【保姆级教程|YOLOv8改进】【6】快速涨点,SPD-Conv助力低分辨率与小目标检测_spd-conv 和fasternet-程序员宅基地
技术标签: YOLO YOLOv8网络结构改进 目标检测 人工智能 YOLOv8改进
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
感谢小伙伴们点赞、关注!
《------往期经典推荐------》
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
《------正文------》
前言
论文发表时间:2022.08.07
github地址:https://github.com/LabSAINT/SPD-Conv
paper地址:https://arxiv.org/pdf/2208.03641v1.pdf

文章提出了一个新的CNN构建模块称为SPD-Conv,用来替换每个步长卷转层和每个池化层(从而完全消除它们)。SPD-Conv由一个空间到深度(SPD)层和一个非步长卷积(Conv)层组成。本文详细介绍了如何在yolov8中引入SPD-Conv,助力助力低分辨率与小目标检测,并且使用修改后的yolov8进行目标检测训练与推理。本文提供了所有源码免费供小伙伴们学习参考,需要的可以通过文末方式自行下载。
本文改进使用的ultralytics版本为:ultralytics == 8.0.227
目录
1.SPD-Conv简介

摘要:卷积神经网络(CNN)在许多计算机视觉任务中取得了显著的成功,例如图像分类和目标检测。然而,它们的性能在图像分辨率低或对象较小的更艰难任务中会急剧下降。在本文中,我们指出这一问题源于现有CNN架构中一个有缺陷但常见的设计,即使用步长卷积和/或池化层,这导致了细微信息的丢失和较少有效特征表示的学习。为此,我们提出了一个新的CNN构建模块称为
SPD-Conv,用来替换每个步长卷转层和每个池化层(从而完全消除它们)。SPD-Conv由一个空间到深度(SPD)层和一个非步长卷积(Conv)层组成,可以应用于大部分(如果不是全部的话)CNN架构。我们在两个最有代表性的计算机视觉任务下解释了这种新设计:目标检测和图像分类。然后,我们通过将SPD-Conv应用于YOLOv5和ResNet创建了新的CNN架构,并通过实验证明,我们的方法显著优于最先进的深度学习模型,尤其是在图像分辨率低和对象较小的更艰难任务上。
