- Big5 编码(大五码):是台湾地区的繁体中文字符集,使用 2 个字节来表示一个汉字,适用于使用繁体中文的应用场景。
每种编码方式都有其特点和适用场景。在进行软件开发、网站开发和数据存储时,需要根据实际情况选择适合的编码方式。
注意:Java语言中的字符char和字符串String,都是采用Unicode编码。
Unicode码表
Unicode码表示的一部分:
| 十六进制码 | 字符 | 名称 | 符号 |
|---|---|---|---|
| U+0020 | 空格 | (space) | |
| U+0021 | ! | 感叹号 | (exclamation mark) |
| U+0022 | " | 双引号 | (quotation mark) |
| U+0023 | # | 井号 | (number sign) |
| U+0024 | $ | 美元 | (dollar sign) |
| U+0025 | % | 百分号 | (percent sign) |
| U+0026 | & | 和号 | (ampersand) |
| U+0027 | ’ | 单引号 | (apostrophe) |
| U+0028 | ( | 左括号 | (left parenthesis) |
| U+0029 | ) | 右括号 | (right parenthesis) |
| U+002A | * | 星号 | (asterisk) |
| U+002B | + | 加号 | (plus sign) |
| U+002C | , | 逗号 | (comma) |
| U+002D | - | 减号 | (hyphen,-minus sign) |
| U+002E | . | 句点 | (full stop,period) |
| U+002F | / | 斜杠 | (slash,forward slash) |
| U+0030 | 0 | 零 | (digit zero) |
| U+0031 | 1 | 一 | (digit one) |
| U+0032 | 2 | 二 | (digit two) |
| U+0033 | 3 | 三 | (digit three) |
| U+0034 | 4 | 四 | (digit four) |
| U+0035 | 5 | 五 | (digit five) |
| U+0036 | 6 | 六 | (digit six) |
| U+0037 | 7 | 七 | (digit seven) |
| U+0038 | 8 | 八 | (digit eight) |
| U+0039 | 9 | 九 | (digit nine) |
| U+003A | : | 冒号 | (colon) |
| U+003B | ; | 分号 | (semicolon) |
| U+003C | < | 小于号 | (less than sign) |
| U+003D | = | 等于号 | (equals sign) |
| U+003E | > | 大于号 | (greater than sign) |
| U+003F | ? | 问号 | (question mark) |
| U+0040 | @ | 艾特符号 | (commercial at) |
| U+0041 | A | 拉丁大写字母A | (Latin capital letter A) |
| U+0042 | B | 拉丁大写字母B | (Latin capital letter B) |
| U+0043 | C | 拉丁大写字母C | (Latin capital letter C) |
| U+0044 | D | 拉丁大写字母D | (Latin capital letter D) |
| U+0045 | E | 拉丁大写字母E | (Latin capital letter E) |
| U+0046 | F | 拉丁大写字母F | (Latin capital letter F) |
| U+0047 | G | 拉丁大写字母G | (Latin capital letter G) |
在Java程序中也可以使用Unicode码来指定char变量的值:
char c = '\u0041';
输出结果是:A
网络上也有很多在线转码工具,例如:http://www.jsons.cn/unicode/
char参与的运算
Java中允许将一个整数赋值给char类型变量,但这个整数会被当做ASCII码值来处理,例如:
char c = 97;
System.out.println(c);
会将97当做ASCII码值,该码值转换char类型是字符’a’,所以输出结果是:a
但需要特别注意的是,这个码值有要求,不能超出char的取值范围。如果是这样的,编译会报错:
// 编译报错
char c = 65536;
所以结合之间的byte和short,可以有这样一个结论(记住):只要没有超出byte short char的取值范围,是可以直接赋值给byte short char类型变量的。例如:
byte b = 1;
short s = 1;
char c = 1;
再看以下程序输出结果:
System.out.println('a' + 1);
输出结果是:98。这是因为1是int类型,所以’a’会被转换为int类型。
再看以下程序输出结果:
char c = 'a' + 1;
System.out.println(c);
输出结果是:b。这是因为c的类型是char类型。
再看以下程序输出结果:
byte b = 1;
short s = 1;
char c = 1;
short num = b + s + c;
编译报错:第4行的等号右边是int类型,int类型无法赋值给short类型的变量。
这里有一个结论需要记住:byte short char混合运算时,各自会先转换成int再做运算。
布尔型详解
关于布尔型的值
Java中的布尔型,关键字:boolean
只有两个值:true、false。没有1和0这一说。
true表示真,false表示假。
布尔值通常使用在哪
Java中的布尔值(boolean)通常用于表示一些逻辑上的真假值,并在程序中进行逻辑控制。以下是布尔值在Java中常用的场景:
- 条件语句,if和while等语句中需要进行条件判断时,通常使用布尔类型的变量作为条件表达式,根据条件的真假情况执行不同的代码逻辑。
- 逻辑运算,布尔值是逻辑运算的基础,Java中的逻辑运算符有:与(&&)、或(||)、非(!)等,常用于对布尔值的运算和操作。
- 方法返回值,可以将布尔值作为方法的返回值,表示某种条件是否满足。
- 开关标记,布尔变量在程序中常用于开关标记的判断和设置,例如,当某个功能开启或关闭时,我们可以用布尔类型的变量来表示。
综上所述,Java中的布尔值在程序中有很多用途,可以在很多场景下提供非常便利的逻辑控制和判断能力。
下面是一个使用布尔值的简单案例:
boolean gender = true;
if(gender){
System.out.println("男");
}else{
System.out.println("女");
}
基本数据类型转换规则总结
- 八种基本数据类型,除布尔型之外,其它类型都可以互相转换。
- 小容量转换为大容量,叫做自动类型转换,容量从小到大的排序为:
- byte < short(char) < int < long < float < double
- 注意char比short可以表示更大的整数
- 大容量转换为小容量,叫做强制类型转换,需要加强制类型转换符才能编译通过,运行时可能损失精度,也可能不会损失。
- 整数字面量如果没有超出byte short char的取值范围,可以直接赋值给byte short char类型的变量。
- byte short char混合运算,各自先转换为int再做运算。
- 多种类型混合运算,各自先转换成容量最大的类型,再做运算。
变量和数据类型的作业题
-
请定义合理的变量用来存储个人信息(姓名、年龄、性别、联系电话),并编写程序定义这些变量,给变量赋值,并打印输出。输出效果如下:
姓名 年龄 性别 联系电话
张三 20 男 12545457585
李四 30 女 15622525855 -
有两个变量 a 和 b,a 变量中存储的数据100,b 变量中存储的数据200,请编写程序交换两个变量中的数据。让a变量存储200,让b变量存储100。并且计算两个int类型数据的和,要求最终输出 200+100=300的效果。
-
请分析以下程序中哪些是可以编译通过的,哪些是报错的
short s = 100; s = s - 99; byte b = 100; b = b + 1; char c = 'a' int i = 20; float f = .3F; double d = c + i + f; byte b = 11; short s = 22; short x = b + s;
1.6 常量值(constant)(掌握)
-
常量值:在程序执行的过程中,其值不可以发生改变
-
常量值的分类:
类型 举例 整数常量值 12,-23, 1567844444557L 浮点常量值 12.34F,12.34 字符常量值 ‘a’,‘0’,‘高’ 布尔常量值 true,false 字符串常量值 ”HelloWorld“
- 整数常量值,超过int范围的必须加L或l(小写L)
- 小数常量值,无论多少,不加F,就是double类型。要表示float类型,必须加F或f
- char常量值,必须使用单引号
- String字符串常量值,必须使用双引号
public class ConstantDemo {
public static void main(String[] args) {
//输出整数常量值
System.out.println(12);
System.out.println(-23);
System.out.println(2352654566L);
//输出小数常量值
System.out.println(12.34F);
System.out.println(12.34);
//输出字符常量值
System.out.println('a');
System.out.println('0');
System.out.println('尚');
//输出布尔常量值
System.out.println(true);
System.out.println(false);
//输出字符串常量值
System.out.println("HelloWorld");
}
}
1.7 变量(variable)(掌握)
1.7.1 什么是变量
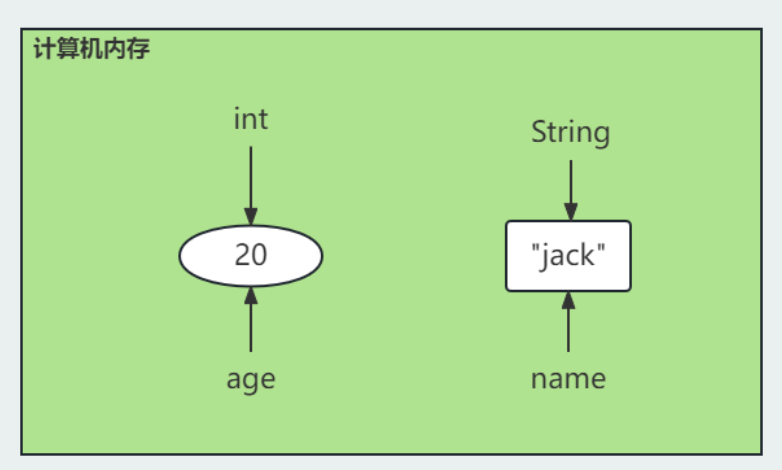
变量可以看做是一个盒子,这个盒子可以存储数据。本质上,变量是内存当中的一块空间,这块空间有三要素(变量的三要素):
- 要素一:数据类型(决定了空间大小)。例如有一种数据类型叫做整数型:int
- 要素二:名字(只要是合法的标识符就行)。例如:age(年龄)
- 要素三:值(盒子中具体存储的数据)。例如:20
例如以下代码则表示声明了一个整数类型的变量age,值为20
int age = 20;
以及以下代码则表示声明了一个字符串类型的变量name,值为"jack"
String name = "jack";
数据类型后面小节会详细讲解。目前只需要知道int代表整数类型,String代表字符串类型即可。
另外,变量的“变”体现在哪里呢?体现在变量这个盒子中的数据是可以改变的。例如,通过“=”赋值运算符,可以改变盒子中存储的数据:
age = 30;
这个操作用专业术语表达叫做:给变量重新赋值。
重新赋值时也是有要求的,值的类型要和变量的类型一致,不然就会报错,例如:
age = "30";
报错信息如下:
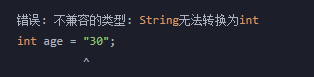
编译器找到等号右边的数据,发现是String类型,然后发现age这个盒子只能存储int类型,类型不匹配,表示这种int盒子不能存放String类型的数据。
1.7.2 变量的作用
