java基础进阶六-泛型_泛型强转-程序员宅基地
泛型,可以看做一种“模板代码”。
什么是“模板代码”呢?
以ArrayList为例。
在JDK1.5引入泛型之前,ArrayList采取的方式是:在内部塞入一个Object[] array。
public class ArrayList {
private Object[] array;
private int size;
public void add(Object e) {
...}
public void remove(int index) {
...}
public Object get(int index) {
...}
}
如果用JDK1.5以前的ArrayList存储String类型,那么会有以下两个缺点(其实是问题的一体两面):
● 需要强制转型
● 强制转型容易出错
代码要这么写:
ArrayList list = new ArrayList();
list.add("Hello");
// 获取到Object,必须强制转型为String:
String first = (String) list.get(0);
为什么要强制转型?因为String是真正的类型,转型后才能使用String特有的方法,比如replace()。
为了解决这些问题,我们必须把ArrayList变成一种模板。
所谓模板,就是我能做的都给你做了,少量易变动的东西我留出来,你自己DIY去。
同理,ArrayList也是一种模板,能写的方法都给你写了,但变量类型我定不了,于是抽成类型参数:
public class ArrayList<T> {
private T[] array;
private int size;
public void add(T e) {
...}
public void remove(int index) {
...}
public T get(int index) {
...}
}
T可以是任何class类型,反正我已经帮你参数化了,你自己定。
这样一来,我们就实现了:只需编写一次模版,可以创建任意类型的ArrayList:
// 创建可以存储String的ArrayList:
ArrayList<String> strList = new ArrayList<>();
// 创建可以存储Float的ArrayList:
ArrayList<Float> floatList = new ArrayList<>();
// 创建可以存储Person的ArrayList:
ArrayList<Person> personList = new ArrayList<>();
因此,泛型类就是模板类,你可以理解为此时ArrayList内部自动被赋值成这样(编译器层面):
public class StringArrayList {
private String[] array;
private int size;
public void add(String e) {
...}
public void remove(int index) {
...}
public String get(int index) {
...}
}
由编译器针对类型作检查:
strList.add("hello"); // OK
String s = strList.get(0); // OK,因为上面add()保证了只能添加String类型,所以无需强制转型
strList.add(new Integer(123)); // compile error!
Integer n = strList.get(0); // compile error!
这样一来,既实现了编写一次万能匹配,又能通过编译器保证类型安全:这就是泛型。
形式参数类型和实际参数类型
泛型是一种技术,而可以理解为对泛型类和泛型接口的统称,类似ArrayList 中的T不叫泛型,而是叫做类型参数,也叫形式类型参数。
使用泛型时,比如ArrayList,T被替换为String,可以看做是对T的“赋值”,这里的String称为实际类型参数(actual type parameter)。
实际类型参数用来为类型参数赋值,把ArrayList由泛化通用的模板变为特定类型的类。
你还可以把泛型理解为:变量是对数据的抽取,而泛型是对变量类型的抽取,抽取成类型参数,抽象层次更高。
源码解析:ArrayList与泛型
文章中经过一次次演化,我们的ArrayList最终变成了这样:
public class ArrayList<T> {
private T[] array;
private int size;
public void add(T e) {
...}
public void remove(int index) {
...}
public T get(int index) {
...}
}
ArrayList内部实际上仍然沿用了之前的Object[]。
那么,ArrayList为什么还能进行类型约束和自动类型转换呢?
上面提到泛型是对变量类型的抽取,它把原本必须确定的变量类型(比如String)弄成了变量E,最终等到了代码模板。
但是有人就会质疑了,对象类型不确定,jvm怎么创建对象呢?
