LLMs:《Instruction Tuning for Large Language Models: A Survey—大型语言模型的指令调优的综述》翻译与解读-程序员宅基地
技术标签: NLP/LLMs 语言模型 人工智能 AI/AGI 自然语言处理
LLMs:《Instruction Tuning for Large Language Models: A Survey—大型语言模型的指令调优的综述》翻译与解读
导读:2023年8月21日,浙江大学等团队,发布了《Instruction Tuning for Large Language Models: A Survey》。指令微调是在大规模语言模型的基础上,使用包含(指令,输出)的监督数据进行进一步训练,以减小模型原有的预测目标与用户指令之间的差距。其目的是增强模型的能力和可控性。
>> 指令微调的方法,包括构建指令数据集、进行指令微调等。构建指令数据集可基于现有数据集转换,也可以使用语言模型自动生成。指令微调则是在指令数据集上进行监督训练。
>> 指令数据集的类型,包括自然指令、非自然指令、跨语言指令、对话指令等多种类型。
>> 应用指令微调的语言模型,如InstructGPT、Alpaca、Vicuna等在大型预训练语言模型基础上进行指令微调的模型。
>> 指令微调的效果评估、分析和批评,需要关注指令数据集的质量、指令学习是否只停留在表面模仿等问题。
>> 提高指令微调效率的方法,如基于适配器、重参数化等方法来进行高效微调。
LLMs指令微调技术通过构建丰富的指令数据集和采用有监督学习的方式,能有效提升开源LLMs的能力和可控性。主要技术点包括构建多种指令数据集方式自然指令、非自然指令以及多模态指令等,采用指令微调的方法对LLMs进行微调,例如基于GPT、T5、LLaMA等骨干模型,采用LOMO、DELTA微调等高效微调技术。指令微调取得很好效果,但是否只是学习表面模式尚存在争议,未来应注重提升指导质量和多方面评估。
目录
LLMs之Data:指令微调的简介、Self Instruction思想(一种生成指令数据集的方法论—主要用在指令微调阶段)的简介、Alpaca/BELLE应用、实战案例代码实现之详细攻略
2023年8月21日—Paper:《Instruction Tuning for Large Language Models: A Survey—大型语言模型的指令调优的综述》翻译与解读
《Instruction Tuning for Large Language Models: A Survey—大型语言模型的指令调优的综述》翻译与解读
指令微调技术(增强LLM的能力和可控性,有监督微调+增量训练)、指令对
LLM显著进展(GPT-3→PaLM→LLaMA)、当前痛点(训练目标与用户目标间的不匹配)、
提出指令微调技术(解决不匹配)、指令微调的3个好处(弥合误差+为人类提供介入模型行为的渠道+性价比高)
指令微调的3大挑战:高质量性、改善严重依赖数据性、可能只学皮毛性
2.1、Instruction Dataset Construction指令数据集构建:
数据实例三元素:instruction【指定任务】、input【补充上下文】、output【预期输出】
2.2、Instruction Tuning指令微调:有监督的训练
3.1、Natural Instructions自然指令:来自193K个实例和61个NLP任务,2元组{输入,输出}
3.2、P3公共提示池:整合170个英语NLP数据集和2052个英语提示,三元组{“输入”【描述任务】+“答案选择”【响应列表】+“目标”【正确响应】}
3.3、xP3跨语言公共提示池:46种语言中16类NLP任务,2元组{输入和目标}
3.4、Flan 2021:将63个NLP基准转换为输入-输出对进而构建,2元组{输入+目标}
3.5、Unnatural Instructions非自然指令:基于InstructGPT构建的24万个实例,4元组{指令+输入+约束+输出}
LLMs之Data:指令微调的简介、Self Instruction思想(一种生成指令数据集的方法论—主要用在指令微调阶段)的简介、Alpaca/BELLE应用、实战案例代码实现之详细攻略
包含基于InstructGPT的52K个训练指令和252个评估指令,3元组{“指令”【定义任务】+“输入”【指令的内容补充】+“输出”【正确结果】}
形成过程:基于52K的初始集→随机选择1个进化策略让ChatGPT重写指令→过滤未进化的指令对(利用ChatGPT和规则)→利用新生成进化指令对更新数据集→重复上述四次→收集了25万个指令对
3.8、LIMA:包含1K数据实例的训练集(75%源自3个社区问答网站)和300个实例的测试集,二元组{instruction, response}
3.9、Super-Natural Instructions超级自然指令:包含1616个NLP任务和500万个任务实例+涵盖76种任务类型和55种语言,二元组(“指令”和“任务实例”)
3.10、Dolly:包含15000个人工生成英语指令+7种特定类型
3.11、OpenAssistant Conversations
包含158K条消息(90K个用户提示+68K个助手回复),35种语言中65K个对话树+450K个人工注释的质量评分,对话树(节点,路径/线程)
五步流程收集对话树:提示者→标记提示→扩展树节点→标记回复→排名
3.12、Baize:基于ChatGPT(self-chat思想)构建的111.5K个实例多轮(3.4轮)聊天语料库,二元组{prompt,response}
4、Instruction Fine-tuned LLMs指导微调的LLM模型
4.1、InstructGPT:基于GPT-3模型+人类指导微调
LLMs之InstructGPT:《Training language models to follow instructions with human feedback》翻译与解读
微调三步骤(基于人类筛选指令进行SFT→基于一个instruction多个降序的responses来训练RM模型→利用RL的PPO策略优化RM模型)
InstructGPT的真实性、毒性、模型性能等表现非常出色
4.2、BLOOMZ:基于BLOOM模型+指令数据集xP3,多种任务及其数据集上表现均超于BLOOM
LLMs:《BLOOM: A 176B-Parameter Open-Access Multilingual Language Model》翻译与解读
4.3、Flan-T5:基于T5模型+FLAN数据集微调,基于JAX的T5X框架+128*TPU v4=37小时
4.4、Alpaca:基于LLaMA模型+利用InstructGPT生成指令数据集进行微调,8*A100-80G设备+混合精度AMP+DP=3小时
LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读
LLMs之Vicuna:《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读
AIGC之GPT-4:GPT-4的简介(核心原理/意义/亮点/技术点/缺点/使用建议)、使用方法、案例应用(计算能力/代码能力/看图能力等)之详细攻略
4.8、WizardLM:基于LLaMA模型+Evol-Instruct指令数据集(ChatGPT生成)微调,8*V100 GPU+Deepspeed Zero-3技术+3个epochs =70小时
LLMs之ChatGLM2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
4.10、LIMA:基于LLaMA模型+基于表面对齐假设构建的指令数据集,提出了表面对齐假设并验证了其效果
LLMs:《OPT: Open Pre-trained Transformer Language Models》翻译与解读
Dolly 2:基于Pythia模型+微调databricks-dolly-15k指令数据集
Falcon-Instruct:基于Falcon模型+微调英语对话数据集(Baize数据集150M/1.5亿tokens+RefinedWeb数据集),降内存(Flash Attention+MQ)
Guanaco:基于LLaMA+微调多语言对话数据集(源自包含52K英文指令数据对的Alpaca+534K的多轮对话的多语言)
LLMs之Guanaco:《QLoRA:Efficient Finetuning of Quantized LLMs》翻译与解读
Minotaur:基于Starcoder Plus模型+微调WizardLM和GPTeacher-General-Instruc指令数据集
Nous-Herme:基于LLaMA模型+微调BiologyPhysicsChemistry子集的300K个指令
YuLan-Chat:基于LLaMA模型+微调双语数据集(25万个中英文指令对)
Airoboros:基于LLaMA+微调Self-instruct数据集
5、Multi-modality Instruction Fine-tuning多模态指令微调
5.1、Multi-modality Datasets多模态数据集
MUL-TIINSTRUCT—多模态指令微调数据集—OFA模型:由62个不同的多模态任务组成+统一的序列到序列格式
PMC-VQA—大规模的医学视觉问答数据集—MedVInT模型:227k个图像-问题对和149k个图像,从PMC-OA收集图像-标题对+ChatGPT生成问题-答案对+手工验证
LAMM—2D图像和3D点云理解:包含186K个语言-图像指令-响应对,以及10K个语言-点云指令-响应对
5.2、Multi-modality Instruction Fine-tuning Models多模态指令微调模型
InstructPix2Pix条件扩散模型:基于Stable Diffusion+微调多模态数据集(综合两大模型能力【GPT-3、Stable Diffusion】来生成)
LLaVA:基于CLIP视觉编码器和LLaMA语言解码器模型+微调158K个独特的语言-图像指令-跟随样本的教学视觉语言数据集(利用GPT-4转换格式)
Video-LLaMA多模态框架:由两个分支编码器组成(视觉-语言VL分支和音频-语言AL分支+语言解码器LLaMA)
InstructBLIP视觉-语言指令微调框架:基于BLIP-2模型(图像编码器+LLM+Query Transformer)
Otter:基于OpenFlamingo模型+只微调Perceiver重采样模块、交叉注意力层和输入/输出嵌入
6、Domain-specific Instruction Finetuning特定领域指令微调
6.1、Dialogue对话—InstructDial、LINGUIST模型:每个任务实例{任务描述、实例输入、约束、指令和输出}+两个元任务(指令选择任务+指令二元任务)
CoEdIT辅助写作:基于对FLANT模型+微调在文本编辑的指令数据集,两元组{指令:源,目标}
CoPoet协作的诗歌写作工具:基于T5模型+微调诗歌写作数据集,两元组{指令,诗行}
2023年6月14日,Radiology-GPT针对放射学领域:基于Alpaca+微调放射学领域知识数据集,两元组{发现,结论}
2023年4月18日,ChatDoctor:基于LLaMA模型+微调Alpaca指令数据集和HealthCareMagic100k患者-医生对话数据集且检索外部知识数据库
2023年3月,ChatGLM-Med:基于ChatGLM模型+微调中国医学指令数据集(基于GPT3.5的API和医学知识图谱创建问题-答案对)
6.7、Arithmetic算术:Goat=基于LLaMA模型+微调算术问题数据集(ChatGPT生成数百个指令+自然语言问答的形式表达)
6.8、Code代码:WizardCoder=基于StarCoder模型+Evol-Instruct方法+微调Code Alpaca数据集,3元组{指令、输入、期望输出}
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略
2023年,LLMs之Code:Code Llama的简介(衍生模型如Phind-CodeLlama/WizardCoder)、安装、使用方法之详细攻略
LLMs之Law:大语言模型领域行业场景应用之大模型法律行业的简介、主流LLMs(PowerLawGLM/ChatLaw)、经典应用之详细攻略
7、Efficient Tuning Techniques高效微调技术
7.1、基于重参数化—LoRA=基于DeepSpeed框架+训练低维度的A和B→可训练参数比完全微调少得多(LoRA训练GPT-3可降低到千分之一)
7.2、基于添加式—HINT=添加易于微调的模块(基于超网络数生成器生成适配器和前缀参数)+插入到骨干模型作为高效的微调模块
7.3、基于重参数化—QLoRA=LoRA的量化版+NF4+双量化DQ+分页优化器PO
7.4、基于重参数化—LOMO=降低梯度内存需求(融合梯度计算与参数更新+实时只存储单个参数的梯度)+稳定训练(梯度值裁剪+分离梯度范数计算+态损失缩放)+节省内存(激活检查点+ZeRO优化)
7.5、基于规范化—Delta-tuning=优化和最优控制视角+将微调限制在低维流形上来执行子空间优化+微调参数充当最优控制器+在下游任务中引导模型行为
8、Evaluation, Analysis and Criticism评估、分析和批评
8.1、HELM Evaluation:整体评估+提高LM透明度+关注三因素(广泛性+多指标性+标准化)
8.2、Low-resource Instruction Tuning低资源指令微调:STL需要数据量的25%、MTL需要数据量的6%
8.3、Smaller Instruction Dataset更小的指令数据集:LIMA(精选1,000个训练示例)表面可过少数精心策划的指令进行微调
8.4、Evaluating Instruction-tuning Datasets评估指令微调数据集:缺乏开放性和主观性的评估
8.5、Do IT just learn Pattern Copying?IT是否只是学习模式复制?——有论文指出基于IT的显著改进只是捕获表面级别模式而非理解了本质
8.6、Proprietary LLMs Imitation专有LLMs模仿:微调模型能效仿ChatGPT的表达风格,但不等于提升其通用能力→更应注重基模型及指导实例的质量
相关文章
LLMs之Data:指令微调的简介、Self Instruction思想(一种生成指令数据集的方法论—主要用在指令微调阶段)的简介、Alpaca/BELLE应用、实战案例代码实现之详细攻略
2023年8月21日—Paper:《Instruction Tuning for Large Language Models: A Survey—大型语言模型的指令调优的综述》翻译与解读
《Instruction Tuning for Large Language Models: A Survey—大型语言模型的指令调优的综述》翻译与解读
| 地址 |
论文地址:https://arxiv.org/abs/2308.10792 文章地址:Instruction Tuning for Large Language Models: A Survey | Papers With Code 文章地址:Instruction Tuning for Large Language Models: A Survey - AMiner |
| 时间 |
2023年8月21日 |
| 作者 |
浙江大学等 Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu Tianwei Zhang▲, Fei Wu and Guoyin Wang |
Abstract摘要
指令微调技术(增强LLM的能力和可控性,有监督微调+增量训练)、指令对
| This paper surveys research works in the quickly advancing field of instruction tuning (IT), a crucial technique to enhance the capabilities and controllability of large language models (LLMs). Instruction tuning refers to the process of further training LLMs on a dataset consisting of (Instruction, Output) pairs in a supervised fashion, which bridges the gap between the next-word prediction objective of LLMs and the users’ objective of having LLMs adhere to human instructions. In this work, we make a systematic review of the literature, including the general methodology of IT, the construction of IT datasets, the training of IT models, and applications to different modalities, domains and application, along with analysis on aspects that influence the outcome of IT (e.g., generation of instruction outputs, size of the instruction dataset, etc). We also review the potential pitfalls of IT along with criticism against it, along with efforts pointing out current deficiencies of existing strategies and suggest some avenues for fruitful research. |
本文调查了指令微调(IT)领域中的研究工作,这是一种关键技术,用于增强大型语言模型(LLM)的能力和可控性。指令微调是指以监督方式进一步训练LLM,使用由(Instruction, Output)对组成的数据集,从而弥合LLM的下一个词预测目标与用户要求LLM遵循人类指令的目标之间的差距。 在本工作中,我们对文献进行了系统回顾,包括IT的一般方法、IT数据集的构建、IT模型的训练,以及应用于不同形式、领域和应用的应用,以及影响IT结果的因素的分析(例如,指令输出的生成、指令数据集的大小等)。我们还回顾了IT的潜在风险,以及对其的批评,同时还指出了现有策略的当前不足之处,并提出了一些有益的研究方向。 |
1 Introduction引言
LLM显著进展(GPT-3→PaLM→LLaMA)、当前痛点(训练目标与用户目标间的不匹配)、
| The field of large language models (LLMs) has witnessed remarkable progress in recent years. LLMs such as GPT-3 (Brown et al., 2020b), PaLM (Chowdhery et al., 2022), and LLaMA (Touvron et al., 2023a) have demonstrated impressive capabilities across a wide range of natural language tasks (Zhao et al., 2021; Wang et al., 2022b, 2023a; Wan et al., 2023; Sun et al., 2023c; Wei et al., 2023; Li et al., 2023a; Gao et al., 2023a; Yao et al., 2023; Yang et al., 2022a; Qian et al., 2022; Lee et al., 2022; Yang et al., 2022b; Gao et al., 2023b; Ning et al., 2023; Liu et al., 2021b; Wiegreffe et al., 2021; Sun et al., 2023b,a;Adlakha et al., 2023; Chen et al., 2023). One of the major issues with LLMs is the mismatch between the training objective and users’ objective: LLMs are typically trained on minimizing the contextual word prediction error on large corpora; while users want the model to "follow their instructions helpfully and safely" (Radford et al., 2019; Brown et al., 2020a; Fedus et al., 2021; Rae et al., 2021; Thoppilan et al., 2022) |
近年来,大型语言模型(LLM)领域取得了显着进展。诸如GPT-3(Brown等,2020b)、PaLM(Chowdhery等,2022)和LLaMA(Touvron等,2023a)等LLM在各种自然语言任务中展示了令人印象深刻的能力。 LLM的一个主要问题是训练目标与用户目标之间的不匹配:LLM通常在最小化大型语料库上的上下文词预测误差的基础上进行训练,而用户希望模型“有助于并安全地遵循他们的指令”(Radford等,2019;Brown等,2020a;Fedus等,2021;Rae等,2021;Thoppilan等,2022)。 |
提出指令微调技术(解决不匹配)、指令微调的3个好处(弥合误差+为人类提供介入模型行为的渠道+性价比高)
| To address this mismatch, instruction tuning (IT) is proposed, serving as an effective technique to enhance the capabilities and controllability of large language models. It involves further training LLMs using (Instruction, Output) pairs, where INSTRUCTION denotes the human instruction for the model, and OUTPUT denotes the desired output that follows the INSTRUCTION. The benefits of IT are threefold: (1) Finetuning an LLM on the instruction dataset bridges the gap between the next-word prediction objective of LLMs and the users’ objective of instruction following; (2) IT allows for a more controllable and predictable model behavior compared to standard LLMs. The instructions serve to constrain the model’s outputs to align with the desired response characteristics or domain knowledge, providing a channel for humans to intervene with the model’s behaviors; and (3) IT is computationally efficient and can help LLMs rapidly adapt to a specific domain without extensive retraining or architectural changes. |
为了解决这种不匹配,提出了指令微调(IT),作为增强大型语言模型能力和可控性的有效技术。它涉及使用(Instruction, Output)对进一步训练LLM,其中指令表示模型的人类指令,输出表示遵循指令的所需输出。 IT的好处有三个: (1)在指令数据集上微调LLM弥合了LLM的下一个词预测目标与用户遵循指令目标之间的差距; (2)与标准LLM相比,IT允许模型行为更可控和可预测。指令用于限制模型的输出,使其与期望的响应特性或领域知识保持一致,为人类提供介入模型行为的渠道; (3)IT在计算上是高效的,并且可以帮助LLM在不需要大量重新训练或架构更改的情况下迅速适应特定领域。 |
指令微调的3大挑战:高质量性、改善严重依赖数据性、可能只学皮毛性
| Despite its effectiveness, IT also poses challenges: (1) Crafting high-quality instructions that properly cover the desired target behaviors is non-trivial: existing instruction datasets are usually limited in quantity, diversity, and creativity; (2) there has been an increasing concern that IT only improves on tasks that are heavily supported in the IT training dataset (Gudibande et al., 2023); and (3) there has been an intense criticism that IT only captures surface-level patterns and styles (e.g., the output format) rather than comprehending and learning the task (Kung and Peng, 2023). Improving instruction adherence and handling unanticipated model responses remain open research problems. These challenges highlight the importance of further investigations, analysis, and summarization in this field, to optimize the fine-tuning process and better understand the behavior of instruction fine-tuned LLMs. |
尽管其有效性,IT也带来了挑战: (1)制定高质量的指令以正确覆盖所需的目标行为并不容易:现有的指令数据集通常在数量、多样性和创意方面受限; (2)越来越多的人担心,IT只会改善那些在IT训练数据集中得到大量支持的任务(Gudibande et al., 2023); (3)有人强烈批评IT只捕获表面模式和样式(例如,输出格式),而不是理解和学习任务(Kung和Peng,2023)。 改进指令遵循和处理意外模型响应仍然是未解决的研究问题。 这些挑战强调了进一步调查、分析和总结在这一领域的重要性,以优化微调过程并更好地理解经过指令微调的LLM的行为。 |
