hadoop安装_接着需要把本地文件系统的“/usr/local/hadoop/etc/hadoop”目录中的所有xm-程序员宅基地
技术标签: spark hadoop和spark hadoop
写在前面
本教程使用的环境是虚拟机VM安装的ubuntu16.04,提供给需要的网友下载
链接:https://pan.baidu.com/s/1G9fXGBgdevkp-mdHkSIMPg?pwd=7vzl
提取码:7vzl
1、安装ssh
sudo apt-get install openssh-server
安装后,可以使用如下命令登录本机:
ssh localhost
执行该命令后会出现提示信息,输入yes,然后按提示输入密码hadoop

输入命令exit退出SSH,回到原先的终端窗口;然后,利用ssh-keygen生成密钥,并将密钥加入到授权中,命令如下:
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车即可
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时,再执行ssh localhost命令,无需输入密码就可以直接登录了
2、安装java环境
jdk下载
链接:https://pan.baidu.com/s/1eXSqx8hXoyEqg76tkZIWwA?pwd=qzo1
提取码:qzo1
执行如下命令创建/usr/lib/jvm目录用来存放JDK文件:
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
执行如下命令对安装文件进行解压缩:
cd ~ #进入hadoop用户的主目录
cd Downloads
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
添加环境变量
vim ~/.bashrc
添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
Source ~/.bashrc
3、 下载安装文件
文件下载地址
链接:https://pan.baidu.com/s/15KCPJ_AcRcsgBzy9ysw6NA?pwd=n9ho
提取码:n9ho
使用hadoop用户登录Linux系统,打开终端,执行如下命令:
sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop解压后即可使用,可以输入如下命令来检查 Hadoop是否可用,成功则会显示 Hadoop版本信息:
cd /usr/local/hadoop
./bin/hadoop version
4、伪分布式模式配置
1)修改配置文件
修改以后,/usr/local/hadoop/etc/hadoop/core-site.xml文件的内容如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同样,需要修改配置文件/usr/local/hadoop/etc/hadoop/hdfs-site.xml,修改后的内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
2)执行名称节点格式化
修改配置文件以后,要执行名称节点的格式化,命令如下:
cd /usr/local/hadoop
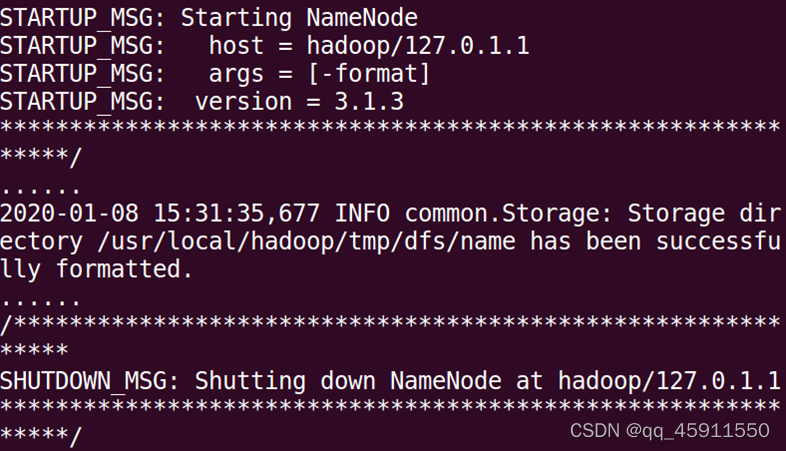
./bin/hdfs namenode -format
如果格式化成功,会看到“successfully formatted”的提示信息
3) 启动Hadoop
执行下面命令启动Hadoop:
cd /usr/local/hadoop
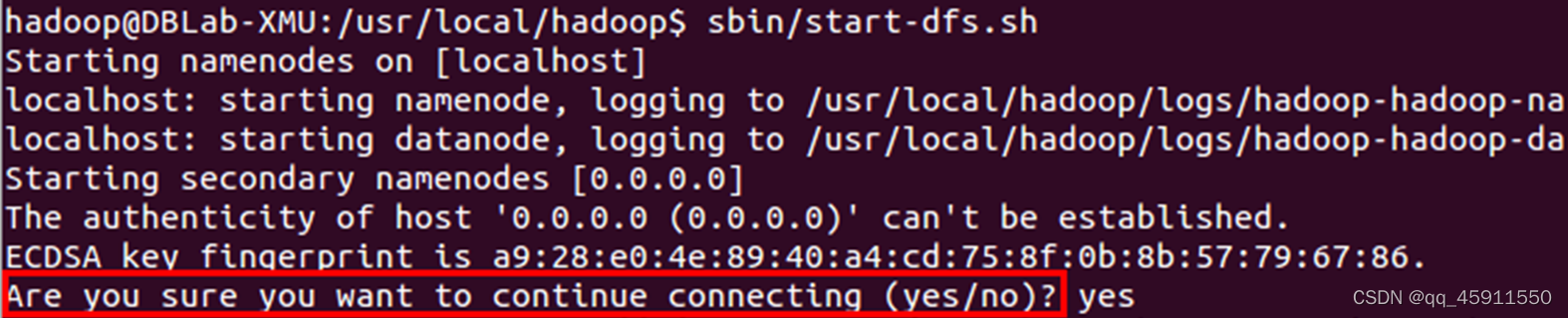
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
如果出现SSH提示,输入yes即可:
4)运行Hadoop伪分布式实例
要使用HDFS,首先需要在HDFS中创建用户目录,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /user/hadoop