要回答这个问题,我们必须了解Java的两个阶段:编译期、运行期。你可以理解为Java代码运行有4个要素:
● 源代码
● 编译器
● 字节码
● 虚拟机
也就是说java有两台很重要的机器,编译器和虚拟机。
在代码编写阶段,我们确实引入了泛型对变量类型进行泛型抽取,让泛型不是特定的
public class ArrayList<T> {
private T[] array;
private int size;
public void add(T e) {
...}
public void remove(int index) {
...}
public T get(int index) {
...}
}
模板定好后,如果我们希望这个ArrayList只处理String类型,就传入类型参数,把T“赋值为”String,比如ArrayList,此时你可以理解为代码变成了这样:
public class ArrayList<String> {
private String[] array;
private int size;
public void add(String e) {
...}
public void remove(int index) {
...}
public String get(int index) {
...}
}
但事实是这样的吗?
我们必须去了解泛型的底层机制。
泛型擦除与自动类型转换
我们来研究以下代码:
public class GenericDemo {
public static void main(String[] args) {
UserDao userDao = new UserDao();
User user = userDao.get(new User());
List<User> list = userDao.getList(new User());
}
}
class BaseDao<T> {
public T get(T t){
return t;
}
public List<T> getList(T t){
return new ArrayList<>();
}
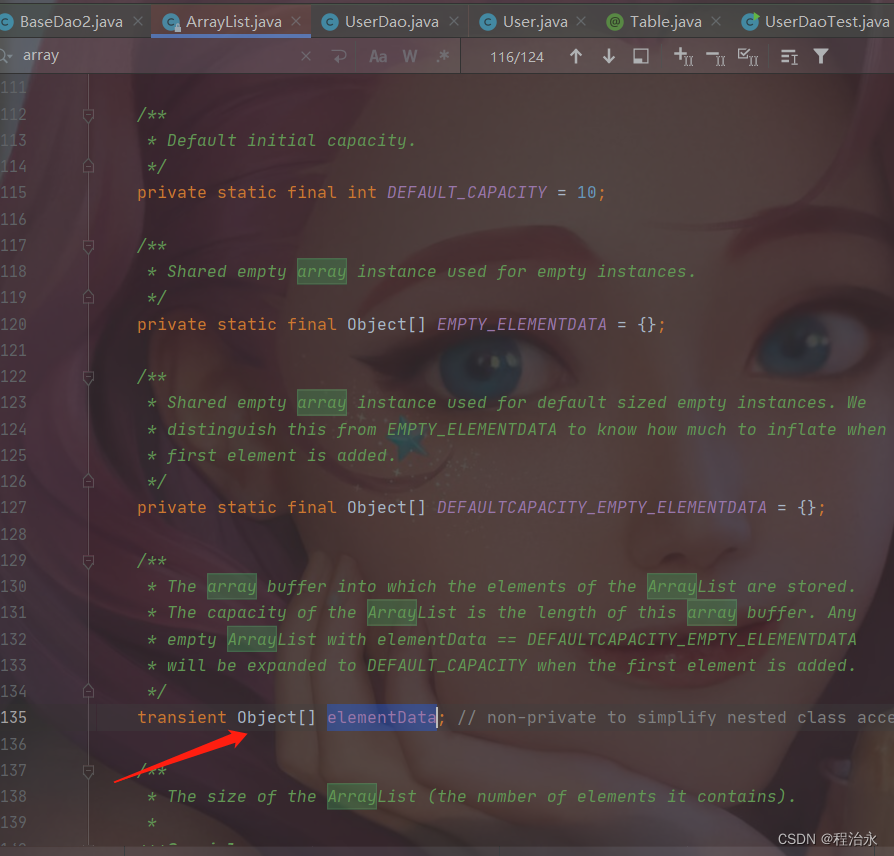
}
class UserDao extends BaseDao<User> {
}
class User{
}
通过反编译工具,反编译字节码得到:
public class GenericDemo {
// 编译器会为我们自动加上无参构造器
public GenericDemo() {
}
public static void main(String args[]) {
UserDao userDao = new UserDao();
/**
* 1.原先代码是 User user = userDao.get(new User());
* 编译器加上了(User),做了类型强转
*/
User user = (User)userDao.get(new User());
/**
* 2.List<User>的泛型被擦除了,只剩下List
*/
java.util.List list = userDao.getList(new User());
}
}
class BaseDao {
BaseDao() {
}
// 编译器编译后的字节码中,其实是没有泛型的,泛型T底层其实是Object
public Object get(Object t) {
return t;
}
public List getList(Object t) {
return new ArrayList();
}
}
// BaseDao<User>泛型也没了
class UserDao extends BaseDao {
UserDao(){
}
}
class User {
User() {
}
}
反编译之后 ,我们发现其实泛型T在编译之后就会消失,底层其实还是Object。既然泛型底层用Object接收,那么:
● 对于ArrayList,为什么add(Integer i)会编译报错?