| In the literature, there has been an increasing research interest in analysis and discussions on LLMs, including pre-training methods (Zhao et al., 2023), reasoning abilities (Huang and Chang, 2022), downstream applications (Yang et al., 2023; Sun et al., 2023b), but rarely on the topic of LLM instruction finetuning. This survey attempts to fill this blank, organizing the most up-to-date state of knowledge on this quickly advancing field. Specifically, >>Section 2 presents the general methodology employed in instruction fine-tuning. >>Section 3 outlines the construction process of commonly-used IT representative datasets. >>Section 4 presents representative instruction- finetuned models. >>Section 5 reviews multi-modality techniques and datasets for instruction tuning, including images, speech, and video. >>Section 6 reviews efforts to adapt LLMs to different domains and applications using the IT strategy. >>Section 7 reviews explorations to make instruction fine-tuning more efficient, reducing the computational and time costs associated with adapting large models. >>Section 8 presents the evaluation of IT models, analysis on them, along with criticism against them. |
在文献中,人们越来越关注对LLM进行分析和讨论,包括预训练方法(Zhao等,2023),推理能力(Huang和Chang,2022),下游应用(Yang等,2023;Sun等,2023b),但很少涉及LLM指令微调这个主题。本调查试图填补这一空白,整理关于这一快速发展领域的最新知识状态。具体而言, 第2节介绍了指令微调中采用的一般方法。 第3节概述了常用IT代表性数据集的构建过程。 第4节介绍了代表性的经过指令微调的模型。 第5节回顾了用于指令微调的多模态技术和数据集,包括图像、语音和视频。 第6节回顾了使用IT策略将LLM调整为不同领域和应用的努力。 第7节回顾了使指令微调更高效的探索,减少与调整大型模型相关的计算和时间成本。 第8节介绍了对IT模型的评估、分析以及对它们的批评。 |
2、Methodology方法
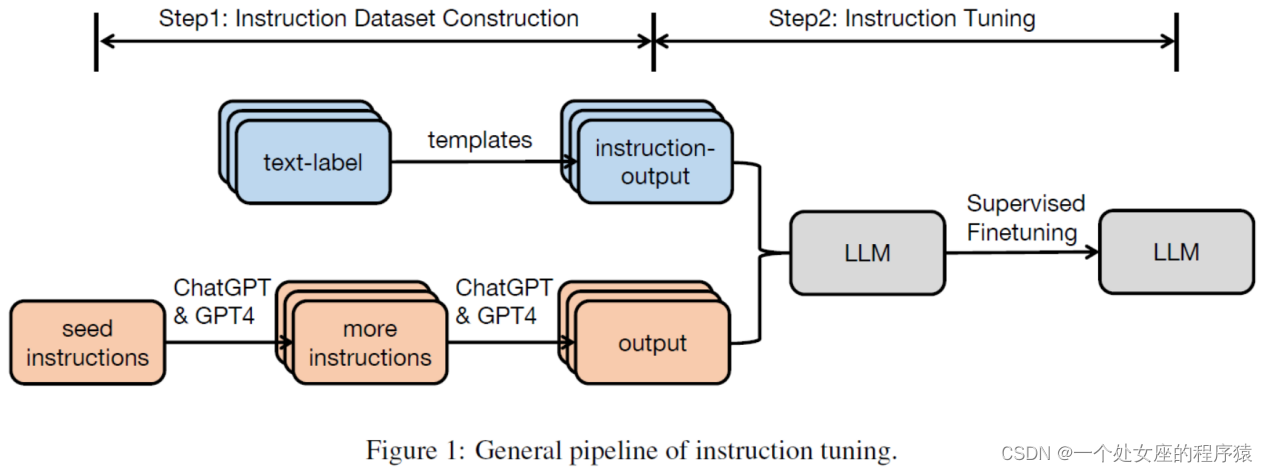
| In this section, we describe the general pipeline employed in instruction tuning. |
在本节中,我们描述了指令微调中采用的一般流程。 |
2.1、Instruction Dataset Construction指令数据集构建:
数据实例三元素:instruction【指定任务】、input【补充上下文】、output【预期输出】
| Each instance in an instruction dataset consists of three elements: an instruction, which is a natural language text sequence to specify the task (e.g., write a thank-you letter to XX for XX, write a blog on the topic of XX, etc); an optional input which provides supplementary information for context; and an anticipated output based on the instruction and the input. |
指令数据集中的每个实例包含三个元素: instruction:一个instruction,是一系列自然语言文本序列,用于指定任务(例如,为XX写一封感谢信,为XX写一篇关于XX主题的博客等); input :可选的input ,为上下文提供补充信息; output:以及基于指令和输入预期的output 。 |
两种方法构建:T1基于现有数据集成策略法(Flan/P3)、T2基于指令收集【手动/自动,如使用LLM的小型手写种子指令进行扩展】采用LLM【如GPT-3.5-Turbo/GPT4】自动生成法(InstructWild/Self-Instruct)
| There are generally two methods for constructing instruction datasets: >>Data integration from annotated natural language datasets. In this approach, (Instruction, Output) pairs are collected from existing annotated natural language datasets by using templates to transform text-label pairs to (Instruction, Output) pairs. Datasets such as Flan (Longpre et al., 2023) and P3 (Sanh et al., 2021) are constructed based on the data integration strategy. >>Generating outputs using LLMs: An alternate way to quickly gather the desired outputs to given instructions is to employ LLMs such as GPT-3.5-Turbo or GPT4 instead of manually collecting the outputs. Instructions can come from two sources: (1) manually collected; or (2) expanded based a small handwritten seed instructions using LLMs. Next, the collected instructions are fed to LLMs to obtain outputs. Datasets such as InstructWild (Xue et al., 2023) and Self-Instruct (Wang et al., 2022c) are geneated following this approach. |
通常有两种方法用于构建指令数据集: >> 基于现有数据集成策略法—从带注释的自然语言数据集中集成数据。在这种方法中,通过使用模板将文本-标签对转换为(Instruction, Output)对,从现有的带注释的自然语言数据集中收集(Instruction, Output)对。Flan(Longpre等,2023)和P3(Sanh等,2021)等数据集是基于数据集集成策略构建的。 >> 采用LLM自动生成法—使用LLM生成输出:一种快速获取给定指令所需输出的替代方法是使用LLM,例如GPT-3.5-Turbo或GPT4,而不是手动收集输出。指令可以来自两个来源:(1)手动收集;或(2)使用LLM扩展基于小型手写种子指令。接下来,收集到的指令被输入LLM以获得输出。InstructWild(Xue等,2023)和Self-Instruct(Wang等,2022c)等数据集是按照这种方法生成的。 |
多轮对话微调数据集:让LLM扮演两个对立角色来生成
| For multi-turn conversational IT datasets, we can have large language models self-play different roles (user and AI assistant) to generate messages in a conversational format (Xu et al., 2023b). |
对于多轮对话型的指令微调数据集,我们可以让大型语言模型扮演不同角色(用户和AI助手),以生成对话格式的消息(Xu等,2023b)。 |
2.2、Instruction Tuning指令微调:有监督的训练
| Based on the collected IT dataset, a pretrained model can be directly fune-tuned in a fully- supervised manner, where given the instruction and the input, the model is trained by predicting each token in the output sequentially. |
基于收集到的指令微调数据集,可以以完全监督的方式直接微调预训练模型,其中在给定指令和输入的情况下,模型通过逐个预测输出中的每个令牌来进行训练。 |
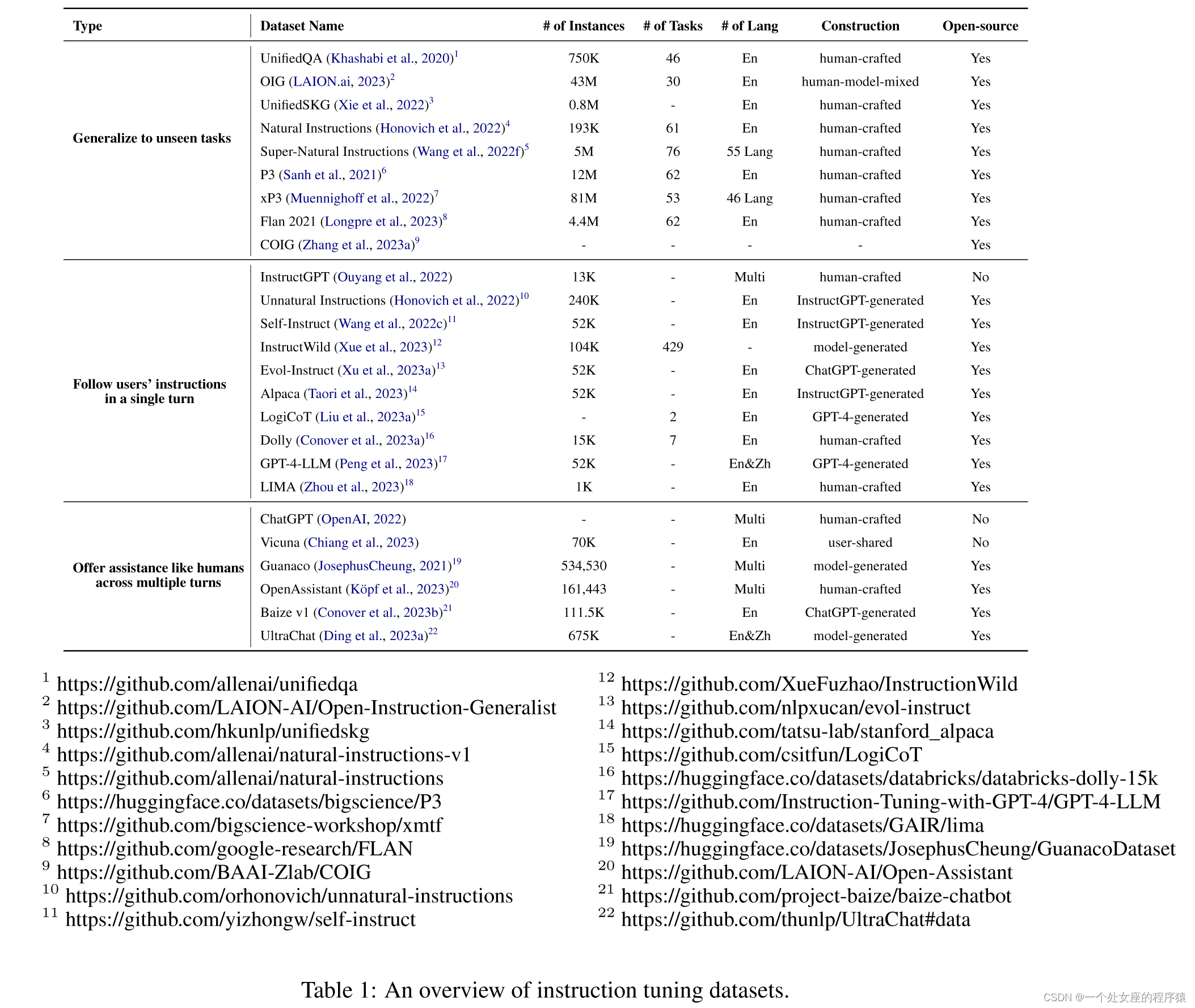
3、Datasets数据集:大多都是英文指令,Natural Instructions/Unnatural Instructions/Super-Natural Instructions、P3/xP3、Flan 2021、Self-Instruct、Evol-Instruct、LIMA、Dolly、OpenAssistant Conversations、Baize
| In this section, we detail widely-used instruction tuning datasets in the community. Table 1 gives an overview of the datasets. |
在本节中,我们详细介绍了社区中广泛使用的指令微调数据集。表格1提供了数据集的概述。 |
3.1、Natural Instructions自然指令:来自193K个实例和61个NLP任务,2元组{输入,输出}
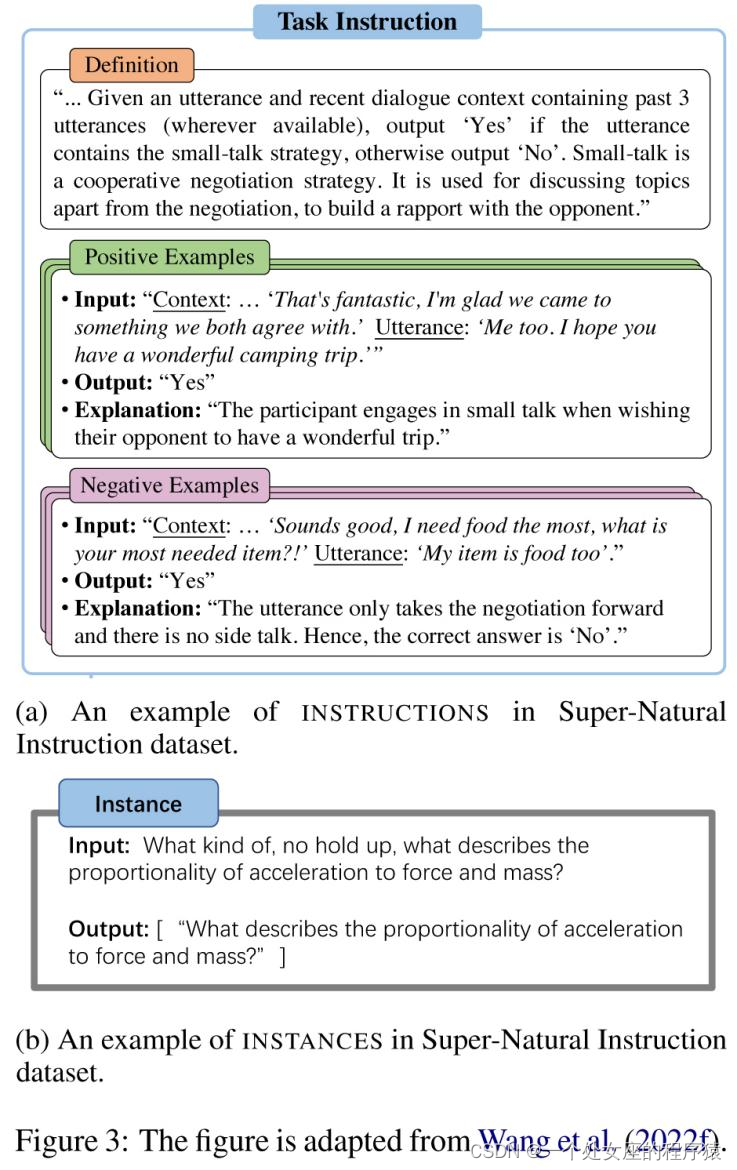
| Natural Instructions (Mishra et al., 2021) is a human-crafted English instruction dataset consisting of 193K instances, coming from 61 distinct NLP tasks. The dataset is comprised of "instructions" and "instances". Each instance in the "instructions" is a task description consisting of 7 components: title, definition, things to avoid emphasis/caution, prompt, positive example, and negative example. Subfigure (a) in Figure 2 gives an example of the "instructions". "Instances" consists of ("input", "output") pairs, which are the input data and textual result that follows the given instruction correctly. Subfigure (b) in Figure 2 gives an example of the instances. The data comes from existing NLP datasets of 61 tasks. The authors collected the "instructions" by referring to the dataset annotating instruction file. Next, the authors constructed the "instances" by unifying data instances across all NLP datasets to ("input", "output") pairs. |
Natural Instructions(Mishra等,2021)是一个人工创建的英语指令数据集,包含了193K个实例,来自61个不同的自然语言处理任务。数据集由“指令”和“实例”组成。 在“指令”中,每个实例是一个任务描述,包括7个组成部分:标题、定义、避免强调/注意事项、提示、正面示例和负面示例。 图2(a)中的子图示例展示了“指令”的一个示例。而“实例”由(“输入”,“输出”)对组成,即输入数据和按照给定指令正确生成的文本结果。图2(b)中的子图示例展示了“实例”的一个示例。 这些数据来自61个任务的现有自然语言处理数据集。作者通过参考数据集的指令注释文件来收集“指令”。接下来,作者通过将所有NLP数据集中的数据实例统一为(“输入”,“输出”)对来构建“实例”。 |

3.2、P3公共提示池:整合170个英语NLP数据集和2052个英语提示,三元组{“输入”【描述任务】+“答案选择”【响应列表】+“目标”【正确响应】}
| P3 (Public Pool of Prompts) (Sanh et al., 2021) is an instruction fine-tuning dataset constructed by integrating 170 English NLP datasets and 2,052 English prompts. Prompts, which are sometimes named task templates, are functions that map a data instance in a conventional NLP task (e.g., question answering, text classification) to a natural language input-output pair. Each instance in P3 has three components: "inputs", "answer_choices", and “targets". "Inputs" is a sequence of text that describes the task in natural language (e.g., "If he like Mary is true, is it also true that he like Mary’s cat?"). "Answer choices" is a list of text string that are applicable responses to the given task (e.g., ["yes", "no", "undetermined"]). "Targets" is a text string that is the correct response to the given "inputs" (e.g., "yes"). The authors built PromptSource, a tool for creating high-quality prompts collaboratively and an archive for open-sourcing high-quality prompts. the P3 dataset was built by randomly sampling a prompt from multiple prompts in the PromptSource and mapping each instance into a ("inputs", "answer choices", "targets") triplet. |
P3(Public Pool of Prompts)(Sanh等,2021)是一个指令微调数据集,通过整合170个英语自然语言处理数据集和2052个英语提示来构建。提示有时被称为任务模板,是一种将传统自然语言处理任务(例如,问题回答、文本分类)的数据实例映射到自然语言输入-输出对的功能。 P3中的每个实例有三个组成部分:“输入”,“答案选择”和“目标”。 “输入”是一系列以自然语言描述任务的文本序列(例如,“如果他喜欢玛丽是真的,那么他是否也喜欢玛丽的猫?”)。 “答案选择”是一个文本字符串列表,是给定任务的适用响应(例如,“是”,“否”,“不确定”)。 “目标”是文本字符串,是给定“输入”的正确响应(例如,“是”)。 作者构建了PromptSource,这是一个协作创建高质量提示的工具,也是一个开源高质量提示的存档。P3数据集是通过从PromptSource中随机抽样选择一个提示,将每个实例映射为一个(“输入”,“答案选择”,“目标”)三元组而构建的。 |
3.3、xP3跨语言公共提示池:46种语言中16类NLP任务,2元组{输入和目标}
| xP3 (Crosslingual Public Pool of Prompts) (Muennighoff et al., 2022) is a multilingual instruction dataset consisting of 16 diverse natural language tasks in 46 languages. Each instance in the dataset has two components: "inputs" and "targets". "Inputs" is a task description in natural language. "Targets" is the textual result that follows the "inputs" instruction correctly. The original data in xP3 comes from three sources: the English instruction dataset P3, 4 English unseen tasks in P3 (e.g., translation, program synthesis), and 30 multilingual NLP datasets. The authors built the xP3 dataset by sampling human-written task templates from PromptSource and then filling templates to transform diverse NLP tasks into a unified formalization. For example, a task template for the natural language inference task is as follows: “If Premise is true, is it also true that Hypothesis?”; "yes", "maybe", no" with respect to the original task labels "entailment (0)", "neutral (1)" and "contradiction (2)". |
xP3(Crosslingual Public Pool of Prompts)(Muennighoff等,2022)是一个多语言指令数据集,包含46种语言中16个不同的自然语言处理任务。 数据集中的每个实例有两个组成部分:“输入”和“目标”。 “输入”是自然语言中的任务描述。 “目标”是按照“输入”指令正确生成的文本结果。 xP3中的原始数据来自三个来源:英语指令数据集P3,P3中的4个英语未见过的任务(例如,翻译、程序合成)以及30个多语言自然语言处理数据集。作者通过从PromptSource中随机抽样选择人工编写的任务模板,然后填充模板,将不同的自然语言处理任务转换为统一的形式,从而构建了xP3数据集。 |
3.4、Flan 2021:将63个NLP基准转换为输入-输出对进而构建,2元组{输入+目标}
| Flan 2021 (Longpre et al., 2023) is an English instruction dataset constructed by transforming 62 widely-used NLP benchmarks (e.g., SST-2, SNLI, AG News, MultiRC) into language input- output pairs. Each instance in the Flan 2021 has "input" and "target" components. "Input" is a sequence of text that describes a task via a natural language instruction (e.g., "determine the sentiment of the sentence ’He likes the cat.’ is positive or negative?"). "Target" is a textual result that executes the "input" instruction correctly (e.g., "positive"). The authors transformed conventional NLP datasets into input-target pairs by: Step 1: manually composing instruction and target templates; Step 2: filling templates with data instances from the dataset. |
Flan 2021(Longpre等,2023)是一个英语指令数据集,通过将62个广泛使用的自然语言处理基准(例如,SST-2、SNLI、AG News、MultiRC)转换为语言输入-输出对来构建。Flan 2021中的每个实例包含“输入”和“目标”两个组成部分。“输入”是描述任务的自然语言指令序列(例如,“确定句子'他喜欢猫。'的情感是积极还是消极?”)。 “目标”是正确执行“输入”指令的文本结果(例如,“积极”)。作者通过以下步骤将传统的自然语言处理数据集转换为输入-目标对: 步骤1:手动组合指令和目标模板; 步骤2:使用数据集中的数据实例填充模板。 |
3.5、Unnatural Instructions非自然指令:基于InstructGPT构建的24万个实例,4元组{指令+输入+约束+输出}
| Unnatural Instructions (Honovich et al., 2022) is an instruction dataset with approximately 240,000 instances, constructed using InstructGPT (text- davinci-002) (Ouyang et al., 2022). Each instance in the dataset has four components: INSTRUCTION, INPUT, CONSTRAINTS, and OUTPUT. Instruction" is a description of the instructing task in natural language. "Input" is an argument in natural language that instantiates the instruction task. |
非自然指令(Honovich等,2022)是一个包含约24万个实例的指令数据集,使用InstructGPT(text-davinci-002)(Ouyang等,2022)构建而成。数据集中的每个实例有四个组成部分:指令、输入、约束和输出。 “指令”是自然语言中的指令任务描述。 “输入”是实例化指令任务的自然语言参数。 |
3.6、Self-Instruct
LLMs之Data:指令微调的简介、Self Instruction思想(一种生成指令数据集的方法论—主要用在指令微调阶段)的简介、Alpaca/BELLE应用、实战案例代码实现之详细攻略
包含基于InstructGPT的52K个训练指令和252个评估指令,3元组{ “指令”【定义任务】+“输入”【指令的内容补充】+“输出”【正确结果】}
| Self-Instruct (Wang et al., 2022c) is an English instruction dataset with 52K training instructions and 252 evaluation instructions, constructed using InstructGPT (Ouyang et al., 2022). Each data instance consists of "instruction", "input" and "output". "Instruction" is a task definition in natural language (e.g., "Please answer the following question."). "Input" is optional and is used as supplementary content for the instruction (e.g., "Which country’s capital is Beijing?"), and "output" is the textual result that follows the instruction correctly (e.g., "Beijing"). |
自我指导(Self-Instruct)(Wang等,2022c)是一个英语指令数据集,包含52K个训练指令和252个评估指令,使用InstructGPT(Ouyang等,2022)构建而成。每个数据实例包括“指令”、“输入”和“输出”三个部分。 “指令”是自然语言中的任务定义(例如,“请回答以下问题。”)。 “输入”是可选的,用作指令的补充内容(例如,“哪个国家的首都是北京?”),而“输出”是正确遵循指令生成的文本结果(例如,“北京”)。 |
生成四步骤:构建示例(175个种子任务来抽样8个自然语言指令)来提示InstructGPT生成更多指令→判断是否分类任务+基于给定的“指令”提示InstructGPT生成“输入”再结合生成“输出”→为相应的指令任务生成“输入”和“输出”→后处理(过滤和删除重复)→最终得到52K个英语指令
| The full dataset is generated based on the following steps: Step 1. The authors randomly sampled 8 natural language instructions from the 175 seed tasks as examples and prompted InstructGPT to generate more task instructions. Step 2. The authors determined whether the instructions generated in Step 1 is a classification task. If yes, they asked InstructGPT to generate all possible options for the output based on the given instruction and randomly selected a particular output category to prompt InstructGPT to generate the corresponding "input" content. For Instructions that do not belong to a classification task, there should be countless "output" options. The authors proposed to use the Input-first strategy, where InstructGPT was prompted to generate the "input" based on the given "instruction" first and then generate the "output" according to the "instruction" and the generated "input". Step 3. Based on results of step-2, the authors used InstructGPT to generate the "input" and "output" for corresponding instruction tasks using the output-first or input-first strategy. Step 4. The authors post-processed (e.g., filtering out similar instructions and removing duplicate data for input and output) the generated instruction tasks and got a final number of 52K English instructions. |