论文主要亮点如下:
- 我们发现了现有CNN架构中一个有缺陷但常见的设计,并提出了一种新的构建模块,称为SPD-Conv,以取代旧的设计。SPD-Conv在不丢失可学习信息的情况下下采样特征图,彻底抛弃了如今广泛使用的带步长的卷积和池化操作。
- SPD-Conv代表一种通用且统一的方法,可以很容易地应用于大部分(如果不是全部的话)基于深度学习的计算机视觉任务。
- 使用两个最具代表性的计算机视觉任务,目标检测和图像分类,来评估SPD-Conv的性能。具体来说,我们构建了YOLOv5-SPD、ResNet18-SPD和ResNet50-SPD,并在COCO-2017、Tiny ImageNet和CIFAR-10数据集上与几种最先进的深度学习模型进行了比较。结果显示在AP和top-1精度上都有显著的性能提升,特别是在小物体和低分辨率图像上。
1.1 网络结构
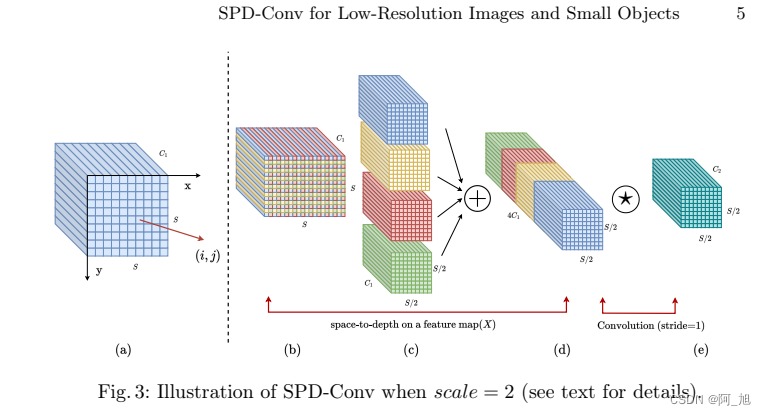
1.2 性能对比
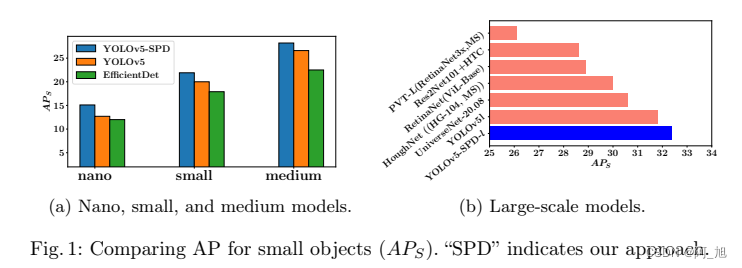
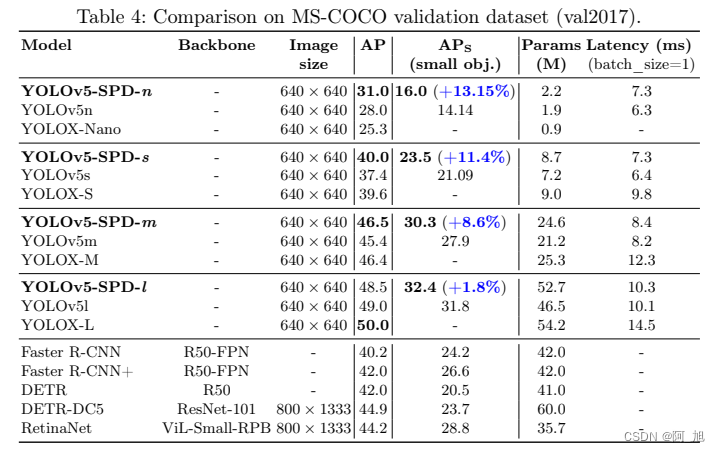
2.YOLOv8添加SPD-Conv
YOLOv8网络结构前后对比
定义FasterNet相关类
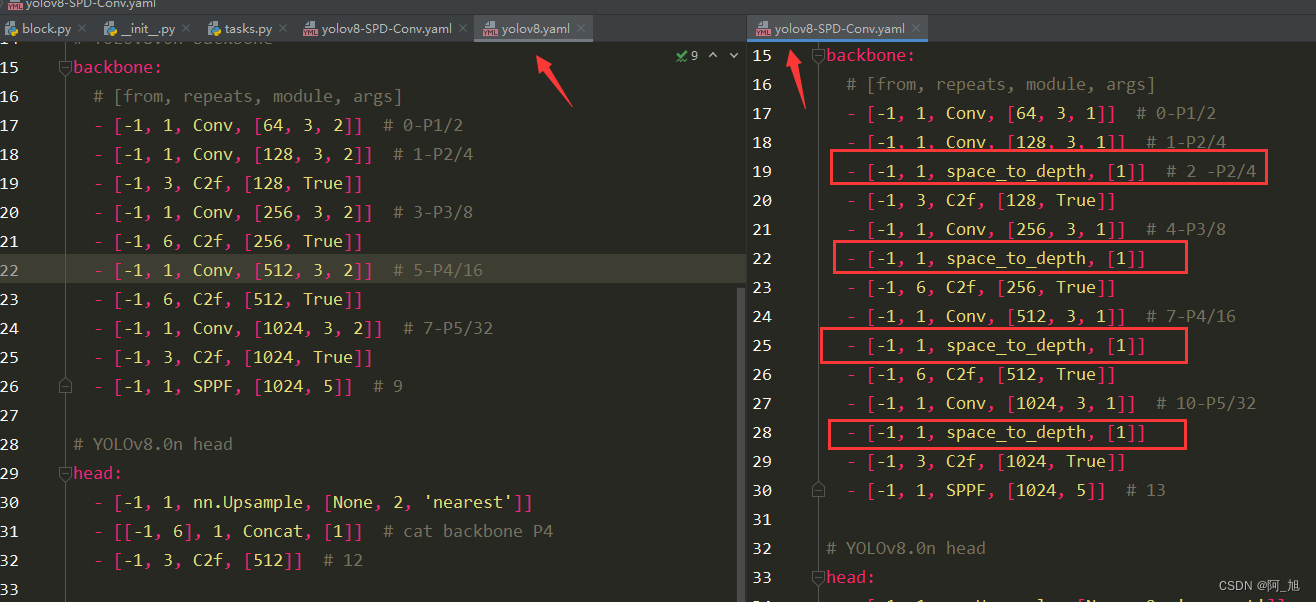
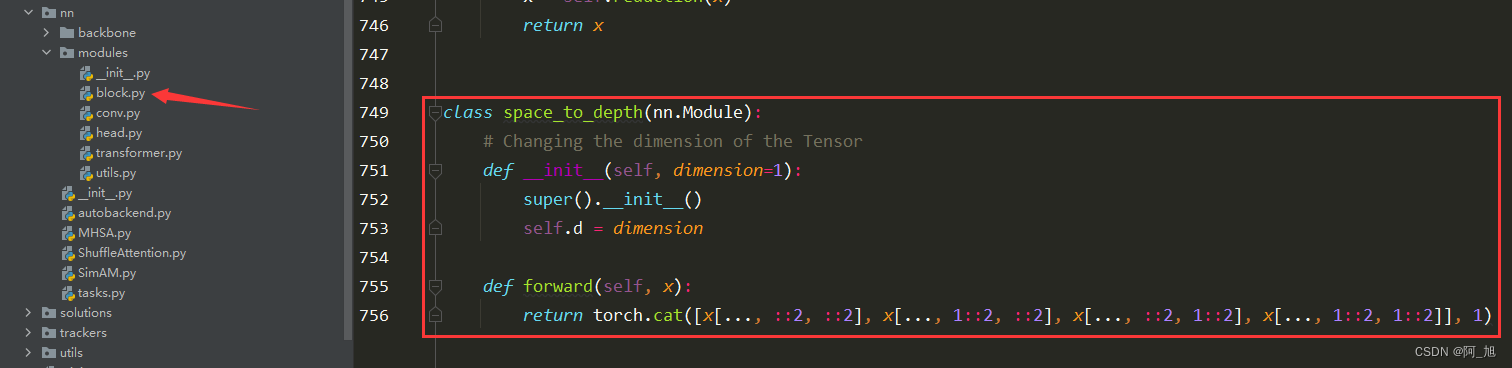
在ultralytics/nn/modules/block.py中添加如下代码块,为space_to_depth模块代码:
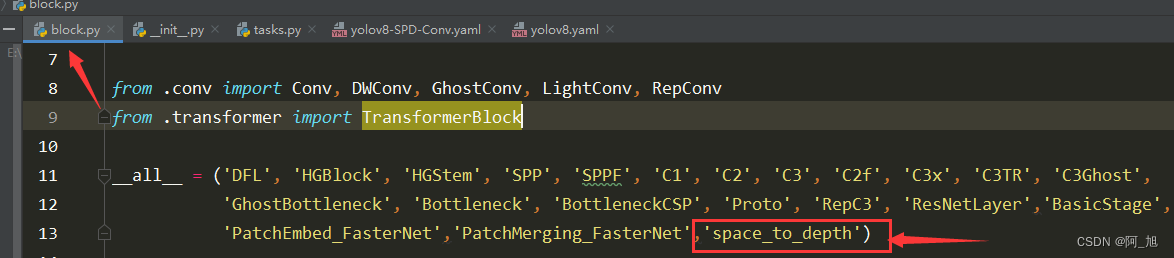
并在ultralytics/nn/modules/block.py中最上方添加如下代码:
修改指定文件
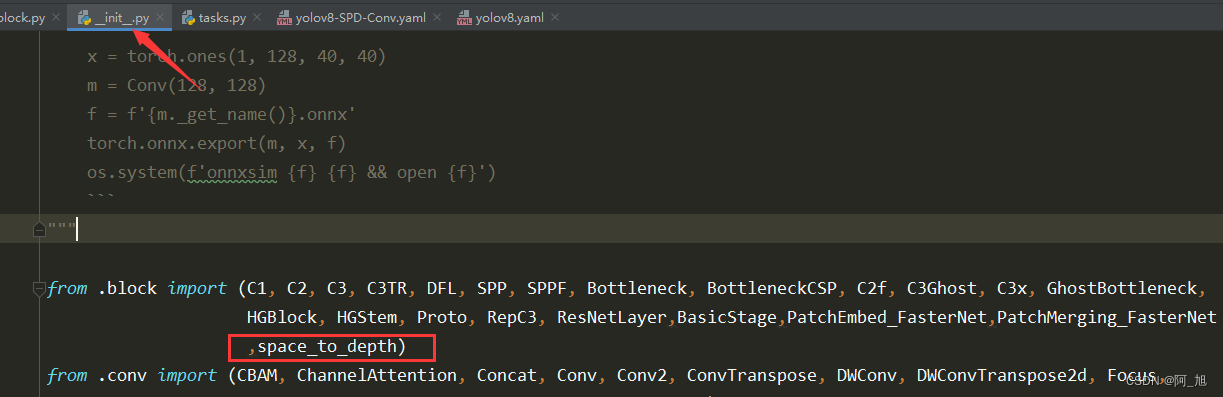
