Java基础知识之Map_java map-程序员宅基地
技术标签: jvm java servlet Java基础知识总结
文章目录
一、Map介绍
Map是用于保存具有映射关系的数据集合,它具有双列存储的特点,即一次必须添加两个元素,即一组键值对==><Key,Value>,其中Key的值不可重复(当Key的值重复的时候,后面插入的对象会将之前插入的具有相同的Key值的对象覆盖掉),Value的值可重复。Map作为接口,它最常见的实现类是HashMap和TreeMap,作为接口它抽取了所有实现类的共有方法。同时Map不具有带索引的方法,因此无法使用普通for循环来遍历Map集合
其中<Key,Value>键值对,在Java语言中又被称之为Entry/entry,Map.Entry就相当于Student.name,若name的数据类型为String,则Student.name的数据类型为String,同理若<key,value>中key的数据类型为Integer,value的数据类型为String,则Map.Entry的数据类型为<Integer,String>。
接下来我们将结合代码来具体学习Map相关知识。
二、Map的常用方法 Map应知应会
Map作为接口,它最常见的实现类是HashMap和TreeMap,作为接口它抽取了所有实现类的共有方法,所有实现Map接口的实现类均可使用这些方法。例如HashMap和TreeMap均可使用如下共有方法。
| 方法名 | 说明 |
|---|---|
| V put(K key,V value) | 增添数据 |
| V remove(Object Key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| V get(Object key)() | 根据键获取值 |
| Set keySet() | 获取所有键集合 |
2.1 调用put()方法增添数据
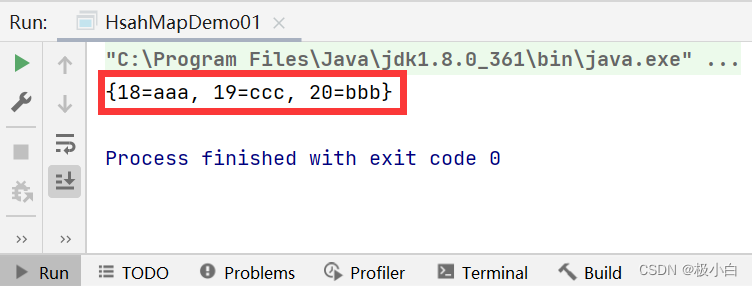
具体实现类为HashMap的Map
public static void main(String[] args) {
//Map为双列存储(一次必须同时存储两个元素),<key,value>key是键,value是值,键不可以重复,值可以重复
//创建一个Key数据类型为Integer类型和Value数据类型为String类型的Map对象,由于Map是一个接口,因此在创建对象时必须指定具体实现类(TreeMap和HashMap均可)
Map<Integer,String> map=new HashMap<>();
//调用put()方法增添数据
map.put(18,"aaa");
map.put(20,"bbb");
map.put(19,"ccc");
//输出数据
System.out.println(map);
}
运行结果:
具体实现类为TreeMap的Map
public static void main(String[] args) {
//Map为双列存储(一次必须同时存储两个元素),<key,value>key是键,value是值,键不可以重复,值可以重复
//创建一个Key数据类型为Integer类型和Value数据类型为String类型的Map对象,由于Map是一个接口,因此在创建对象时必须指定具体实现类(TreeMap和HashMap均可)
Map<Integer,String> map=new TreeMap<>();
//调用put()方法增添数据
map.put(18,"aaa");
map.put(20,"bbb");
map.put(19,"ccc");
//输出数据
System.out.println(map);
}
运行结果:

2.2 调用remove()方法删除数据
