什么是数据_数据内容-程序员宅基地
数据的概念与内容
数据的概念
数据是指对客观事件进行记录并可以鉴别的符号,是信息的表现形式和载体。据所指代的并不仅是狭义上的数字,还可以包括符号、文字、语音、图形和视频等。
在计算机科学中数据是指所有能输入到计算机中并被计算机程序处理的符号和介质的总称。数据经过加工后就成为信息。
数据的分类
1.按照数据性质分类
- 定位数据:各位坐标数据
- 定性数据:事务属性,如高矮胖瘦
- 定量数据:长宽高、温度、重量、体积
- 定时数据:时间数据,如年月日、时分秒
2.按照数据产生方式分类
- 直接数据
- 间接数据:加工和汇总后得到的数据
3.按照数据表现形式分类
- 图形数据:如点、线、面
- 符号数据
- 文字数据
- 图像数据
- 音频数据
- 视频数据
- 三维模型数据
4.按照数据的内容分类
- 实时数据与历史数据
实时数据是在某事发生发生、发展过程中发展过程中的同一时间中获得的数据,比如某人在餐馆点菜,只要行为完成,就有关于他的数据。
实时数据不再具有实时性,则成为历史数据 - 事务数据与时序数据
事务数据是一种记录类型的数据,每个记录是一个项的集合,如学生在本学期所选的课表就构成了一个事务。
时序数据即为时间序列数据,为每个记录包含一个与之相关联的时间。 - 图形数据与图像数据
图形数据是以图形为对象形式的表示
5.按照数据的内容分类
- 主题数据与全局数据
主题数据是按照主题在数据仓库中提取出的数据集合,面向应用领域。
全局数据是数据仓库中所有主题数据的集合 - 空间数据
指用来表示空间中物体的位置、形状、大小及其分布特征诸多方面信息的数据
具有定位、定性、时间、空间和专题属性等特性,专题属性是空间目标某一方面的特征,比如地形的坡度,某地的降雨量、人口密度、空气湿度等特征 - 序列数据与数据流
序列数据能够反映了某一事物、现象等随时间的变化状态或程度。比如股票的交易价格与交易量、某地气温变化趋势、期货交易价格等都是时间序列。
流数据特点就是,像流水一样,不是一次过来而是一点一点地“流”过来。它是一种顺序、大量、快速、连续流进和流出的数据序,可以被视为一个随时间延续而无限增长的动态数据。集合流数据具有四个特点:
1 数据实施到达
2 数据到达次序独立,不受应用系统所控制
3 数据规模宏大且不能预知其最大值
4 数据一经处理,除非特意保存,否则不能再次被取出处理,或者再次提取数据代价昂贵
数据属性与数据集
数据的属性:
数据的属性是指数据在某方面的特征,我们根据属性的性质将属性分为四种类型:
- 标称:如性别(男、女)、婚姻状况(已婚、未婚)、职业(教师、医生、电工)
- 序数:成绩等级(优、良、中、及格、不及格)、衣服尺码(S、M、L、XL)
- 区间:测量单位,如温度、日历日期等
- 比率:如绝对温度、年龄、长度、成绩分数等
数据集:
数据集是待处理的数据对象的集合,在数据挖掘领域,数据集有三个重要的特性:维度、稀疏性和分辨率:
- 维度:指数据集中的对象具有的属性个数总和
- 稀疏性:指在数据集中,有意义的数据的多少
- 分辨率:可以在不同的分辨率下或者粒度下得到数据,而且在不同的分辨率下对象的数据也不同
数据预处理
数据预处理的意义
数据质量问题:现实世界的数据一般是含噪声的、不完整的、不一致的,是“肮脏的”。
- 不一致数据:缺乏统一的分类标准和编码方案
- 重复数据:存在相同的记录,相同的信息存储在多个数据源中
- 残缺数据:空值
- 噪声数据:错误值或孤立点
- 高维数据:存在无用或冗余属性