整个数据集是通过以下步骤生成的: 步骤1:作者随机从175个种子任务中抽样8个自然语言指令作为示例,并提示InstructGPT生成更多的任务指令。 步骤2:作者确定步骤1中生成的指令是否是分类任务。如果是,他们要求InstructGPT基于给定的指令生成所有可能的输出选项,并随机选择一个特定的输出类别,以促使InstructGPT生成相应的“输入”内容。对于不属于分类任务的指令,应该有无数个“输出”选项。作者提出了首先生成“输入”的策略,即首先基于给定的“指令”提示InstructGPT生成“输入”,然后根据“指令”和生成的“输入”生成“输出”。 步骤3:根据步骤2的结果,作者使用InstructGPT基于输出优先或输入优先策略为相应的指令任务生成“输入”和“输出”。 步骤4:作者对生成的指令任务进行后处理(例如,过滤相似指令,删除输入和输出的重复数据),得到最终的52K个英语指令。 |
3.7、Evol-Instruct:包含基于ChatGPT采用进化策略(添加约束、增加推理步骤、复杂化输入等)构建的52K个训练指令和218个评估指令,二元组{ instruction, response}
形成过程:基于52K的初始集→随机选择1个进化策略让ChatGPT重写指令→过滤未进化的指令对(利用ChatGPT和规则)→利用新生成进化指令对更新数据集→重复上述四次→收集了25万个指令对
| Evol-Instruct (Xu et al., 2023a) is an English instruction dataset consisting of a training set with 52K instructions and an evaluation set with 218 instructions. The authors prompted ChatGPT (OpenAI, 2022) to rewrite instructions using the in-depth and in-breath evolving strategies. The in-depth evolving strategy contains five types of operations, e.g., adding constraints, increasing reasoning steps, complicating input and etc. The in-breath evolving strategy upgrades the simple instruction to a more complex one or directly generates a new instruction to increase diversity. The authors first used 52K (instruction, response) pairs as the initial set. Then they randomly sampled an evolving strategy and asked ChatGPT to rewrite the initial instruction based on the chosen evolved strategy. The author employed ChatGPT and rules to filter out no-evolved instruction pairs and updated the dataset with newly generated evolved instruction pairs. After repeating the above process 4 times, the authors collected 250K instruction pairs. Besides the train set, the authors collected 218 human-generated instructions from real scenarios (e.g., open-source projects, platforms, and forums), called the Evol- Instruct test set. |
Evol-Instruct(Xu等,2023a)是一个英语指令数据集,包含一个包含52K个训练指令和218个评估指令的训练集。作者使用ChatGPT(OpenAI,2022)以深入和全面的进化策略重写指令来构建这个数据集。深入进化策略包含五种类型的操作,例如添加约束、增加推理步骤、复杂化输入等。全面进化策略将简单指令升级为更复杂的指令,或直接生成新的指令以增加多样性。 作者首先使用52K个 (instruction, response)对作为初始集。然后随机选择一个进化策略,要求ChatGPT根据选择的进化策略重写初始指令。作者使用ChatGPT和规则来过滤掉未进化的指令对,并使用新生成的进化指令对更新数据集。在重复上述过程4次之后,作者收集了25万个指令对。除了训练集之外,作者还从真实场景(例如,开源项目、平台和论坛)中收集了218个人工生成的指令,称为Evol-Instruct测试集。 |
3.8、LIMA:包含1K数据实例的训练集(75%源自3个社区问答网站)和300个实例的测试集,二元组{instruction, response}
| LIMA (Zhou et al., 2023) is an English instruction dataset consisting of a train set with 1K data instances and a test set with 300 instances. The train set contains 1K ("instruction", "response") pairs. For the training data, 75% are sampled from three community question & answers websites (i.e., Stack Exchange, wikiHow, and the Pushshift Reddit Dataset (Baumgartner et al., 2020)); 20% are manually written by a set of the authors (referred Group A) inspired by their interests; 5% are sampled from the Super-Natural Instructions dataset (Wang et al., 2022d). As for the valid set, the authors sampled 50 instances from the Group A author-written set. The test set contains 300 examples, with 76.7% written by another group (Group B) of authors and 23.3% sampled from the Pushshift Reddit Dataset (Baumgartner et al., 2020), which is a collection of questions & answers within the Reddit community. |
LIMA(Zhou等,2023)是一个英语指令数据集,包含一个包含1K个数据实例的训练集和一个包含300个实例的测试集。训练集包含1K个(instruction, response)对。对于训练数据,其中75%来自三个社区问答网站(即Stack Exchange、wikiHow和Pushshift Reddit数据集(Baumgartner等,2020));20%由一组作者(Group A)手动编写,受到他们兴趣的启发;5%来自Super-Natural Instructions数据集(Wang等,2022d)。至于验证集,作者从Group A作者编写的集合中抽样了50个实例。测试集包含300个示例,其中76.7%由另一组作者(Group B)编写,23.3%来自Pushshift Reddit数据集(Baumgartner等,2020),这是Reddit社区中的问题和回答的集合。 |
3.9、Super-Natural Instructions超级自然指令:包含1616个NLP任务和500万个任务实例+涵盖76种任务类型和55种语言,二元组(“指令”和“任务实例”)
| Super Natural Instructions (Wang et al., 2022f) is a multilingual instruction collection composed of 1,616 NLP tasks and 5M task instances, covering 76 distinct task types (e.g., text classification, information extraction, text rewriting, text composition and etc.) and 55 languages. Each task in the dataset consists of an "instruction" and "task instances". Specifically, "instruction" has three components: a "definition" that describes the task in natural language; "positive examples" that are samples of inputs and correct outputs, along with a short explanation for each; and "negative examples" that are samples of inputs and undesired outputs, along with a short explanation for each, as shown in Figure 2 (a). "Task instances" are data instances comprised of textual input and a list of acceptable textual outputs, as shown in Figure 2 (b). The original data in Super Natural Instructions comes from three sources: (1) existing public NLP datasets (e.g., CommonsenseQA); (2) applicable intermediate annotations that are generated through a crowdsourcing process (e.g., paraphrasing results to a given question during a crowdsourcing QA dataset); (3) synthetic tasks that are transformed from symbolic tasks and rephrased in a few sentences (e.g., algebraic operations like number comparison). |
超级自然指令(Super Natural Instructions)(Wang等,2022f)是一个多语言指令收集,包含1616个自然语言处理任务和500万个任务实例,涵盖76种不同的任务类型(例如,文本分类、信息提取、文本改写、文本组成等)和55种语言。数据集中的每个任务包括“指令”和“任务实例”两个部分。 具体来说,“指令”有三个组成部分:以自然语言描述任务的“定义”;“正面示例”,它是输入和正确输出的示例,每个示例都附有简短的解释;“负面示例”,它是输入和不希望的输出的示例,每个示例都附有简短的解释,如图2(a)所示。 “任务实例”是由文本输入和可接受的文本输出列表组成的数据实例,如图2(b)所示。 超级自然指令中的原始数据来自三个来源:(1)现有的公共自然语言处理数据集(例如,CommonsenseQA);(2)通过众包过程生成的适用中间注释(例如,在众包问答数据集中对给定问题进行释义);(3)从符号任务转换而来且经过重新表述的合成任务,这些任务在几句话中重新表述(例如,代数运算,如数字比较)。 |
3.10、Dolly:包含15000个人工生成英语指令+7种特定类型
| Dolly (Conover et al., 2023a) is an English instruction dataset with 15,000 human-generated data instances designed to enable LLMs to interact with users akin to ChatGPT. The dataset is designed for simulating a wide range of human behaviors, covering 7 specific types: open Q&A, closed Q&A, extracting information from Wikipedia, summarizing information from Wikipedia, brainstorming, classification, and creative writing. Examples of each task type in the dataset are shown in Table 2. |
Dolly(Conover等,2023a)是一个包含15000个人工生成的数据实例的英语指令数据集,旨在使大型语言模型能够与用户进行类似于ChatGPT的互动。该数据集旨在模拟各种人类行为,涵盖7种特定类型:开放式问答、封闭式问答、从维基百科中提取信息、从维基百科中总结信息、头脑风暴、分类和创意写作。数据集中每种任务类型的示例如表2所示。 |

3.11、OpenAssistant Conversations
包含158K条消息(90K个用户提示+68K个助手回复),35种语言中65K个对话树+450K个人工注释的质量评分,对话树(节点,路径/线程)
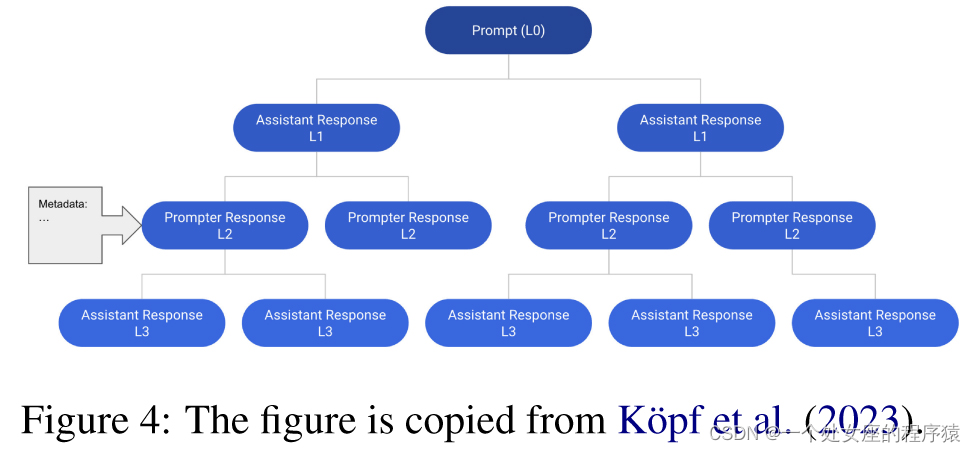
| OpenAssistant Conversations (Köpf et al., 2023) is a human-crafted multilingual assistant-style conversation corpus consisting of 161,443 messages (i.e., 91,829 user prompts, 69,614 assistant replies) from 66,497 conversation trees in 35 languages, along with 461,292 human-annotated quality ratings. Each instance in the dataset is a conversation tree (CT). Specifically, each node in a conversation tree denotes a message generated by roles (i.e., prompter, assistant) in the conversation. A CT’s root node represents an initial prompt from the prompter, while other nodes denote replies from a prompter or an assistant. A path from the root to any node in a CT represents a valid conversation between the prompter and assistant in turns and is referred to as a thread. Figure 4 shows an example of a conversation tree consisting of 12 messages in 6 threads. |
OpenAssistant Conversations(Köpf等,2023)是一个人工创建的多语言助手风格对话语料库,包含161443条消息(即91829个用户提示,69614个助手回复),来自35种语言中66497个对话树,同时还包含461292个人工注释的质量评分。 数据集中的每个实例是一个对话树(CT)。具体来说,对话树中的每个节点表示会话中角色(即提示者、助手)生成的消息。CT的根节点表示提示者的初始提示,而其他节点表示提示者或助手的回复。从根节点到CT中任何节点的路径表示提示者和助手之间的有效会话,称为线程。图4显示了一个由12条消息组成的对话树的示例,其中包含6个线程。 |
五步流程收集对话树:提示者→标记提示→扩展树节点→标记回复→排名
| The authors first collected conversation trees based on the five-step pipeline: Step 1. prompting: contributors performed as the prompter and crafted initial prompts; Step 2. labeling prompts: contributors rated scores to initial prompts from step 1, and the authors chose high-quality prompts as root nodes with a balanced sampling strategy; Step 3. expanding tree nodes: contributors added reply messages as prompter or assistant; Step 4. labeling replies: contributors assigned scores to existing node replies; Step 5. ranking: contributors ranked assistant replies referring to the contributor guidelines. The tree state machine managed and tracked the state (e.g., initial state, growing state, end state) throughout the conversation crafting process. Subsequently, the OpenAssistant Conversations dataset was built by filtering out offensive and inappropriate conversation trees. |
作者首先根据以下五步流程收集了对话树: 步骤1:提示者:贡献者扮演提示者的角色,创建初始提示; 步骤2:标记提示:贡献者对步骤1中的初始提示进行评分,作者使用平衡的抽样策略选择高质量的提示作为根节点; 步骤3:扩展树节点:贡献者添加提示者或助手的回复消息; 步骤4:标记回复:贡献者对现有节点的回复分配分数; 步骤5:排名:贡献者根据贡献者指南对助手的回复进行排名。 树状态机在整个对话创作过程中管理和跟踪状态(例如,初始状态、增长状态、结束状态)。随后,通过过滤掉冒犯性和不适当的对话树,构建了OpenAssistant Conversations数据集。 |
3.12、Baize:基于ChatGPT(self-chat思想)构建的111.5K个实例多轮(3.4轮)聊天语料库,二元组{ prompt,response}
| Baize (Conover et al., 2023b) is an English multi- turn chat corpus with 111.5K instances constructed using ChatGPT. And each turn consists of a user’s prompt and a response from the assistant. Each instance in Baize v1 contains 3.4 turns of conversations. To create the Baize dataset, the authors proposed self-chat, where ChatGPT plays roles of the user and the AI assistant in turns and generates messages in a conversational format. Specifically, the authors first crafted a task template that defines the roles and tasks for ChatGPT (as shown in Table 3). Next, they sampled questions (e.g., "How do you fix a Google Play Store account that isn’t working?") from Quora and Stack Overflow datasets as conversation seeds (e.g., topics). Subsequently, they prompted ChatGPT with the template and the sampled seed. ChatGPT continuously generates messages for both sides until a natural stopping point is reached. |
Baize(Conover等,2023b)是一个包含111.5K个实例的英语多轮聊天语料库,使用ChatGPT构建。每个轮次包括用户的提示和助手的回复。Baize v1中的每个实例包含3.4轮的对话。 为了创建Baize数据集,作者提出了自我对话的概念,其中ChatGPT在轮流扮演用户和AI助手的角色,以会话格式生成消息。具体来说,作者首先创建了一个任务模板,定义了ChatGPT的角色和任务(如表3所示)。接下来,他们从Quora和Stack Overflow数据集中抽样问题(例如,“如何修复不工作的Google Play Store账户?”)作为会话种子(例如,话题)。随后,他们使用模板和抽样的种子提示ChatGPT。ChatGPT持续地为双方生成消息,直到达到自然停止点为止。 |

4、Instruction Fine-tuned LLMs指导微调的LLM模型
| In this section, we detail widely-used LLM models in the community that are trained through instruction fine-tuning. |
在本节中,我们详细介绍社区中广泛使用的通过指导微调训练的LLM模型。 |
4.1、InstructGPT:基于GPT-3模型+人类指导微调
LLMs之InstructGPT:《Training language models to follow instructions with human feedback》翻译与解读
微调三步骤(基于人类筛选指令进行SFT→基于一个instruction多个降序的responses来训练RM模型→利用RL的PPO策略优化RM模型)
| InstructGPT (176B) (Ouyang et al., 2022) is initialized with GPT-3 (176B) (Brown et al., 2020b) and then fine-tuned on human instructions. The fine-tuning procedure is composed of the following three steps: (1) supervised fine-tuning (SFT) on the human-filtered instruction dataset, which is collected from Playground API history records; (2) training a reward model to predict human preferences based on an annotated dataset, which is constructed though human labors by sampling multiple responses for one instruction and rank them from the best to the worst; (3) further optimizing the model from Step 1 with new instructions and the trained reward model in step (2). Parameters are updated using the proximal policy optimization (PPO) (Schulman et al., 2017) method, a policy gradient reinforcement learning method. Steps (2) and (3) are alternated multiple times until the model performance does not significantly improve. |
InstructGPT(176B)(Ouyang等,2022)以GPT-3(176B)(Brown等,2020b)为初始模型,然后在人类指导下进行微调。 微调过程包括以下三个步骤: (1)在人类筛选的指令数据集上进行监督微调(SFT),该数据集从Playground API历史记录中收集; (2)训练奖励模型以预测人类偏好,基于通过人工劳动采样的带注释数据集,该数据集为一个指令采样多个响应,并将其从最佳到最差进行排序; (3)使用步骤(2)中训练的奖励模型从步骤1中的模型和新指令进一步优化。参数使用近端策略优化(PPO)(Schulman等,2017)方法进行更新,这是一种策略梯度强化学习方法。步骤(2)和(3)多次交替进行,直到模型性能不再显著提高为止。 |
InstructGPT的真实性、毒性、模型性能等表现非常出色
| Overall, InstructGPT outperforms GPT-3. For automatic evaluations, InstructGPT outperforms GPT-3 by 10% on the TruthfulQA (Lin et al., 2021) dataset in terms of truthfulness and by 7% on the RealToxicityPrompts (Gehman et al., 2020) in terms of toxicity. On NLP datasets (i.e., WSC), InstructGPT achieves comparable performance to GPT-3. For human evaluations, regarding four different aspects, including following correct instructions, following explicit constraints, fewer hallucinations, and generating appropriate responses, InstructGPT outperforms GPT-3 +10%, +20%, -20%, and +10%, respectively. |