接着把/usr/local/hadoop/etc/hadoop目录中的所有xml文件作为输入文件,复制到分布式文件系统HDFS中的/user/hadoop/input目录中,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir input #在HDFS中创建hadoop用户对应的input目录
./bin/hdfs dfs -put ./etc/hadoop/*.xml input #把本地文件复制到HDFS中
运行Hadoop自带的grep程序,命令如下:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
运行结束后,可以通过命令查看HDFS中的output文件夹中的内容:
./bin/hdfs dfs -cat output/*
执行结果如图所示

5)关闭Hadoop
cd /usr/local/hadoop
./sbin/stop-dfs.sh
4、配置PATH环境
首先使用vim编辑器打开~/.bashrc这个文件,在这个文件的最前面位置加入一行:
export PATH=$PATH:/usr/local/hadoop/sbin
如果要继续把其他命令的路径也加入到PATH变量中,也需要修改~/.bashrc文件。用英文冒号“:”隔开,把新的路径加到后面即可,如下所示:
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin
添加后,执行命令source ~/.bashrc使设置生效。设置生效后,在任何目录下启动Hadoop,都只要直接输入start-dfs.sh命令即可,同理,停止Hadoop,也只需要在任何目录下输入stop-dfs.sh命令即可。
声明:本内容为整理诸峰老师课件而来
智能推荐
《第一行代码》(第二版)广播的问题及其解决_代码里的广播错误-程序员宅基地
文章浏览阅读2.6k次,点赞5次,收藏13次。1)5.2.1弹出两次已连接或者未连接这是因为你同时打开了流量和WiFi,他就会发出两次广播。2)5.3.1中发送自定义广播问题标准广播未能弹出消息:Intent intent=new Intent("com.example.broadcasttest.MY_BROADCAST");sendBroadcast(intent);上述已经失效了。修改:Intent intent=new Intent("com.example.broadcasttest...._代码里的广播错误
K8s 学习者绝对不能错过的最全知识图谱(内含 58个知识点链接)-程序员宅基地
文章浏览阅读249次。作者 |平名 阿里服务端开发技术专家导读:Kubernetes 作为云原生时代的“操作系统”,熟悉和使用它是每名用户的必备技能。本篇文章概述了容器服务 Kubernet..._k8知识库
TencentOS3.1安装PHP+Nginx+redis测试系统_tencentos-3.1-程序员宅基地
文章浏览阅读923次。分别是etc/pear.conf,etc/php-fpm.conf, etc/php-fpm.d/www.conf,lib/php.ini。php8安装基本一致,因为一个服务期内有2个版本,所以注意修改不同的安装目录和端口号。可以直接使用sbin下的nginx命令启动服务。完成编译安装需要gcc支持,如果没有,使用如下命令安装。安装过程基本一致,下面是安装7.1.33的步骤。执行如下命令,检查已经安装的包和可安装的包。执行如下命令,检查已经安装的包和可安装的包。执行如下命令,检查已经安装的包和可安装的包。_tencentos-3.1
urllib.request.urlopen()基本使用_urllib.request.urlopen(url)-程序员宅基地
文章浏览阅读3.1w次,点赞21次,收藏75次。import urllib.requesturl = 'https://www.python.org'# 方式一response = urllib.request.urlopen(url)print(type(response)) # <class 'http.client.HTTPResponse'># 方式二request = urllib.request.Req..._urllib.request.urlopen(url)
如何用ChatGPT+GEE+ENVI+Python进行高光谱,多光谱成像遥感数据处理?-程序员宅基地
文章浏览阅读1.5k次,点赞12次,收藏15次。如何用ChatGPT+GEE+ENVI+Python进行高光谱,多光谱成像遥感数据处理?