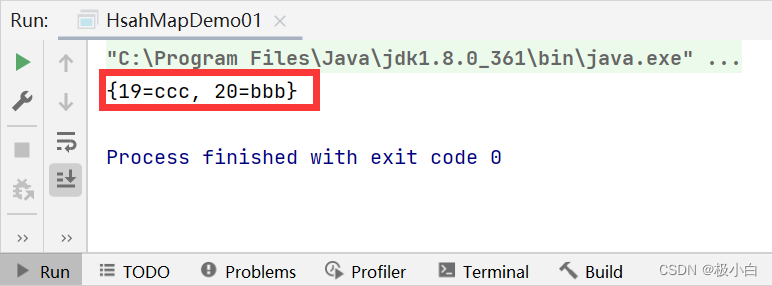
接下来我们以具体实现类为HashMap的Map来举例
public static void main(String[] args) {
//Map为双列存储(一次必须同时存储两个元素),<key,value>key是键,value是值,键不可以重复,值可以重复
//创建一个Key数据类型为Integer类型和Value数据类型为String类型的Map对象,由于Map是一个接口,因此在创建对象时必须指定具体实现类(TreeMap和HashMap均可)
Map<Integer,String> map=new HashMap<>();
//调用put()方法增添数据
map.put(18,"aaa");
map.put(20,"bbb");
map.put(19,"ccc");
//调用remove()方法删除数据
map.remove(18);
//输出数据
System.out.println(map);
}
运行结果:
2.3 调用clear()方法清空数据
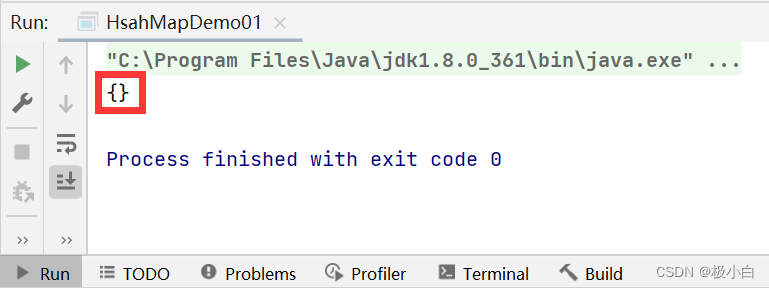
public static void main(String[] args) {
//Map为双列存储(一次必须同时存储两个元素),<key,value>key是键,value是值,键不可以重复,值可以重复
//创建一个Key数据类型为Integer类型和Value数据类型为String类型的Map对象,由于Map是一个接口,因此在创建对象时必须指定具体实现类(TreeMap和HashMap均可)
Map<Integer,String> map=new HashMap<>();
//调用put()方法增添数据
map.put(18,"aaa");
map.put(20,"bbb");
map.put(19,"ccc");
map.put(20,"ddd");
map.put(21,"eee");
//调用clear()方法清空数据
map.clear();
//输出数据
System.out.println(map);
}
运行结果:
2.4 调用containsKey()方法查看是否存在指定的键
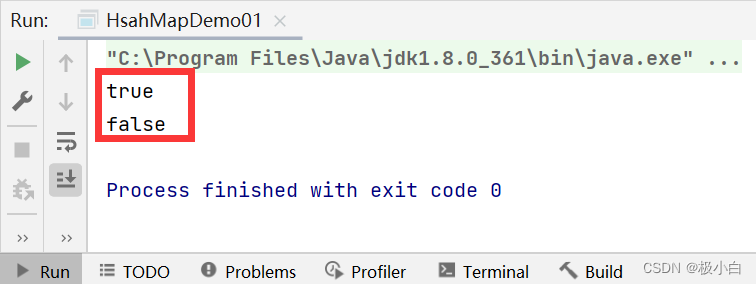
public static void main(String[] args) {
//Map为双列存储(一次必须同时存储两个元素),<key,value>key是键,value是值,键不可以重复,值可以重复
//创建一个Key数据类型为Integer类型和Value数据类型为String类型的Map对象,由于Map是一个接口,因此在创建对象时必须指定具体实现类(TreeMap和HashMap均可)
Map<Integer,String> map=new HashMap<>();
//调用put()方法增添数据
map.put(18,"aaa");
map.put(19,"bbb");
map.put(20,"ccc");
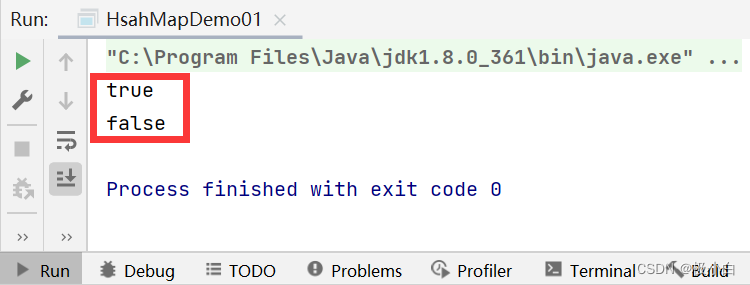
//调用containsKey()方法查看是否存在指定的键
boolean b = map.containsKey(20);
System.out.println(b);
boolean b1 = map.containsKey(21);
System.out.println(b1);
}
运行结果:
2.5 调用containsValue()方法查看是否存在指定的值
public static void main(String[] args) {
//Map为双列存储(一次必须同时存储两个元素),<key,value>key是键,value是值,键不可以重复,值可以重复