有这样一个需求:请用你当前所学知识,分别计算100和111、222、666、888、999的和,你该怎么编写代码?
System.out.println(100 + 111);
System.out.println(100 + 222);
System.out.println(100 + 666);
System.out.println(100 + 888);
System.out.println(100 + 999);
现在需求变化了,要求计算234和111、222、666、888、999的和,你需要将以上代码中所有的100全部进行修改:
System.out.println(234 + 111);
System.out.println(234 + 222);
System.out.println(234 + 666);
System.out.println(234 + 888);
System.out.println(234 + 999);
修改了5个位置,如果求和的数据更多,那么修改的位置也会更多,显然:可维护性太差。怎么解决?使用变量可以解决。
int num = 100;
System.out.println(num + 111);
System.out.println(num + 222);
System.out.println(num + 666);
System.out.println(num + 888);
System.out.println(num + 999);
如果需求变化了,只需要修改一个位置即可:
int num = 234;
System.out.println(num + 111);
System.out.println(num + 222);
System.out.println(num + 666);
System.out.println(num + 888);
System.out.println(num + 999);
通过以上内容的学习,可以得知,变量的存在,可以让程序更加易维护。
再比如,又有这样一个需求:现在有三个圆,半径分别是10cm,20cm,30cm,π取值3.14,请分别计算他们的面积,如果不使用变量,程序是这样的:
System.out.println(3.14 * 10 * 10); // 314
System.out.println(3.14 * 20 * 20); // 1256
System.out.println(3.14 * 30 * 30); // 2826
上面程序存在的最大问题就是:可读性太差。使用变量可以提高程序的可读性:
double π = 3.14;
int r1 = 10;
int r2 = 20;
int r3 = 30;
System.out.println(π * r1 * r1);
System.out.println(π * r2 * r2);
System.out.println(π * r3 * r3);
因此变量的出现可以提高程序的可读性。
1.7.3 变量的声明
数据类型 变量名;
例如:
//存储一个整数类型的年龄
int age;
//存储一个小数类型的体重
double weight;
//存储一个单字符类型的性别
char gender;
//存储一个布尔类型的婚姻状态
boolean marry;
//存储一个字符串类型的姓名
String name;
//声明多个同类型的变量
int a,b,c; //表示a,b,c三个变量都是int类型。
注意:变量的数据类型可以是基本数据类型,也可以是引用数据类型。
1.7.4 变量的赋值
给变量赋值,就是把“值”存到该变量代表的内存空间中。
1、变量赋值的语法格式
变量名 = 值;
- 给变量赋值,变量名必须在=左边,值必须在=右边
- 给变量赋的值类型必须与变量声明的类型一致或兼容(<=)
2、可以使用合适类型的常量值给变量赋值
int age = 18;
double weight = 44.4;
char gender = '女';
boolean marry = true;
String name = "Cisyam";
long类型:如果赋值的常量整数超过int范围,那么需要在数字后面加L。
float类型:如果赋值为常量小数,那么需要在小数后面加F。
char类型:使用单引号’’
String类型:使用双引号""
3、可以使用其他变量或者表达式给变量赋值
int m = 1;
int n = m;
int x = 1;
int y = 2;
int z = 2 * x + y;
1.7.5 变量值的输出
//输出变量的值
System.out.println(age);
//输出变量的值
System.out.println("年龄:" + age);
System.out.println("age:" + age);
System.out.println("name" + name + ",age = " + age + ",gender = " + gender + ",weight = " + weight + ",marry = " + marry);
如果()中有多项内容,那么必须使用 + 连接起来
如果某些内容想要原样输出,就用"“引起来,而要输出变量中的内容,则不要把变量名用”"引起来
1.7.6 变量可以反复赋值
- 变量的第一次赋值称为初始化;
- 变量的再赋值称为修改变量的值;
//先声明,后初始化
char gender;
gender = '女';
//声明的同时初始化
int age = 18;
System.out.println("age = " + age);///age = 18
//给变量重新赋值,修改age变量的值
age = 19;
System.out.println("age = " + age);//age = 19
1.7.7 变量的三要素
1、数据类型
- 变量的数据类型决定了在内存中开辟多大空间
- 变量的数据类型也决定了该变量可以存什么值
2、变量名
- 见名知意非常重要
3、值
-
基本数据类型的变量:存储数据值
-
引用数据类型的变量:存储地址值,即对象的首地址。例如:String类型的变量存储的是字符串对象的首地址(关于对象后面章节再详细讲解)
1.7.8 变量的使用应该注意什么?
1、先声明后使用
int age;
System.out.println(age); // 报错,原因是变量age没有赋值
如果没有声明,会报“找不到符号”错误
2、在使用之前必须初始化
如果没有初始化,会报“未初始化”错误
3、变量有作用域
如果超过作用域,也会报“找不到符号”错误
4、在同一个作用域中不能重名
5、变量值的类型必须与变量声明的类型一致或兼容(<=)
一致:一样
int age = 18; 18是int类型的常量值,age也是int类型
兼容:可以装的下,=右边的值要 小于等于 =左边的变量类型
long bigNum =18; 18是int类型的常量值,bigNum是long类型
int < long
int age = 18L; 错误 18L是long类型的常量值,age是int类型
long > int
1.7.9 变量的作用域
什么是变量作用域
作用域就是变量的有效范围。变量的作用域是怎样的呢?用一句大白话就可以概括了:出了大括号就不认识了。
public class MyClass {
static int e = 100;
public static void main(String[] args){
int i = 100;
System.out.println(i);
for(int k = 0; k < 10; i++){
int f = 100;
}
// 这里是无法访问f变量的
System.out.println(f);
// 这里是可以访问e的
System.out.println(e);
}
public static void m(){
// 这里无法访问main方法中的i
System.out.println(i);
}
}
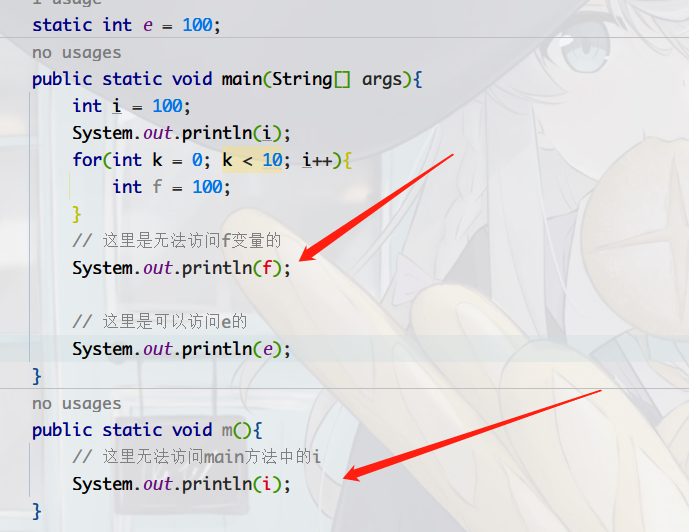
作用域的不同主要是因为声明在不同位置的变量具有不同的生命周期。所谓的生命周期是:从内存开辟到内存释放。
Java的就近原则
public class MyClass {
static int num = 10;
public static void main(String[] args){
int num = 200;
// 输出结果是200,这就是就近原则。
System.out.println(num);
}
}
1.7.10 变量的分类
Java中的变量可以按照作用域的不同划分为以下几类:
- 局部变量:定义在方法、语句块、形式参数中的变量。
- 成员变量:定义在类中,但在方法之外的变量。
- 静态变量:使用static关键字定义的变量。
- 实例变量:没有使用static关键字定义的变量。
1.8 最终变量/常量(final)
最终变量习惯上也称为常量,因为它是通过在声明变量的数据类型前面加final的方式实现的,所以叫最终变量。加final修饰后,这个变量的值就不能修改了,一开始赋值多少,就是多少,所以此时的变量名通常称为常量名。常量名通常所有字母都大写,每一个单词之间使用下划线分割,从命名上和变量名区分开来。
这样做的好处,就是可以见名知意,便于维护。
public class FinalVariableDemo {
public static void main(String[] args){
//定义常量
final int FULL_MARK = 100;//满分
// FULL_MARK = 150;//错误,final修饰的变量,是常量,不能重新赋值
//输出常量值
System.out.println("满分:" + FULL_MARK);
//小王的成绩比满分少1分
int wang = FULL_MARK - 1;
//小尚得了满分
int shang = FULL_MARK;
//小刘得了一半分
int liu = FULL_MARK/2;
//输出变量值
System.out.println("小王成绩:" + wang);
System.out.println("小李成绩:" + shang);
System.out.println("小刘成绩:" + liu);
}
}
1.9 计算机如何存储数据
计算机世界中只有二进制。那么在计算机中存储和运算的所有数据都要转为二进制。包括数字、字符、图片、声音、视频等。
1.9.1 进制(了解)
1、进制的分类
-
十进制:
- 数字组成:0-9
- 进位规则:逢十进一
-
二进制:
- 数字组成:0-1
- 进位规则:逢二进一
十进制的256,二进制:100000000,为了缩短二进制的表示,又要贴近二进制,在程序中引入八进制和十六进制
-
八进制:很少使用
- 数字组成:0-7
- 进位规则:逢八进一
与二进制换算规则:每三位二进制是一位八进制值
-
十六进制
- 数字组成:0-9,a-f
- 进位规则:逢十六进一
与二进制换算规则:每四位二进制是一位十六进制值
2、进制的换算
| 十进制 | 二进制 | 八进制 | 十六进制 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 10 | 2 | 2 |
| 3 | 11 | 3 | 3 |
| 4 | 100 | 4 | 4 |
| 5 | 101 | 5 | 5 |
| 6 | 110 | 6 | 6 |
| 7 | 111 | 7 | 7 |
| 8 | 1000 | 10 | 8 |
| 9 | 1001 | 11 | 9 |
| 10 | 1010 | 12 | a或A |
| 11 | 1011 | 13 | b或B |
| 12 | 1100 | 14 | c或C |
| 13 | 1101 | 15 | d或D |
| 14 | 1110 | 16 | e或E |
| 15 | 1111 | 17 | f或F |
| 16 | 10000 | 20 | 10 |
-
**十进制数据转成二进制数据:**使用除以2倒取余数的方式