总体而言,InstructGPT在真实性QA数据集(Lin等,2021)方面比GPT-3表现出色,真实性方面提高了10%,在RealToxicityPrompts数据集—即评估生成文本模型的毒性(Gehman等,2020)方面提高了7%。在自然语言处理数据集(例如WSC)上,InstructGPT的性能与GPT-3相当。在人类评估方面,涉及遵循正确指令、遵循明确约束、幻觉较少以及生成适当响应等四个不同方面,InstructGPT分别优于GPT-3 +10%、+20%、-20%和+10%。 |
4.2、BLOOMZ:基于BLOOM模型+指令数据集xP3,多种任务及其数据集上表现均超于BLOOM
LLMs:《BLOOM: A 176B-Parameter Open-Access Multilingual Language Model》翻译与解读
LLMs:《BLOOM: A 176B-Parameter Open-Access Multilingual Language Model》翻译与解读_一个处女座的程序猿的博客-程序员宅基地
| BLOOMZ (176B) (Muennighoff et al., 2022) is initialized with BLOOM (176B) (Scao et al., 2022), and then fine-tuned on the instruction dataset xP3 (Muennighoff et al., 2022), a collection of human-instruction datasets in 46 languages, coming from two sources: (1) P3, which is a collection of (English instruction, English response) pairs; and (2) an (English instruction, Multilingual response) set which is transformed from multilingual NLP datasets (e.g., Chinese benchmarks) by filling task templates with pre- defined English instructions. For automatic evaluation, BLOOMZ performs better than BLOOM in the zero-shot setting by +10.4%, 20.5%, and 9.8% on coreference resolution, sentence completion and natural language inference datasets, respectively. For the HumanEval benchmark (Chen et al., 2021), BLOOMZ outperforms BLOOM by 10% in terms of the Pass@100 metric. For generative tasks, BLOOMZ receives +9% BLEU improvement compared to BLOOM on the lm-evaluation-harness benchmark. |
BLOOMZ(176B)(Muennighoff等,2022)以BLOOM(176B)(Scao等,2022)为初始模型,然后在指令数据集xP3(Muennighoff等,2022)上进行微调。xP3是一个包含46种语言的人类指令数据集的集合,来自两个来源: (1)P3,其中包含(英文指令,英文响应)对; (2)一个(英文指令,多语言响应)集,通过在多语言自然语言处理数据集(例如中文基准)中使用预定义的英文指令填充任务模板而转化而来。 对于自动评估,BLOOMZ在zero-shot设置下在共指消解、句子补全和自然语言推理数据集上分别比BLOOM提高了10.4%、20.5%和9.8%。对于HumanEval基准(Chen等,2021),BLOOMZ在Pass@100度量上优于BLOOM 10%。对于生成任务,BLOOMZ在lm-evaluation-harness基准上比BLOOM的BLEU分数提高了9%。 |
"Pass@100" 是一种评估指标,用于衡量生成式模型在生成任务中的性能。通常,生成式模型会根据输入生成相应的文本输出。
T1、BLEU指标:在文本生成任务中,一种评估方式是将生成的文本与人工提供的参考文本进行比较,以测量生成文本的质量。"BLEU"(Bilingual Evaluation Understudy,双语评估候补)是一种常用的自动评估指标,用于衡量生成文本与参考文本之间的相似性。
T2、Pass@K指标:而在生成式任务中,尤其是类似问答任务中,还有一些其他的评估指标,如"Pass@K",其中 K 代表一个特定的数值,表示模型生成的回答是否在前 K 个候选中。例如,"Pass@100" 意味着模型生成的回答是否在前100个候选中。
4.3、Flan-T5:基于T5模型+FLAN数据集微调,基于JAX的T5X框架+128*TPU v4=37小时
| Flan-T5 (11B) is is a large language model initialized with T5 (11B) (Raffel et al., 2019), and then fine-tuned on the FLAN dataset (Longpre et al., 2023). The FLAN dataset is a collection of (instruction, pairs) pairs, constructed from 62 datasets of 12 NLP tasks (e.g., natural language inference, commonsense reasoning, paraphrase generation) by filling templates with various instructions under a unified task formalization. During fine-tuning, FLAN-T5 adapts the JAX- based T5X framework and selects the best model evaluated on the held-out tasks every 2k step. Compared with T5’s pre-training stage, fine-tuning costs 0.2% computational resources (approximately 128 TPU v4 chips for 37 hours). For evaluation, FLAN-T5 (11B) outperforms T5 (11B), and achieves comparable results to larger models, including PaLM (60B) (Chowdhery et al., 2022) in the few-shot setting. FLAN- T5 outperforms T5 by +18.9%, +12.3%, +4.1%, +5.8%, +2.1%, and +8% on MMLU (Hendrycks et al., 2020), BBH (Suzgun et al., 2022), TyDiQA (Clark et al., 2020), MGSM (Shi et al., 2022), open-ended generation, and RealToxicityPrompts (Gehman et al., 2020), respectively. In few-shot settings, FLAN-T5 outperforms PaLM +1.4% and +1.2% on the BBH and TyDiQA datasets. |
Flan-T5(11B)是一种大型语言模型,其初始化采用T5(11B)(Raffel等,2019)并在FLAN数据集(Longpre等,2023)上进行微调。FLAN数据集是一个包含(instruction, pairs)对的集合,通过在统一任务规范下使用各种指令填充模板,从12个自然语言处理任务的62个数据集构建而成(例如,自然语言推理、常识推理、释义生成)。 在微调过程中,FLAN-T5采用基于JAX的T5X框架,并在每2k步时选择在预留任务上评估的最佳模型。与T5的预训练阶段相比,微调过程消耗0.2%的计算资源(大约128个TPU v4芯片,耗时37小时)。 对于评估,FLAN-T5(11B)优于T5(11B),在少样本设置中实现了与更大模型(如PaLM(60B)(Chowdhery等,2022))相当的结果。FLAN-T5在MMLU(Hendrycks等,2020)、BBH(Suzgun等,2022)、TyDiQA(Clark等,2020)、MGSM(Shi等,2022)、开放式生成以及RealToxicityPrompts(Gehman等,2020)方面分别优于T5 +18.9%、+12.3%、+4.1%、+5.8%、+2.1%和+8%。在少样本设置中,FLAN-T5在BBH和TyDiQA数据集上分别优于PaLM +1.4%和+1.2%。 |
4.4、Alpaca:基于LLaMA模型+利用InstructGPT生成指令数据集进行微调,8*A100-80G设备+混合精度AMP+DP=3小时
LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读
LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读_一个处女座的程序猿的博客-程序员宅基地
| Alpaca (7B) (Taori et al., 2023) is a language model trained by fine-tuning LLaMA (7B) (Touvron et al., 2023a) on the constructed instruction dataset generated by InstructGPT (175B, text-davinci-003) (Ouyang et al., 2022). The fine-tuning process takes around 3 hours on an 8-card 80GB A100 device with mixed precision training and fully shared data parallelism. Alpaca (7B) achieves comparable performances to InstructGPT (175B,text-davinci-003) in terms of human evaluation. Specifically, Alpaca outperforms InstructGPT on the self-instruct dataset, garnering 90 instances of victories compared to 89 instances. |
Alpaca(7B)(Taori等,2023)是一种语言模型,通过对由InstructGPT(175B,text-davinci-003)(Ouyang等,2022)生成的构建指令数据集进行微调,使用LLaMA(7B)(Touvron等,2023a)完成微调。微调过程在8卡80GB A100设备上进行,使用混合精度训练和完全共享的数据并行技术,大约耗时3小时。 Alpaca(7B)在人类评估方面表现与InstructGPT(175B,text-davinci-003)相当。具体来说,Alpaca在自我指导数据集上优于InstructGPT,获得了90次胜利,而InstructGPT获得了89次。 |
4.5、Vicuna:基于LLaMA模型+利用ShareGPT的ChatGPT生成对话数据集(过滤低质得70K)进行微调,上下文扩到2K+GradientCheckpointing和FlashAttention(降低GPU成本)+8*A100-80G=24小时
LLMs之Vicuna:《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读
| Vicuna (13B) (Chiang et al., 2023) is a language model trained by fine-tuning LLaMA (13B) (Touvron et al., 2023a) on the conversational dataset generated by ChatGPT. The authors gathered user-shared ChatGPT conversations from ShareGPT.com, and got 70K conversation records after filtering out low-quality samples. LLaMA (13B) was fine-tuned on the constructed conversation dataset using a modified loss function tailored to multi-turn conversations. To better understand long context across multiple- turn dialog, the authors expanded the max context length from 512 to 2048. For training, the authors adopted the gradient checkpointing and flash attention (Dao et al., 2022) techniques to reduce the GPU memory cost in the fine-tuning process. The fine-tuning process takes 24 hours on an 8 × 80GB A100 device with fully shared data parallelism. The authors built a test set used exclusively to measure chatbots’ performances. They collected a test set composed by 8 question categories, such as Fermi problems, role play scenarios, coding/math tasks, etc, and then asked GPT-4 (OpenAI, 2023) to rate models’ responses considering helpfulness, relevance, accuracy, and detail. On the constructed test set, Vicuna (13B)outperforms Alpaca (13B) (Taori et al., 2023) and et al., 2022), open-ended generation, and LLaMA (13B) in 90% of the test questions, and generates equal or better rating responses compared to ChatGPT in 45% of the questions. |
Vicuna(13B)(Chiang等,2023)是一种语言模型,通过对由ChatGPT生成的对话数据集进行微调,使用LLaMA(13B)(Touvron等,2023a)完成微调。 作者从ShareGPT.com收集了用户分享的ChatGPT对话,并在滤除低质量样本后获得了70K个对话记录。使用经过修改的适用于多轮对话的损失函数对LLaMA(13B)进行了微调。 为了更好地理解多轮对话中的长上下文,作者将最大上下文长度从512扩展到2048。在训练过程中,作者采用了GradientCheckpointing和FlashAttention(Dao等,2022)技术,以减少微调过程中的GPU内存成本。微调过程在8个80GB A100设备上进行,使用完全共享的数据并行技术,耗时24小时。 作者构建了一个专门用于衡量聊天机器人表现的测试集。他们收集了一个由8个问题类别组成的测试集,例如费米问题、角色扮演情景、编码/数学任务等,然后要求GPT-4(OpenAI,2023)根据有用性、相关性、准确性和细节对模型的响应进行评分。在构建的测试集上,Vicuna(13B)在90%的测试问题中优于Alpaca(13B)、开放式生成以及LLaMA(13B),并在45%的问题中生成与ChatGPT相等或更好的评分响应。 |
4.6、GPT-4-LLM:基于LLaMA模型+利用Alpaca的指令和GPT-4生成指令数据集进行有监督微调→基于构建比较数据集(收集GPT-4、InstructGPT 等多个大模型的指令响应+GPT-4对响应评分1~10分)训练RM模型(PPO优化),8*A100-80G+AMP+DP=3小时
AIGC之GPT-4:GPT-4的简介(核心原理/意义/亮点/技术点/缺点/使用建议)、使用方法、案例应用(计算能力/代码能力/看图能力等)之详细攻略
AIGC之GPT-4:GPT-4的简介(核心原理/意义/亮点/技术点/缺点/使用建议)、使用方法、案例应用(计算能力/代码能力/看图能力等)之详细攻略_一个处女座的程序猿的博客-程序员宅基地
| GPT-4-LLM (7B) (Peng et al., 2023) is a language model trained by fine-tuning LLaMA (7B) (Touvron et al., 2023a) on the GPT-4 (OpenAI, 2023) generated instruction dataset. GPT-4-LLM is initialized with LLaMA, then fine-tuned in the following two steps: (1) supervised fine- tuning on the constructed instruction dataset. The authors used the instructions from Alpaca (Taori et al., 2023), and then collected responses using GPT-4. LLaMA is fine-tuned on the GPT-4 generated dataset. The fine-tuning process takes approximately three hours on an 8*80GB A100 machine with mixed precision and fully shared data parallelism. (2) optimizing the step-1 model using the proximal policy optimization (PPO) (Schulman et al., 2017) method, the authors first built a comparison dataset by collecting responses from GPT-4, InstructGPT (Ouyang et al., 2022), and OPT-IML (Iyer et al., 2022) to a collection of instructions and then asked GPT-4 to rate each response from 1 to 10. Using the ratings, a reward model is trained based on OPT (Zhang et al., 2022a). The fine-tuned model from Step 1 is optimized by using the reward model to compute the policy gradient. For evaluations, GPT-4-LLM (7B) outperforms not only the baseline model Alpaca (7B), but also larger models including Alpaca (13B) and LLAMA (13B). For automated evaluation, GPT- 4-LLM (7B) outperforms Alpaca by 0.2, 0.5, and 0.7 on User-Oriented-Instructions-252 (Wang et al., 2022c), Vicuna-Instructions (Chiang et al., 2023), and Unnatural Instructions (Honovich et al., 2022) datasets, respectively. For human evaluation, regarding aspects including helpfulness, honesty, and harmlessness, GPT-4-LLM outperforms Alpaca by 11.7, 20.9, and 28.6 respectively. |
GPT-4-LLM(7B)(Peng等,2023)是一种语言模型,通过对GPT-4(OpenAI,2023)生成的指令数据集进行微调,使用LLaMA(7B)(Touvron等,2023a)完成微调。 GPT-4-LLM首先使用LLaMA进行初始化,然后在以下两个步骤中进行微调: (1)在构建的指令数据集上进行监督微调。作者使用了Alpaca的指令,然后使用GPT-4生成了响应。LLaMA在由GPT-4生成的数据集上进行微调。微调过程在8个80GB A100设备上使用混合精度和完全共享的数据并行技术,大约耗时三小时。 (2)使用近端策略优化(PPO) (Schulman et al., 2017)方法优化step-1模型,作者首先通过收集GPT-4、InstructGPT (Ouyang et al., 2022)和OPT-IML (Iyer et al., 2022)对指令集合的响应构建比较数据集,然后要求GPT-4对每个响应进行1到10的评分。使用评级,基于OPT训练奖励模型(Zhang et al., 2022a)。通过使用奖励模型来计算策略梯度,对步骤1的微调模型进行优化。 在评估方面,GPT-4-LLM(7B)不仅优于基准模型Alpaca(7B),还优于更大的模型,包括Alpaca(13B)和LLAMA(13B)。在自动评估方面,GPT-4-LLM(7B)在用户导向的指令-252(Wang等,2022c)、Vicuna-指令(Chiang等,2023)和非自然指令(Honovich等,2022)数据集上分别优于Alpaca 0.2、0.5和0.7。在人类评估方面,关于可帮助性、诚实性和无害性等四个不同方面,GPT-4-LLM分别优于Alpaca 11.7、20.9和28.6。 |
4.7、Claude:基于数据集(52K指令和GPT-4生成的响应配对)进行SFT→基于构建比较数据集(收集GPT-3等多个大模型的指令响应+GPT-4对响应评分)训练RM模型(PPO优化),8*A100-80G+AMP+DP=8小时
| Claude is a language model trained by fine-tuning the pre-trained language model on an instruction dataset, aiming to generate helpful and harmless responses. The fine-tuning process consists of two stages: (1) supervised fine-tuning on the instruction dataset. The authors created an instruction dataset by collecting 52K different instructions, paired with responses generated by GPT-4. The fine- tuning process takes approximately eight hours on an 8-card 80GB A100 machine with mixed precision and fully shared data parallelism. (2) optimizing the step-1 model with the proximal policy optimization (Schulman et al., 2017) method. The authors first built a comparison dataset by collecting responses from multiple large language models (e.g., GPT-3 (Brown et al., 2020b)) to the given collection of instructions and then asking GPT-4 (OpenAI, 2023) to rate each response. Using the ratings, a reward model is trained. Then, the fine-tuned model from Step 1 is optimized using the reward model with the proximal policy optimization method. Claude generates more helpful and harmless responses compared to the backbone model. For automatic evaluations, Claude outperforms GPT- 3 by 7% on the RealToxicityPrompts (Gehman et al., 2020) in terms of toxicity. For human evaluations, regarding four different aspects, including following correct instructions, following explicit constraints, fewer hallucinations, and generating appropriate responses, Claude outperforms GPT-3 (Brown et al., 2020b) +10%,+20%, -20%, and +10%. respectively. |
Claude是一种语言模型,通过对预训练语言模型在指令数据集上进行微调,旨在生成有帮助且无害的响应。微调过程包括两个阶段: (1)在指令数据集上进行监督微调。作者通过收集了52K个不同的指令,并与GPT-4生成的响应配对,创建了一个指令数据集。微调过程在8卡80GB A100设备上使用混合精度和完全共享的数据并行技术,大约耗时八小时。 (2)使用近端策略优化(Schulman等,2017)方法优化步骤1中的模型。作者首先通过收集多个大型语言模型(如GPT-3(Brown等,2020b))对给定指令的响应,并要求GPT-4对每个响应进行评分,来构建比较数据集。使用这些评分,训练了一个奖励模型。然后,使用奖励模型使用近端策略优化方法优化步骤1中的微调模型。 与骨干模型相比,Claude生成的响应更有帮助且无害。在自动评估方面,Claude在RealToxicityPrompts(Gehman等,2020)方面优于GPT-3 7%。在人类评估方面,关于遵循正确指令、遵循明确约束、幻觉较少以及生成适当响应等四个不同方面,Claude分别优于GPT-3 +10%、+20%、-20%和+10%。 |
4.8、WizardLM:基于LLaMA模型+Evol-Instruct指令数据集(ChatGPT生成)微调,8*V100 GPU+Deepspeed Zero-3技术+3个epochs =70小时