//创建一个Key数据类型为Integer类型和Value数据类型为String类型的Map对象,由于Map是一个接口,因此在创建对象时必须指定具体实现类(TreeMap和HashMap均可)
Map<Integer,String> map=new HashMap<>();
//调用put()方法增添数据
map.put(18,"aaa");
map.put(19,"bbb");
map.put(20,"ccc");
//调用containsValue()方法查看是否存在指定的值
boolean bbb = map.containsValue("bbb");
System.out.println(bbb);
boolean ddd = map.containsValue("ddd");
System.out.println(ddd);
}
运行结果:
2.6 调用isEmpty()方法判断集合是否为空
public static void main(String[] args) {
//Map为双列存储(一次必须同时存储两个元素),<key,value>key是键,value是值,键不可以重复,值可以重复
//创建一个Key数据类型为Integer类型和Value数据类型为String类型的Map对象,由于Map是一个接口,因此在创建对象时必须指定具体实现类(TreeMap和HashMap均可)
Map<Integer,String> map=new HashMap<>();
//调用put()方法增添数据
map.put(18,"aaa");
map.put(19,"bbb");
map.put(20,"ccc");
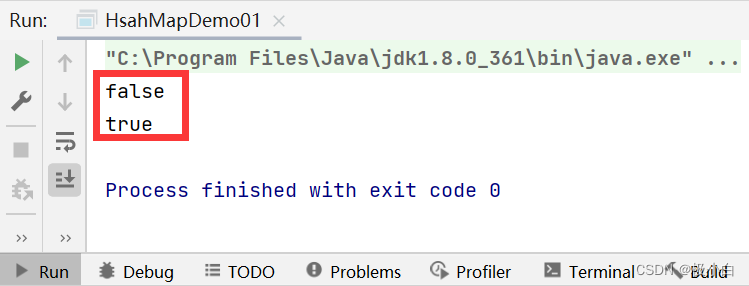
//调用isEmpty()方法查看集合是否为空
boolean empty = map.isEmpty();
System.out.println(empty);
//调用clear()方法清空数据
map.clear();
调用isEmpty()方法查看集合是否为空
boolean empty1=map.isEmpty();
System.out.println(empty1);
}
运行结果:
2.7 调用get()方法根据键获取值
public static void main(String[] args) {
//创建一个Key的数据类型为String,Value数据类型为Integer的Map对象,并指明其实现类为HashMap
Map<String ,Integer> map=new HashMap<>();
//调用put()方法增添数据
map.put("zhangsan",18);
map.put("lisi",19);
map.put("wangwu",20);
map.put("zhaoliu",21);
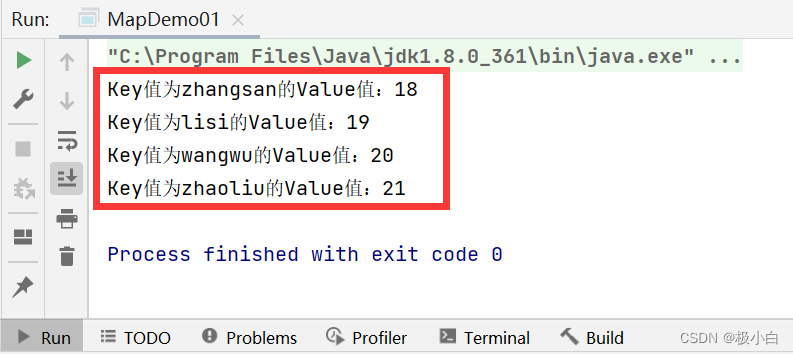
//调用get()方法来获取Key值对应的Value值
//在Map集合中Key值是非常重要的,我们可以通过Key来获取与Key对应的Value,具体方法为集合调用get()方法
Integer zhangsan = map.get("zhangsan");
System.out.println("Key值为zhangsan的Value值:"+zhangsan);
Integer lisi = map.get("lisi");
System.out.println("Key值为lisi的Value值:"+lisi);
Integer wangwu = map.get("wangwu");
System.out.println("Key值为wangwu的Value值:"+wangwu);
Integer zhaoliu = map.get("zhaoliu");
