关于爬虫学习的一些小小记录(二)——正则表达式匹配_爬虫 正则表达式怎么看匹配-程序员宅基地
关于爬虫学习的一些小小记录——正则表达式匹配
前面说了怎么访问一个 url,并读取返回的网页源码。有了源码文件,我们还要学会怎么从文件中查找、提取我们需要的数据。这次我们就简单讲讲怎么从源码文件中提取数据
正则表达式
说起提取数据,我就想到了正则表达式(此处不开花)
那什么是正则表达式?
请看,官方介绍
简单说,匹配字符串的
知道了是什么,再看看怎么学
这里列出可能要用到的匹配字符:

Python的re模块
Python 绝对是个处理数据的好能手,它的标准库中提供了强大的re模块,完整地实现了正则表达式的方法功能。简直天衣无缝,恐怖如斯!
这里是学习教程
同样列举一下可能会用到的方法(以及我理解的用法):
findall(pattern, string[, pos[, endpos]])
findall()方法,字面意思,可以在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。其中,
pattern 匹配的正则表达式
string 待匹配的字符串
pos 可选参数,指定字符串的起始位置,默认为 0
endpos 可选参数,指定字符串的结束位置,默认为字符串的长度
举个小栗子
演示一下从豆瓣上爬取2019版《倚天屠龙记》的演职员信息:
网页地址:https://movie.douban.com/subject/25865815/celebrities
我们先打开网页,右键查看源文件。找到演职员列表部分的源码,分析一下
我们发现,演职员的主要信息都在span标签中,再找我们需要提取的信息周围的特征
比如说,演职员名字信息前后,这是前面的部分
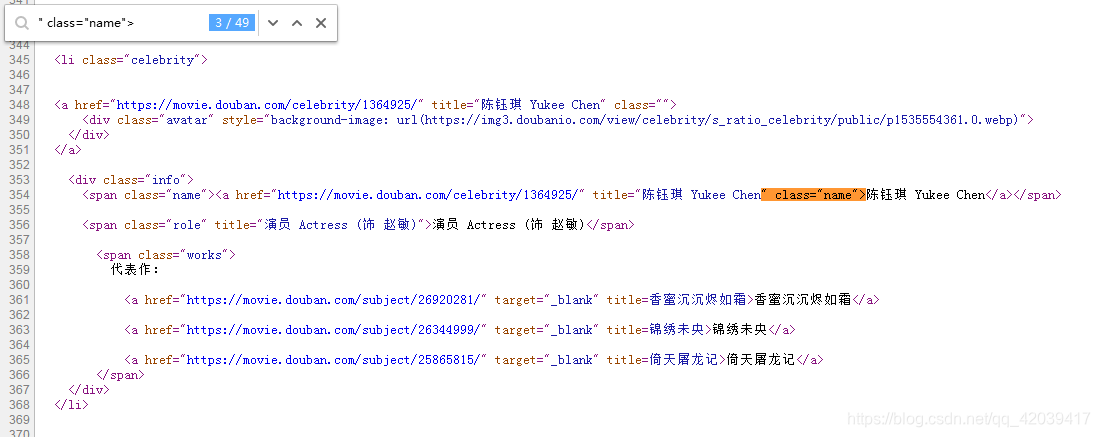
以及后面的部分

而恰好,演职员列表中刚好是49个人,所以我们只需要匹配正则表达式
" class="name">(.*)</a></span>
就可以获取我们需要的演职员姓名信息
代码如下
# 爬虫--爬取豆瓣 2019版 《倚天屠龙记》 全体演职员
import re
from urllib import request
url = 'https://movie.douban.com/subject/25865815/celebrities'
response = request.urlopen(url) # 访问 url
page = response.read().decode() # 以 utf-8 的格式读取数据