| WizardLM (7B) (Xu et al., 2023a) is a language model trained by fine-tuning LLaMA (7B) (Touvron et al., 2023a) on the instruction dataset Evol-Instruct generated by ChatGPT (details see Section 3.7). It is fine-tuned on a subset (with 70K) of Evol-Instruct to enable a fair comparison with Vicuna (Chiang et al., 2023). The fine-tuning process takes approximately 70 hours on 3 epochs based on an 8 V100 GPU with the Deepspeed Zero-3 (Rasley et al., 2020) technique. During inference, the max generation length is 2048. To evaluate LLMs’ performances on complex instructions, the authors collected 218 human- generated instructions from real scenarios (e.g., open-source projects, platforms, and forums), called Evol-Instruct testset. Evaluations are conducted on the Evol-Instruct testset and Vicuna’s testset. For human evaluation, WizardLM outperforms Alpaca (7B) (Taori et al., 2023) and Vicuna (7B) by a large margins, and generates equal or better responses on 67% test samples compared to ChatGPT. Automatic evaluation is conducted by asking GPT-4 to rate LLMs’ reponses. Specifically, WizardLM gains performance boosts compared to Alpaca by +6.2%, +5.3% on the Evol-Instruct testset and Vicuna’s test sets. WizardLM achieves outperforms Vicuna by+5.8 on the Evol-Instruct testset and +1.7% on the Vicuna’s test set. |
WizardLM(7B)(Xu等,2023a)是一种语言模型,通过对由ChatGPT生成的Evol-Instruct指令数据集进行微调,使用LLaMA(7B)(Touvron等,2023a)完成微调(详见第3.7节)。它在Evol-Instruct的一个子集(含70K)上进行微调,以便与Vicuna(Chiang等,2023)进行公平比较。微调过程基于8个V100 GPU和Deepspeed Zero-3(Rasley等,2020)技术,在3个epochs 内耗时约70小时。推理过程中,最大生成长度为2048。 为了评估LLM在复杂指令上的性能,作者从实际情境(例如开源项目、平台和论坛)中收集了218个人工生成的指令,称为Evol-Instruct测试集。评估在Evol-Instruct测试集和Vicuna的测试集上进行。在人类评估中,WizardLM在绝大多数情况下都优于Alpaca(7B)(Taori等,2023)和Vicuna(7B),并且与ChatGPT相比,在67%的测试样本上生成相等或更好的响应。自动评估通过要求GPT-4对LLM的响应进行评分进行,其中更高的得分意味着更好的性能。具体来说,在Evol-Instruct测试集和Vicuna的测试集上,WizardLM在比较上优于Alpaca +6.2%、+5.3%。WizardLM在Evol-Instruct测试集上优于Vicuna +5.8%,在Vicuna的测试集上优于Vicuna +1.7%。 |
4.9、ChatGLM2:基于GLM模型+中英文指令(1:1)的双语数据集(1.4T的tokens),类似InstructGPT的三步微调策略+上下文长度扩展到32K+MQA/CM策略(降GPU成本)+需13GB的显存(INT4量化后需6GB)
LLMs之ChatGLM2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
LLMs之ChatGLM2:ChatGLM2-6B的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-程序员宅基地
| ChatGLM2 (6B) (Du et al., 2022) is a language model trained by fine-tuning GLM (6B) (Du et al., 2022) on a bilingual dataset that contains both English and Chinese instructions The bilingual instruction dataset contains 1.4T tokens, with a 1:1 ratio of Chinese to English. Instructions in the dataset are sampled from the question-answering and dialogue completion tasks. ChatGLM is initialized with GLM, then trained by the three-step fine-tuning strategy, which is akin to InstructGPT (Ouyang et al., 2022). To better model contextual information across multi-turn conversations, the authors expanded the maximum context length from 1024 to 32K. To reduce GPU memory cost in the fine-tuning stage, the authors employed multi-query attention and causal mask strategies. During inference, ChatGLM2 requires 13GB GPU memory with FP16 and supports conversations up to 8K in length with 6GB GPU memory using the INT4 model quantization technique. Evaluations are conducted on four English and Chinese benchmarks, including MMLU (English) (Hendrycks et al., 2020), C-Eval (Chinese) (Huang et al., 2023), GSM8K (Math) (Cobbe et al., 2021), and BBH (English) (Suzgun et al., 2022). ChatGLM2 (6B) outperforms GLM (6B) and the baseline model ChatGLM (6B) on all benchmarks. Specifically, ChatGLM2 outperforms GLM by+3.1 on MMLU, +5.0 on C-Eval, +8.6 on GSM8K,and +2.2 on BBH. ChatGLM2 achieves better performances than ChatGLM by +2.1, +1.2, +0.4,+0.8 on MMLU, C-Eval, GSM8K and BBH, respectively. |
ChatGLM2(6B)(Du等,2022)是一种语言模型,通过对包含英文和中文指令的双语数据集进行微调,使用GLM(6B)(Du等,2022)完成微调。双语指令数据集包含1.4T个标记,中英比例为1:1。数据集中的指令来自问答和对话完成任务。ChatGLM2初始化使用GLM,然后通过类似于InstructGPT(Ouyang等,2022)的三步微调策略进行训练。 为了更好地对多轮对话中的上下文信息进行建模,作者将最大上下文长度从1024扩展到32K。为了在微调阶段降低GPU内存成本,作者采用了多查询注意力MQA和因果掩码CM策略。在推理过程中,ChatGLM2需要13GB的GPU内存,使用FP16支持最大长度为8K的对话,使用INT4模型量化技术时只需要6GB的GPU内存。 评估在四个英文和中文基准数据集上进行,包括MMLU(英文)(Hendrycks等,2020)、C-Eval(中文)(Huang等,2023)、GSM8K(数学)(Cobbe等,2021)和BBH(英文)(Suzgun等,2022)。ChatGLM2(6B)在所有基准数据集上优于GLM(6B)和基准模型ChatGLM(6B)。具体来说,ChatGLM2在MMLU上优于GLM +3.1,在C-Eval上优于GLM +5.0,在GSM8K上优于GLM +8.6,在BBH上优于GLM +2.2。ChatGLM2在MMLU、C-Eval、GSM8K和BBH上的性能也优于ChatGLM +2.1、+1.2、+0.4、+0.8。 |
4.10、LIMA:基于LLaMA模型+基于表面对齐假设构建的指令数据集,提出了表面对齐假设并验证了其效果
| LIMA (65B) (Zhou et al., 2023) is a large language model trained by fine-tuning LLaMA (65B) (Touvron et al., 2023a) on an instruction dataset, which is constructed based on the proposed superficial alignment hypothesis. The superficial alignment hypothesis refers to the idea that the knowledge and capabilities of a model are almost acquired in the pre-training stage, while the alignment training (e.g., instruction fine-tuning) teaches models to generate responses under user-preferred formalizations. Based on the superficial alignment hypothesis, the authors claimed that large language models can generate user-satisfied responses by fine-tuning it on a small fraction of instruction data. Therefore, the authors built instruction train/valid/test sets to verify this hypothesis. Evaluations are conducted on the constructed test set. For human evaluations, LIMA outperforms InstructGPT and Alpaca by 17% and 19%, respectively. Additionally, LIMA achieves comparable results to BARD, Cladue, and GPT-4. For automatic evaluation, which is conducted by asking GPT-4 to rate responses and a higher rate score denotes better performance, LIMA outperforms InstructGPT and Alpaca by 20% and 36%, respectively, achieving comparable results to BARD, while underperforming Claude and GPT-4. Experimental results verify the proposed superficial alignment hypothesis. |
LIMA(65B)(Zhou等,2023)是一种大型语言模型,通过对基于所提出的表面对齐假设构建的指令数据集进行微调,使用LLaMA(65B)(Touvron等,2023a)完成微调。表面对齐假设指的是模型的知识和能力几乎在预训练阶段获得,而对齐训练(例如指令微调)则教导模型在用户首选的形式化下生成响应。基于这一表面对齐假设,作者声称可以通过在少量指令数据上进行微调来生成满足用户的响应。因此,作者构建了指令训练/验证/测试集来验证这一假设。 评估在构建的测试集上进行。在人类评估中,LIMA在有关方面优于InstructGPT和Alpaca分别达到17%和19%。此外,LIMA在自动评估方面,通过要求GPT-4对响应进行评分,得分越高表示性能越好,分别优于InstructGPT和Alpaca达到20%和36%,与BARD的性能相当,但不如Claude和GPT-4。实验结果验证了提出的表面对齐假设。 |
4.11、Others
OPT-IML:基于OPT模型+微调IML数据集
LLMs:《OPT: Open Pre-trained Transformer Language Models》翻译与解读
LLMs:《OPT: Open Pre-trained Transformer Language Models》翻译与解读_csv数据集下载_一个处女座的程序猿的博客-程序员宅基地
Dolly 2:基于Pythia模型+微调databricks-dolly-15k指令数据集
| OPT-IML (175B) (Iyer et al., 2022) is a large language model trained by fine-tuning the OPT (175B) (Zhang et al., 2022a) model on the constructed Instruction Meta-Learning (IML) dataset, which consists of over 1500 NLP tasks from 8 publicly available benchmarks such as PromptSource (Bach et al., 2022), FLAN (Longpre et al., 2023), and Super-NaturalInstructions (Wang et al., 2022d). After fine-tuning, OPT-IML outperforms OPT across all benchmarks. Dolly 2.0 (12B) (Conover et al., 2023a) is initialized with the pre-trained language model Pythia (12B) (Biderman et al., 2023), and fine- tuned on the instruction dataset databricks-dolly- 15k, which contains 7 categories of NLP tasks such as text classification and information extraction. After fine-tuning, Dolly 2.0 (12B) outperforms Pythia (12B) on the EleutherAI LLM Evaluation Harness benchmark (Gao et al., 2021) by a large margin, and achieves comparable performances to GPT-NEOX (20B) (Black et al., 2022), which has dolly-15k two times more parameters compared to Dolly 2.0 (12B). |
OPT-IML(175B)(Iyer等,2022)是一种大型语言模型,通过对构建的Instruction Meta-Learning(IML)数据集上的OPT(175B)(Zhang等,2022a)模型进行微调,该数据集包含来自8个公开可用基准数据集的1500多个NLP任务,如PromptSource(Bach等,2022)、FLAN(Longpre等,2023)和Super-NaturalInstructions(Wang等,2022d)。微调后,OPT-IML在所有基准数据集上优于OPT。 Dolly 2.0(12B)(Conover等,2023a)通过在databricks-dolly-15k指令数据集上进行微调,使用Pythia(12B)(Biderman等,2023)进行初始化,该数据集包含文本分类和信息提取等7类NLP任务。微调后,Dolly 2.0(12B)在EleutherAI LLM 评估套件基准(Gao等,2021)上远远优于Pythia(12B),并在性能上与拥有两倍参数的GPT-NEOX(20B)(Black等,2022)达到相当的性能。 |
Falcon-Instruct:基于Falcon模型+微调英语对话数据集(Baize数据集150M/1.5亿tokens+RefinedWeb数据集),降内存(Flash Attention+MQ)
LLMs之Data:《The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only》翻译与解读
https://yunyaniu.blog.csdn.net/article/details/131137560
Guanaco:基于LLaMA+微调多语言对话数据集(源自包含52K英文指令数据对的Alpaca+534K的多轮对话的多语言)
LLMs之Guanaco:《QLoRA:Efficient Finetuning of Quantized LLMs》翻译与解读
LLMs之Guanaco:《QLoRA:Efficient Finetuning of Quantized LLMs》翻译与解读_一个处女座的程序猿的博客-程序员宅基地
| Falcon-Instruct (40B) (Almazrouei et al., 2023a) is a large language model trained by fine- tuning Falcon (40B) (Almazrouei et al., 2023b) on an English dialogue dataset, which contains 150 million tokens from the Baize dataset (Xu et al., 2023c), with an additional 5% of the data from the RefinedWeb dataset (Penedo et al., 2023). To reduce memory usage, the authors employed flash attention (Dao et al., 2022) and multi-query techniques. For evaluation, Falcon- Instruct (40B) achieved better performance on the Open LLM Leaderboard (Beeching et al., 2023) compared to the baseline model Falcon (40B), and outperforms the Guanaco (65B), which has more model parameters. Guanaco (7B) (JosephusCheung, 2021) is a multi-turn dialog language model trained by fine- tuning LLaMA (7B) (Touvron et al., 2023a) on the constructed multilingual dialogue dataset. The multilingual dialogue dataset comes from two sources: Alpaca (Taori et al., 2023), which contains 52K English instruction data pairs; and a multilingual (e.g., Simplified Chinese, Traditional Chinese, Japanese, German) dialogue data, which contains 534K+ multi-turn conversations. After fine-tuning, Guanaco is to generate role-specific responses and continuous responses on a given topic in multi-turn conversations. |
Falcon-Instruct (40B) (Almazrouei等人,2023a)是一个大型语言模型,它是通过对Falcon (40B) (Almazrouei等人,2023b)在英语对话数据集上进行微调训练而成的,该数据集包含来自Baize数据集(Xu等人,2023c)的1.5亿个令牌,以及来自RefinedWeb数据集(Penedo等人,2023)的额外5%的数据。为了减少内存使用,作者采用了Flash Attention (Dao et al., 2022)和多查询技术。在评估中,Falcon- Instruct (40B)在Open LLM排行榜(Beeching et al., 2023)上的表现优于基线模型Falcon (40B),优于模型参数更多的Guanaco (65B)。 Guanaco(7B)(JosephusCheung,2021)是一种多轮对话语言模型,通过在构建的多语言对话数据集上进行微调,使用LLaMA(7B)(Touvron等,2023a)进行初始化。多语言对话数据集来自两个来源:包含52K英文指令数据对的Alpaca(Taori等,2023);以及包含534K+多轮对话的多语言(例如简体中文、繁体中文、日语、德语)对话数据。微调后,Guanaco用于在多轮对话中生成针对角色的响应和给定主题的连续响应。 |
Minotaur:基于Starcoder Plus模型+微调WizardLM和GPTeacher-General-Instruc指令数据集
Nous-Herme:基于LLaMA模型+微调BiologyPhysicsChemistry子集的300K个指令
| Minotaur (15B) is a large language model trained by fine-tuning the Starcoder Plus (15B) (Li et al., 2023f) on open-source instruction datasets including WizardLM (Xu et al., 2023a) and GPTeacher-General-Instruct. For model inference, Minotaur supports a maximum context length of 18K tokens. Nous-Herme (13B) is a large language model trained by fine-tuning LLaMA (13B) (Touvron et al., 2023a) on an instruction dataset, which contains over 300k instructions, sampled from GPTeacher, CodeAlpaca (Chaudhary, 2023), GPT-4-LLM (Peng et al., 2023), Unnatural Instructions (Honovich et al., 2022), and BiologyPhysicsChemistry subsets in the Camel- AI (Li et al., 2023c). Responses are generated by GPT-4. For evaluations, Nous-Herme (13B) achieves comparable performances to GPT-3.5- turbo on multiple tasks like ARC challenge (Clark et al., 2018) and BoolQ (Clark et al., 2019). |
Minotaur(15B)是一种大型语言模型,通过在包括WizardLM(Xu等,2023a)和GPTeacher-General-Instruct在内的开源指令数据集上,微调Starcoder Plus(15B)(Li等,2023f)。在模型推理阶段,Minotaur支持最大上下文长度为18K标记。 Nous-Herme(13B)是一种大型语言模型,通过在基于GPTeacher、CodeAlpaca(Chaudhary,2023)、GPT-4-LLM(Peng等,2023)、Unnatural Instructions(Honovich等,2022)以及Camel-AI(Li等,2023c)中的BiologyPhysicsChemistry子集中,包含超过300K个指令的指令数据集上进行微调,使用LLaMA(13B)(Touvron等,2023a)进行初始化。评估结果显示,Nous-Herme(13B)在多个任务(如ARC挑战和BoolQ)上与GPT-3.5-turbo的性能相当。 |
TÜLU :基于OPT 模型+微调混合指令数据集
YuLan-Chat:基于LLaMA模型+微调双语数据集(25万个中英文指令对)
| TÜLU (6.7B) (Wang et al., 2023c) is a large language model trained by fine-tuning OPT (6.7B) (Zhang et al., 2022a) on a mixed instruction dataset, which contains FLAN V2 (Longpre et al., 2023), CoT (Wei et al., 2022), Dolly (Conover et al., 2023a), Open Assistant-1, GPT4-Alpaca, Code-Alpaca (Chaudhary, 2023), and ShareGPT. After fine-tuning, TÜLU (6.7B) reaches on average 83% of ChatGPT’s performance and 68% of GPT- 4’s performance. YuLan-Chat (13B) (YuLan-Chat-Team, 2023) is a language model trained by fine-tuning LLaMA (13B) (Touvron et al., 2023a) on a constructed bilingual dataset, which contains 250,000 Chinese- English instruction pairs. After fine-tuning, YuLan-Chat-13B achieves comparable results to the state-of-the-art open-source model ChatGLM (6B) (Du et al., 2022), and outperforms Vicuna (13B) (Chiang et al., 2023) on the English BBH3K (BBH3K is a subset of BBH benchmark (Srivastava et al., 2022)) dataset. |