高质量的决策必须依赖高质量的数据
数据仓库需要对高质量的数据进行一致地集成
意义:
- 改进数据质量,提高其后的挖掘过程的精度和性能。
- 数据预处理是知识发现过程的重要步骤。
- 检测数据异常、尽早调整数据,并归约待分析数据,将得到较高决策回报。
数据预处理的基本方法
- 数据清洗:除去噪声,纠正不一致性。填写空缺的值,平滑噪声数据,识别、删除孤立点,解决不一致性
- 数据集成:将多种数据源合并成一致的数据存储。集成多个数据库、数据立方体或文件
- 数据变换:即规范化,可以改进距离度量的挖掘算法的精度和有效性。规范化和聚集
- 数据规约:通过聚集、删除冗余特性或聚类方法来压缩数据。通过一些技术(概念分层上卷等)得到数据集的压缩表示,它小得多,但可以得到相同或相近的结果
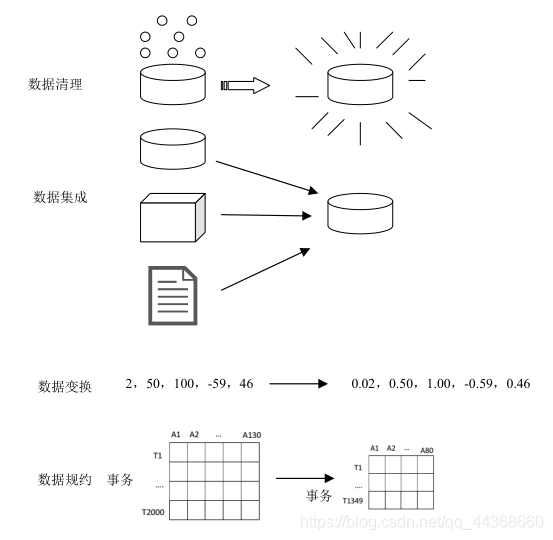
数据清洗
数据清洗(Data cleaning),就是按照一定的规则把“脏数据”“洗掉”,即填充空缺的值,识别孤立点、消除噪声,并纠正数据中的不一致。
通过对数据进行重新审查和校验的过程,发现并纠正数据文件中可识别的错误,包括检查数据一致性,处理无效值和缺失值,删除重复信息、纠正存在的错误,并提供数据一致性等。
目的是提高数据质量。
数据清理一般是由计算机而不是人工完成。
业界对数据清洗的认识:数据清洗是数据仓库构建中最重要的问题。
数据清洗任务:数据清洗任务:1)空缺值处理 2)属性选择与处理 3)噪声数据处理
一、空缺值处理
- 忽略元组
- 使用全局常量填充空缺值
- 使用属性平均值填充空缺值
- 使用与给定元组属于同一类的所有样本的平均值
- 预测最有可能的值填充空缺值(决策树算法、关联规则算法、神经网络。考虑数据库系统和挖掘算法的特点)
二、属性选择与处理
属性的选择与处理包括统一属性编码、去除重复属性和不相关属性、合理选择关键字段等工作。去除与数据挖掘目的无关的属性值,可以大大减少数据挖掘的时间,同时保证数据挖掘的结果。
- 赋予属性值明确的含义:
对名称和取值含义模糊的属性,赋予每个属性确切的、便于理解的属性名称。 - 统一属性值编码:
保证在各个数据源中对同一事物特征的描述是统一的。例如:在不同数据源中用“M”、“F”或者“0”、“1”分别表示“男”、“女”,多个数据源合并的时候,就需要把这些属性值统一起来。 - 处理唯一属性:
需要建立挖掘结果和原始数据的对应关系则保留,若不形成规则,则去除。 - 去除重复属性:
原始数据中会出现意义相同或者可以用于表示同一信息的多个属性,则选择性去除重复属性。比如:年龄和出生日期,只需年龄段时,出生日期属性则冗余。 - 去除可忽略字段:
若某属性值缺失非常严重,该属性已经不能成为有用知识时,则去除该属性。 - 合理选择关联字段:
如果属性X可以由另一个或多个属性推导或者计算出来,则认为这些字段之间的关联度高,属性X和它的关联属性对数据挖掘的作用是相同的,所以只选择其中之一,或者属性X,或者它的关联属性。如商品价格、数量和总价格之间有高度关联关系
三、噪声数据处理
噪声:噪声:一个测量变量中的随机错误或偏差。噪声数据本身含有偏差和孤立点,可能会导致错误的数据分析结果。
-
分箱(binning):通过考察周围的值来平滑存储数据的值,存储的值被分布到一些“桶”或箱中。
分箱目的是对各个箱子中的数据进行处理,完成了分箱之后,就需要采用一种方法对数据进行平滑,使得箱中的数据更接近,目前通常使用的平滑方法有按平均值平滑、按边界值平滑和按中值平滑。 -