在ultralytics/nn/modules/__init__.py文件中的添加如下代码:
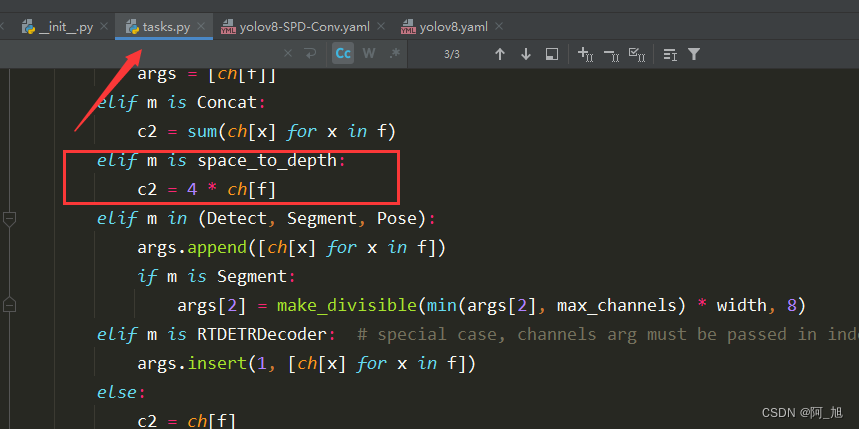
在 ultralytics/nn/tasks.py 上方导入相应类名,并在parse_model解析函数中添加如下代码:
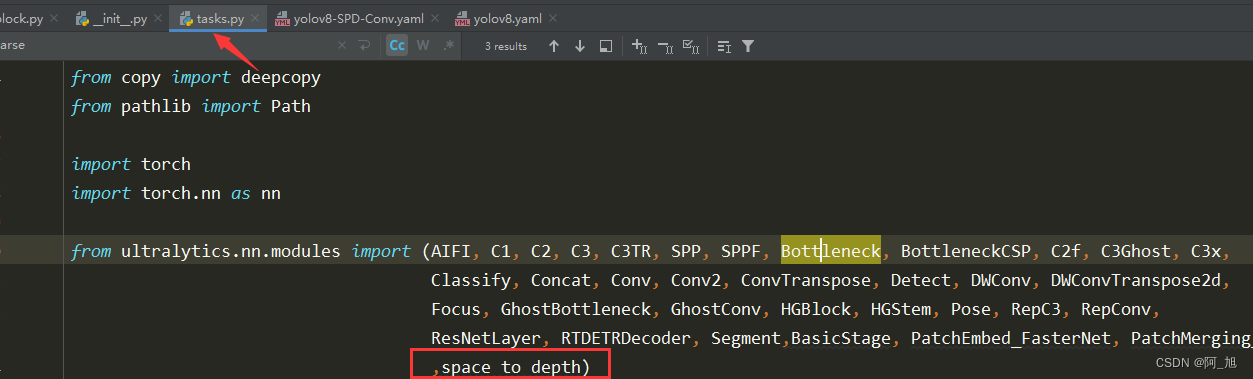
elif m is space_to_depth:
c2 = 4 * ch[f]
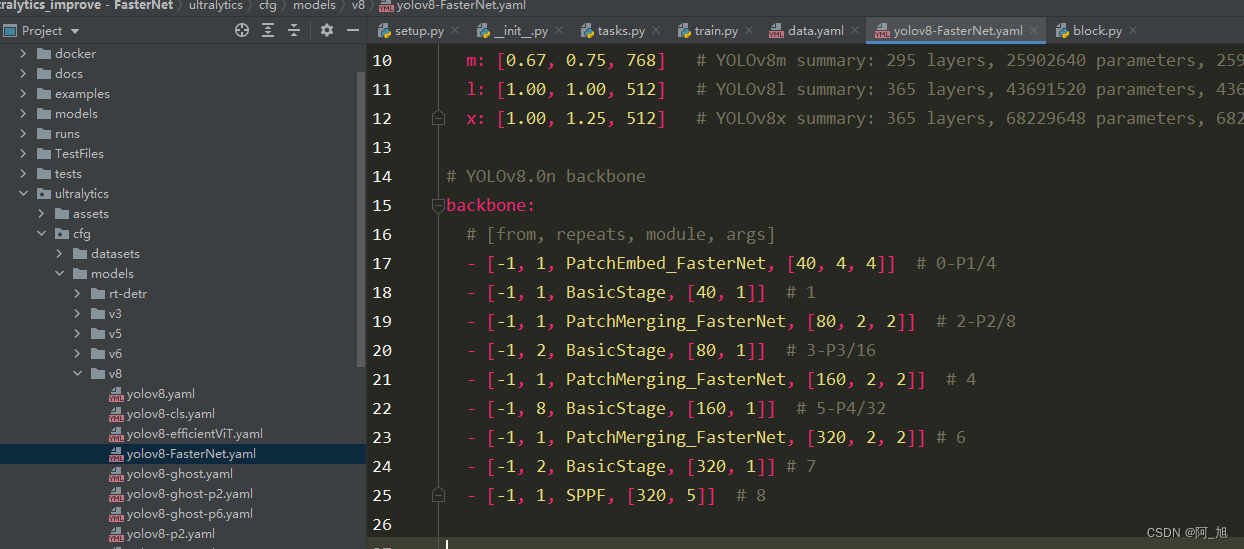
在ultralytics/cfg/models/v8文件夹下新建yolov8-FasterNet.yaml文件,内容如下:
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 1]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 1]] # 1-P2/4
- [-1, 1, space_to_depth, [1]] # 2 -P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 1]] # 4-P3/8
- [-1, 1, space_to_depth, [1]]
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 1]] # 7-P4/16
- [-1, 1, space_to_depth, [1]]
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 1]] # 10-P5/32
- [-1, 1, space_to_depth, [1]]
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 13
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 8], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 16