-
二进制数据转成十进制数据:
从右边开始依次是2的0次,2的1次,2的2次。。。。

-
二进制数据转八进制数据
从右边开始,三位一组

-
二进制数据转十六进制数据
从右边开始,四位一组

十进制转换为二进制
要将一个十进制数转换为二进制数,可以使用以下步骤:
- 将十进制数除以2,得到商和余数。
- 将余数记录下来,然后将商作为新的十进制数,重复步骤1,直到商为0为止。
- 将记录的余数从下往上排列,得到的就是对应的二进制数。
例如,将十进制数27转换为二进制数:
27 ÷ 2 = 13 … 1
13 ÷ 2 = 6 … 1
6 ÷ 2 = 3 … 0
3 ÷ 2 = 1 … 1
1 ÷ 2 = 0 … 1
所以27的二进制数为11011。
二进制转换为十进制
将二进制数每一位权值找出来,然后每个权值与对应二进制位相乘,最后将它们相加,即可得到十进制数。
什么是权值?
在二进制中,权值指的是每个位所代表的数值大小,即二进制中每个位的位置所代表的数值大小。例如,在二进制数1101中,最高位的权值为8,次高位的权值为4,第三位的权值为2,最低位的权值为1。
例如,二进制数1101转换为十进制数的计算过程如下:
1×2³ + 1×2² + 0×2¹ + 1×2⁰ = 8 + 4 + 0 + 1 = 13
因此,二进制数1101转换为十进制数为13。
练习一下
将以下十进制的数字转换为二进制:
- 243:11110011
- 165
- 89
将以下二进制的数字转换为十进制:
- 101010
- 111100
- 011001
十进制转换为八进制
将十进制数除以8,直到商为0,然后将每次的余数从下往上排列即为该十进制数的八进制表示。
例如,将十进制数27转换为八进制:
27 ÷ 8 = 3 … 3
3 ÷ 8 = 0 … 3
所以27的八进制表示为33。
八进制转换为十进制
八进制转换为十进制的方法如下:
- 将八进制数的每一位按权展开,权值分别为8的0次方、8的1次方、8的2次方,以此类推。
- 将每一位的值乘以对应的权值,然后将所有结果相加。
例如,将八进制数 346 转换为十进制数:
3×8^2 + 4×8^1 + 6×8^0 = 3×64 + 4×8 + 6×1 = 198
因此,八进制数 346 转换为十进制数为 198。
十进制转换为十六进制
- 首先将十进制数除以16,得到商和余数。
- 将余数转换为对应的十六进制数,如果余数小于10,则直接写下来,否则用A、B、C、D、E、F表示10、11、12、13、14、15。
- 将商作为新的十进制数,重复步骤1和2,直到商为0为止。
- 将每一步得到的十六进制数倒序排列,即为最终的十六进制数。
例如,将十进制数255转换为十六进制数:
- 255 ÷ 16 = 15 余 15
- 余数15对应的十六进制数为F,所以最后一位为F。
- 15 ÷ 16 = 0 余 15
- 余数15对应的十六进制数为F,所以第二位为F。
- 最终的十六进制数为FF。
十六进制转换为十进制
将十六进制转换为十进制的方法是将每一位的十六进制数值乘以对应的权值,再将各位的结果相加。
例如,将十六进制数ABCD转换为十进制数:
- 将A、B、C、D分别转换为对应的十进制数值,即10、11、12、13。
- 根据十六进制的权值规则,从右往左依次乘以16的0次方、1次方、2次方、3次方,即1、16、256、4096。
- 将各位的乘积相加,即:13×1 + 12×16 + 11×256 + 10×4096 = 43981。
- 所以,十六进制数ABCD转换为十进制数为43981。
另一种简便的方法是,将十六进制数中的每一位转换为4位的二进制数,再将这些二进制数转换为十进制数,最后将各位的结果相加。
二进制转换为十六进制
二进制转换为十六进制的方法如下:
- 将二进制数从右往左每四位一组,不足四位则在左侧补0,得到若干个四位二进制数。
- 将每个四位二进制数转换为对应的十六进制数,可以使用下表进行转换:
| 二进制数 | 十六进制数 |
|---|---|
| 0000 | 0 |
| 0001 | 1 |
| 0010 | 2 |
| 0011 | 3 |
| 0100 | 4 |
| 0101 | 5 |
| 0110 | 6 |
| 0111 | 7 |
| 1000 | 8 |
| 1001 | 9 |
| 1010 | A |
| 1011 | B |
| 1100 | C |
| 1101 | D |
| 1110 | E |
| 1111 | F |
- 将每个四位二进制数对应的十六进制数按照从左往右的顺序排列,得到最终的十六进制数。
例如,将二进制数1101011010111011转换为十六进制数:
- 从右往左每四位一组,得到1101 0110 1011 1011。
- 将每个四位二进制数转换为对应的十六进制数,得到D 6 B B。
- 将每个四位二进制数对应的十六进制数按照从左往右的顺序排列,得到最终的十六进制数:D6BB。
十六进制转换为二进制
将每个十六进制数位转换为四位二进制数即可。
例如:将十六进制数 AF 转换为二进制数。
A 对应的二进制数为 1010,F 对应的二进制数为 1111,因此 AF 对应的二进制数为 10101111
3、在代码中如何表示四种进制的常量值
请分别用四种类型的进制来表示10,并输出它的结果:(了解)
-
十进制:正常表示
System.out.println(10);
-
二进制:0b或0B开头
System.out.println(0B10);
-
八进制:0开头
System.out.println(010);
-
十六进制:0x或0X开头
System.out.println(0X10);
1.9.2 计算机存储单位(掌握)
-
**字节(Byte):**是计算机信息技术用于计量存储容量的一种计量单位,一字节等于八位。
-
**位(bit):**是数据存储的最小单位。也就是二进制。二进制数系统中,每个0或1就是一个位,叫做bit(比特),其中8 bit 就称为一个字节(Byte)。
-
转换关系:
- 8 bit = 1 Byte
- 1024 Byte = 1 KB
- 1024 KB = 1 MB
- 1024 MB = 1 GB
- 1024 GB = 1 TB
1.9.3 Java的基本数据类型的存储范围(掌握)

