hugegraph-server和HugeGraph-Hubble超详细安装部署教程(主要idea和linux压缩文件安装)-程序员宅基地
技术标签: spring boot # HugeGraph 图数据库 java spring cloud 数据库
1. HugeGraph安装与使用
本章主要介绍HugeGraph图数据库HugeGraph-Server的安装与入门使用。本文使用的工作环境为:Windows11、linux(centOs7)、idea。不支持windows安装
HugeGraph官方地址:https://hugegraph.apache.org/
官方文档地址:https://hugegraph.apache.org/docs/
有三种方法可以部署HugeGraph-Server组件(主讲方法二和三):
- 方式一:一键部署
- 方法 二:下载压缩包
- 方法三:源码编译
1.1. 各个模块基本介绍(详情去官网查看)
- HugeGraph-Server:HugeGraph-Server是HugeGraph项目的核心部分,包括Core、后端和API等子模块;
- 核心:图引擎实现,向下连接后端模块,向上支持API模块;
- 后端:实现图数据到后端的存储。支持的后端包括:Memory,Cassandra,ScyllaDB,RocksDB,HBase,MySQL和PostgreSQL。用户可以根据实际情况选择一种;
- API:内置 REST Server,为用户提供 RESTful API,与 Gremlin 查询完全兼容。
- HugeGraph-Client:HugeGraph-Client 提供了一个 RESTful API 客户端,用于连接到 HugeGraph-Server。目前,仅实现Java版本。其他语言的用户可以自己实现;
- HugeGraph-Loader:HugeGraph-Loader是一款基于HugeGraph-Client的数据导入工具,它将普通文本数据转换为图形顶点和边缘,并插入图形数据库;
- HugeGraph-Spark:HugeGraph-Spark可以对图进行并行计算,如PageRank算法等;
- HugeGraph-Hubble:HugeGraph-Hubble是HugeGraph的Web可视化管理平台,一站式可视化分析平台。平台覆盖从数据建模,到数据快速导入,再到数据线上线下分析、图统一管理的全流程;
- HugeGraph-Tools:HugeGraph-Tools 是 HugeGraph 的部署和管理工具,包括管理图形、备份/恢复、Gremlin 执行等功能。
| components | description |
| HugeGraph-Server | HugeGraph的主程序 |
| HugeGraph-Hubble | 基于Web的可视化图形界面 |
| HugeGraph-Loader | 数据导入工具 |
| HugeGraph-Tools | 命令行工具集 |
本文只选用HugeGraph-Server(0.12.0)和HugeGraph-Hubble(1.6.0)。
2. HugeGraph-server安装配置
2.1、使用安装方法二:下载压缩包(不支持windows)
2.1.1、环境准备
在linux环境中安装jdk1.8和mysql5.7(至少和以上),这个两个的安装和配置网上有很多详细的文章,自行安装即可。
去官网下载HugeGraph-server 0.12.0,并上传至linux opt目录(该目录一般用于软件安装)下备用。
2.1.2、HugeGraph-server安装和配置
进入opt目录
cd /opt
解压之前下载的安装包
tar -xzvf hugegraph-0.12.0.tar.gz
新建目录
mkdir hugegraph12
移动解压后的文件到新建的目录
mv hugegraph-0.12.0 hugegraph12
进入配置文件目录
cd hugegraph12/hugegraph-0.12.0/conf
进入graphs 这个目录存放hugegraph.properties