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 5], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 19 (P3/8-small)
- [-1, 1, Conv, [256, 3, 1]]
- [-1, 1, space_to_depth, [1]]
- [[-1, 16], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 23 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 1]]
- [-1, 1, space_to_depth, [1]]
- [[-1, 13], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 27 (P5/32-large)
- [ [ 19, 23, 27 ], 1, Detect, [ nc ] ] # Detect(P3, P4, P5)
3.加载配置文件并训练
加载yolov8-BiLevelRoutingAttention.yaml配置文件,并运行train.py训练代码:
#coding:utf-8
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8-SPD-Conv.yaml')
model.load('yolov8n.pt') # loading pretrain weights
model.train(data='datasets/TomatoData/data.yaml', epochs=50, batch=4)
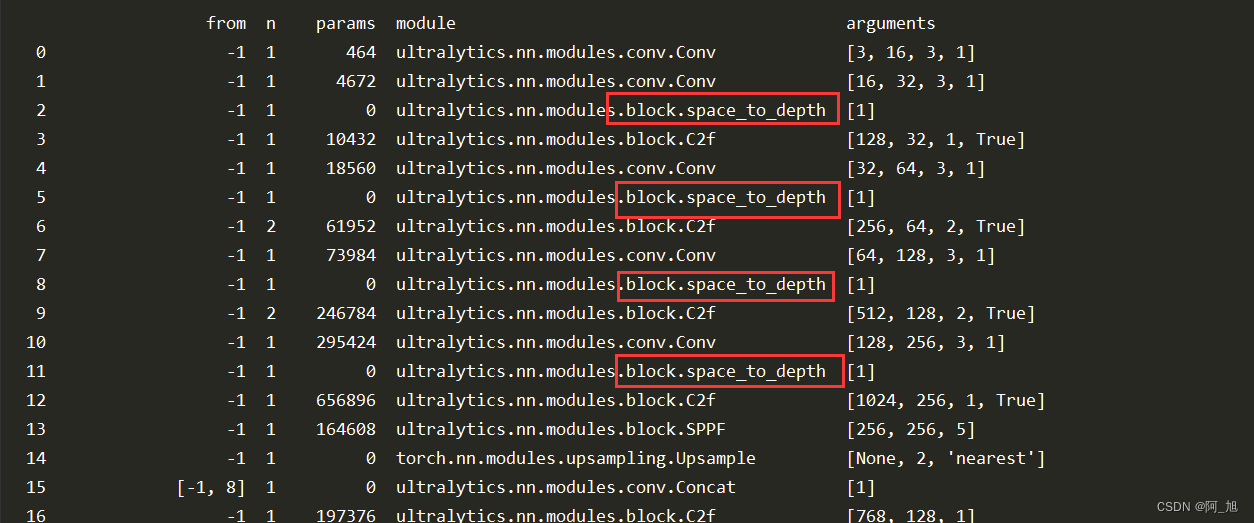
注意观察,打印出的网络结构是否正常修改,如下图所示:
4.模型推理
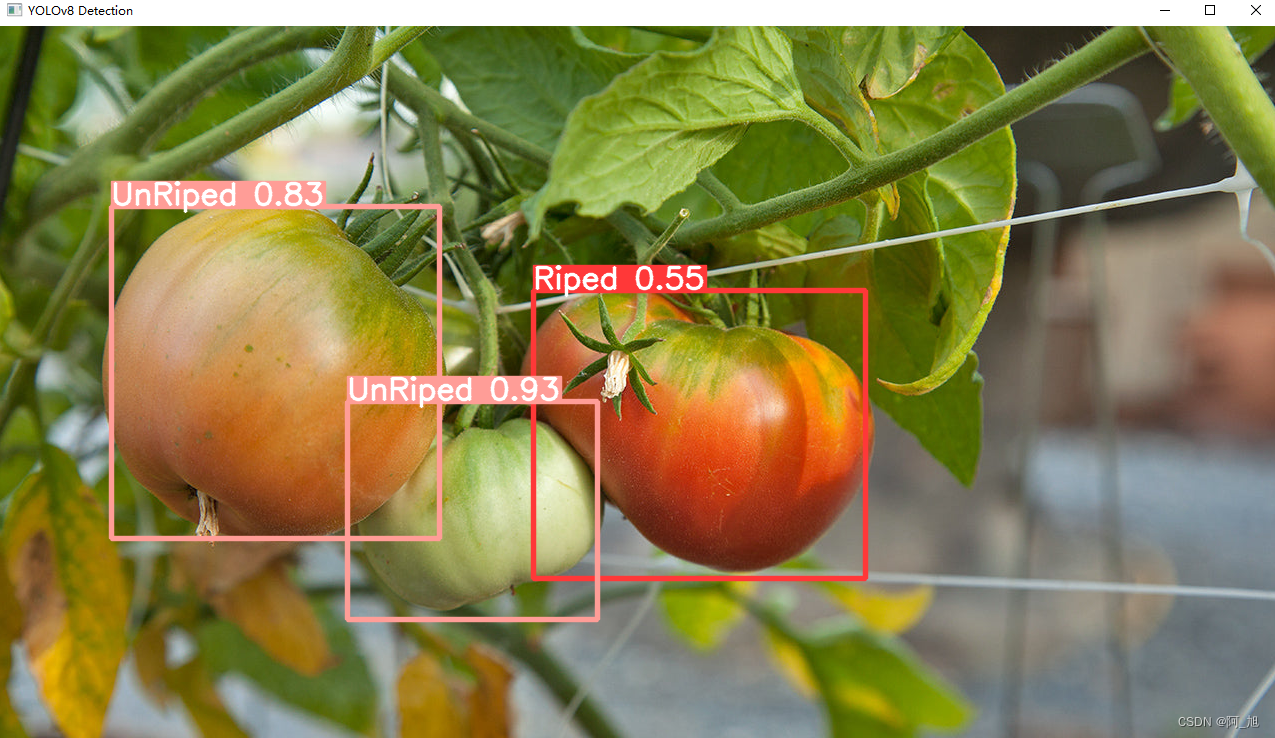
模型训练完成后,我们使用训练好的模型对图片进行检测:
#coding:utf-8
from ultralytics import YOLO