float:单精度浮点型,占内存:4个字节,精度:科学记数法的小数点后6~7位
double:双精度浮点型,占内存:8个字节,精度:科学记数法的小数点后15~16位
1.9.4 计算机如何表示数据(理解)
1、如何表示boolean类型的值
true底层使用1表示。
false底层使用0表示。
2、如何表示整数?
原码反码补码
原码、反码和补码都是计算机二进制的表示方式。在这三种编码方式中,原码是最简单的,也是最直接的表示方式;反码可以解决原码在计算过程中的问题;补码可以解决反码在计算过程中的问题。
计算机在底层是采用补码形式表示数据的。
在二进制当中,最高位表示符号位,0表示正数,1表示负数。
规定:正数的补码与反码、原码一样,称为三码合一;
负数的补码与反码、原码不一样:
负数的原码:把十进制 转为二进制,然后最高位设置为1
负数的反码:在原码的基础上,最高位不变,其余位取反(0变1,1变0)
负数的补码:反码+1
例如:byte类型(1个字节,8位)25 ==> 原码 0001 1001 ==> 反码 0001 1001 -->补码 0001 1001
-25 ==>原码 1001 1001 ==> 反码1110 0110 ==>补码 1110 011
正数的原码反码补码正数的原码、反码和补码都是相同的。
例如,一个十进制数+5的二进制原码为00000101,反码为00000101,补码为00000101。
原码:将正数的二进制表示直接写下来,最高位为0。
反码:正数的反码就是其原码本身。
补码:正数的补码也就是其原码本身。
127的原码反码补码127的原码为01111111,其反码和补码均与原码相同。
负数的原码反码补码负数的原码运算规则:将绝对值转换为二进制后,最高位改为1。
-5的原码:10000101
-5的反码:11111010(原则是:以原码作为参考,符号位不变,其他位取反。)
-5的补码:11111011(原则是:以反码作为参考,符号位不变,加1)
-128的原码反码补码-128的原码为10000000,其反码为11111111,补码为10000000。注意,对于-128这个特殊的数,它的补码和原码相同。
整数:
正数:25 00000000 00000000 000000000 00011001(原码)
正数:25 00000000 00000000 000000000 00011001(反码)
正数:25 00000000 00000000 000000000 00011001(补码)
负数:-25 10000000 00000000 000000000 00011001(原码)
负数:-25 11111111 11111111 111111111 11100110(反码)
负数:-25 11111111 11111111 111111111 11100111(补码)
计算机底层为什么采用补码
算机采用补码形式进行数值计算的原因有以下几点:
- 可以简化电路设计:采用补码形式可以将加减法运算转化为相同的操作,从而简化电路设计。
- 解决了0的正负问题:在原码中,0有两个表示,+0和-0,这样会导致计算结果不唯一,而在补码中,0只有一种表示,即全0,可以避免这个问题。
- 解决了负数溢出问题:在原码中,负数的表示范围比正数少1,这样在进行减法运算时容易出现负数溢出的情况,而在补码中,负数的表示范围与正数相同,可以避免负数溢出的问题。
- 方便计算机进行运算:补码形式可以方便计算机进行加减法运算,而且可以使用相同的电路进行运算,从而提高了计算机的运算效率。
下面是一个简单的数据演示:
假设我们要计算-3+2的结果,使用原码进行计算:
-3的原码为10000011,2的原码为00000010,进行加法运算得到的结果为10000101,转换成十进制为-5,这个结果是错误的。
使用补码进行计算:
-3的补码为11111101,2的补码为00000010,进行加法运算得到的结果为11111111,转换成十进制为-1,这个结果是正确的。
一个字节可以存储的整数范围是多少?
1个字节:8位
0000 0001 ~ 0111 111 ==> 1~127
1000 0001 ~ 1111 1111 ==> -127 ~ -1
0000 0000 ==>0
1000 0000 ==> -128(特殊规定)=-127-1
3、如何表示小数?
了解小数如何存储是为了理解如下问题:
- 为什么float(4个字节)比long(8个字节)的存储范围大?
- 为什么float和double不精确?
- 为什么double(8个字节)比float(4个字节)精度范围大?
因为float、double底层也是二进制,先把小数转为二进制,然后把二进制表示为科学记数法,然后只保存:
①符号位②指数位(需要移位)③尾数位
float:符号位(1位),指数位(8位,偏移127),尾数位(23位)
double:符号位(1位),指数位(11位,偏移1023),尾数为(52位)
float指数-126~+127
double指数-1022~+1023
float类型
小数:8.25 1000.01
1.00001(科学计数法)
符号位0,指数位3+127(偏移量)=130->10000010,尾数00001
0 10000010 00001000000000000000000 原码
0 10000010 00001000000000000000000 反码
0 10000010 00001000000000000000000 补码
小数:-8.25 -1000.01(原码)
1 10000010 00001000000000000000000 原码
1 01111101 11110111111111111111111 反码
1 01111101 11111000000000000000000 补码
double类型:
小数:8.25 1000.01
1.00001(科学计数法)
符号位0,指数位3+1023(偏移量)=1026->10000000010,尾数00001
0 10000000010 0000 10000000 00000000 00000000 00000000 00000000 00000000 原码
0 10000000010 0000 10000000 00000000 00000000 00000000 00000000 00000000 反码
0 10000000010 0000 10000000 00000000 00000000 00000000 00000000 00000000 补码
double类型:
小数:-8.25 -1000.01(原码)
1.00001(科学计数法)
符号位0,指数位3+1023(偏移量)=1026->10000000010,尾数00001
1 10000000010 0000 10000000 00000000 00000000 00000000 00000000 00000000 原码
1 01111111101 1111 01111111 11111111 11111111 11111111 11111111 11111111 反码
1 01111111101 1111 10000000 00000000 00000000 00000000 00000000 00000000 补码
为什么float类型指数位偏移127,double类型指数位偏移1023。
因为指数+3,偏移127就是130
因为指数-3,偏移127就是124
130>124,比较大小比较方便。
4、Java程序中如何表示和处理单个字符?
(1)使用单引号将单个字符引起来:例如:‘A’,‘0’,‘尚’
char c = '尚';//使用单引号
String s = '尚';//错误的,哪怕是一个字符,也要使用双引号
char kongChar = '';//错误,单引号中有且只能有一个字符
String kongStr = "";//可以,双引号中可以没有其他字符,表示是空字符串
(2)特殊的转义字符
\n:换行
\r:回车
\t:Tab键
\\:\
\":"
\':'
\b:删除键Backspace
public class TestEscapeCharacter {
public static void main(String[] args){
System.out.println("hello\tjava");
System.out.println("hello\rjava");
System.out.println("hello\njava");
System.out.println("hello\\world");
System.out.println("\"hello\"");
char shuang = '"';
System.out.println(shuang + "hello" + shuang);
System.out.println("'hello'");
char dan ='\'';
System.out.println(dan + "hello" + dan);
}
}
public class TestTab {
public static void main(String[] args){
System.out.println("hello\tworld\tjava.");
System.out.println("chailinyan\tis\tbeautiful.");
System.out.println("姓名\t基本工资\t年龄");
System.out.println("张三\t10000.0\t23");
}
}
(3)用十进制的0~65535之间的Unicode编码值,表示一个字符
在JVM内存中,一个字符占2个字节,Java使用Unicode字符集来表示每一个字符,即每一个字符对应一个唯一的Unicode编码值。char类型的数值参与算术运算或比较大小时,都是用编码值进行计算的。
| 字符 | Unicode编码值 |
|---|---|
| ‘0’ | 48 |
| ‘1’ | 49 |
| ‘A’ | 65 |
| ‘B’ | 66 |
| ‘a’ | 97 |
| ‘b’ | 98 |
| ‘尚’ | 23578 |
char c1 = 23578;
System.out.println(c1);//尚
char c2 = 97;
System.out.println(c2);//a
//如何查看某个字符的Unicode编码?
//将一个字符赋值给int类型的变量即可
int codeOfA = 'A';
System.out.println(codeOfA);
int codeOfShang = '尚';
System.out.println(codeOfShang);
int codeOfTab = '\t';
System.out.println(codeOfTab);
(4)\u字符的Unicode编码值的十六进制型
例如:‘\u5c1a’代表’尚’
char c = '\u0041'; //十进制Unicode值65,对应十六进制是41,但是\u后面必须写4位
char c = '\u5c1a'; //十进制Unicode值23578,对应十六进制是5c1a
5、一个字符到底占几个字节?
在JVM内存中,一个字符占2个字节,Java使用Unicode字符集来表示每一个字符,即每一个字符对应一个唯一的Unicode编码值。char类型的数值参与算术运算或比较大小时,都是用编码值进行计算的。
在文件中保存或网络中传输时文本数据时,和环境编码有关。如果环境编码选择ISO8859-1(又名Latin),那么一个字符占一个字节;如果环境编码选择GBK,那么一个字符占1个或2个字节;如果环境编码选择UTF-8,那么一个字符占1-4个字节。(后面讲String类时再详细讲解)
1.10 运算符(Operator)和标点符号(Separators)(掌握)
在Java中,一共有38个运算符。