回归:
通过让数据适合一个函数(回归函数)来平滑数据。
一元线性回归:找出适合两个变量的“最佳”直线,使得一个变量能够预测另一个,形如Y=aX+b。
多线性回归:是线性回归的扩展,它涉及多于两个变量,数据要适合一个多维面,Z=aX+bY+c。 -
聚类:
通过聚类分析检测离群点,消除噪声(离群点)
数据集成
数据集成数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中。这些数据源可以包括多个数据库、数据立方体或一般文件。
由于开发部门或开发时间的不同,相关系统的数据源彼此独立、相互封闭,在将多数据库中的异构数据进行集成的过程中可能出现多种问题:在两个不同的数据库中,同一个字段可能有不同的命名、不同的字段有相同的命名、在两个不同的数据库中一个教师收入单位为千元,一个为元的单位不一致情况、在不同的数据库中数据类型不同、无关数据冗余等情况。
-
模式匹配
模式匹配模式匹配即整合不同数据源中的元数据。在模式匹配过程中涉及实体识别问题。 -
数据值冲突
不同数据源中,表示同一实体的属性值可能存在不同,可能表现在单位不统一、数值类型不统一等方面。比如在一个数据表中学生性别用“男”、“女”来表示,而在另外一张数据表中则用“F”、“M”来表示;也可能由于数据类型不统一带来的冲突。 -
数据冗余
冗余是指重复存在的消息,在数据挖掘领域中,也指无用的信息。一个属性(例如,年收入)如果能由另一个或另一组属性“导出”,则这个属性可能是冗余的。属性或维命名的不一致也可能导致结果数据集中的冗余。
有些数据冗余比较隐蔽,可以使用相关性分析方法来分析两属性之间的相似度。两属性相关性越高,则通过一个属性能映射到另外一个属性的可能性就越大,就可以选择只保留其中一个属性
其中卡方检验适用于定性数据,相关系数适用于数值属性。
数据变换
数据变换是数据变换是将数据转换成适合挖掘的形式(原始数据表并不适合直接用于数据挖掘,需变换之后才能使用),主要有:
- 光滑:去除噪声,将连续的数据离散化。
减少属性的取值个数,减少挖掘算法的工作量 - 聚集:对数据进行汇总
avg(), count(), sum(), min(), max()… - 数据泛化
使用概念分层的方式,利用高层的概念来替换低层或原始数据。 - 规范化
所用的度量单位可能影响数据分析。例如,把高度的度量单位从米变成英寸,把重量的度量单位从公斤改成磅,可能导致完全不同的结果。为了帮助避免对度量单位选择的依赖性需要对数据进行规范化,对属性数据进行缩放,使之可以落入到一个较小的特定区域之间,如[-1,1]、[0,1]。
例如:最小最大规范化、零一均值规范化、小数定标规范化
数据规约
据归约数据归约的本质就是缩小数据的范围,是指在不破坏数据完整性的前提下,获得比原始数据小得多的挖掘数据集,该数据集可以得到和原始数据集相同的挖掘结果,进而减少数据挖掘所需要的时间。
-
数据立方体聚集
数据立方体数据立方体是数据的多维模型,由维和事实组成。维度就是数据的属性,事实是具体的数据内容。平常的认知中立方体都是三维结构,在数据挖掘领域,数据立方体可以是多维的,甚至是n维的。

-
维规约
维归约维归约就是对维度,即属性进行归约,去掉不相关或者相关性较低的属性,减少数据量。
通过删除不相干的属性或维,减少数据集。
属性子集选择(特征选择)找出最小属性集,使得数据类的概率分布尽可能的接近使用所有属性得到的原分布。减少出现在发现模式上的属性数目,使得模式更易于理解。
属性子集选择方法