import cv2
# 所需加载的模型目录
# path = 'models/best2.pt'
path = 'runs/detect/train/weights/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/Riped tomato_8.jpeg"
# 加载预训练模型
# conf 0.25 object confidence threshold for detection
# iou 0.7 intersection over union (IoU) threshold for NMS
model = YOLO(path, task='detect')
# 检测图片
results = model(img_path)
res = results[0].plot()
# res = cv2.resize(res,dsize=None,fx=2,fy=2,interpolation=cv2.INTER_LINEAR)
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)
【源码免费获取】
为了小伙伴们能够,更好的学习实践,本文已将所有代码、示例数据集、论文等相关内容打包上传,供小伙伴们学习。获取方式如下:
结束语
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!
智能推荐
使用nginx解决浏览器跨域问题_nginx不停的xhr-程序员宅基地
文章浏览阅读1k次。通过使用ajax方法跨域请求是浏览器所不允许的,浏览器出于安全考虑是禁止的。警告信息如下:不过jQuery对跨域问题也有解决方案,使用jsonp的方式解决,方法如下:$.ajax({ async:false, url: 'http://www.mysite.com/demo.do', // 跨域URL ty..._nginx不停的xhr
在 Oracle 中配置 extproc 以访问 ST_Geometry-程序员宅基地