运算符的分类:
- 按照功能分:算术运算符、赋值运算符、比较运算符、逻辑运算、条件运算符、Lambda运算符
| 分类 | 运算符 |
|---|---|
| 算术运算符(7个) | +、-、*、/、%、++、– |
| 赋值运算符(12个) | =、+=、-=、*=、/=、%=、>>=、<<=、>>>=、&=、|=、^=等 |
| 关系运算符(6个) | >、>=、<、<=、==、!= |
| 逻辑运算符(6个) | &、|、^、!、&&、|| |
| 条件运算符(2个) | (条件表达式)?结果1:结果2 |
| 位运算符(7个) | &、|、^、~、<<、>>、>>> |
| Lambda运算符(1个) | ->(后面学) |
- 按照操作数个数分:一元运算符(单目运算符)、二元运算符(双目运算符)、三元运算符 (三目运算符)
| 分类 | 运算符 |
|---|---|
| 一元运算符(单目运算符) | 正号(+)、负号(-)、++、–、!、~ |
| 二元运算符(双目运算符) | 除了一元和三元运算符剩下的都是二元运算符 |
| 三元运算符 (三目运算符) | (条件表达式)?结果1:结果2 |
1.10.1 算术运算符
| 算术运算符 | 符号解释 |
|---|---|
+ |
加法运算,字符串连接运算,正号 |
- |
减法运算,负号 |
* |
乘法运算 |
/ |
除法运算,整数/整数结果还是整数 |
% |
求余运算,余数的符号只看被除数 |
++ 、 -- |
自增自减运算 |
1、加减乘除模
public class OperatorDemo01 {
public static void main(String[] args) {
int a = 3;
int b = 4;
System.out.println(a + b);// 7
System.out.println(a - b);// -1
System.out.println(a * b);// 12
System.out.println(a / b);// 计算机结果是0,为什么不是0.75呢?
System.out.println(a % b);// 3
System.out.println(5%2);//1
System.out.println(5%-2);//1
System.out.println(-5%2);//-1
System.out.println(-5%-2);//-1
//商*除数 + 余数 = 被除数
//5%-2 ==>商是-2,余数时1 (-2)*(-2)+1 = 5
//-5%2 ==>商是-2,余数是-1 (-2)*2+(-1) = -4-1=-5
}
}
2、“+”号的两种用法
- 第一种:对于
+两边都是数值的话,+就是加法的意思 - 第二种:对于
+两边至少有一边是字符串得话,+就是拼接的意思
public class OperatorDemo02 {
public static void main(String[] args) {
// 字符串类型的变量基本使用
// 数据类型 变量名称 = 数据值;
String str1 = "Hello";
System.out.println(str1); // Hello
System.out.println("Hello" + "World"); // HelloWorld
String str2 = "Java";
// String + int --> String
System.out.println(str2 + 520); // Java520
// String + int + int
// String + int
// String
System.out.println(str2 + 5 + 20); // Java520
}
}
3、自加自减运算
理解:++ 运算,变量自己的值加1。反之,-- 运算,变量自己的值减少1,用法与++ 一致。
1、单独使用
- 变量在单独运算的时候,变量
前++和变量后++,变量的是一样的; - 变量
前++:例如++a。 - 变量
后++:例如a++。
public class OperatorDemo3 {
public static void main(String[] args) {
// 定义一个int类型的变量a
int a = 3;
//++a;
a++;
// 无论是变量前++还是变量后++,结果都是4
System.out.println(a);
}
}
2、复合使用
- 和
其他变量放在一起使用或者和输出语句放在一起使用,前++和后++就产生了不同。
- 变量
前++:变量先自身加1,然后再取值。 - 变量
后++:变量先取值,然后再自身加1。
public class OperatorDemo03 {
public static void main(String[] args) {
// 其他变量放在一起使用
int x = 3;
//int y = ++x; // y的值是4,x的值是4,
int y = x++; // y的值是3,x的值是4
System.out.println(x);
System.out.println(y);
System.out.println("==========");
// 和输出语句一起
int z = 5;
//System.out.println(++z);// 输出结果是6,z的值也是6
System.out.println(z++);// 输出结果是5,z的值是6
System.out.println(z);
int a = 1;
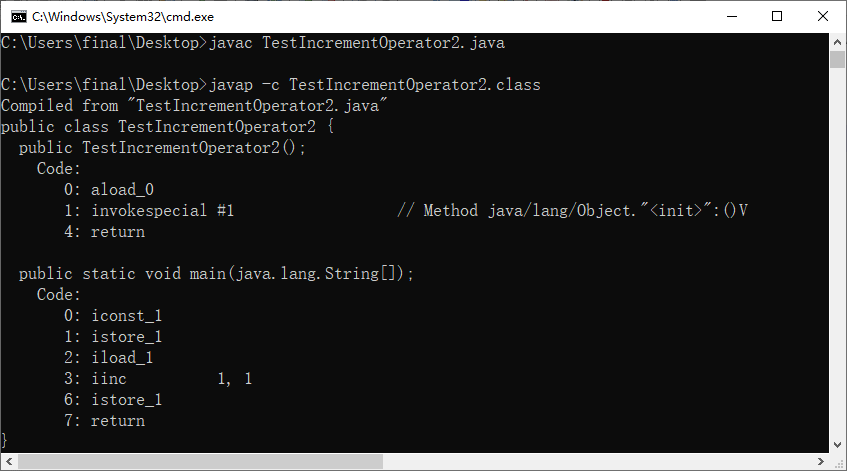
a = a++;//(1)先取a的值“1”放操作数栈(2)a再自增,a=2(3)再把操作数栈中的"1"赋值给a,a=1
int i = 1;
int j = i++ + ++i * i++;
/*
从左往右加载
(1)先算i++
①取i的值“1”放操作数栈
②i再自增 i=2
(2)再算++i
①i先自增 i=3
②再取i的值“3”放操作数栈
(3)再算i++
①取i的值“3”放操作数栈
②i再自增 i=4
(4)先算乘法
用操作数栈中3 * 3 = 9,并把9压会操作数栈
(5)再算求和
用操作数栈中的 1 + 9 = 10
(6)最后算赋值
j = 10
*/
}
}
- 小结:
- ++在前,先自加,后使用;
- ++在后,先使用,后自加。
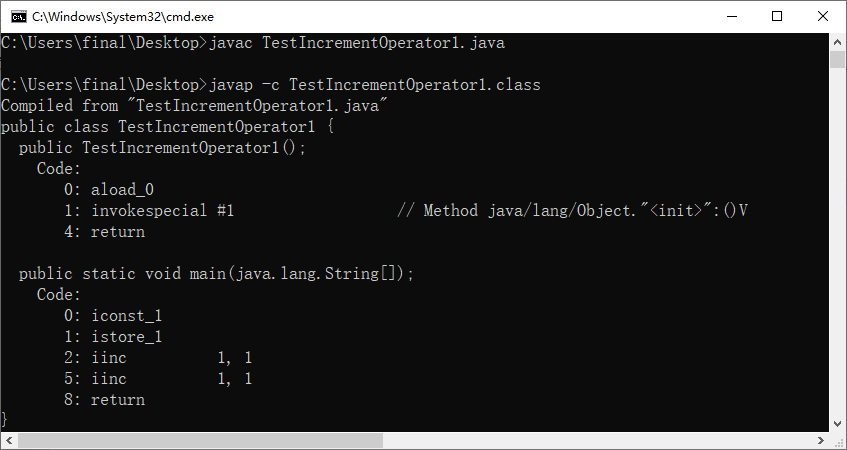
- 分析
public class TestIncrementOperator1{
public static void main(String[] args){
int i = 1;
i++;
++i;
}
}
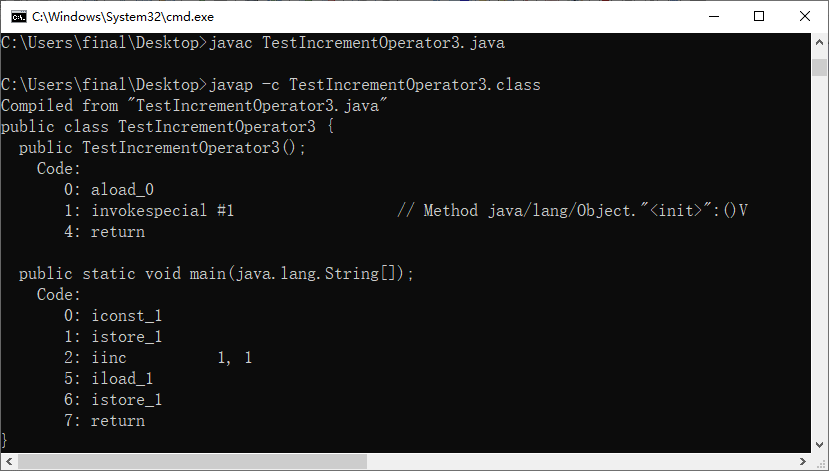
public class TestIncrementOperator2{
public static void main(String[] args){
int i = 1;
i = i++;
}
}
public class TestIncrementOperator3{
public static void main(String[] args){
int i = 1;
i = ++i;
}
}
1.10.2 关系运算符/比较运算符
| 关系运算符 | 符号解释 |
|---|---|
< |
比较符号左边的数据是否小于右边的数据,如果小于结果是true。 |
> |
比较符号左边的数据是否大于右边的数据,如果大于结果是true。 |
<= |
比较符号左边的数据是否小于或者等于右边的数据,如果大于结果是false。 |
>= |
比较符号左边的数据是否大于或者等于右边的数据,如果小于结果是false。 |
== |
比较符号两边数据是否相等,相等结果是true。 |
!= |
不等于符号 ,如果符号两边的数据不相等,结果是true。 |
- 比较运算符,是两个数据之间进行比较的运算,运算结果一定是boolean值
true或者false。 - 其中>,<,>=,<=不支持boolean,String类型,==和!=支持boolean和String。
public class OperatorDemo05 {
public static void main(String[] args) {
int a = 3;
int b = 4;
System.out.println(a < b); // true
System.out.println(a > b); // false
System.out.println(a <= b); // true
System.out.println(a >= b); // false
System.out.println(a == b); // false
System.out.println(a != b); // true