● 对于ArrayList,list.get(0)为什么不需要强制转型?
因为泛型本身是一种编译时的机制,是Java程序员和编译器之间的协议。
ArrayList是已经编写好的代码模板,底层还是Object[]接收元素,但我们可以通过ArrayList的语法形式,告诉编译器:“我希望你把这个ArrayList看做StringArrayList”。
换句话说,编译器会根据我们指定的实际类型参数(ArrayList中的String),自动地在编译器做好语法约束:
● ArrayList的add(E e)只能传String类型
● ArrayList的get(i)返回值一定是String(编译后自动强转,无需我们操心)
基于上面的实验,我们可以得到以下4个结论:
- 泛型是JDK专门为编译器创造的语法糖,只在编译器期,由编译器解析,虚拟机不知情。
- 存入:普通类继承泛型类并给变量类型赋值,就能让编译器帮忙进行类型校验。
- 取出:代码编译时,编译器底层会根据实际类型参数,自动进行类型转换,无需程序员在外部手动强转
- 实际上,编译后的Class文件还是JDK1.5以前的样子,虚拟机看到的仍然是Object。
我们可以通过反射跳过泛型的约束:
public class GenericClassDemo {
public static void main(String[] args) throws Exception {
ArrayList<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
// list.add(1);//报错
//泛型的约束只存在与编译阶段,底层仍然是Object,在运行期间可以往list中存放任意类型的数据
//通过反射跳过泛型约束
Method me = list.getClass().getDeclaredMethod("add", Object.class);
me.invoke(list,1);
for (Object s : list) {
System.out.println(s);
}
}
}
泛型和多态
经过上面的介绍,你会觉得泛型只是和编译器有关,但实际上泛型的成功离不开多态。
泛型固然强悍,既能约束入参,又能对返回值进行i自动强转。但你有没有想过,对于编译器的智能转换,其实是需要多态的支持的。
多态的代码模板本质就是:用Object接收一切对象,用泛型+编译器限定特定对象,用多态支持类型强转。
当泛型完成了“编译时检查”和“编译时自动类型转换”的作用后,底层还是要多态来支持。
你可以理解为泛型有以下作用:
- 抽取代码模板:代码复用并且可以通过类型参数与编译器达成约定
- 类型校验:编译时阻止不匹配元素进入Object[]
- 类型强转:根据泛型自动强转(多态,向下转型)

但实际运行时,Object[]接收特定类型的元素,体现了多态,取出Object[]元素并强转,也体现了多态。
泛型真的把对象类型弄成了变量吗
通过反编译能够看到,其实根本没有所谓的泛型类型T,底层还是Object,所以当我们new 一个ArrayList时,JVM根本不会傻傻等着T被确定.T作为类型参数,只作用于编译阶段,用来限制存入和强转取出,JVM是感知不到的。
所以对于泛型类本身,它的类型是确定的,就是Object或Object[]数组。
一点补充
为什么泛型不支持基本类型?
我们太依赖于泛型只能使用引用类型,但不知道为什么?