cd graphs/
编辑配置文件
vim hugegraph.properties
几个主要的配置文件:
gremlin-server.yaml:Gremlin Server服务配置
rest-server.properties:HugeGraph服务配置
hugegraph.properties:具体图实例的配置,每个图一个配置文件,图的名称就是文件的名称。
下面对需要修改的文件进行详解
2.1.3. 图存储配置
由于各种后端所需的配置(示例图实例配置文件:hugegraph.properties)及启动步骤略有不同,下面只对使用mysql做图数据存储配置及启动做介绍(其它官网文档都有,只有mysql没有)。一个图只有一种存储方式,不同图可以采用不同的后端存储。以下操作红色部分都是修改后的hugegraph.properties文件。
# auth config: com.baidu.hugegraph.auth.HugeFactoryAuthProxy
gremlin.graph=com.baidu.hugegraph.HugeFactory
# cache config
#schema.cache_capacity=100000
# vertex-cache default is 1000w, 10min expired
vertex.cache_type=l2
#vertex.cache_capacity=10000000
#vertex.cache_expire=600
# edge-cache default is 100w, 10min expired
edge.cache_type=l2
#edge.cache_capacity=1000000
#edge.cache_expire=600
# schema illegal name template
#schema.illegal_name_regex=\s+|~.*
#vertex.default_label=vertex
backend=mysql
serializer=mysql
store=hugegraph
raft.mode=false
raft.safe_read=false
raft.use_snapshot=false
raft.endpoint=127.0.0.1:8281
raft.group_peers=127.0.0.1:8281,127.0.0.1:8282,127.0.0.1:8283
raft.path=./raft-log
raft.use_replicator_pipeline=true
raft.election_timeout=10000
raft.snapshot_interval=3600
raft.backend_threads=48
raft.read_index_threads=8
raft.read_strategy=ReadOnlyLeaseBased
raft.queue_size=16384
raft.queue_publish_timeout=60
raft.apply_batch=1
raft.rpc_threads=80
raft.rpc_connect_timeout=5000
raft.rpc_timeout=60000
search.text_analyzer=jieba
search.text_analyzer_mode=INDEX
# rocksdb backend config
#rocksdb.data_path=/path/to/disk
#rocksdb.wal_path=/path/to/disk
# cassandra backend config
cassandra.host=localhost
cassandra.port=9042
cassandra.username=
cassandra.password=
#cassandra.connect_timeout=5
#cassandra.read_timeout=20
#cassandra.keyspace.strategy=SimpleStrategy