names = re.findall('" class="name">(.*)</a></span>', page) # 正则表达式匹配
print(names)
运行结果:
['蒋家骏 Jeffrey Chiang', '曾舜晞 Joseph Zeng', '陈钰琪 Yukee Chen', '祝绪丹 Xudan Zhu', '张超人 Chaoren Zhang', '林雨申 Shen Lin', '曹曦月 Xiyue Cao', '周海媚 Kathy Chow', '王德顺 Deshun Wang', '李东学 Ethan Li', '宗峰岩 Fengyan Zong', '黑子 Zi Hei', '樊少皇 Siu-Wong Fan', '肖荣生 Rongsheng Xiao ', '陈创 Chuang Chen', '杨明娜 Minna Yang', '陈欣予 Xinyu Chen', '许雅婷 Kabby Hui', '孙安可 Anke Sun', '杨一威 Yiwei Yang', '纪沨 Feng Ji', '李泰延 Taiyan Li', '宁文彤 Wentong Ning', '曾黎 Li Zeng', '金钊 Zhao Jin', '李浩轩 Hao-xuan Li', '阮圣文 Shengwen Ruan', '徐爱珉 Aimin Xu', '李曼铱 Manyi Li', '于波 Bo Yu', '李依晓 Xiaoyi Li', '李解 Jie Li', '李泽宇 Zeyu Li', '郭军 Jun Guo', '贺刚 Gang He', '宫正楠 Zhengnan Gong', '邬靖靖 Jingjing Wu', '韩昊霖 Haolin Han', '芦展翔 Zhanxiang Lu', '沈保平 Baoping Shen', '姜彦希 Yanxi Jiang', '侯瑞祥 Ruixiang Hou', '康嘉泽 Jiaze Kang', '林以政 Yizheng Lin', '谢雨辰 Yuchen Xie', '曲吉 Ji Qu', '欧阳小如 Xiaoru Ouyang', '关展博 Edwin Chin-Pok Kwan', '金庸 Louis Cha']
小小扩展
作为一个心中永远向往着学习的优秀者,当然是不能只满足于爬那么一两个名字信息
毕竟,来都来了,不如把图片也爬一下
我们接着分析源码,找一下图片链接
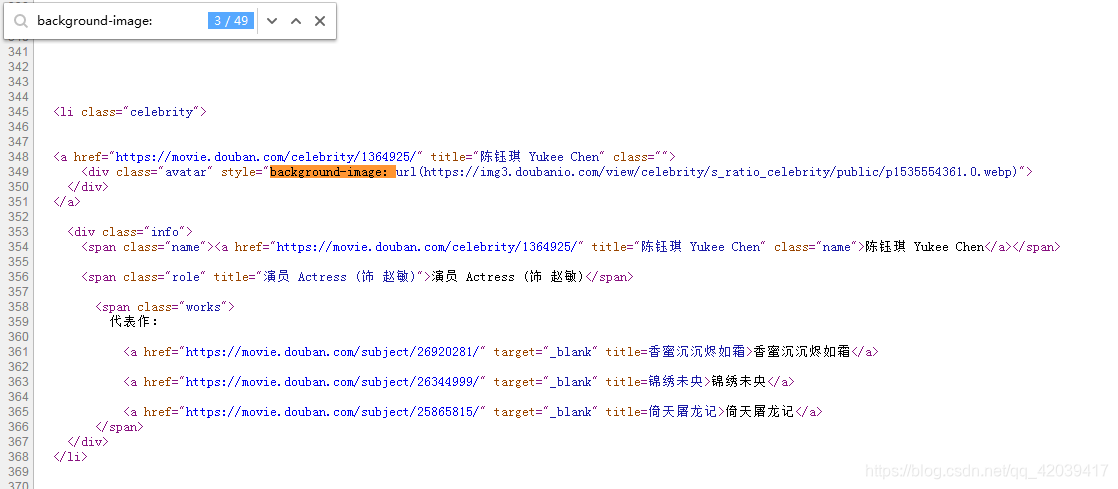
发现了吗,一下子就找到了关键点,简直不要太容易
明显的,括号里面就是我们需要的图片链接,不防打开看看