TÜLU (6.7B) (Wang等人,2023c)是在混合指令数据集上通过对OPT (6.7B) (Zhang等人,2022a)进行微调而训练的大型语言模型,该数据集包含FLAN V2 (Longpre等人,2023)、CoT (Wei等人,2022)、Dolly (Conover等人,2023a)、Open Assistant-1、GPT4-Alpaca、Code-Alpaca (Chaudhary, 2023)和ShareGPT。经过微调,TÜLU (6.7B)平均达到ChatGPT的83%和GPT- 4的68%的性能。 YuLan-Chat (13B) (YuLan-Chat- team, 2023)是通过微调LLaMA (13B) (Touvron et al., 2023a)在包含25万个中英文指令对的构建双语数据集上训练的语言模型。经过微调,YuLan-Chat-13B在英语BBH3K (BBH3K是BBH基准(Srivastava et al., 2022)的一个子集)数据集上取得了与最先进的开源模型ChatGLM (6B) (Du等人,2022)相当的结果,并且优于Vicuna (13B) (Chiang等人,2023)。 |
MOSS:微调对话指令的双语对话语言模型
Airoboros:基于LLaMA+微调Self-instruct数据集
UltraLM:基于LLAMA+微调,
| MOSS (16B) is a bilingual dialogue language model, which aims to engage in multi-turn conversations and utilize various plugins, trained by fine-tuning on dialogue instructions. After fine- tuning, MOSS outperforms the backbone model and generates responses that better align with human preferences. Airoboros (13B) is a large language model trained by fine-tuning LLAMA (13B) (Touvron et al., 2023a) on the Self-instruct dataset (Wang et al., 2022c). After fine-tuning, Airoboros significantly outperforms LLAMA (13B) (Touvron et al., 2023a) on all benchmarks and achieves highly comparable results to models fine-tuned specifically for certain benchmarks. UltraLM (13B) (Ding et al., 2023a) is a large language model trained by fine-tuning LLAMA (13B) (Touvron et al., 2023a). For evaluation, UltraLM (13B) outperforms Dolly (12B) (Conover et al., 2023a) and achieves the winning rate up to 98%. Additionally, it surpasses the previous best open-source models (i.e., Vicuna (Chiang et al., 2023) and WizardLM (Xu et al., 2023a)) with winning rates of 9% and 28%, respectively. |
MOSS(16B)是一种双语对话语言模型,旨在进行多轮对话并利用各种插件,在对话指令上进行微调。微调后,MOSS优于基准模型,并生成与人类偏好更加一致的响应。 Airoboros(13B)通过在Self-instruct数据集上进行微调,使用LLaMA(13B)(Touvron等,2023a)进行初始化。微调后,Airoboros在所有基准数据集上明显优于LLAMA(13B),并且与专门针对某些基准测试进行微调的模型取得了高度可比性的结果。 UltraLM(13B)(Ding等,2023a)通过对LLAMA(13B)(Touvron等,2023a)进行微调获得,微调后在性能上优于Dolly(12B)(Conover等,2023a)并达到98%的胜率。此外,它在性能上超越了之前的最佳开源模型(即Vicuna和WizardLM),其胜率分别为9%和28%。 |
5、Multi-modality Instruction Fine-tuning多模态指令微调
5.1、Multi-modality Datasets多模态数据集
MUL-TIINSTRUCT—多模态指令微调数据集—OFA模型:由62个不同的多模态任务组成+统一的序列到序列格式
| MUL-TIINSTRUCT (Xu et al., 2022) is a multimodal instruction tuning dataset consisting of 62 diverse multimodal tasks in a unified seq- to-seq format. This dataset covers 10 broad categories and its tasks are derived from 21 existing open-sourced datasets. Each task is equipped with 5 expert-written instructions. For the existing tasks, the authors use the input/output pairs from their available open-source datasets to create instances. While for each new task, the authors create 5k to 5M instances by extracting the necessary information from instances of existing tasks or reformulating them. The MUL-TIINSTRUCT dataset has demonstrated its efficiency in enhancing various transfer learning technique. For example, fine-tuning the OFA model (930M) (Wang et al., 2022a) using various transfer learning strategies such as Mixed Instruction Tuning and Sequential Instruction Tuning on MUL-TIINSTRUCT improve the zero- shot performance across all unseen tasks. On commonsense VQA task, OFA fine-tuned on MUL- TIINSTRUCT achieves 50.60 on RougeL and 31.17 on accuracy, while original OFA achieves 14.97 on RougeL and 0.40 on accuracy. |
MUL-TIINSTRUCT(Xu等,2022)是一个多模态指令微调数据集,由62个不同的多模态任务组成,以统一的序列到序列格式呈现。该数据集涵盖10个广泛的类别,其任务来自21个现有的开源数据集。每个任务配备了5个专家编写的指令。 >> 对于现有任务,作者使用其可用的开源数据集中的输入/输出对创建实例。 >> 而对于每个新任务,作者通过从现有任务的实例中提取必要信息或重新构建它们来创建5k到5M个实例。 MUL-TIINSTRUCT数据集已经证明在增强各种迁移学习技术方面的有效性。例如,使用Mixed Instruction Tuning和Sequential Instruction Tuning等各种迁移学习策略对OFA模型(930M)(Wang等,2022a)在MUL-TIINSTRUCT上进行微调,改进了所有未见任务的零-shot性能。在常识视觉问答任务上,经过MUL-TIINSTRUCT微调的OFA在RougeL上达到50.60,在准确性上达到31.17,而原始OFA在RougeL上只有14.97,在准确性上只有0.40。 |
PMC-VQA—大规模的医学视觉问答数据集—MedVInT模型:227k个图像-问题对和149k个图像,从PMC-OA收集图像-标题对+ChatGPT生成问题-答案对+手工验证
| PMC-VQA (Zhang et al., 2023c) is a large- scale medical visual question-answering dataset that comprises 227k image-question pairs of 149k images, covering various modalities or diseases. The dataset can be used for both open-ended and multiple-choice tasks. The pipeline for generating the PMC-VQA dataset involves collecting image-caption pairs from the PMC-OA (Lin et al., 2023) dataset, using ChatGPT to generate question-answer pairs, and manually verifying a subset of the dataset for quality. The authors propose a generative-based model MedVInT for medical visual understanding by aligning visual information with a large language model. MedVInT pretrained on PMC- VQA achieves state-of-the-art performance and outperforms existing models on VQA-RAD (Lau et al., 2018) and SLAKE (Liu et al., 2021a) benchmarks, with 81.6% accuracy on VQA-RAD and 88.0% accuracy on SLAKE. |
PMC-VQA(Zhang等,2023c)是一个大规模的医学视觉问答数据集,包括227k个图像-问题对和149k个图像,涵盖了各种模态或疾病。该数据集可用于开放式和多项选择任务。生成PMC-VQA数据集的流程涉及从PMC-OA(Lin等,2023)数据集中收集图像-标题对,使用ChatGPT生成问题-答案对,并对数据集的子集进行手工验证以确保质量。作者提出了一种基于生成的模型MedVInT,通过将视觉信息与大型语言模型进行对齐,实现医学视觉理解。在经过PMC-VQA微调的MedVInT上实现了最新的性能,并在VQA-RAD(Lau等,2018)和SLAKE(Liu等,2021a)基准上优于现有模型,VQA-RAD上的准确率为81.6%,SLAKE上的准确率为88.0%。 |
LAMM—2D图像和3D点云理解:包含186K个语言-图像指令-响应对,以及10K个语言-点云指令-响应对
| LAMM (Yin et al., 2023) is a comprehensive multi-modal instruction tuning dataset for 2D image and 3D point cloud understanding. LAMM contains 186K language-image instruction- response pairs, and 10K language-point cloud instruction-response pairs. The authors collect images and point clouds from publicly available datasets and use the GPT-API and self-instruction methods to generate instructions and responses based on the original labels from these datasets. LAMM-Dataset includes data pairs for commonsense knowledge question answering by incorporating a hierarchical knowledge graph label system from the Bamboo (Zhang et al., 2022b) dataset and the corresponding Wikipedia description. The authors also propose the LAMM- Benchmark, which evaluates existing multi-modal language models (MLLM) on various computer vision tasks. It includes 9 common image tasks and 3 common point cloud tasks, and LAMM- Framework, a primary MLLM training framework that differentiates the encoder, projector, and LLM finetuning blocks for different modalities to avoid modality conflicts. |
LAMM(Yin等,2023)是一个全面的多模态指令微调数据集,用于2D图像和3D点云理解。LAMM包含186K个语言-图像指令-响应对,以及10K个语言-点云指令-响应对。作者从公开可用的数据集中收集图像和点云,并使用GPT-API和自我指导方法根据这些数据集的原始标签生成指令和响应。LAMM-Dataset还包括了常识知识问答的数据对,通过将分层知识图标签系统从Bamboo(Zhang等,2022b)数据集和相应的维基百科描述整合进来。作者还提出了LAMM-Benchmark,用于评估现有的多模态语言模型(MLLM)在各种计算机视觉任务上的性能。其中包括9个常见的图像任务和3个常见的点云任务,以及LAMM-Framework,一个主要的MLLM训练框架,用于为不同的模态区分编码器、投影器和LLM微调模块,以避免模态冲突。 |
5.2、Multi-modality Instruction Fine-tuning Models多模态指令微调模型
InstructPix2Pix条件扩散模型:基于Stable Diffusion+微调多模态数据集(综合两大模型能力【GPT-3、Stable Diffusion】来生成)
| InstructPix2Pix (983M) (Brooks et al., 2022) is a conditional diffusion model trained by fine-tuning Stable Diffusion (983M) (Rombach et al., 2022) on a constructed multi-modal dataset that contains more than 450K text editing instructions and corresponding images before and after the edit. The authors combine the abilities of two large-scale pre- trained models, a language model GPT-3 (Brown et al., 2020b) and a text-to-image model Stable Diffusion (Rombach et al., 2022), to generate the the training dataset. GPT-3 is fine-tuned to generate text edits based on image prompts, while Stable Diffusion is used to convert the generated text edits into actual image edits. InstructPix2Pix is then trained on this generated dataset using a latent diffusion objective. Figure 5 shows the process of generating image editing dataset and training the diffusion model on that dataset. The authors compares the proposed method qualitatively with previous works such as SDEdit (Meng et al., 2022) and Text2Live (Bar-Tal et al., 2022), highlighting the ability of the model to follow image editing instructions instead of descriptions of the image or edit layer. The authors also presents quantitative comparisons with SDEdit (Meng et al., 2022) using metrics measuring image consistency and edit quality. |
InstructPix2Pix(983M)(Brooks等,2022)是一种条件扩散模型,通过在构建的多模态数据集上对Stable Diffusion(983M)(Rombach等,2022)进行微调而训练得到,该数据集包含超过450K个文本编辑指令和相应的编辑前后图像。作者将两个大规模预训练模型的能力结合在一起,即语言模型GPT-3(Brown等,2020b)和文本到图像模型Stable Diffusion(Rombach等,2022),以生成训练数据集。GPT-3被微调以根据图像提示生成文本编辑,而Stable Diffusion则用于将生成的文本编辑转换为实际图像编辑。然后,InstructPix2Pix在此生成的数据集上使用潜在扩散目标进行训练。图5展示了生成图像编辑数据集的过程以及在该数据集上训练扩散模型的过程。 作者将所提出的方法与之前的作品(如SDEdit和Text2Live)进行了定性比较,强调该模型能够按照图像编辑指令进行操作,而不是图像或编辑层的描述。作者还使用衡量图像一致性和编辑质量的指标对其与SDEdit进行了定量比较。 |
LLaVA:基于CLIP视觉编码器和LLaMA语言解码器模型+微调158K个独特的语言-图像指令-跟随样本的教学视觉语言数据集(利用GPT-4转换格式)
| LLaVA (13B) (Liu et al., 2023b) is a large multimodal model developed by connecting the visual encoder of CLIP (400M) (Radford et al., 2021) with the language decoder LLaMA (7B) (Touvron et al., 2023a). LLaVA is fine-tuned using the generated instructional vision-language dataset consisted of 158K unique language-image instruction-following samples. The data collection process involved creating conversation, detailed description, and complex reasoning prompts. GPT-4 is used to convert image-text pairs into appropriate instruction-following format for this dataset. Visual features such as captions and bounding boxes were used to encode images. LLaVA yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. |
LLaVA(13B)(Liu等,2023b)是一个大型多模态模型,通过将CLIP(400M)(Radford等,2021)的视觉编码器与LLaMA(7B)(Touvron等,2023a)的语言解码器相连接而开发。LLaVA通过生成包含158K个独特的语言-图像指令-跟随样本的教学视觉语言数据集进行微调。 数据收集过程涉及创建会话、详细描述和复杂推理提示。使用GPT-4将图像-文本对转换为适用于此数据集的适当的指令跟随格式。使用标题和边界框等视觉特征来编码图像。LLaVA在合成多模态指令跟随数据集上相对于GPT-4的得分为85.1%。在Science QA上进行微调时,LLaVA和GPT-4的协同作用实现了92.53%的新的最高准确率。 |
Video-LLaMA多模态框架:由两个分支编码器组成(视觉-语言VL分支和音频-语言AL分支+语言解码器LLaMA)
| Video-LLaMA (Zhang et al., 2023b) is a multimodal framework that enhances large language models with the ability to understand both visual and auditory content in videos. The architecture of Video-LLaMA consists of two branche encoders: the Vision-Language (VL) Branch and the Audio-Language (AL) Branch, and a language decoder (Vicuna (7B/13B) (Chiang et al., 2023), LLaMA (7B) (Touvron et al., 2023a), etc.). The VL Branch includes a frozen pre-trained image encoder (pre-trained vision component of BLIP-2 (Li et al., 2023d), which includes a ViT-G/14 and a pre-trained Q-former), a position embedding layer, a video Q-former and a linear layer. The AL Branch includes a pre- trained audio encoder (ImageBind (Girdhar et al., 2023)) and an Audio Q-former. Figure 6 shows the overall architecture of Video-LLaMA with Vision-Language Branch and Audio-Language Branch. The VL Branch is trained on the Webvid-2M (Bain et al., 2021) video caption dataset with a video-to-text generation task, and fine-tuned on the instruction-tuning data from MiniGPT-4 (Zhu et al., 2023), LLaVA (Liu et al., 2023b) and VideoChat (Li et al., 2023e). The AL Branch is trained on video/image instru- caption data to connect the output of ImageBind to language decoder. After finetuning, Video- LLaMA can perceive and comprehend video content, demonstrating its ability to integrate auditory and visual information, understand static images, recognize common-knowledge concepts, and capture temporal dynamics in videos. |
Video-LLaMA(Zhang等,2023b)是一个多模态框架,通过在视频中理解视觉和听觉内容来增强大型语言模型的能力。Video-LLaMA的架构由两个分支编码器组成:视觉-语言(VL)分支和音频-语言(AL)分支,以及一个语言解码器(Vicuna(7B/13B)(Chiang等,2023),LLaMA(7B)(Touvron等,2023a)等)。 VL分支包括一个冻结的预训练图像编码器(BLIP-2的预训练视觉组件(Li等,2023d)),其中包括一个ViT-G/14和一个预训练的Q-former)、一个位置嵌入层、一个视频Q-former和一个线性层。 AL分支包括一个预训练的音频编码器(ImageBind(Girdhar等,2023))和一个音频Q-former。图6展示了Video-LLaMA的整体架构,包括视觉-语言分支和音频-语言分支。 VL分支在Webvid-2M(Bain等,2021)视频字幕数据集上进行训练,进行视频到文本生成任务,并在来自MiniGPT-4(Zhu等,2023)、LLaVA(Liu等,2023b)和VideoChat(Li等,2023e)的指令微调数据上进行微调。 AL分支在视频/图像指令-字幕数据上进行训练,将ImageBind的输出连接到语言解码器。 微调后,Video-LLaMA能够感知和理解视频内容,展示了其整合听觉和视觉信息、理解静态图像、识别常识概念以及捕捉视频中的时间动态的能力。 |
InstructBLIP视觉-语言指令微调框架:基于BLIP-2模型(图像编码器+LLM+Query Transformer)