#cassandra.keyspace.replication=3
# hbase backend config
#hbase.hosts=localhost
#hbase.port=2181
#hbase.znode_parent=/hbase
#hbase.threads_max=64
# mysql backend config
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306
jdbc.username=root
jdbc.password=root
jdbc.reconnect_max_times=3
jdbc.reconnect_interval=3
jdbc.sslmode=false
# postgresql & cockroachdb backend config
#jdbc.driver=org.postgresql.Driver
#jdbc.url=jdbc:postgresql://localhost:5432/
#jdbc.username=postgres
#jdbc.password=
#jdbc.postgresql.connect_database=template1
# palo backend config
#palo.host=127.0.0.1
#palo.poll_interval=10
#palo.temp_dir=./palo-data
#palo.file_limit_size=32
修改完后 ESC退出编辑,:wq保存并退出
gremlin-server.yaml 这个文件配置gremlin图数据库查询语言服务配置,网上较多博主说要修改里面的配置,graphs:{},但是修改后启动报错,所以不要修改,默认即可。实践真实有效。
rest-server.properties需要修改,红色部分是修改后的:
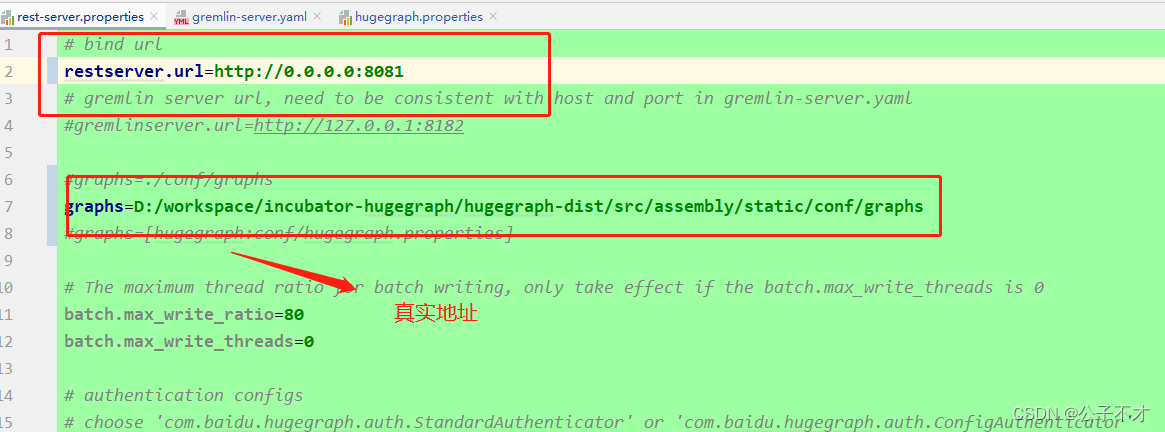
如果需要外部访问HugeGraphServer,请修改rest-server.properties的restserver.url配置项 (默认为http://127.0.0.1:8080),修改成机器名或IP地址,或者直接配置为:
# bind url
restserver.url=http://0.0.0.0:8080
# gremlin server url, need to be consistent with host and port in gremlin-server.yaml
#gremlinserver.url=http://127.0.0.1:8182
#graphs=[hugegraph:conf/hugegraph.properties](网上说修改成这样,但是报错,默认即可)
graphs=./conf/graphs
# The maximum thread ratio for batch writing, only take effect if the batch.max_write_threads is 0
batch.max_write_ratio=80
batch.max_write_threads=0
# authentication configs
# choose 'com.baidu.hugegraph.auth.StandardAuthenticator' or 'com.baidu.hugegraph.auth.ConfigAuthenticator'
#auth.authenticator=
# for StandardAuthenticator mode
#auth.graph_store=hugegraph
# auth client config
#auth.remote_url=127.0.0.1:8899,127.0.0.1:8898,127.0.0.1:8897
# for ConfigAuthenticator mode
#auth.admin_token=
#auth.user_tokens=[]