System.out.println("Key值为zhaoliu的Value值:"+zhaoliu);
}
运行结果:
2.8 调用keySet()方法获取所有键集合
public static void main(String[] args) {
//创建一个Key的数据类型为String,Value数据类型为Integer的Map对象,并指明其实现类为HashMap
Map<String ,Integer> map=new HashMap<>();
//调用put()方法增添数据
map.put("zhangsan",18);
map.put("lisi",19);
map.put("wangwu",20);
map.put("zhaoliu",21);
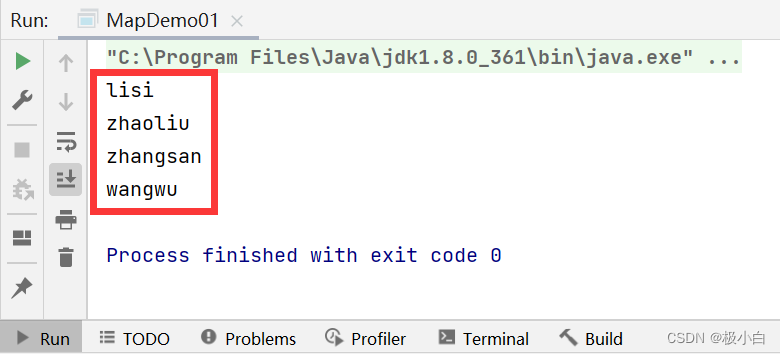
//调用keySet()方法获取所有键的集合,并存入Set集合中
//由于Key键的数据类型为String,因此Set的数据类型为String
Set<String> strings = map.keySet();
for (String string : strings) {
System.out.println(string);
}
}
运行结果:
三、Map的基本操作代码 Map入门
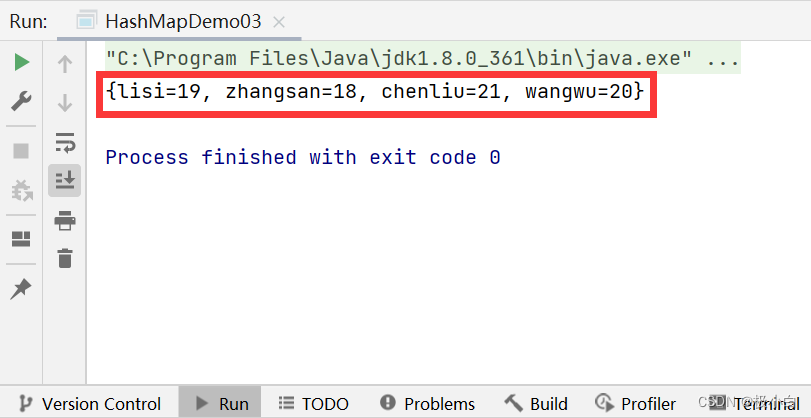
Key数据类型为String类型,Value数据类型为Integer类型的Map
public static void main(String[] args) {
//若要使用Map,我们需要导入import java.util.HashMap;与import java.util.Map;
//我们使用泛型来约束Map的数据类型,Key为String数据类型,Value为Integer数据类型
//其具体实现类为HashMap
Map<String,Integer> map=new HashMap<>();
//使用put()方法来添加数据
map.put("zhangsan",18);
map.put("lisi",19);
map.put("wangwu",20);
map.put("chenliu",21);
//普通打印
System.out.println(map);
}
运行结果:
接下来我们探讨Key的值不可重复(当Key的值重复的时候,后面插入的对象会将之前插入的具有相同的Key值的对象覆盖掉),Value的值可重复此问题
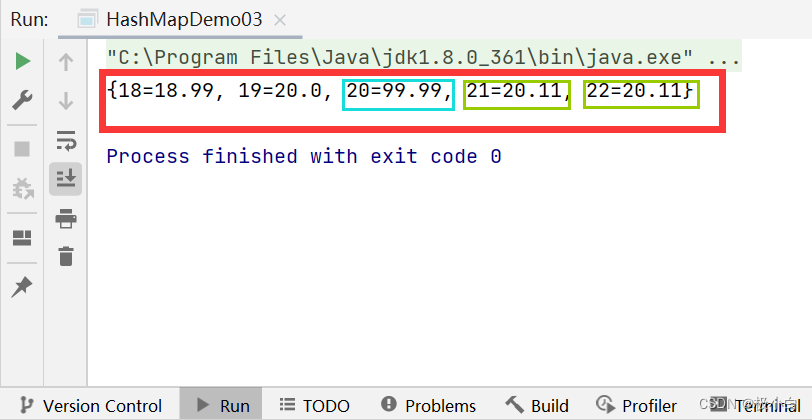
Key数据类型为Integer类型,Value数据类型为double类型的Map
其中第四对象和第五对象的Value值相同,第三对象与第六对象的Key值相同。
public static void main(String[] args) {
//若要使用Map,我们需要导入import java.util.HashMap;与import java.util.Map;
//我们使用泛型来约束Map的数据类型,Key为Integer数据类型,Value为Double数据类型
//其具体实现类为HashMap
Map<Integer, Double> map=new HashMap<>();
//使用put()方法来添加数据
map.put(18,18.99);//第一对象
map.put(19,20.00);//第二对象
map.put(20,59.99);//第三对象
map.put(21,20.11);//第四对象
map.put(22,20.11);//第五对象
map.put(20,99.99);//第六对象
//普通打印
System.out.println(map);
}