}
}
1.10.3 逻辑运算符
- 逻辑运算符,是用来连接两个布尔类型值的运算符(
!除外),运算结果也是boolean值true或者false
| 逻辑运算符 | 符号解释 | 符号特点 |
|---|---|---|
& |
与,且 | 有false则false |
| ` | ` | 或 |
^ |
异或 | 相同为false,不同为true |
! |
非 | 非false则true,非true则false |
&& |
双与,短路与 | 左边为false,则右边就不看 |
| ` | ` |
&&和&区别,||和|区别:
- **
&&和&**区别:&&和&结果一样,&&有短路效果,左边为false,右边不执行;&左边无论是什么,右边都会执行。
- **
||和|**区别:||和|结果一样,||有短路效果,左边为true,右边不执行;|左边无论是什么,右边都会执行。
public class OperatorDemo06 {
public static void main(String[] args) {
int a = 3;
int b = 4;
int c = 5;
// & 与,且;有false则false
System.out.println((a > b) & (a > c));
System.out.println((a > b) & (a < c));
System.out.println((a < b) & (a > c));
System.out.println((a < b) & (a < c));
System.out.println("===============");
// | 或;有true则true
System.out.println((a > b) | (a > c));
System.out.println((a > b) | (a < c));
System.out.println((a < b) | (a > c));
System.out.println((a < b) | (a < c));
System.out.println("===============");
// ^ 异或;相同为false,不同为true
System.out.println((a > b) ^ (a > c));
System.out.println((a > b) ^ (a < c));
System.out.println((a < b) ^ (a > c));
System.out.println((a < b) ^ (a < c));
System.out.println("===============");
// ! 非;非false则true,非true则false
System.out.println(!false);
System.out.println(!true);
//&和&&的区别
System.out.println((a > b) & (a++ > c));
System.out.println("a = " + a);
System.out.println((a > b) && (a++ > c));
System.out.println("a = " + a);
System.out.println((a == b) && (a++ > c));
System.out.println("a = " + a);
//|和||的区别
System.out.println((a > b) | (a++ > c));
System.out.println("a = " + a);
System.out.println((a > b) || (a++ > c));
System.out.println("a = " + a);
System.out.println((a == b) || (a++ > c));
System.out.println("a = " + a);
}
}
/*
3、逻辑运算符
逻辑与:&
true & true 结果是true
true & false 结果是false
false & true 结果是false
false & false 结果是false
只有两个边都是true,结果才为true。
逻辑或:|
true | true 结果是true
true | false 结果是true
false | true 结果是true
false | false 结果是false
只要有一边是true,结果就为true。
逻辑非:!
!true 变为false
!false 变为true
逻辑异或:^
true | true 结果是false
true | false 结果是true
false | true 结果是true
false | false 结果是false
只有两边不一样,一个是true,一个是false,结果才为true。
短路与:&&
true && true 结果是true
true && false 结果是false
false && ? 结果是false
false && ? 结果是false
只有两个边都是true,结果才为true。
但是它如果左边已经是false,右边不看。这样的好处就是可以提高效率。
短路或:||
true || ? 结果是true
true || ? 结果是true
false || true 结果是true
false || false 结果是false
只要有一边是true,结果就为true。
但是它如果左边已经是true,右边就不看了。这样的好处就是可以提高效率。
特殊:
(1)逻辑运算符的操作数必须是boolean值
(2)逻辑运算符的结果也是boolean值
*/
public class LogicOperator{
public static void main(String[] args){
/*
表示条件,成绩必须在[0,100]之间
成绩是int类型变量score
*/
int score = 56;
//System.out.println(0<=score<=100);
/*
LogicOperator.java:23: 错误: 二元运算符 '<=' 的操作数类型错误
System.out.println(0<=score<=100);
^
第一个类型: boolean 0<=score的结果 true
第二个类型: int
true <= 100?不对的
1 个错误*/
System.out.println(0<=score & score<=100);
}
}
1.10.4 条件运算符
- 条件运算符格式:
条件表达式?结果1:结果2
- 条件运算符计算方式:
- 条件判断的结果是true,条件运算符整体结果为结果1,赋值给变量。
- 判断条件的结果是false,条件运算符整体结果为结果2,赋值给变量。
public static void main(String[] args) {
int i = (1==2 ? 100 : 200);
System.out.println(i);//200
int j = (3<=4 ? 500 : 600);
System.out.println(j);//500
}
public class ConditionOperator{
public static void main(String[] args){
//判断两个变量a,b谁大,把大的变量赋值给max
int a = 2;
int b = 2;
int max = a >= b ? a : b;
//如果a>=b成立,就取a的值赋给max,否则取b的值赋给max
System.out.println(max);
boolean marry = false;
System.out.println(marry ? "已婚" : "未婚" );
}
}
1.10.5 位运算符
| 位运算符 | 符号解释 |
|---|---|
& |
按位与,当两位相同时为1时才返回1 |
| ` | ` |
~ |
按位非,将操作数的每个位(包括符号位)全部取反 |
^ |
按位异或。当两位相同时返回0,不同时返回1 |
<< |
左移运算符 |
>> |
右移运算符 |
>>> |
无符号右移运算符 |
- 位运算符的运算过程都是基于补码运算,但是看结果,我们得换成原码,再换成十进制看结果
- 从二进制到十进制都是基于原码
- 正数的原码反码补码都一样,负数原码反码补码不一样
- byte,short,char在计算时按照int类型处理
如何区分&,|,^是逻辑运算符还是位运算符?
如果操作数是boolean类型,就是逻辑运算符,如果操作数是整数,那么就位运算符。
(1)左移:<<
运算规则:左移几位就相当于乘以2的几次方
**注意:**当左移的位数n超过该数据类型的总位数时,相当于左移(n-总位数)位
byte,short,char在计算时按照int类型处理
3<<4 类似于 3*2的4次= 3*16 = 48