文章浏览阅读2k次。关于在 Oracle 中配置 extproc 以访问 ST_Geometry,也就是我们所说的 使用空间SQL 的方法,官方文档链接如下。http://desktop.arcgis.com/zh-cn/arcmap/latest/manage-data/gdbs-in-oracle/configure-oracle-extproc.htm其实简单总结一下,主要就分为以下几个步骤。..._extproc
Linux C++ gbk转为utf-8_linux c++ gbk->utf8-程序员宅基地
文章浏览阅读1.5w次。linux下没有上面的两个函数,需要使用函数 mbstowcs和wcstombsmbstowcs将多字节编码转换为宽字节编码wcstombs将宽字节编码转换为多字节编码这两个函数,转换过程中受到系统编码类型的影响,需要通过设置来设定转换前和转换后的编码类型。通过函数setlocale进行系统编码的设置。linux下输入命名locale -a查看系统支持的编码_linux c++ gbk->utf8
IMP-00009: 导出文件异常结束-程序员宅基地
文章浏览阅读750次。今天准备从生产库向测试库进行数据导入,结果在imp导入的时候遇到“ IMP-00009:导出文件异常结束” 错误,google一下,发现可能有如下原因导致imp的数据太大,没有写buffer和commit两个数据库字符集不同从低版本exp的dmp文件,向高版本imp导出的dmp文件出错传输dmp文件时,文件损坏解决办法:imp时指定..._imp-00009导出文件异常结束
python程序员需要深入掌握的技能_Python用数据说明程序员需要掌握的技能-程序员宅基地
文章浏览阅读143次。当下是一个大数据的时代,各个行业都离不开数据的支持。因此,网络爬虫就应运而生。网络爬虫当下最为火热的是Python,Python开发爬虫相对简单,而且功能库相当完善,力压众多开发语言。本次教程我们爬取前程无忧的招聘信息来分析Python程序员需要掌握那些编程技术。首先在谷歌浏览器打开前程无忧的首页,按F12打开浏览器的开发者工具。浏览器开发者工具是用于捕捉网站的请求信息,通过分析请求信息可以了解请..._初级python程序员能力要求