以ArrayList为例:底层还是用Object[]数据接收,存进去时Object obj = new User(),体现了多态,取出来时,没有记住,就可以变成转成(Cat)obj了,就强转异常了,于是JDK1.5引入了泛型,在编译期进行约束并帮我们自动强转。
可以说,本身泛型的引入就是为了解决引用类型强转易出错的问题,也就自然不会考虑基本类型。
也有一种说法是:JDK1.5不仅引入了泛型,同时也引入了自动拆装箱特性,所以int完全可以用integer代替,也就无需支持int了。
但归根结底,Java泛型之所以无法支持基本类型,还是因为存在泛型擦除,底层仍是Object,而基本类型无法直接赋值给Object类型,导致JDK只能用自动拆装箱特性来弥补,而自动拆装箱会带来性能损耗。
泛型边界
学习一下泛型通配符。
简单泛型
假设有一个需求:设计一个print方法打印任意类型的List。
你可能会结合之前的认识,这样设计:
public class Demo{
public static void main(String[] args) {
List<Integer> integerList = new ArrayList<>();
print(integerList);
}
public static void print(List<Integet> list){
//打印
}
}
看着没有问题,但是会报错:

你想了想,Object是所有对象的父类,我改成List吧:
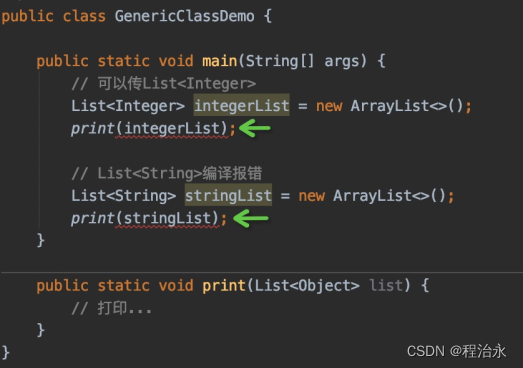
这是为什么呢?
实际编码时,常见的错误写法如下:
// 错误写法1:间接传递(通常发生在方法传参,比如将stringList传给print(List<Object> list))
List<String> stringList = new ArrayList<>();
List<Object> list = stringList;
// 错误写法2:直接赋值
List<Object> list = new ArrayList<String>();
总之,list引用和实例指向的list容器类型必须一致(赋值操作左右两边的类型必须一致)。
这就和我们前面了解的就有点异样了,泛型底层是Object/Object[]数组,所以上面的几种写法归根到底都是Object[]赋值给Object[],理论上是没有问题的。
既然底层都支持了,为什么编译器要禁止这种写法呢?
思考:
首先,Object和String之间确实有继承关系,但List和List没有,不能用多态的思维考虑这个问题(List和ArrayList才是继承/实现关系)。
对于:
List list = new ArrayList();
左边List的意思是希望编译器帮它约束存入的元素类型为Object,而右边new ArrayList()则希望约束存入的类型为String,此时就会出现两个约束标准,而它们却是对同一个List的约束,是自相矛盾的。
泛型的指向和存取
前面在介绍泛型的时候,我们观察的维度只有存入和取出,实际上泛型还有一个很重要的约束:指向。
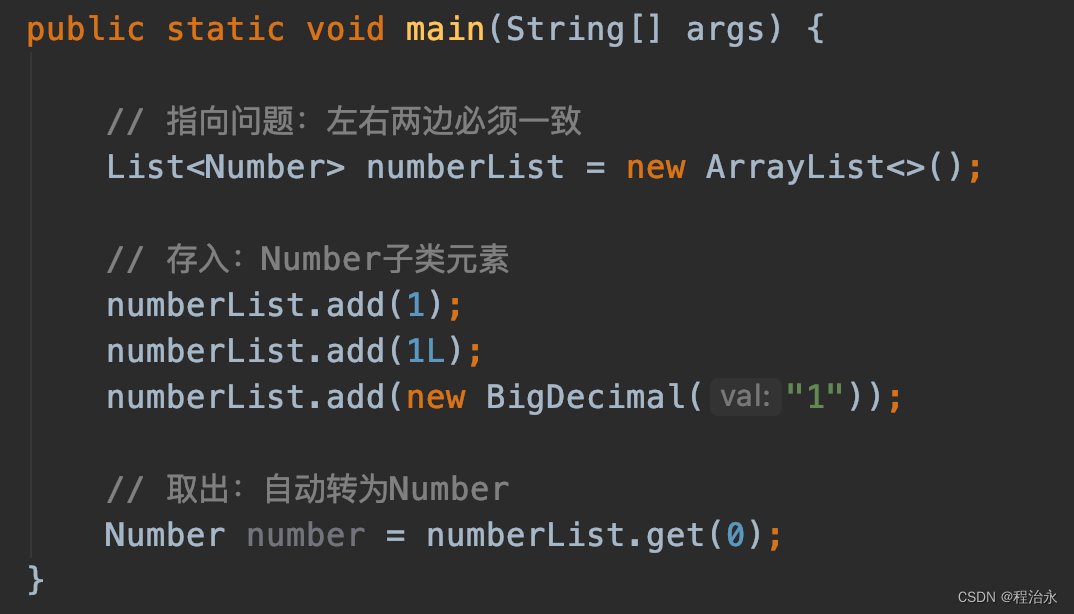
千万别以为List 只能存number类型的数据,只要是number子类都可以存,因为对于List取出的时候统一向上转型为number类型,很安全。
对于简单泛型而言:
● List指向:只能指向List,左右两边泛型必须一致(所以简单泛型解决不了print(List<???> list)的通用性问题)
● List存入:可以存入Integer/Long/BigDecimal…等Number子类元素
● List取出:自动按Number转(存在多态,不会报错)
通配符
既然泛型强制要求左右两边类型参数必须一致,是否意味着永远无法封装一个方法打印任意类型的List?如何既能享受泛型的约束(防止出错),又能保留一定的通用性呢?