运行结果:(我们发现后面插入的第六对象将之前插入的第三对象给覆盖掉了,而第四对象与第五对象的Value值重复则不会带来任何影响)
四、Map的遍历操作 Map基础
Map的遍历分为调用keySet()方法遍历和entrySet()方法遍历
Map调用keySet()方法遍历
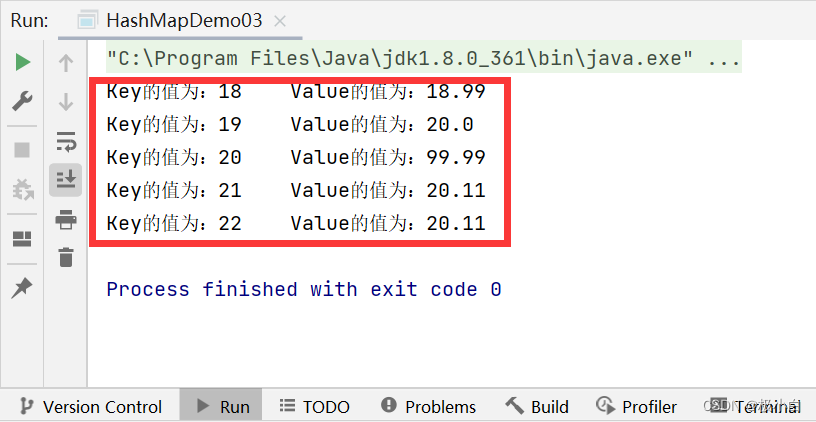
public static void main(String[] args) {
//若要使用Map,我们需要导入import java.util.HashMap;与import java.util.Map;
//我们使用泛型来约束Map的数据类型,Key为Integer数据类型,Value为Double数据类型
//其具体实现类为HashMap
Map<Integer, Double> map=new HashMap<>();
//使用put()方法来添加数据
map.put(18,18.99);//第一对象
map.put(19,20.00);//第二对象
map.put(20,59.99);//第三对象
map.put(21,20.11);//第四对象
map.put(22,20.11);//第五对象
map.put(20,99.99);//第六对象
//调用keySet方法遍历
//在Map遍历中Key占据着主导地位,可以通过Key值找到对应的Value值
//调用keySet()方法,Set<>泛型约束应与Key的数据类型一致
//例如在本代码中,Map<Integer, Double>,Key的数据类型为Integer,因此Set<>泛型约束也应当为Integer
//Set<Integer> set11=map.keySet();代码的意思为将Map中所有Key值存入Set集合(18,19,20,21,22)
//那么set11即为Key值集合
Set<Integer> set11=map.keySet();
//使用forEach()语句遍历,Integer为set11的数据类型,i为set11的复用名(相当于set11)
//那么i就成为了Key值
for(Integer i:set11){
//在Map遍历中Key占据着主导地位,可以通过Key值找到对应的Value值
//接下来我们要根据Key值来查找各个Key值对应的Value值
//Value数据类型为Double,设置一个Double变量来存储Value
//map.get(i);代码意思为根据i(Key值)找到相对应的Value值
Double dou=map.get(i);
//打印输出
System.out.println("Key的值为:"+i+" "+"Value的值为:"+dou);
}
}
运行结果:(我们发现输出顺序与插入顺序不一致,这是因为我们使用了Set集合来遍历Map,Set集合具有存取数据不一致的问题)
Map调用entrySet()方法遍历
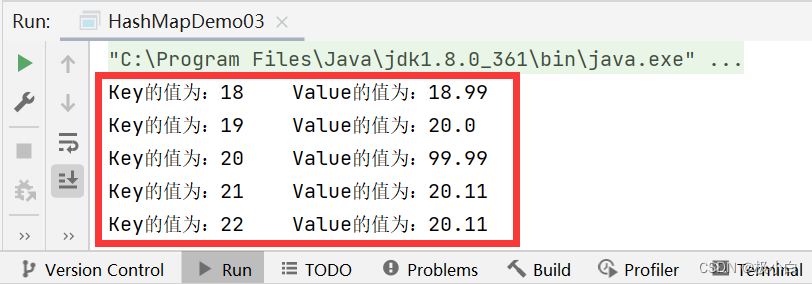
public static void main(String[] args) {
//若要使用Map,我们需要导入import java.util.HashMap;与import java.util.Map;
//我们使用泛型来约束Map的数据类型,Key为Integer数据类型,Value为Double数据类型
//其具体实现类为HashMap
Map<Integer, Double> map=new HashMap<>();
//使用put()方法来添加数据
map.put(18,18.99);//第一对象
map.put(19,20.00);//第二对象
map.put(20,59.99);//第三对象
map.put(21,20.11);//第四对象
map.put(22,20.11);//第五对象