-3<<4 类似于 -3*2的4次= -3*16 = -48

(2)右移:>>
快速运算:类似于除以2的n次,如果不能整除,向下取整
69>>4 类似于 69/2的4次 = 69/16 =4

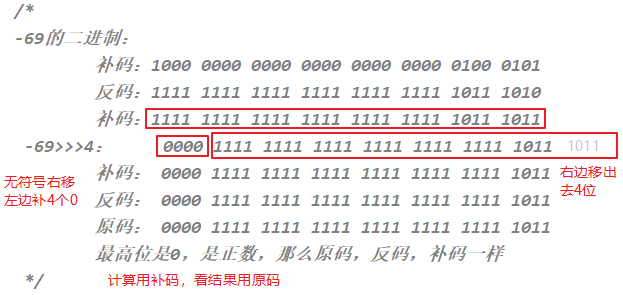
-69>>4 类似于 -69/2的4次 = -69/16 = -5
(3)无符号右移:>>>
运算规则:往右移动后,左边空出来的位直接补0,不看符号位
正数:和右移一样
负数:右边移出去几位,左边补几个0,结果变为正数
69>>>4 类似于 69/2的4次 = 69/16 =4

-69>>>4 结果:268435451
(4)按位与:&
运算规则:对应位都是1才为1
1 & 1 结果为1
1 & 0 结果为0
0 & 1 结果为0
0 & 0 结果为0
9&7 = 1

-9&7 = 7

(5)按位或:|
运算规则:对应位只要有1即为1
1 | 1 结果为1
1 | 0 结果为1
0 | 1 结果为1
0 & 0 结果为0
9|7 结果: 15

-9|7 结果: -9

(6)按位异或:^
运算规则:对应位一个为1一个为0,才为1
1 ^ 1 结果为0
1 ^ 0 结果为1
0 ^ 1 结果为1
0 ^ 0 结果为0
9^7 结果为14

-9^7 结果为-16

(7)按位取反:~
运算规则:~0就是1
~1就是0
~9 结果:-10

~-9 结果:8

1.10.6 赋值运算符
| 运算符 | 符号解释 |
|---|---|
| = | 将右边的常量值/变量值/表达式的值,赋值给左边的变量 |
| += | 将左边变量的值和右边的常量值/变量值/表达式的值进行相加,最后将结果赋值给左边的变量 |
| -= | 将左边变量的值和右边的常量值/变量值/表达式的值进行相减,最后将结果赋值给左边的变量 |
| *= | 将左边变量的值和右边的常量值/变量值/表达式的值进行相乘,最后将结果赋值给左边的变量 |
| /= | 将左边变量的值和右边的常量值/变量值/表达式的值进行相除,最后将结果赋值给左边的变量 |
| %= | 将左边变量的值和右边的常量值/变量值/表达式的值进行相模,最后将结果赋值给左边的变量 |
| <<= | 将左边变量的值左移右边常量/变量值/表达式的值的相应位,最后将结果赋值给左边的变量 |
| >>= | 将左边变量的值右移右边常量/变量值/表达式的值的相应位,最后将结果赋值给左边的变量 |
| >>>= | 将左边变量的值无符号右移右边常量/变量值/表达式的值的相应位,最后将结果赋值给左边的变量 |
| &= | 将左边变量的值和右边的常量值/变量值/表达式的值进行按位与,最后将结果赋值给左边的变量 |
| |= | 将左边变量的值和右边的常量值/变量值/表达式的值进行按位或,最后将结果赋值给左边的变量 |
| ^= | 将左边变量的值和右边的常量值/变量值/表达式的值进行按位异或,最后将结果赋值给左边的变量 |
public class OperatorDemo04 {
public static void main(String[] args) {
int a = 3;
int b = 4;
int c = a + b;
b += a;// 相当于 b = b + a ;
System.out.println(a); // 3
System.out.println(b); // 7
System.out.println(c); //7
short s = 3;
// s = s + 4; 代码编译报错,因为将int类型的结果赋值给short类型的变量s时,可能损失精度
s += 4; // 代码没有报错
//因为在得到int类型的结果后,JVM自动完成一步强制类型转换,将int类型强转成short
System.out.println(s);
int j = 1;
j += ++j * j++;//相当于 j = j + (++j * j++);
System.out.println(j);//5
int m = 1;
m <<= 2;
System.out.println(m);
}
}
- 扩展赋值运算符在将最后的结果赋值给左边的变量前,多做了一步强制类型转换。
- 注意:所有的赋值运算符的=左边一定是一个变量
1.10.7 运算符优先级

提示说明:
(1)表达式不要太复杂
(2)先算的使用()
口诀:
单目运算排第一;
乘除余二加减三;
移位四,关系五;
等和不等排第六;
位与、异或和位或;
短路与和短路或;
依次从七到十一;
条件排在第十二;
赋值一定是最后;
1.10.8 标点符号
在Java中一共有12个标点符号。(后面再一一学习)