RS485总线常识_rs485 差分走綫間距-程序员宅基地
文章浏览阅读1.2k次。RS485总线常识 2010-10-12 15:56:36| 分类: 知识储备 | 标签:rs485 总线 传输 差分 |字号大中小 订阅RS485总线RS485采用平衡发送和差分接收方式实现通信:发送端将串行口的TTL电平信号转换成差分信号A,B两路输出,经过线缆传输之后在接收端将差分信号还原成TTL电平信号。由于传输线通常使用双绞线,又是差分传输,所_rs485 差分走綫間距
随便推点
移植、制作uboot、Linux(一)_uboot制作-程序员宅基地
文章浏览阅读621次。u-boot、linux烧录_uboot制作
windows下安装git和gitbash安装教程_64-bit git for windows setup.-程序员宅基地
文章浏览阅读1.2w次,点赞10次,收藏44次。windos上git安装,git bash安装_64-bit git for windows setup.
环形链表(算法java)_java 实现环形链表-程序员宅基地
文章浏览阅读196次。环形链表(算法java)的两种解决方法_java 实现环形链表
docker部署Airflow(修改URL-path、更换postgres -->myslq数据库、LDAP登录)_airflow docker-程序员宅基地
文章浏览阅读5.7k次。Airflow什么是 Airflow?Airflow 的架构Airflow 解决哪些问题一、docker-compose 安装airflow(postgres)1、创建启动文件airflow-docker-compose.yml.1.1、添加挂载卷,需要修改airflow-docker-compose.yml的位置2、创建本地配置文件airflow.cfg2.1、如果想修改WEB URL地址,需要修改airflow.cfg中以下两个地方3、之后up -d直接启动即可web访问地址:二、存储数据库更换post_airflow docker
计算机毕业设计springboot高校教务管理系统532k79【附源码+数据库+部署+LW】-程序员宅基地
文章浏览阅读28次。选题背景:随着社会的发展和教育的普及,高校教务管理系统在现代高等教育中扮演着至关重要的角色。传统的手工管理方式已经无法满足高校日益增长的规模和复杂的管理需求。因此,开发一套高效、智能的教务管理系统成为了当今高校管理的迫切需求。选题意义:高校教务管理系统的开发具有重要的意义和价值。首先,它可以提高高校教务管理的效率和准确性。通过自动化处理学生选课、排课、考试安排等繁琐的事务,大大减轻了教务人员的工作负担,提高了工作效率。同时,系统可以实时更新学生信息和课程信息,减少了数据错误和冗余,保证了管理的准确性
javaint接收float_Java Integer转换double,float,int,long,string-程序员宅基地
文章浏览阅读132次。首页>基础教程>常用类>常用 Integer类Java Integer转换double,float,int,long,stringjava中Integer类可以很方便的转换成double,float,int,long,string等类型,都有固定的方法进行转换。方法double doubleValue() //以 double 类型返回该 Integer 的值。flo..._java integet接收float类型的参数