map.put(20,99.99);//第六对象
//调用entrySet方法遍历
//调用entrySet()方法,Set<>泛型约束应与Map.Entry的数据类型一致,即<Integer, Double>
//<Key,Value>键值对,在Java语言中又被称之为Entry/entry,Map.Entry就相当于Student.name,若name的数据类型为String,则Student.name的数据类型为String,同理若<key,value>中key的数据类型为Integer,value的数据类型为String,则Map.Entry的数据类型为<Integer,String>,在这里就是<Integer, Double>。
//Set<Map.Entry<Integer,Double>> set11=map.entrySet();代码的意思为将Map中所有(Key,Value)值存入Set集合[(18,18.99),(19,20.00),(20,99.99),(21,20.11),(22,20.11)]
//那么set11即为(Key,Value)值集合
Set<Map.Entry<Integer,Double>> set11=map.entrySet();
//使用forEach()语句遍历,Integer为set11的数据类型,i为set11的复用名(相当于set11)
//那么i就成为了(Key,Value)值
for(Map.Entry<Integer,Double> i:set11){
//打印输出,直接调用getKey()方法得到Key值,直接调用getValue()得到Value值
System.out.println("Key的值为:"+i.getKey()+" "+"Value的值为:"+i.getValue());
}
}
运行结果:(我们发现输出顺序与插入顺序不一致,这是因为我们使用了Set集合来遍历Map,Set集合具有存取数据不一致的问题)
五、案例Map集合储存学生对象并遍历 Map基础强化
需求:创建一个Map集合,键是学生对象(Student),值是籍贯(String)。
要求:存储三个键值对元素(Entry),并遍历
Student类
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
Map遍历输出
public static void main(String[] args) {
//若要使用Map,我们需要导入import java.util.HashMap;与import java.util.Map;
//我们使用泛型来约束Map的数据类型,Key为Student数据类型,Value为String数据类型
//其具体实现类为HashMap
Map<Student, String> map=new HashMap<>();
//创建Student对象元素
Student student1=new Student("zhangsan",18);
Student student2=new Student("lisi",29);
Student student3=new Student("wangwu",33);
//使用put()方法来添加数据
map.put(student1,"北京");
map.put(student2,"上海");
map.put(student3,"广州");
//调用keySet方法遍历
//在Map遍历中Key占据着主导地位,可以通过Key值找到对应的Value值
//调用keySet()方法,Set<>泛型约束应与Key的数据类型一致
//例如在本代码中,Map<Student, String>,Key的数据类型为Student,因此Set<>泛型约束也应当为Student