答案是:通配符
List、BaseDao这样的称为简单泛型,把extends、super、?称为通配符。
而简单泛型和通配符组合后又可以得到更为复杂的泛型,比如? extends T、? super T、?等。简而言之,通配符可以用来调节泛型的指向和存取之间的矛盾。
extends:上边界通配符
通配符所谓的上边界、下边界其实是对“指向”来说的。比如
List<? extends Number> list = new ArrayList<Integer>();
extends是上边界通配符,所以对于List<? extends Number>,元素类型的天花板就是Number,右边List的元素类型只能比Number“低”。
换句话说,List<? extends Number>只能指向List、List等子类型List,不能指向List、List。
记忆方法: List<? extends Number> list = ...,把?看做右边List的元素(暂不确定,用?代替),? extends Number表示右边元素必须是Number的子类。
你可能会问了:
之前简单泛型List不能指向List,怎么到了extends这就可以了。这不扯淡吗?
其实换个角度就是,Java规定简单泛型左右类型必须一致,但有些情况又要考虑通用性,所以又搞出了extends,允许List<? extends Number>指向子类型List。
extends小结:
● List<? extends Number>指向:Java允许extends指向子类型List,比如List<? extends Number>允许指向List
● List<? extends Number>存入:禁止存入(防止出错)
● List<? extends Number>取出:由于指向的都是子类型List,所以按Number转肯定是正确的
相比简单泛型,extends虽然能大大提高指向的通用性,但为了防止出错,不得不禁止存入元素,也算是一种取舍。换句话说,print(List<? extends Number> list)对于传入的list只能做读操作,不能做写操作。
super:下边界通配符
super是下边界通配符,所以对于List<? super Integer>,元素类型的地板就是Integer,右边List的元素类型只能比Integer“高”。换句话说,List<? super Integer>只能指向List、List等父类型List。
记忆方法: List<? super Integer> list = …,把?看做右边List的元素(暂不确定,用?代替),? super Integer表示右边元素必须是Integer的父类。
super的特点是:
● List<? super Integer>指向:只能指向父类型List,比如List、List
● List<? super Integer>存入:只能存Integer及其子类型元素
● List<? super Integer>取出:只能转Object
?:无界通配符
?就很简单了。它类似于List<? extends Object>,允许指向任意类型的List。
● 由于指向的List不确定,并且这些List没有共同的子类,所以找不到一种类型的元素,能保证add()时百分百不出错,所以禁止存入。
● 由于指向的List不确定,并且这些List没有共同的父类(除了Object),所以只能用Object接收。
泛型类和泛型方法
回顾一下泛型类是怎么出现的
话说JDK1.5以前,还没引入泛型时ArrayList大概是这样的:
public class ArrayList {
private Object[] array;
private int size;
public void add(Object e) {
...}
public void remove(int index) {