| InstructBLIP (1.2B) (Dai et al., 2023) is a vision-language instruction tuning framework initialized with a pre-trained BLIP-2 (Li et al., 2023d)) model consisting of an image encoder, an LLM (FlanT5 (3B/11B) (Chung et al., 2022) or Vicuna (7B/13B) (Chiang et al., 2023)), and a Query Transformer (Q-Former) to bridge the two. As shown in Figure 7, the Q-Former extracts instruction-aware visual features from the output embeddings of the frozen image encoder, and feeds the visual features as soft prompt input to the frozen LLM. The authors evaluate the proposed InstructBLIP model on a variety of vision- language tasks, including image classification, image captioning, image question answering, and visual reasoning. They use 26 publicly available datasets, dividing them into 13 held-in and 13 held-out datasets for training and evaluation. The authors demonstrate that InstructBLIP achieves state-of-the-art zero-shot performance on a wide range of vision-language tasks. InstructBLIP yields an average relative improvement of 15.0% when compared to BLIP-2, smallest InstructBLIP (4B) outperforms Flamingo (80B) (Alayrac et al., 2022) on all six shared evaluation datasets with an average relative improvement of 24.8%. |
InstructBLIP(1.2B)(Dai等,2023)是一个视觉-语言指令微调框架,其初始化为一个预训练的BLIP-2(Li等,2023d)模型,包括图像编码器、LLM(FlanT5(3B/11B)(Chung等,2022)或Vicuna(7B/13B)(Chiang等,2023))和一个Query Transformer(Q-Former)以连接两者。如图7所示,Q-Former从冻结的图像编码器的输出嵌入中提取指令感知的视觉特征,并将视觉特征作为软提示输入到冻结的LLM中。 作者在各种视觉-语言任务上评估了所提出的InstructBLIP模型,包括图像分类、图像字幕生成、图像问答和视觉推理。他们使用了26个公开可用的数据集,将其分为13个用于训练和13个用于评估的数据集。作者证明InstructBLIP在各种视觉-语言任务上实现了最新的零-shot性能。相较于BLIP-2,InstructBLIP平均相对改进15.0%,最小的InstructBLIP(4B)在六个共享评估数据集上优于Flamingo(80B)(Alayrac等,2022),平均相对改进为24.8%。 |
Otter:基于OpenFlamingo模型+只微调Perceiver重采样模块、交叉注意力层和输入/输出嵌入
| Otter (Li et al., 2023b) is a multi-modal model trained by fine-tuning OpenFlamingo (9B) (Awadalla et al., 2023), with the language and vision encoders frozen and only fine-tuning the Perceiver resampler module, cross-attention layers, and input/output embeddings. The authors organize diverse multi-modal tasks covering 11 categories and build multi-modal in-context instruction tuning datasets MIMIC-IT of 2.8M multimodal instruction-response pairs, which consists of image- instruction-answer triplets, where the instruction- answer is tailored to the image. Each data sample also includes context, which contains a series of image-instruction-answer triplets that contextually correlate with the queried triplet. Otter demonstrates the ability to follow user instructions more accurately and provide more detailed descriptions of images compared to OpenFlamingo (Awadalla et al., 2023). |
Otter(Li等,2023b)是一种多模态模型,通过微调OpenFlamingo(9B)(Awadalla等,2023),其中语言和视觉编码器被冻结,只微调了Perceiver重采样模块、交叉注意力层和输入/输出嵌入。作者组织了涵盖11个类别的多样多模态任务,并构建了包含2.8M个多模态指令-响应对的多模态上下文指令微调数据集MIMIC-IT,其中包括图像-指令-答案三元组,其中指令-答案适用于图像。每个数据样本还包括上下文,其中包含一系列与查询的三元组在上下文上下文相关的图像-指令-答案三元组。Otter相对于OpenFlamingo(Awadalla等,2023)能够更准确地遵循用户指令,并提供与图像相关的更详细的描述。 |
MultiModal-GPT:多模态指令微调模型
| MultiModal-GPT (Gong et al., 2023) is a multi- modal instruction tuning model that is capable of following diverse instructions, generating detailed captions, counting specific objects, and addressing general inquiries. MultiModal-GPT is trained by fine-tuning OpenFlamingo (9B) (Awadalla et al., 2023) on various created visual instruction data with open datasets, including VQA, Image Captioning, Visual Reasoning, Text OCR, and Visual Dialogue. The experiments demonstrate the proficiency of MultiModal-GPT in maintaining continuous dialogues with humans. |
MultiModal-GPT(Gong等,2023)是一种多模态指令微调模型,能够遵循不同的指令,生成详细的标题,计数特定的对象,并回答一般性问题。MultiModal-GPT通过在包括VQA、图像字幕生成、视觉推理、文本OCR和视觉对话等的各种创建的视觉指令数据上微调OpenFlamingo(9B)(Awadalla等,2023)而训练得到。实验展示了MultiModal-GPT在与人类保持持续对话方面的能力。 |
6、Domain-specific Instruction Finetuning特定领域指令微调
| In this section, we describe instruction tuning in different domains and applications. |
在本节中,我们描述了不同领域和应用中的指令微调。 |
6.1、Dialogue对话—InstructDial、LINGUIST模型:每个任务实例{任务描述、实例输入、约束、指令和输出}+两个元任务(指令选择任务+指令二元任务)
| InstructDial (Gupta et al., 2022) is an instruction tuning framework designed for dialogue. It contains a collection of 48 dialogue tasks in a consistent text-to-text format created from 59 dialogue datasets. Each task instance includes a task description, instance inputs, constraints, instructions, and output. To ensure adherence to instructions, the framework introduces two meta- tasks: (1) an instruction selection task, where the model selects the instruction corresponding to a given input-output pair; and (2) an instruction binary task, where the model predicts "yes" or "no" if an instruction leads to a given output from an input. Two base models T0-3B (Sanh et al., 2021) (3B parameters version of T5 (Lester et al., 2021)) and BART0 (Lin et al., 2022) (406M parameters based on Bart-large (Lewis et al., 2019)) are fine- tuned on the tasks from InstructDial. InstructDial achieves impressive results on unseen dialogue datasets and tasks, including dialogue evaluation and intent detection. Moreover, it delivers even better results when applied to a few-shot setting. Intent Classification and Slot Tagging LINGUIST (Rosenbaum et al., 2022) finetunes AlexaTM 5B (Soltan et al., 2022), a 5-billion-parameter multilingual model, on the instruction dataset for intent classification and slot tagging tasks. Each instruction consists of five blocks: (i) the language of the generated output, (ii) intention, slot types and values to include in the output (e.g., the number 3 in [3, snow] corresponds the slot type, and snow is the value used for that slot), a mapping from slot type labels to numbers, and (v) up to 10 examples to instruct the format of the outputs. LINGUIST shows significant improvements over state-of-the-art approaches in a 10-shot novel intent setting using the SNIPS dataset (Coucke et al., 2018). In the zero-shot cross- lingual setting of the mATIS++ dataset (Xu et al., 2020), LINGUIST surpasses a strong baseline of Machine Translation with Slot Alignment across 6 languages while maintaining intent classification performance. |
InstructDial(Gupta等,2022)是一个专为对话设计的指令微调框架。它包含一个由59个对话数据集创建的一致的文本到文本格式的48个对话任务集合。 每个任务实例包括任务描述、实例输入、约束、指令和输出。为了确保遵循指令,该框架引入了两个元任务:(1)指令选择任务,模型根据给定的输入-输出对选择相应的指令; (2)指令二元任务,模型预测如果一个指令将输入转化为给定的输出,它将预测“是”或“否”。 两个基本模型T0-3B(Sanh等,2021)(T5的3B参数版本(Lester等,2021))和BART0(Lin等,2022)(基于Bart-large(Lewis等,2019)的406M参数)在来自InstructDial的任务上进行微调。InstructDial在看不见的对话数据集和任务上取得了令人印象深刻的成绩,包括对话评估和意图检测。此外,当应用于少样本设置时,它甚至可以获得更好的结果。 意图分类和槽位标记LINGUIST(Rosenbaum等,2022)对AlexaTM 5B(Soltan等,2022),一个50亿参数的多语言模型进行微调,用于意图分类和槽位标记任务的指令数据集。每个指令由五个块组成: (i)生成输出的语言, (ii)意图、槽位类型和要包含在输出中的值(例如,[3, snow]中的数字3对应于槽位类型,snow是用于该槽位的值),从槽位类型标签到数字的映射, (v)最多10个示例,以指导输出的格式。 LINGUIST在使用SNIPS数据集(Coucke等,2018)进行10样本新意图设置时,在零样本跨语言的mATIS++数据集(Xu等,2020)中,LINGUIST在维持意图分类性能的同时,超越了机器翻译与槽位对齐的强基线。 |
6.3、Information Extraction信息抽取—InstructUIE:基于FlanT5模型+指令微调的统一信息抽取(IE)框架+将IE任务转化为seq2seq格式,每个任务实例四个属性{任务指令、选项、文本、输出}
| InstructUIE (Wang et al., 2023b) is a unified information extraction (IE) framework based on instruction tuning, which transforms IE tasks to the seq2seq format and solves them by fine- tuning 11B FlanT5 (Chung et al., 2022) on the constructed IT dataset. Figure 8 shows the overall architecture of InstructUIE. It introduces IE INSTRUCTIONS, a benchmark of 32 diverse information extraction datasets in a unified text-to- text format with expert-written instructions. Each task instance is delineated by four properties: task instruction, options, text, and output. Task instruction contains information such as the type of information to be extracted, the output structure format, and additional constraints or rules that need to be adhered to during the extraction process. Options refer to the output label constraints of a task. Text refers to the input sentence. Output is the sentence obtained by converting the original tags of the sample (e.g. "entity tag: entity span" for NER). In the supervised setting, InstructUIE performs comparably to BERT (Devlin et al.,2018) and outperforms the state-of-the-art and GPT3.5 (Brown et al., 2020a) in zero-shot settings. |
InstructUIE(Wang等,2023b)是一个基于指令微调的统一信息抽取(IE)框架,它将IE任务转化为seq2seq格式,并通过在构建的IT数据集上微调11B FlanT5(Chung等,2022)来解决这些问题。 图8展示了InstructUIE的整体架构。它引入了IE INSTRUCTIONS,这是一个由32个多样的信息抽取数据集组成的基准,以统一的文本到文本格式呈现,其中包含专家编写的指令。 每个任务实例由四个属性描述:任务指令、选项、文本和输出。 >> 任务指令包含诸如要提取的信息类型、输出结构格式以及在提取过程中需要遵循的附加约束或规则等信息。 >> 选项是任务的输出标签约束。 >> 文本是输入句子。 >> 输出是通过将样本的原始标签(例如,NER中的"实体标签:实体跨度")转换为句子获得的(实体标签为槽位标签,实体跨度为值)。 在监督设置下,InstructUIE在零样本设置中表现出色,与BERT(Devlin等,2018)相当,并在零样本设置中超越了最先进的和GPT3.5(Brown等,2020a)。 |
6.4、ABSA基于内容的情感分析:基于T5模型
ABSA/Aspect-based Sentiment Analysis基于内容的情感分析
| Varia et al. (2022) propose a unified instruction tuning framework for solving Aspect-based Sentiment Analysis (ABSA) task based on a fine- tuned T5 (220M) (Raffel et al., 2019) model. The framework addresses multiple factorized sub- tasks that involve the four elements of ABSA, namely Aspect Term, Aspect Category, Opinion Term, and Sentiment. It treats these sub-tasks as a combination of five Question Answering (QA) tasks by transforming each sentence in the corpus using instruction templates provided for each task. For instance, one of the instruction templates used is "What are the aspect terms in the text: $TEXT?". The framework showcases substantial improvement (8.29 F1 on average) over the state-of- the-art in few-shot learning scenarios and remains comparable in full fine-tuning scenarios. |
Varia等(2022)提出了一个统一的指令微调框架,用于解决基于内容的情感分析(ABSA)任务,基于微调的T5(220M)(Raffel等,2019)模型。该框架处理涉及ABSA的四个元素的多个分解子任务,即内容术语、内容类别、意见术语和情感。它将这些子任务视为五个问答(QA)任务的组合,通过使用为每个任务提供的指令模板来转化语料库中的每个句子。例如,所使用的指令模板之一是"What are the aspect terms in the text: $TEXT?"。该框架在少样本学习场景中展示了显著的改进(平均F1值为8.29),在完全微调场景中保持了可比性。 |
6.5、Writing写作
Writing-Alpaca-7B辅助写作:基于LLaMa-7B模型+微调写作指令数据集(EDITEVAL基准的扩展),四元组{通用序言用于指导任务完成的指令字段,提供要编辑的文本的输入字段,要求模型填写的响应字段}
| Zhang et al. (2023d) propose Writing-Alpaca- 7B that fine-tunes LLaMa-7B on the writing instruction dataset to provide writing assistance. The proposed instruction dataset is an extension of the EDITEVAL benchmark based on instructional data, with the Updating task removed and a task for grammaticality introduced. The instruction scheme strictly follows the one in the Stanford Alpaca project, comprising a universal preface, an instruction field to guide task completion, an input field that provides the text to be edited, and a response field that requires models to fill out. The Writing-Alpaca-7B improves upon LLaMa’s performance on all writing tasks and outperforms other larger off-the-shelf LLMs. |
Zhang等(2023d)提出了Writing-Alpaca-7B,通过对写作指令数据集进行LLaMa-7B的微调,以提供写作辅助。所提出的指令数据集是基于指导性数据的EDITEVAL基准的扩展,删除了更新任务并引入了一个用于语法的任务。 指令方案严格遵循斯坦福Alpaca项目中的方案,包括通用序言、用于指导任务完成的指令字段、提供要编辑的文本的输入字段和要求模型填写的响应字段。Writing-Alpaca-7B在所有写作任务上均优于LLaMa,并在其他更大的现成LLM上取得了更好的表现。 |
CoEdIT辅助写作:基于对FLANT模型+微调在文本编辑的指令数据集,两元组{指令:源,目标}
| CoEdIT (Raheja et al., 2023) finetunes FLANT5 (770M parameters, 3B parameters, and 11B parameters) on the instruction dataset for text editing to provide writing assistance. The instruction dataset comprises approximately 82K<instruction: source, target> pairs. As shown in Figure 9, the model takes instructions from the user specifying the characteristics of the desired text, such as "Make the sentence simpler", and outputs the edited text. CoEdIT achieves state-of-the-art performance on several text editing tasks, including grammatical error correction, text simplification, iterative text editing, and three stylistic editing tasks: formality style transfer, neutralization, and paraphrasing. Furthermore, it can generalize well to new, adjacent tasks not seen during fine-tuning. |
CoEdIT(Raheja等,2023)对FLANT5(770M参数、3B参数和11B参数)在文本编辑的指令数据集上进行微调,以提供写作辅助。 指令数据集包括约82K个<指令:源,目标>对。 如图9所示,模型从用户处获取指令,指定所需文本的特性,例如"使句子更简单",然后输出编辑后的文本。 CoEdIT在多个文本编辑任务上取得了最先进的性能,包括语法错误纠正、文本简化、迭代文本编辑以及三个风格编辑任务:正式风格转换、中性化和改写。此外,它还可以很好地推广到新的、相邻的任务,这些任务在微调过程中未曾见过。 |
CoPoet协作的诗歌写作工具:基于T5模型+微调诗歌写作数据集,两元组{指令,诗行}
| CoPoet (Chakrabarty et al., 2022) is a collaborative poetry writing tool that utilizes a large language model (e.g. T5-3B, T5-11B and T0-3B models) trained on a diverse collection of instructions for poetry writing. Each sample in the instruction dataset includes an <instruction, poem_line> pair. There are three major types of instructions: Continuation, Lexical Constraints, and Rhetorical Techniques. The CoPoet is guided by user instructions that specify desired attributes of the poetry, such as writing a sentence about "love" or ending a sentence with "fly." Not only is the system competitive with publicly available LLMs trained on instructions, such as InstructGPT, but it is also capable of satisfying unseen compositional instructions. |
CoPoet(Chakrabarty等,2022)是一个协作的诗歌写作工具,利用大型语言模型(如T5-3B、T5-11B和T0-3B模型)在诗歌写作的各种指导下进行训练。指导性数据集中的每个样本都包括一个<指令,诗行>对。有三种主要类型的指导:延续、词汇约束和修辞技巧。 CoPoet根据用户的指令进行指导,指定诗歌的所需属性,例如写一个关于"爱"的句子或以"飞"结尾的句子。该系统不仅在公开可用的受指导训练的LLM方面具有竞争力,例如InstructGPT,还能够满足未见过的组合指导。 |
6.6、Medical医学
2023年6月14日,Radiology-GPT针对放射学领域:基于Alpaca+微调放射学领域知识数据集,两元组{发现,结论}
| 地址 |
|
| 时间 |
2023年6月14日 |
| 作者 |
佐治亚大学+哈佛+湘雅第二医院等 |