Spring @Service生成bean名称的规则(当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致)_@service beanname-程序员宅基地
文章浏览阅读7.6k次,点赞2次,收藏6次。@Service标注的bean,类名:ABDemoService查看源码后发现,原来是经过一个特殊处理:当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致public class AnnotationBeanNameGenerator implements BeanNameGenerator { private static final String C..._@service beanname
随便推点
二叉树的各种创建方法_二叉树的建立-程序员宅基地
文章浏览阅读6.9w次,点赞73次,收藏463次。1.前序创建#include<stdio.h>#include<string.h>#include<stdlib.h>#include<malloc.h>#include<iostream>#include<stack>#include<queue>using namespace std;typed_二叉树的建立
解决asp.net导出excel时中文文件名乱码_asp.net utf8 导出中文字符乱码-程序员宅基地
文章浏览阅读7.1k次。在Asp.net上使用Excel导出功能,如果文件名出现中文,便会以乱码视之。 解决方法: fileName = HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8);_asp.net utf8 导出中文字符乱码
笔记-编译原理-实验一-词法分析器设计_对pl/0作以下修改扩充。增加单词-程序员宅基地
文章浏览阅读2.1k次,点赞4次,收藏23次。第一次实验 词法分析实验报告设计思想词法分析的主要任务是根据文法的词汇表以及对应约定的编码进行一定的识别,找出文件中所有的合法的单词,并给出一定的信息作为最后的结果,用于后续语法分析程序的使用;本实验针对 PL/0 语言 的文法、词汇表编写一个词法分析程序,对于每个单词根据词汇表输出: (单词种类, 单词的值) 二元对。词汇表:种别编码单词符号助记符0beginb..._对pl/0作以下修改扩充。增加单词