...}
public Object get(int index) {
...}
}
它有这个最大的问题是:无法限制传入的元素类型、取出时又容易发生ClassCastException。最直观的做法是使用期望类型的元素数组,比如:
public class StringArrayList {
// 因为这种ArrayList只存String,所以不需要用Object[]兼容所有类型,只要String[]即可
private String[] array;
private int size;
public void add(String e) {
...}
public void remove(int index) {
...}
public String get(int index) {
...}
}
但不可能为所有类型都编写专门的XxxArrayList,于是JDK就推出了泛型:抽取一种类模板,方法、变量都写好了,但变量的类型抽取成“形式类型参数”:
public class ArrayList<T> {
private Object[] array; // 本质还是Object数组,只对add/get做约束。就好比垃圾桶本身并没有变化,只是加了检测器做投递约束
private int size;
public void add(T e) {
...}
public void remove(int index) {
...}
public T get(int index) {
...}
}
再配合编译器做约束:比如ArrayList表示告诉编译器,帮我盯着点,我只存取User类型的元素。
简而言之,泛型类的出现就是为了“通用”,而且还能在编译期约束元素的类型。
“泛型类的方法”并不是泛型方法
class BaseDao<T> {
public T get(T t) {
}
public boolean save(T t) {
}
}
方法里的T和类上的T是同一个,也正因为多个方法操作的POJO类型一致,所以才会被抽取到类上统一声明。
这个T具体是什么类型或者说里面的get()、save()到底操作什么类型的POJO,取决于BaseDao到底被谁继承。比如:
class UserDao extends BaseDao<User> {
}
那么UserDao从BaseDao继承过来的get()、save()其实已经被约束为“只能操作User类型的元素”。
但要清楚,上面的get()、save()只是“泛型类的方法”,而不是所谓的“泛型方法”。
什么是泛型方法
泛型类上的其实是一种声明,如果把类型参数T也看做一种特殊的变量,那么就是变量声明(不是我们一般概念中的变量声明,一个作用于运行期,一个作用于编译期)。
由于泛型类上已经声明了T,所以类中的字段、方法都可以自由使用T。但是当T被“赋值”为某种类型后,就会在编译器的帮助下形成一种强制类型约束,此时这个通用的代码模板也就不再通用了。因而你会发现,对于编译器而言UserDao extends BaseDao里的方法只能操作User,CarDao extends BaseDao里的方法只能操作Car。
这好吗?一般来说,这很好,因为一个Dao操作的肯定是同一张表同一个对象,限定为某个类型反而能避免出错。但大家想想,如果不是BaseDao,而是一个工具类呢?BaseUtils提供通用的操作,XxUtils extends BaseUtils固然没问题,但如果XxUtils希望提供一个方法处理Yy怎么办?如果还想处理Zz呢?
问题的症结并不在于后期想要处理什么类型或者有多少种类型,而是T被过早确定了,从而早早地放弃了“可变性”。
因为对于泛型类的T来说,当UserDao继承BaseDao或者XxUtils继承BaseUtils时,T就被确定为User和Xx了,且已经拒绝了其他可能性,也就无法复用于其他类型。
那么,有没有办法延迟T的确定呢?