当然,链接毕竟不是图片文件。有了图片链接,我们还需要访问链接下载图片
这里介绍urllib库中的urlretrieve()方法,可以访问 url 并把网页源码下载到本地
urlretrieve(url, filename=None, reporthook=None, data=None)
url 指定待访问的网页地址
filename 指定了保存到本地的路径(如果参数未指定,urllib会生成一个临时文件保存数据)
reporthook 一个回调函数,可显示当前的下载进度。
data 指定 post 服务器的数据,返回一个包含两个元素的 (filename, headers) 元组,filename 表示保存到本地的路径,headers 表示服务器的响应头
简单点,再顺便把职位爬一下,过程跟爬名字信息的差不多
下面是扩展后的代码
# 爬虫--爬取豆瓣 2019版 《倚天屠龙记》 全体演职员
import re
from urllib import request
url = 'https://movie.douban.com/subject/25865815/celebrities'
response = request.urlopen(url) # 访问 url
page = response.read().decode() # 以 utf-8 的格式读取数据
names = re.findall('" class="name">(.*)</a></span>', page) # 正则表达式匹配
roles = re.findall('span class="role" title="(.*)">', page) # 匹配职位
imgs = re.findall('style="background-image: url\((.*)\)">', page) # 匹配图片链接
i = 0
while i < len(names):
role_list = roles[i].split(' ') # 避免因文件名过长无法建立,只好从这里切短
role = role_list[0] + ' (' + role_list[-1] # 切碎了重新拼一下
img_name = r'19版《倚天屠龙记》演职员/' + names[i] + ' ' + role + r'.jpg'
img = request.urlretrieve(imgs[i], img_name)
i += 1
运行结果
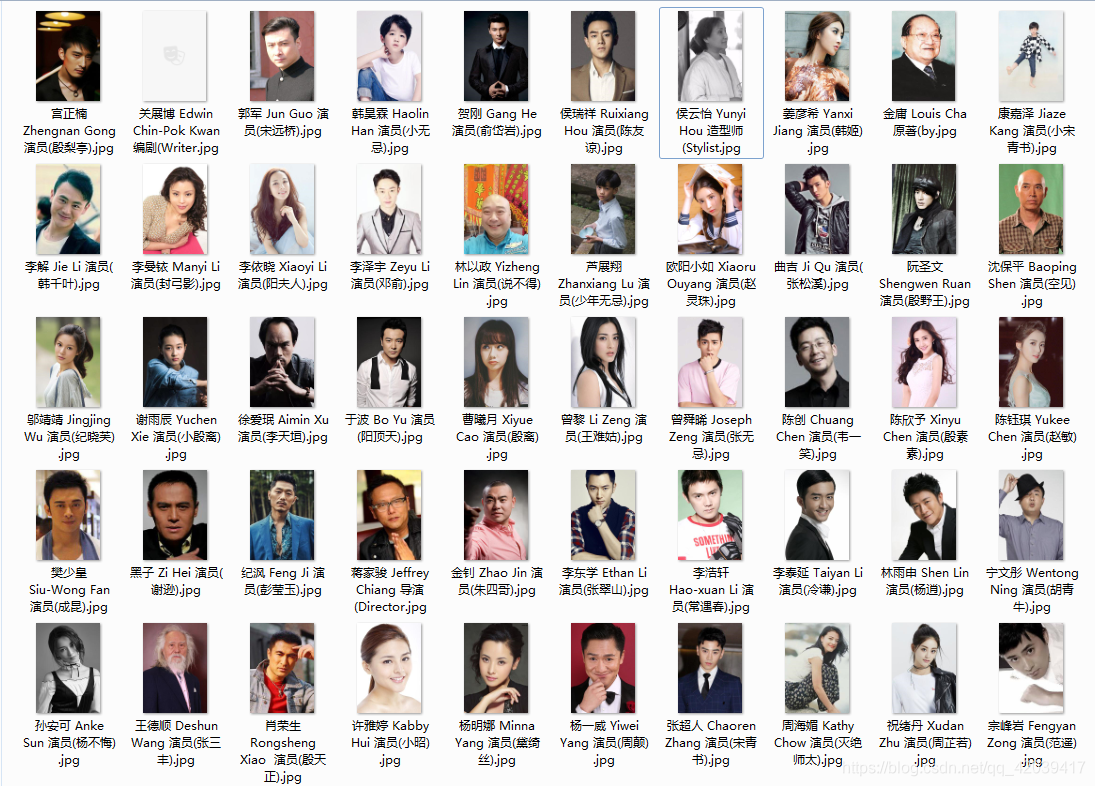
我咧个去!!!
怎么会有 50 个???