逐步向前选择
逐步向后删除
向前选择和向后删除相结合
决策树归约 -
数据压缩
数据压缩数据压缩是指应用数据编码或变换,以便得到原数据的归约或“压缩”表示。
无损数据压缩技术:原数据可以由压缩数据重新构造而不丢失任何信息,所采用的压缩技术,是基于熵的编码方法。(哈夫曼编码、香农编码)
有损数据压缩技术:只能重新构造原数据的近似表示,所采用的数据压缩技术。两种流行的有效的有损数据压缩方法:(小波变换、主成分分析) -
数值规约
数值归约技术数值归约技术就是用较少的数据来代替原始数据,减小数据量。
有参方法:使用一个参数模型估计数据,最后只要存储参数即可,如线性回归方法和非线性回归
无参方法:直方图、聚类、抽样 -
离散化与概念分层
离散化:
通过将属性域划分为区间,减少给定连续属性值的个数
区间的标号可以代替实际的数据值
离散化可以在一个属性上递归的进行
概念分层:
通过使用高层的概念(比如:青年、中年、老年)来替代底层的属性值(比如:实际的年龄数据值)来规约数据,虽然一些细节在数据泛化过程中消失了,但这样所获得的泛化数据或许会更易于理解、更有意义。在消减后的数据集上进行数据挖掘显然效率更高
总结
- 数据是信息的表现形式和载体,数据经过加工后就成为信息。
- 按照数据内容可以将数据分为实时数据与历史数据、事务数据与时序数据、图形数据与图像数据、主图数据与全局数据、空间数据、序列数据与流数据
- 数据集有三个重要的特性:维度、稀疏性和分辨率
- 数据清洗数据清洗试图填补缺失的值,光滑噪声识别离群点,并纠正数据的不一致性。数据清理通常是一个两步的迭代过程,包括偏差检测和数据变换。
- 数据集成数据集成将来自多个数据源的数据整合成一致的数据存储。语义异种性的解决、元数据、相关分析、重复检测和冲突检测都有助于数据的集成
- 数据归约数据归约得到数据的归约表示,而使得信息内容的损失最小化。数据归约方法包括维归约、数值归约和数据压缩等
- 数据变换数据变换将数据变换成适于挖掘的形式。例如,在规范化中,属性数据可以缩放,使得它们可以落在较小的区间。
- 尽管已经开发了许多数据预处理的方法,由于不一致或脏数据的数量巨大,以及问题本身的复杂性,数据预处理仍然是一个活跃的研究领域。
智能推荐
JWT(Json Web Token)实现无状态登录_无状态token登录-程序员宅基地
文章浏览阅读685次。1.1.什么是有状态?有状态服务,即服务端需要记录每次会话的客户端信息,从而识别客户端身份,根据用户身份进行请求的处理,典型的设计如tomcat中的session。例如登录:用户登录后,我们把登录者的信息保存在服务端session中,并且给用户一个cookie值,记录对应的session。然后下次请求,用户携带cookie值来,我们就能识别到对应session,从而找到用户的信息。缺点是什么?服务端保存大量数据,增加服务端压力 服务端保存用户状态,无法进行水平扩展 客户端请求依赖服务.._无状态token登录
SDUT OJ逆置正整数-程序员宅基地
文章浏览阅读293次。SDUT OnlineJudge#include<iostream>using namespace std;int main(){int a,b,c,d;cin>>a;b=a%10;c=a/10%10;d=a/100%10;int key[3];key[0]=b;key[1]=c;key[2]=d;for(int i = 0;i<3;i++){ if(key[i]!=0) { cout<<key[i.