有,但泛型类的T已经没办法了,需要另辟蹊径,引入泛型方法。
和泛型类一样,泛型方法使用类型参数前也需要“声明”(要放在返回值的前面):
public class DemoForGenericMethod {
public static void main(String[] args) {
List<String> list = new ArrayList<>(Arrays.asList("1", "2", "3", "4", "5"));
List<String> stringList = reverseList(list);
}
/**
* 一个普通类,也可以定义泛型方法(比如静态泛型方法)
* @param list
* @param <T>
* @return
*/
public static <T> List<T> reverseList(List<T> list) {
List<T> newList = new ArrayList<>();
for (int i = list.size() - 1; i >= 0; i--) {
newList.add(list.get(i));
}
return newList;
}
}
泛型方法中T的确定时机是使用方法时。
泛型方法和泛型类没有必然联系,你可以理解为这两个东西可以各自使用,也可以硬把它们凑在一块,不冲突:
class BaseDao<T> {
// 泛型类的方法
public T get(T t) {
}
/**
* 泛型方法,无返回值,所以是void。<E>出现在返回值前,表示声明E变量
* @param e
* @param <E>
*/
public <E> void methodWithoutReturn(E e) {
}
/**
* 泛型方法,有返回值。入参和返回值都是V。注意,即使这个方法也用E,也和上面的E不是同一个
* @param v
* @param <V>
* @return
*/
public <V> V methodWithReturn(V v) {
return v;
}
}
泛型类与泛型方法的使用场景
比如,在做数据访问层的时候,对一种类型的实体有一系列统一的访问方法,此时采用泛型类会比较合适,而对于接口的统一结果封装则采用泛型方法比较合适,比如:
@Data
@NoArgsConstructor
public class Result<T> implements Serializable {
private Integer code;
private String message;
private T data;
private Result(Integer code, String message, T data) {
this.code = code;
this.message = message;
this.data = data;
}
private Result(Integer code, String message) {
this.code = code;
this.message = message;
this.data = null;
}
/**
* 带数据成功返回
* 请注意,虽然泛型方法也用了T,但和Result<T>里的没关系
* 这里之所以这么写,是因为实际开发时你们会见到很多这种“迷惑性”的写法,放出来作为“反例”,推荐最好使用其他符号,比如K
*
* @param data
* @param <T>
* @return
*/
public static <T> Result<T> success(T data) {
return new Result<>(ExceptionCodeEnum.SUCCESS.getCode(), ExceptionCodeEnum.SUCCESS.getDesc(), data);
}
}
智能推荐
yshon对讲机如何调频率_对讲机频率如何设置?-程序员宅基地
文章浏览阅读524次。展开全部TK2118-3118调频率方法1. 按住MONI键+DIAL键开e68a84e8a2ad3231313335323631343130323136353331333363396461机至显示SELF;2. 按一下LOW显CH1,转动频道旋钮"ENC"选择所需信道;3. 按一下PTT键显------2,按一下LOW键显示接收频率,按住 "1"键转动频道旋钮"ENC"调整数,松开 "1"键转动..._yshon对讲机设置
Linux安装Git并配置完成拉取项目代码和提交(1)-程序员宅基地
文章浏览阅读747次,点赞21次,收藏19次。本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!
数模3—Matlab线性规划、非线性规划、多目标规划(超全解法合集)-程序员宅基地
文章浏览阅读1.9w次,点赞49次,收藏461次。生产两种机床,利润分别为XXX, A机器和B机器加工,两种机器工作时间…若不存在不等式约束,用"[]”代替A和b: [x, fval ] = linprog (f,[],[], Aeq, beq, lb, ub)若不存在等式约束,用"[]”代替Aeq和beq: [x, fval ] = linprog Cf,A,b,[],[] ,lb,ub)A机器和B机器加工,有顺序要求,有不同损耗费用,不同的工作时间…每种资产的平均收益率…结论,4个人攻碉楼,2个人追替身的情况下,百姓的士气最大,最大值为220。_线性规划