# rpc group configs of multi graph servers
# rpc server configs
rpc.server_host=127.0.0.1
rpc.server_port=8090
#rpc.server_timeout=30
# rpc client configs (like enable to keep cache consistency)
rpc.remote_url=127.0.0.1:8090
#rpc.client_connect_timeout=20
#rpc.client_reconnect_period=10
#rpc.client_read_timeout=40
#rpc.client_retries=3
#rpc.client_load_balancer=consistentHash
# lightweight load balancing (beta)
server.id=server-1
server.role=master
到此所有配置文件都改完了。
2.1.4、启动
启动分为"首次启动"和"非首次启动",这么区分是因为在第一次启动前需要初始化后端数据库,然后启动服务。 而在人为停掉服务后,或者其他原因需要再次启动服务时,因为后端数据库是持久化存在的,直接启动服务即可。
HugeGraphServer启动时会连接后端存储并尝试检查后端存储版本号,如果未初始化后端或者后端已初始化但版本不匹配时(旧版本数据),HugeGraphServer会启动失败,并给出错误信息。
(1)、初次启动
进入目录
cd /opt/hugegraph12/hugegraph-0.12.0
先执行
./bin/init-store.sh
(2)、启动server
./bin/start-hugegraph.sh
Starting HugeGraphServer...
Connecting to HugeGraphServer (http://127.0.0.1:8089/graphs)....OK
测试是否成功
结果:
{ "graphs": [ "hugegraph" ]}
2.1、使用安装方法三:源码编译
2.1.1 拉取代码并修改配置
进入idea git clone :https://github.com/apache/incubator-hugegraph.git
把12 版本的代码拉下来,目录结构如下图:

找到我们需要修改的配置文件如图:
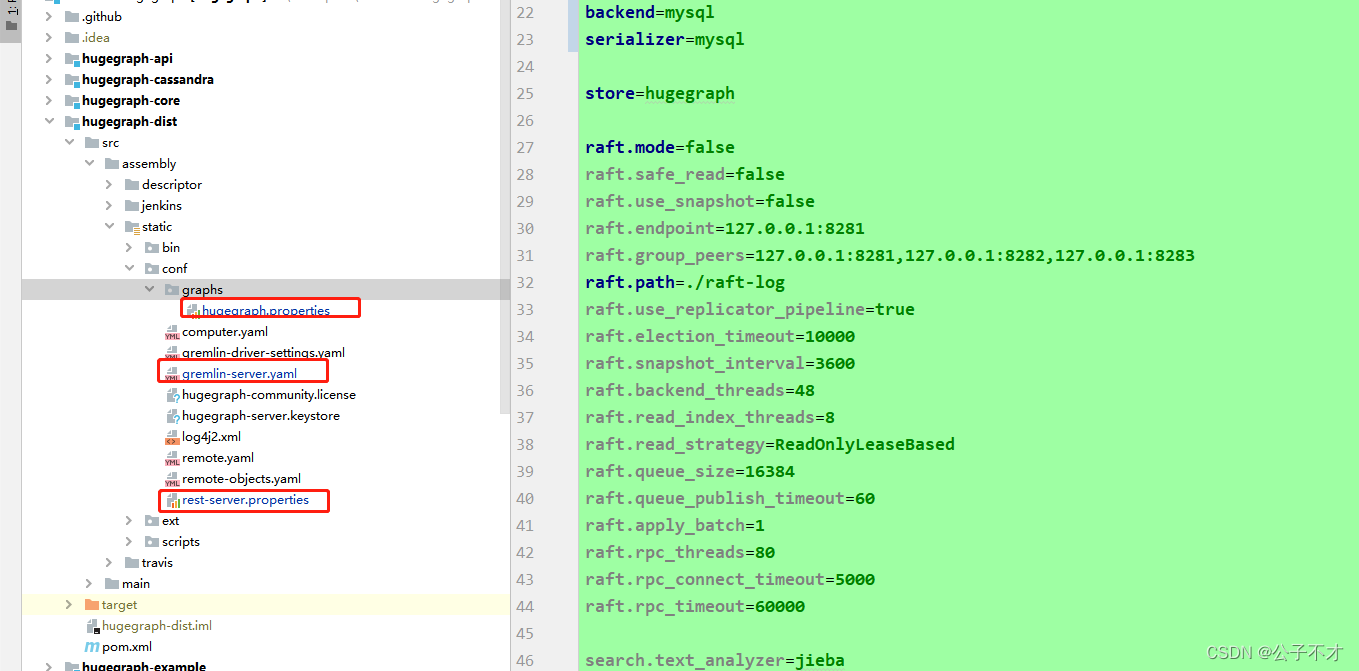
hugegraph.properties 的修改和在linux安装配置的修改内容一样。
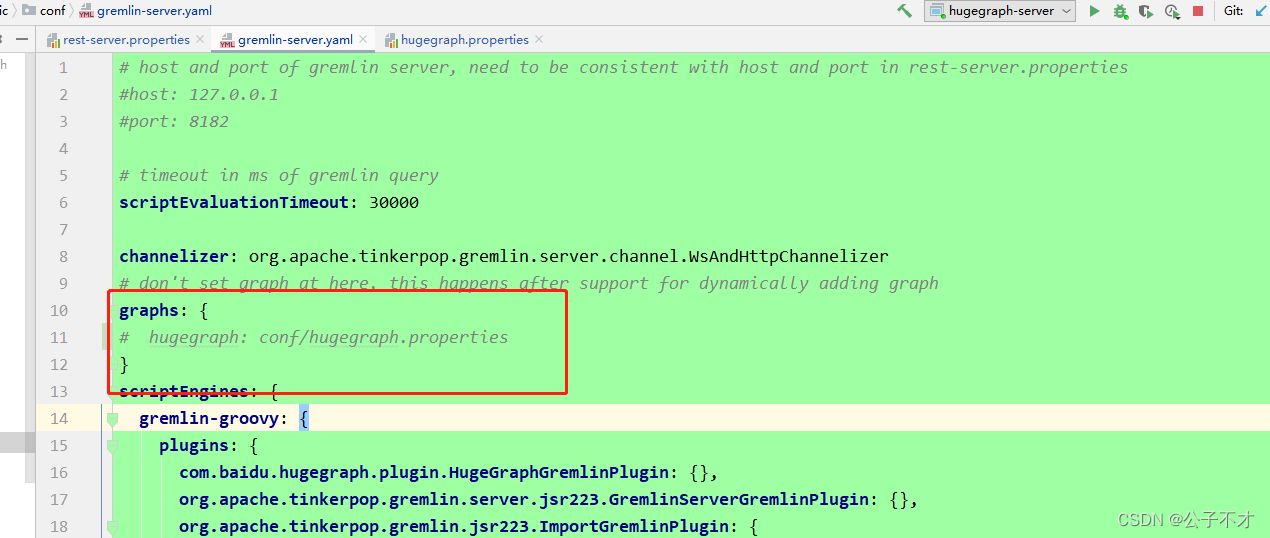
gremlin-server.yaml 修改
由于win的路径问题,默认配置files: [conf/empty-sample.groovy]会找不到empty-sample.groovy这个文件,这里有两种解决办法
1、将files: [conf/empty-sample.groovy]注释掉 (使用这个方式即可)
2、将empty-sample.groovy文件copy到/下,并修改file为files: [empty-sample.groovy]
如图:

rest-server.properties 修改,如图:
2.1.2、初始化数据库(仅第一次启动前需要)


2.1.3、启动服务

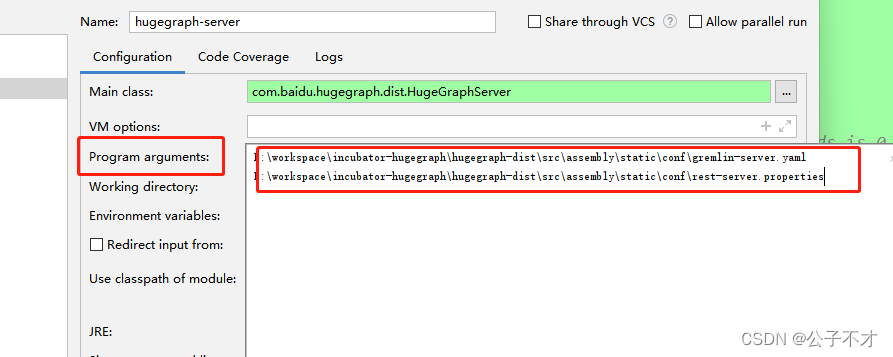
运行,无报错即成功,测试方式和之前一样。
以此启动的服务作为本地服务器,仅供学习或本地开发使用,若作为公司服务则不推荐该方法
3. HugeGraph-Hubble 安装配置和使用
至此HugeGraph-server的安装配置都已讲完。
HugeGraph-Hubble的安装配置请看下一篇文章,HugeGraph-Hubble安装配置和简单使用
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线