//Set<Student> set11=map.keySet();代码的意思为将Map中所有Key值存入Set集合(student1,student2,student3)
//那么set11即为Key值集合
Set<Student> set11=map.keySet();
//使用forEach()语句遍历,Student为set11的数据类型,i为set11的复用名(相当于set11)
//那么i就成为了Key值
for(Student i:set11){
//在Map遍历中Key占据着主导地位,可以通过Key值找到对应的Value值
//接下来我们要根据Key值来查找各个Key值对应的Value值
//Value数据类型为String,设置一个String变量来存储Value
//map.get(i);代码意思为根据i(Key值)找到相对应的Value值
String str=map.get(i);
//打印输出
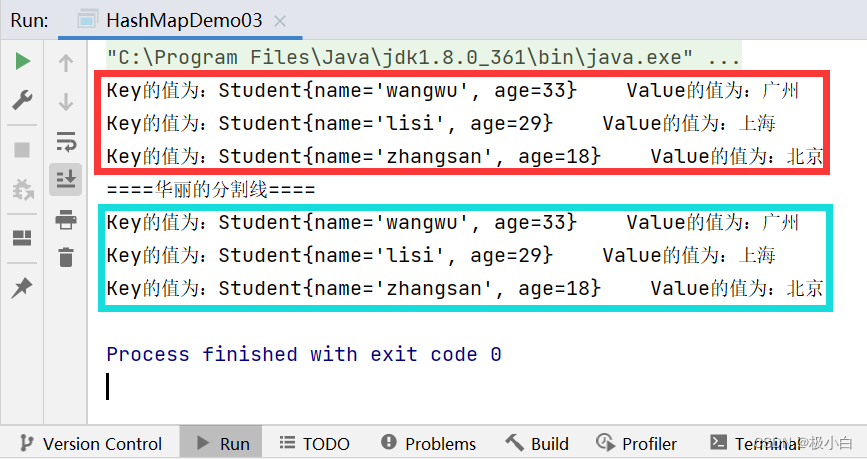
System.out.println("Key的值为:"+i+" "+"Value的值为:"+str);
}
System.out.println("====华丽的分割线====");
//调用entrySet方法遍历
//调用entrySet()方法,Set<>泛型约束应与Map.Entry的数据类型一致,即<Student, String>
//<Key,Value>键值对,在Java语言中又被称之为Entry/entry,Map.Entry就相当于Student.name,若name的数据类型为String,则Student.name的数据类型为String,同理若<key,value>中key的数据类型为Integer,value的数据类型为String,则Map.Entry的数据类型为<Integer,String>,在这里就是<Student, String>。
//Set<Map.Entry<Student, String>> set22=map.entrySet();代码的意思为将Map中所有(Key,Value)值存入Set集合[(Student("zhangsan",18),"北京"),(Student("lisi",29),“上海”),(Student("wangwu",33),“广州”)]
//那么set22即为(Key,Value)值集合
Set<Map.Entry<Student, String>> set22=map.entrySet();
//使用forEach()语句遍历,Integer为set11的数据类型,i为set22的复用名(相当于set22)
//那么i就成为了(Key,Value)值
for(Map.Entry<Student, String> i:set22){
//打印输出,直接调用getKey()方法得到Key值,直接调用getValue()得到Value值
System.out.println("Key的值为:"+i.getKey()+" "+"Value的值为:"+i.getValue());
}
}
运行结果:(我们发现输出顺序与插入顺序不一致,这是因为我们使用了Set集合来遍历Map,Set集合具有存取数据不一致的问题)
OK!!!Map介绍结束!!!
智能推荐
通过formData数据发送ajax请求-程序员宅基地
文章浏览阅读1.9k次。formData1.创建一个formData对象var fd = new FormData(‘form表单’);(创建formdtata对象的小括号里面,就是需要一个form表单dom对象)。2.往fd对象中添加对象fd.append(‘sex’,‘男’);3.formData里面就会有form表单中 有name属性的这些标签的取值。//键值对形式console.log(fd.ge...