stm32f103运行python_microPython 有没有在 STM32F103上运行的固件-程序员宅基地
文章浏览阅读1.7k次。匿名用户1级2017-02-20 回答进入第一个个连接进入之后我们就可以选择红色方框Buid Firmware。之后我们就可以下载相应的固件了,但是这个固件是比较早的就是了,是2015年的固件,所以我们接下来要做的就是来自己编译一个固件。首先我们需要将我们的micropython的github开源项目的内容下载下来。选择下图的图标就是可以下载下来。或者在window或者linux底下直接使用Git..._micropython stm32f103
RK3568平台(时间篇)linux内核延时机制_linux延时-程序员宅基地
文章浏览阅读736次,点赞26次,收藏18次。内核中涉及的延时主要有两种实现方式:忙等待或者睡眠等待。前者阻塞程序,在延时时间到达前一直占用CPU,而后者是将进程挂起(置进程于睡眠状态并释放CPU资源)。所以,前者一般用在延时时间在毫秒以内的精确延时,后者用于延时时间在毫秒以上的长延时。为了充分利用 CPU 资源,使系统有更好的吞吐性能,在对延迟时间的要求并不是很精确的情况下,睡眠等待通常是值得推荐的。_linux延时
集合遍历与删除,java list 交集 并集 差集 去重复并集-程序员宅基地
文章浏览阅读75次。2019独角兽企业重金招聘Python工程师标准>>> ..._java 遍历出所有差集
随便推点
oracle的教材,oracle基础入门教材-程序员宅基地
文章浏览阅读83次。建表create table (column_name1 column_type [not null] [check (expression)][default value] [primary key][references (column_name)],column_name2 column_type [not null] [check (expression)][default value] ..._oracle最新教材
MariaDB数据库安装与使用_使用提供的数据库软件包安装数据库mariadb。使用root用户,登录数据库,将反馈信息-程序员宅基地
文章浏览阅读410次。MariaDB数据库管理系统安装yum install mariadb mariadb-server开启systemctl start mariadb开机启动systemctl enable mariadb初始化mariaDB服务操作涉及下面5个步骤。1 设置root管理员在数据库中的密码值(默认空值,直接回车)2 设置root管理员在数据库中的专有密码。(设置密码)3 随后删除匿名账户,并使用r..._使用提供的数据库软件包安装数据库mariadb。使用root用户,登录数据库,将反馈信息
BGP防环机制_allow-as-loop-程序员宅基地
文章浏览阅读2.5k次。EBGP之间使用AS号来防环,可通过命令allow-as-loop来解除。IBGP水平分割:从IBGP邻居学到的BGP路由不发送给IBGP邻居路由反射器中的:originator-id和cluster-id 起源id和集群id路由聚合时会自动产生指向null的路由(无论手动和自动都会)IBGP学到的路由默认不能引入到IGP中( EBGP可以引入),可通过命令配置。用实验来模拟一下最后一个,IBGP学到的路由默认不能引入IGP中,可以用命令修改,import-bgp ibgp。AR2和._allow-as-loop
【个人作品】记之-串口日志记录工具-程序员宅基地
文章浏览阅读1.3k次,点赞2次,收藏2次。一款用于记录嵌入式设备的串口调试信息设备,目前可以同时支持两路串口输入数据,且串口参数可配置。
Ros系统配置DNS服务器,ros如何设置dns服务器-程序员宅基地
文章浏览阅读835次。ros如何设置dns服务器 内容精选换一换华为云帮助中心,为用户提供产品简介、价格说明、购买指南、用户指南、API参考、最佳实践、常见问题、视频帮助等技术文档,帮助您快速上手使用华为云服务。本章节指导用户为Linux系统的ECS或BMS主机添加域名解析并添加安全组,防止下载Agent安装包与采集监控数据时出现异常。本章节以ECS为例介绍如何修改DNS和添加安全组,BMS操作步骤类似。添加DNS服务..._ros 路由 dns
Google 安装印象笔记剪藏插件_manifest version 2 is deprecated, and support will-程序员宅基地
文章浏览阅读1w次,点赞3次,收藏4次。有时候我们看到较好的网页内容,希望能够保存到自己的笔记中,方便以后的查看有学习。以往我们习惯搜藏网页,但是时间一长容易忘记已收藏的内容,同时有些东西也会随着原作者删除内容而导致之前收藏过的内容无法看到。为此 使用一款笔记工具保存自己想收藏的内容是十分必要的。https://yinxiang.com/product/webclipper/install/可以安装多种浏览器的插件:这里一安装 谷歌浏览器的插件为例。点击下述网址可以查看官方安装插件的说明。https://yinxiang.com/webclipp_manifest version 2 is deprecated, and support will be removed in 2024. see h