年终奖盲区_年终奖盲区表-程序员宅基地
文章浏览阅读2.2k次。年终奖采用的平均每月的收入来评定缴税级数的,速算扣除数也按照月份计算出来,但是最终减去的也是一个月的速算扣除数。为什么这么做呢,这样的收的税更多啊,年终也是一个月的收入,凭什么减去12*速算扣除数了?这个霸道(不要脸)的说法,我们只能合理避免的这些跨级的区域了,那具体是那些区域呢?可以参考下面的表格:年终奖一列标红的一对便是盲区的上下线,发放年终奖的数额一定一定要避免这个区域,不然公司多花了钱..._年终奖盲区表
matlab 提取struct结构体中某个字段所有变量的值_matlab读取struct类型数据中的值-程序员宅基地
文章浏览阅读7.5k次,点赞5次,收藏19次。matlab结构体struct字段变量值提取_matlab读取struct类型数据中的值
Android fragment的用法_android reader fragment-程序员宅基地
文章浏览阅读4.8k次。1,什么情况下使用fragment通常用来作为一个activity的用户界面的一部分例如, 一个新闻应用可以在屏幕左侧使用一个fragment来展示一个文章的列表,然后在屏幕右侧使用另一个fragment来展示一篇文章 – 2个fragment并排显示在相同的一个activity中,并且每一个fragment拥有它自己的一套生命周期回调方法,并且处理它们自己的用户输_android reader fragment
FFT of waveIn audio signals-程序员宅基地
文章浏览阅读2.8k次。FFT of waveIn audio signalsBy Aqiruse An article on using the Fast Fourier Transform on audio signals. IntroductionThe Fast Fourier Transform (FFT) allows users to view the spectrum content of _fft of wavein audio signals
随便推点
Awesome Mac:收集的非常全面好用的Mac应用程序、软件以及工具_awesomemac-程序员宅基地
文章浏览阅读5.9k次。https://jaywcjlove.github.io/awesome-mac/ 这个仓库主要是收集非常好用的Mac应用程序、软件以及工具,主要面向开发者和设计师。有这个想法是因为我最近发了一篇较为火爆的涨粉儿微信公众号文章《工具武装的前端开发工程师》,于是建了这么一个仓库,持续更新作为补充,搜集更多好用的软件工具。请Star、Pull Request或者使劲搓它 issu_awesomemac
java前端技术---jquery基础详解_简介java中jquery技术-程序员宅基地
文章浏览阅读616次。一.jquery简介 jQuery是一个快速的,简洁的javaScript库,使用户能更方便地处理HTML documents、events、实现动画效果,并且方便地为网站提供AJAX交互 jQuery 的功能概括1、html 的元素选取2、html的元素操作3、html dom遍历和修改4、js特效和动画效果5、css操作6、html事件操作7、ajax_简介java中jquery技术
Ant Design Table换滚动条的样式_ant design ::-webkit-scrollbar-corner-程序员宅基地
文章浏览阅读1.6w次,点赞5次,收藏19次。我修改的是表格的固定列滚动而产生的滚动条引用Table的组件的css文件中加入下面的样式:.ant-table-body{ &amp;::-webkit-scrollbar { height: 5px; } &amp;::-webkit-scrollbar-thumb { border-radius: 5px; -webkit-box..._ant design ::-webkit-scrollbar-corner
javaWeb毕设分享 健身俱乐部会员管理系统【源码+论文】-程序员宅基地
文章浏览阅读269次。基于JSP的健身俱乐部会员管理系统项目分享:见文末!
论文开题报告怎么写?_开题报告研究难点-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏15次。同学们,是不是又到了一年一度写开题报告的时候呀?是不是还在为不知道论文的开题报告怎么写而苦恼?Take it easy!我带着倾尽我所有开题报告写作经验总结出来的最强保姆级开题报告解说来啦,一定让你脱胎换骨,顺利拿下开题报告这个高塔,你确定还不赶快点赞收藏学起来吗?_开题报告研究难点
原生JS 与 VUE获取父级、子级、兄弟节点的方法 及一些DOM对象的获取_获取子节点的路径 vue-程序员宅基地
文章浏览阅读6k次,点赞4次,收藏17次。原生先获取对象var a = document.getElementById("dom");vue先添加ref <div class="" ref="divBox">获取对象let a = this.$refs.divBox获取父、子、兄弟节点方法var b = a.childNodes; 获取a的全部子节点 var c = a.parentNode; 获取a的父节点var d = a.nextSbiling; 获取a的下一个兄弟节点 var e = a.previ_获取子节点的路径 vue