android adb shell 权限,android adb shell权限被拒绝-程序员宅基地
文章浏览阅读773次。我在使用adb.exe时遇到了麻烦.我想使用与bash相同的adb.exe shell提示符,所以我决定更改默认的bash二进制文件(当然二进制文件是交叉编译的,一切都很完美)更改bash二进制文件遵循以下顺序> adb remount> adb push bash / system / bin /> adb shell> cd / system / bin> chm..._adb shell mv 权限
投影仪-相机标定_相机-投影仪标定-程序员宅基地
文章浏览阅读6.8k次,点赞12次,收藏125次。1. 单目相机标定引言相机标定已经研究多年,标定的算法可以分为基于摄影测量的标定和自标定。其中,应用最为广泛的还是张正友标定法。这是一种简单灵活、高鲁棒性、低成本的相机标定算法。仅需要一台相机和一块平面标定板构建相机标定系统,在标定过程中,相机拍摄多个角度下(至少两个角度,推荐10~20个角度)的标定板图像(相机和标定板都可以移动),即可对相机的内外参数进行标定。下面介绍张氏标定法(以下也这么称呼)的原理。原理相机模型和单应矩阵相机标定,就是对相机的内外参数进行计算的过程,从而得到物体到图像的投影_相机-投影仪标定
Wayland架构、渲染、硬件支持-程序员宅基地
文章浏览阅读2.2k次。文章目录Wayland 架构Wayland 渲染Wayland的 硬件支持简 述: 翻译一篇关于和 wayland 有关的技术文章, 其英文标题为Wayland Architecture .Wayland 架构若是想要更好的理解 Wayland 架构及其与 X (X11 or X Window System) 结构;一种很好的方法是将事件从输入设备就开始跟踪, 查看期间所有的屏幕上出现的变化。这就是我们现在对 X 的理解。 内核是从一个输入设备中获取一个事件,并通过 evdev 输入_wayland