重新打开网页
天ya噜!!在我刚刚改代码的时候,他又多了个人
智能推荐
程序运行中可以改变数组的大小_EPLAN中的电气符号可以改变大小吗?可以的,只需7步...-程序员宅基地
文章浏览阅读1.5k次。修改电气符号的大小之前有好多朋友问我Eplan这个软件可以修改符号大小吗?其实可以修改但是不建议修改。因为这是对整个符号库放大和缩小,一旦失误就很难恢复了。效果演示方法如下:1.找到EPLAN安装目录下的数据/符号文件夹,默认安装的位置:C:甥敳獲PublicEPLANData符号Home2.在桌面或者文件夹里新建一个自己的文件夹,把系统自带的GB_symbol与GB_symbol.sdb复制到新..._gb-symbol
修改android原型button样式_android studio 修改button默认样式-程序员宅基地
文章浏览阅读1.2k次。<Button android:id="@+id/button_login" android:layout_width="123px" android:layout_height="45px" android:text="@string/str_login" android:background="@drawable/
iOS 获取URL链接中的各参数_ios 获取url参数-程序员宅基地
文章浏览阅读5.1k次。1、iOS请求URL中含有中文怎么办?使用UTF-8编码一下就OK了NSString* encodedString = [urlString stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];2、iOS获取URL链接中的各个参数值:例:http://example.com?param1=value1¶m2=param2通过对一个合法的url(第一个参数用"?“连接,且url中只有一个”?",剩下的参数用_ios 获取url参数
R语言|while循环————R语言入门到入土系列(九)_r语言while循环-程序员宅基地
文章浏览阅读6k次,点赞3次,收藏16次。本文介绍了R语言while循环的写法,并以连加1到1000为例简单介绍用法_r语言while循环
pycallgraph 安装失败,一直报subprocess-exited-with-error_setuptools降级-程序员宅基地
文章浏览阅读5.2k次,点赞17次,收藏11次。两个方式安装pycallgraph均报subprocess-exited-with-error异常_setuptools降级
POJ 2299 Ultra-QuickSort-程序员宅基地
文章浏览阅读708次。Ultra-QuickSortTime Limit: 7000MSMemory Limit: 65536KTotal Submissions: 51274Accepted: 18803DescriptionIn this problem, you have to analyze a particular sorting algorithm. The algori
随便推点
计算机操作系统习题-第二章(进程的描述与控制)-进程与状态转换与进程控制_下列说法中,错误的是( ) a.运行进程提出i/o请求要进入阻塞状态 b.进程挂起应进-程序员宅基地
进程与状态转换:进程特征中,不是进程特征的是静态性。对进程的描述中,错误的是仅①和③。一个进程被唤醒意味着进程变为就绪状态。
0223代码备份-程序员宅基地
文章浏览阅读283次,点赞9次,收藏8次。【代码】0223代码备份。
SuperTextView for Android 是一个在 TextView 的基础上扩展了几种动画效果的控件。_com.king.view.supertextview.supertextview-程序员宅基地
文章浏览阅读600次。SuperTextView项目地址:jenly1314/SuperTextView 简介:SuperTextView for Android 是一个在 TextView 的基础上扩展了几种动画效果的控件。更多:作者 提 Bug 标签:SuperTextView-TextView-dynamic-typing-typewriting- SuperTextVie..._com.king.view.supertextview.supertextview
tf版SSD训练自己的数据集--配置:TensorFlow-GPU1.2.0+python3.5.2+CUDA8.0_train_ssd text.txt-程序员宅基地
文章浏览阅读923次。一、训练本文主要记录自己在使用TensorFlow版SSD算法训练自己的数据集时的步骤。我的文件夹具体内容如下图所示。这里只能显示文件夹,单独的文件无法显示。1.数据集准备数据集按照VOC的格式进行制作,图片标注的工具使用的是labelImg。数据集文件夹存放的方式需要稍作改变。具体格式如图片所示,文件夹分为test和train两个文件夹,Annotations文件夹放置的是对应的图片的..._train_ssd text.txt
Linux(CentOS 7)+ Nginx(1.10.2)+ Mysql(5.7.16)+ PHP(7.0.12)完整环境搭建_linux centos php搭建-程序员宅基地
文章浏览阅读256次。首先安装Linux系统,我以虚拟机安装来做示例,先去下载 VitualBox,这是一款开源的虚拟机软件,https://www.virtualbox.org 官网地址。或者是VMware,www.vmware.com,不过这个软件是收费的。当然同时还要去下载一个Linux镜像,我下载是CentOS 7系统,https://www.centos.org/download下载好了之后打开虚拟机,我..._linux centos php搭建
卷积神经网络实现图像识别_picture_predictions.model_predictions import netwo-程序员宅基地
文章浏览阅读1.8w次,点赞57次,收藏543次。项目简介目的: 实现昆虫的图像分类,同时该模型也可以用于其他图像的分类识别,只需传入相应的训练集进行训练,保存为另一个模型即可,进行调用使用。配置环境: pycharm(python3.7),导入pytotch库知识预备: 需要了解卷积神经网络的基本原理与结构,熟悉pytorch的使用,csdn有很多介绍卷积神经网络的文章,可查阅。算法设计思路:(1) 收集数据集,利用 python 的 requests 库和 bs4 进行网络爬虫,下载数据集(2) 搭建卷积神经网络(3)对卷积神经网络进行训_picture_predictions.model_predictions import network_bn