监控神器Prometheus,开箱即用!-程序员宅基地
文章浏览阅读244次。文章来源:【公众号:云加社区】目录简介整体生态工作原理Metric 指标PromQLGrafana 可视化监控告警简介Prometheus 是一个开源的完整监控解决方案,本文将从指标抓取到查询及可视化展示,以及最后的监控告警,对 Prometheus 做一个基本的认识。Prometheus 是古希腊神话里泰坦族的一名神明,名字的意思是“先见之明”,下图中是 Promet..._dtm prometheus
实验五 -1 快速排序算法和直接插入排序算法-程序员宅基地
文章浏览阅读900次,点赞15次,收藏6次。对数据序列{6,8,7,9,0,1,3,2,4,5},请分别用快速排序算法和直接选择排序设计算法对数据序列进行排序;
10000以内的同构数-程序员宅基地
文章浏览阅读597次。/*找出10000以内的同构数同构数 376*376=141376思路:1、输入一个数num 先判断是几位数。记住数位length。 2、然后算它(num)的平方, square。 3、取square的后length位的数值temp 4、temp与num相等,则是同构数。*/#include <iostream>#include &..._小于10000的同构数
js实现文字转语音功能tts_js tts-程序员宅基地
文章浏览阅读5.1k次,点赞3次,收藏26次。写了很久的语音呼叫功能、调用在线语音合成的调用系统自带的;现在客户又要求搞网页版的语音呼叫还是不带联网的。客户太难伺候了详细使用请参考 【web语音API】完整代码<!DOCTYPE><html xmlns="http://www.w3.org/1999/xhtml" lang="zh-CN"><head><title>网页文字转语音</title><meta http-equiv="Content-Typ._js tts
Java经典问题(百僧吃百馍)-程序员宅基地
文章浏览阅读62次。System.out.println("100个和尚吃了100个馒头 ,100和尚有大和尚和小和尚,一个大和尚能吃3馒头,三个小和尚吃1个馒头,问大和尚和小和尚有多少个?System.out.println("大和尚有"+i+"个人");System.out.println("小和尚有"+j+"个人");System.out.println("查看答案请按回车键");
随便推点
三分钟带你掌握 CSS3 的新属性_采用css转换,边框阴影等新特性完成css3偏光图像画廊设计-程序员宅基地
文章浏览阅读3.8w次,点赞9次,收藏10次。1. css3简介CSS 用于控制网页的样式和布局,CSS3 是最新的CSS标准,CSS3 完全向后兼容,因此您不必改变现有的设计。浏览器通常支持 CSS2,但是现在大部分浏览器也实现了css3的很多特性。CSS3 被划分为模块。其中最重要的 CSS3 模块包括:选择器框模型背景和边框文本效果2D/3D 转换动画多列布局用户界面2. css3边框2.1 边框圆角Internet Explorer 9+ 支持 border-radius 和 box-shadow 属性。Fir_采用css转换,边框阴影等新特性完成css3偏光图像画廊设计
设计模式--组合模式-程序员宅基地
文章浏览阅读47次。定义:允许将对象组成树形结构来表现 “整体/部分” 层次结构。组合能让客户以一致的方式处理个别对象及对象组合。说白了,就是类似于树形结构。 只是它要求子节点和父节点都具备统一的接口。类图如下:示例如下:比如我们常见的电脑上的目录,目录下面有文件夹,也有文件,然后文件夹里面还有文件及文件夹。这样一层层形成了树形结构。示例代码如下:#include <iostream>#include <stdio.h>#include "string"#includ..
Kotlin相关面试题_kotlin面试题-程序员宅基地
文章浏览阅读1.9w次,点赞26次,收藏185次。目录一.请简述下什么是kotlin?它有什么特性?二.Kotlin 中注解 @JvmOverloads 的作用?三.Kotlin中的MutableList与List有什么区别?四.kotlin实现单例的几种方式?五. kotlin中关键字data的理解?相对于普通的类有哪些特点?六.什么是委托属性?简单说一下应用场景?七.kotlin中with、run、apply、let函数的区别?一般用于什么场景?八.kotlin中Unit的应用以及和Java中void的区别?九.Ko_kotlin面试题
HEVC英文缩写及部分概念整理(1)--博主整理_反量化 英文缩写-程序员宅基地
文章浏览阅读2.8k次。有这个想法一方面是确实很多时候会记不得一些缩写是什么意思。另外也是受 http://blog.csdn.net/lin453701006/article/details/52797415这篇博客的启发,本文主要用于自己记忆 内容主要整理自http://blog.sina.com.cn/s/blog_520811730101hmj9.html http://blog.csdn.net/feix_反量化 英文缩写
超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门-程序员宅基地
文章浏览阅读7.3k次,点赞6次,收藏36次。超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门
python怎么输出logistic回归系数_python - Logistic回归scikit学习系数与统计模型的系数 - SO中文参考 - www.soinside.com...-程序员宅基地
文章浏览阅读1.2k次。您的代码存在一些问题。首先,您在此处显示的两个模型是not等效的:尽管您将scikit-learn LogisticRegression设置为fit_intercept=True(这是默认设置),但您并没有这样做statsmodels一;来自statsmodels docs:默认情况下不包括拦截器,用户应添加。参见statsmodels.tools.add_constant。另一个问题是,尽管您处..._sm fit(method