- 小括号 () 用于强制类型转换、表示优先运算表达式、方法参数列表
- 大括号 {} 用于数组元素列表、类体、方法体、复合语句代码块边界符
- 中括号 [] 用于数组
- 分号; 用于结束语句
- 逗号,用于多个赋值表达式的分隔符和方法参数列表分隔符
- 英文句号.用于成员访问和包目录结构分隔符
- 英文省略号…用于可变参数
- @用于注解
- 双冒号::用于方法引用
各个标点符号的使用在后续章节中一一揭晓。
智能推荐
nyoj 132-最长回文子串_第一行输入一个字符串s,s的长度小于等于5000大于等于1-程序员宅基地
文章浏览阅读656次。http://acm.nyist.net/JudgeOnline/problem.php?pid=132最长回文子串时间限制:1000 ms | 内存限制:65535 KB难度:4描述输入一个字符串,求出其中最长的回文子串。子串的含义是:在原串连续出现的字符串片段。回文的含义是:正着看和倒着看是相同的,如abba和abbebba。在判断是要求忽略_第一行输入一个字符串s,s的长度小于等于5000大于等于1
华为WLAN AirEngine 9700S AC控制器如何开启双SSID_华为ac9700s-sweb配置教程-程序员宅基地
文章浏览阅读6.2k次。业务场景:家庭大户型上下2层住宅用户通过WLAN接入网络业务需求:扫地机器人只正常2.4G网络,目前默认2.4G和5G频段合二为一,导致扫地机器人不能正常接收命令上传数据,无法正常使用。目的:5G和2.4G信号都单独显示出,让扫地机器人连上2.4G网络AC版本9700S-SV200R020C00SPC300web配置步骤1.配置向导–无线业务–新建SSIDxx5G生效射频只选1(5G)其他参数和现有ssid一样,保存2.更改原有SSIDxx生效射频只保留0(2.4G)其它不变,保存3_华为ac9700s-sweb配置教程
PeakDo毫米波投屏器Hybrid新玩法-程序员宅基地
文章浏览阅读302次。毫米波在如今的网络通信领域可以称得上是第一梯队的高频词汇,作为5G时代的重要组成部分,毫米波是波长为毫米级的电磁波,通常占据了30~300GHz的网络频段,从速度来看,毫米波甚至要比我国现行5G网络普遍使用的Sub-6 GHz还要更快。不过毫米波对信号条件有着更高要求,这也是为什么如今我们能见到的毫米波实际应用并不多。但在室内良好环境下,毫米波技术仍然具备很大的潜力,替代室内场景的各种屏幕HDMI连接线材,就成了毫米波技术首先盯上的领域。在毫米波60GHz频段有着2.4GHz和5.0GHz W._毫米波投屏
超市出了新的活动:4个空汽水瓶可以换1瓶汽水。小明现在手上有n个空汽水瓶,他最多可以换多少瓶汽水喝?_商店规定每4个空瓶可以换一瓶汽水-程序员宅基地
文章浏览阅读1.5k次。#include<stdio.h>int main(){int n;//初始空瓶数int total;//总共喝到的可乐数int m=0;//上一次喝到的可乐数int t=0;//上一次喝完剩下的空瓶数int i=1;//进入循环结构while(i>0)/循环次数,可以自己定义/{total=0;scanf("%d",&n);m=n/4;t=m+n%4;total+=m;while(t>3){m=t/4;t=m+t%4;total+=m;}_商店规定每4个空瓶可以换一瓶汽水
LoadRunner参数化MySQL-程序员宅基地
文章浏览阅读41次。准备:安装【msql-ODBC驱动】一、配置数据源1、Win7,打开控制面板-系统和安全-管理工具,点击“数据源(ODBC)”.打开数据源(ODBC),在用户DSN选项卡中点击“添加”按钮,弹出“创建新数据源”窗口。点击“添加”,如下图:选中“MYSQLODBC5.2 ANSI Driver”,点击“完成”按钮。配置mysql的IP、用户名与密码,如下..._lr11利用mysql进行参数化设计
WCF初探-19:WCF消息协定-程序员宅基地
文章浏览阅读62次。WCF消息协定概述在生成 WCF应用程序时,开发人员通常会密切关注数据结构和序列化问题,而不必关心携带数据的消息结构。 对于这些应用程序,为参数或返回值创建数据协定的过程很简单。但是,有时完全控制 SOAP 消息的结构与控制其内容一样重要。 当必须提供互操作性或需要在消息或消息部分级别特别控制安全问题时,更是如此。 在这些情况下,您可以创建消息协定 ,使您可以指定所需的精确的 SOA...
随便推点
【UML】——活动图-程序员宅基地
文章浏览阅读5.8w次,点赞25次,收藏96次。一、活动图概述1、流程图:常被用来建立算法模型,使用流程图可以表示一个算法的执行序列、过程、判定点、分支和循环 活动图和流程图十分类似,不同之处在于它支持并行活动 活动图的缺点:很难清楚的描述动作与对象之间的关系,没有交互图直接2、活动图作用描述一个操作的执行过程中所完成的工作或 者动作 描述对象内部的工作 显示如何执行一组相关的动作,以及这些动作如何影响周围对象 描..._活动图
Java并发编程:第七章 并发工具类_java并发编程的类-程序员宅基地
文章浏览阅读1.2k次,点赞32次,收藏11次。在Java并发框架中,Exchanger 是一个同步点,它允许一对线程在一个点上交换对象。Exchanger 非常适合于两个线程需要相互传递数据或信息的场景,例如遗传算法中的配对交叉操作,或者流水线设计中两个工作阶段的交互。让一组线程到达一个屏障时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活,线程进入屏障通过CyclicBrrier的await方法。信号量主要用于两个目的,一个是用于多个共享资源的互斥使用,另外一个用于并发线程的控制。_java并发编程的类
Qt5/6Windows下使用QSettings操作注册表或者使用WindowsAPI调用Firefox浏览器打开网址_windows api打开网页-程序员宅基地
文章浏览阅读655次。在Windows下操作注册表是程序中常用的操作,这里我们借用浏览器打开网页来看看如何操作注册表,使用的是QSettings类,对于键值对的操作,使用它最为适合了。void MainWindow::on_btnSetDefaultBrowser_clicked(){#ifdef WIN32 QSettings a("HKEY_LOCAL_MACHINE\\SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\App Paths\\firefox.ex_windows api打开网页
SpringBoot单元测试java.lang.IllegalStateException Could not initialize plugin: interface org.mockito解决方案_java.lang.illegalstateexception: could not initial-程序员宅基地
文章浏览阅读2.8w次,点赞40次,收藏42次。本文主要介绍了SpringBoot项目单元测试java.lang.IllegalStateException: Could not initialize plugin: interface org.mockito.plugins.MockMaker,希望能对使用SpringBoot项目单元测试的同学们有所帮助。文章目录1. 问题描述2. 原因分析3. 解决办法_java.lang.illegalstateexception: could not initialize plugin: interface org.
Python淘宝电脑销售数据爬虫可视化分析大屏全屏系统 开题报告-程序员宅基地
文章浏览阅读4.4k次,点赞21次,收藏17次。Python淘宝电脑销售数据爬虫可视化分析大屏全屏系统 开题报告毕设毕业设计作品,从而节省人力、物力,只要会打字即可,不需要很高的学历;综上所述,Python淘宝电脑销售数据爬虫可视化分析大屏全屏系统的研究将为企业和市场参与者提供宝贵的市场洞察和决策支持,促进电脑市场的健康发展和竞争态势的优化。跨文化和方法的借鉴:国外的学者在电子商务、消费者行为等领域的研究,尤其是在跨文化背景下的研究,为国内淘宝电脑销售数据的研究提供了方法上的借鉴和启示。
Simulink如何让仿真时长等于真实时长_simulink 仿真时间与真实时间同步-程序员宅基地
文章浏览阅读3.2k次,点赞10次,收藏23次。Simulink如何让仿真时长等于真实时长在Matlab的帮助文档里找到Pure Pursuit模块的文档,在末尾处打开Path Following with Obstacle Avoidance in Simulink的scripts。在该模型中找到Rate Control模块(如下图),复制该模块并粘贴到你的Simulink模型里。2. 将该模块的参数设置成与你Model Configuration Parameters里的Fix-step size相同的仿真步长(如0.02)。运行该模_simulink 仿真时间与真实时间同步