| Radiology-GPT (Liu et al., 2023c) is a fine-tuned Alpaca-7B model for radiology, which utilizes an instruction tuning approach on an extensive dataset of radiology domain knowledge. Radiology reports usually include two corresponding sections: "Findings" and "Impression". The "Findings" section contains detailed observations from the radiology images, while the "Impression" section summarizes the interpretations drawn from those observations. Radiology-GPT provides a brief instruction to the "Findings" text: "Derive the impression from findings in the radiology report". The "Impression" text from the same report serves as the target output. In comparison to general language models such as StableLM, Dolly, and LLaMA, Radiology-GPT demonstrates significant versatility in radiological diagnosis, research, and communication. |
Radiology-GPT(Liu等,2023c)是一个针对放射学领域的Alpaca-7B模型进行微调的模型,它在广泛的放射学领域知识数据集上采用了指令微调方法。放射学报告通常包括两个相应的部分:"发现"和"结论"。"发现"部分包含来自放射学图像的详细观察,而"结论"部分总结了从这些观察中得出的解释。Radiology-GPT为"发现"文本提供了一个简要的指令:"从放射学报告的发现中得出结论"。同一份报告中的"结论"文本被用作目标输出。与StableLM、Dolly和LLaMA等通用语言模型相比,Radiology-GPT在放射学诊断、研究和交流方面表现出显著的多样性。 |
2023年4月18日,ChatDoctor:基于LLaMA模型+微调Alpaca指令数据集和HealthCareMagic100k患者-医生对话数据集且检索外部知识数据库
| 地址 |
|
| 时间 |
2023年4月18日 |
| 作者 |
美国达拉斯德克萨斯大学+伊利诺伊大学+俄亥俄州立大学等 |
| ChatDoctor (Li et al., 2023g) is based on the fine-tuned LLaMA-7B model, utilizing the alpaca instruction dataset and the HealthCareMagic100k patient-doctor dialogue dataset. And prompt templates are designed for retrieving external knowledge databases, such as the Disease Database and Wikipedia retrieval, during doctor-patient conversations to obtain more accurate outputs from the model. The ChatDoctor significantly improves the model’sability to comprehend patient needs and provide informed advice. By equipping the model with self-directed information retrieval from reliable online and offline sources, the accuracy of its responses is substantially improved. |
ChatDoctor(Li等,2023g)基于经过微调的LLaMA-7B模型,利用Alpaca指令数据集和HealthCareMagic100k患者-医生对话数据集。并且在医生-患者对话期间为检索外部知识数据库,如疾病数据库和维基百科检索,设计了提示模板,以从模型中获取更准确的输出。ChatDoctor显著提高了模型理解患者需求并提供明智建议的能力。通过为模型配备从可靠的在线和离线来源自主获取信息的能力,其回答的准确性大大提高。 |
2023年3月,ChatGLM-Med:基于ChatGLM模型+微调中国医学指令数据集(基于GPT3.5的API和医学知识图谱创建问题-答案对)
| 地址 |
|
| 时间 |
2023年3月 |
| 作者 |
哈尔滨工业大学 |
| ChatGLM-Med (Haochun Wang, 2023) is fine- tuned on the Chinese medical instruction dataset based on the ChatGLM-6B model. The instruction dataset comprises medically relevant question and answer pairs, created using the GPT3.5 API and the Medical Knowledge Graph. This model improves the question-answering performance of ChatGLM in the medical field. |
ChatGLM-Med(Haochun Wang,2023)在基于ChatGLM-6B模型的中国医学指令数据集上进行了微调。指令数据集包括使用GPT3.5 API和医学知识图谱创建的与医学相关的问题和答案对。该模型提高了ChatGLM在医学领域的问答性能。 |
6.7、Arithmetic算术:Goat=基于LLaMA模型+微调算术问题数据集(ChatGPT生成数百个指令+自然语言问答的形式表达)
| Goat (Liu and Low, 2023) is a fine-tuned LLaMA-7B model based on instructions, which aims to solve arithmetic problems. It expresses arithmetic problems in the form of natural language question answering, such as "What is 8914/64?", by generating hundreds of instruction templates using ChatGPT. The model applies various techniques to enhance its adaptability to diverse question formats, such as randomly removing spaces between numbers and symbols in the arithmetic expression and replacing "*" with "x" or "times". The Goat model achieves state-of-the-art performance on the BIG-bench arithmetic subtask. In particular, zero-shot Goat7B matches or exceeds the accuracy achieved by the few-shot PaLM-540B. |
Goat(Liu和Low,2023)是一个基于指令微调的LLaMA-7B模型,旨在解决算术问题。它通过使用ChatGPT生成数百个指令模板,以自然语言问答的形式表达算术问题, 例如"What is 8914/64?"。该模型应用各种技术增强其适应各种问题格式的能力,例如随机删除算术表达式中数字和符号之间的空格,将"*"替换为"x"或"times"等。Goat模型在BIG-bench算术子任务上达到了最先进的性能。特别是,零样本的Goat7B的准确性达到或超过了少样本的PaLM-540B的准确性。 |
6.8、Code代码:WizardCoder=基于StarCoder模型+Evol-Instruct方法+微调Code Alpaca数据集,3元组{指令、输入、期望输出}
| WizardCoder (Luo et al., 2023) utilizes StarCoder 15B as the foundation with complex instruction fine-tuning, by adapting the Evol- Instruct method (Xu et al., 2023) to the domain of code. The training dataset is produced through iterative application of the Evol-Instruct technique on the Code Alpaca dataset, which includes the following attributes for each sample: instruction, input, and expected output. For instance, when the instruction is "Amend the following SQL query to select distinct elements", the input is the SQL query, and the expected output is the generated answer. The WizardCoder outperforms all other open-source Code LLMs and even outperforms the largest LLMs, Anthropic’s Claude and Google’s Bard, on HumanEval and HumanEval+. |
WizardCoder(Luo等,2023)以StarCoder 15B为基础,采用复杂指令微调,将Evol-Instruct方法(Xu等,2023)适用于代码领域。训练数据集通过在Code Alpaca数据集上迭代应用Evol-Instruct技术产生,该数据集为每个样本包括以下属性:指令、输入和期望输出。 例如,当指令为"Amend the following SQL query to select distinct elements"时,输入为SQL查询,期望输出为生成的答案。WizardCoder在HumanEval和HumanEval+上超越了所有其他开源代码LLM,甚至在HumanEval和HumanEval+上也超越了最大的LLM,Anthropic的Claude和Google的Bard。 |
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-程序员宅基地
2023年,LLMs之Code:Code Llama的简介(衍生模型如Phind-CodeLlama/WizardCoder)、安装、使用方法之详细攻略
LLMs之Code:Code Llama的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-程序员宅基地
补充—6.9、法律行业
LLMs之Law:大语言模型领域行业场景应用之大模型法律行业的简介、主流LLMs(PowerLawGLM/ChatLaw)、经典应用之详细攻略
LLMs之Law:大语言模型领域行业场景应用之大模型法律行业的简介、主流LLMs(PowerLawGLM/ChatLaw)、经典应用之详细攻略_一个处女座的程序猿的博客-程序员宅基地
7、Efficient Tuning Techniques高效微调技术
7.0、高效微调三种方法论:基于添加式(引入额外可训练参数或模块,如HINT)、基于规范化(冻结某些固有模型参数同时指定要调整的参数,如Delta-tuning)、基于重参数化(假设模型自适应的低秩性→权重可重新参数化为低维子空间,如LoRA/QLoRA/LOMO)
| Efficient fine-tuning techniques aim at adapting LLMs to downstream tasks by optimizing a small fraction of parameters in multiple ways, i.e., addition-based, specification-based, and Reparameterization-based. Addition-based methods introduce extra trainable parameters or modules not present in the original model. Representative methods include adapter tuning (Houlsby et al., 2019) and prompt-based tuning (Schick and Schütze, 2021). Specification-based methods specify certain inherent model parameters to be tuned while freezing others. For example, BitFit (Zaken et al., 2022) tunes the bias terms of the pre-trained model. Reparameterization methods transform model weights into more parameter-efficient forms for tuning. The key hypothesis is that model adaptation is low-rank, so weights can be reparameterized into low- rank factors or a low-dimensional subspace (e.g., LoRA (Hu et al., 2021)). Intrinsic prompt tuning finds a low-dimensional subspace shared by tuning prompts across diverse tasks. |
高效微调技术旨在通过多种方式对少量参数进行优化,从而将LLM适应于下游任务,包括基于添加式、基于规范化和基于重参数化的方法。基于添加式的方法引入了在原始模型中不存在的额外可训练参数或模块。代表性的方法包括Adapter微调(Houlsby等,2019)和基于Prompt的微调(Schick和Schütze,2021)。基于规范化的方法在冻结某些固有模型参数的同时,指定要调整的参数。例如,BitFit(Zaken等,2022)微调预训练模型的偏差项。基于重参数化方法将模型权重转换为更加参数高效的形式进行微调。关键假设是模型的自适应是低秩的,因此权重可以重新参数化为低秩因子或低维子空间(例如LoRA(Hu等,2021))。Intrinsic prompt内在的提示微调在不同任务之间找到了一种共享的低维子空间。 |
7.1、基于重参数化—LoRA=基于DeepSpeed框架+训练低维度的A和B→可训练参数比完全微调少得多(LoRA训练GPT-3可降低到千分之一)
| Low-Rank Adaptation (LoRA) (Hu et al., 2021) enables efficient adaptation of LLMs using low- rank updates. LoRA use DeepSpeed (Rasley et al., 2020) as the training backbone. The key insight of LoRA is that the actual change in LLMs’ weights required for new task adaptation lies in a low- dimensional subspace. Specifically, for a pretrained weight matrix W0, the authors model the adapted weight matrix as W0 + ∆W , where ∆W is a low rank update. ∆W is parameterized as ∆W = BA, where A and B are much smaller trainable matrices. The rank r of ∆W is chosen to be much smaller than the dimensions of W0. The intuition is that instead of directly training all of W0, the authors train low-dimensional A and B, which indirectly trains W0 in a low-rank subspace of directions that matter for the downstream task. This results in far fewer trainable parameters compared to full fine- tuning. For GPT-3, LoRA reduces the number of trainable parameters by 10,000x and memory usage by 3x compared to full fine-tuning. |
低秩适应(LoRA)(Hu等,2021)使用低秩更新实现了LLM的高效适应。LoRA使用DeepSpeed(Rasley等,2020)作为训练骨干。LoRA的关键洞察是,用于新任务适应的LLM权重的实际变化位于低维子空间中。 具体而言,对于预训练权重矩阵W0,作者将适应权重矩阵建模为 W0 + ∆W, 其中∆W是低秩更新。∆W的参数化形式为∆W = BA,其中A和B是较小的可训练矩阵。∆W的秩r被选择为远小于W0的维度。 直觉是,作者不是直接训练所有W0,而是训练低维度的A和B,这间接地在对下游任务重要的低秩子空间中训练W0。这导致可训练参数比完全微调少得多。对于GPT-3,LoRA将可训练参数的数量减少了10000倍,内存使用量降低了3倍,与完全微调相比。 |
7.2、基于添加式—HINT=添加易于微调的模块(基于超网络数生成器生成适配器和前缀参数)+插入到骨干模型作为高效的微调模块
HINT属于Addition-based方法。它通过添加易于微调的模块(如适配器和前缀)来实现微调,这些模块没有包含在原始模型结构中,属于添加额外的参数或模块来实现微调。
| HINT (Ivison et al., 2022) combines the generalization benefits of instruction tuning with efficient on-demand fine-tuning, avoiding repeatedly processing lengthy instructions. The essence of HINT lies in hypernetworks, which generate parameter-efficient modules for LLMs adaptation based on natural language instructions and few-shot examples. The adopted hypernetwork converts instructions and few-shot examples into a encoded instruction and generates adapter and prefix parameters using a pretrained text encoder and cross-attention based parameter generator. Then, the generated adapters and prefixes are inserted into the backbone model as efficient tuning modules. At inference, the hypernetwork performs inference only once per task to generate adapted modules. The benefits are that HINT can incorporate long instructions and additional few- shots without increasing compute, unlike regular fine-tuning or input concatenation methods. |
HINT(Ivison等,2022)将指令微调的泛化优势与高效的按需微调相结合,避免重复处理冗长的指令。HINT的核心在于超网络,它基于自然语言指令和少样本示例为LLM适应生成参数高效的模块。采用的超网络将指令和少样本示例转化为编码指令,并使用预训练文本编码器和基于交叉注意力的参数生成器生成适配器和前缀参数。然后,生成的适配器和前缀被插入到骨干模型中作为高效的微调模块。在推理时,超网络仅执行一次推理以生成适应的模块。好处是,HINT可以在不增加计算的情况下融入长指令和额外的少样本,不像常规微调或输入连接方法。 |
7.3、基于重参数化—QLoRA=LoRA的量化版+NF4+双量化DQ+分页优化器PO
| QLORA (Dettmers et al., 2023) includes optimal quantization and memory optimization, aiming at providing efficient and effective LLMs fine- tuning. QLORA includes 4-bit NormalFloat (NF4) Quantization, which is a quantization scheme optimized for the typical normal distribution of LLM weights. By quantizing based on the quantiles of a normal distribution, NF4 provides better performance than standard 4-bit integer or float quantization. To further reduce memory, the quantization constants are themselves quantized to 8 bits. This second level of quantization saves an additional 0.37 bits per parameter on average. QLORA leverages NVIDIA’s unified memory feature to page optimizer states to CPU RAM when GPU memory is exceeded. avoiding out-of-memory during training. QLORA enables training a 65B parameter LLM on a single 48GB GPU with no degradation compared to full 16- bit finetuning. QLORA works by freezing the 4-bit quantized base LLM, then backpropagating through it into a small set of 16-bit low-rank adapter weights which are learned. |
QLORA(Dettmers等,2023)包括最佳量化和内存优化,旨在提供高效有效的LLM微调。QLORA包括4位NormalFloat(NF4)量化,这是一种针对LLM权重的典型正态分布优化的量化方案。通过基于正态分布的分位数进行量化,NF4的性能优于标准的4位整数或浮点数量化。为了进一步减少内存,量化常数本身被量化为8位。这第二层量化平均可节省每个参数0.37位的内存。QLORA利用NVIDIA的统一内存功能,当GPU内存超出限制时,将优化器状态分页到CPU RAM中,避免训练期间的内存不足。QLORA可以在单个48GB GPU上训练65B参数的LLM,与完全16位微调相比没有降级。QLORA的工作方式是冻结4位量化的基础LLM,然后通过反向传播将其传播到一小组16位低秩适配器权重中进行学习。 |
7.4、基于重参数化—LOMO=降低梯度内存需求(融合梯度计算与参数更新+实时只存储单个参数的梯度)+稳定训练(梯度值裁剪+分离梯度范数计算+态损失缩放)+节省内存(激活检查点+ZeRO优化)
LOMO属于Reparameterization-based方法。LOMO通过将梯度计算和参数更新融合到一个步骤中,来避免存储完整的梯度张量,从而实现只存储单个参数梯度的能力,从而更高效地进行微调。这属于使用参数重参数化的方法来实现更高效的微调。
| LOw-Memory Optimization (LOMO) (Lv et al., 2023) enables full parameter fine-tuning of LLMs using limited computational resources through a fusion of gradient computation and update. The essence is to fuse gradient computation and parameter update into one step during backpropagation, thereby avoiding storage of full gradient tensors. Firstly, theoretical analysis is provided in LOMO on why SGD can work well for fine-tuning large pre-trained models despite its challenges on smaller models. In addition, LOMO updates each parameter tensor immediately after computing its gradient in backpropagation. Storing the gradient of one parameter at a time reduces gradient memory to O(1). LOMO employs gradient value clipping, separate gradient norm computation pass and dynamic loss scaling to stabilize training. The integration of activation checkpointing and ZeRO optimization methods saves memory. |
低内存优化(LOMO)(Lv等,2023)通过梯度计算和更新的融合,在有限的计算资源下实现LLM的全参数微调。其核心是在反向传播期间将梯度计算和参数更新融合为一步,从而避免存储完整的梯度张量。首先,LOMO在理论上分析了为什么SGD可以在微调大型预训练模型时表现良好,尽管在较小的模型上可能存在挑战。此外,LOMO在反向传播中在计算梯度后立即更新每个参数张量。一次只存储一个参数的梯度将梯度内存降低到O(1)。LOMO采用梯度值裁剪、单独的梯度范数计算传递和动态损失缩放来稳定训练。激活检查点和ZeRO优化方法的集成可节省内存。 |
7.5、基于规范化—Delta-tuning=优化和最优控制视角+将微调限制在低维流形上来执行子空间优化+微调参数充当最优控制器+在下游任务中引导模型行为
Delta-tuning属于Specification-based方法。Delta-tuning通过限制微调在一个低维子空间上进行,来指定预训练模型中的某些固有参数进行微调,而冻结其他参数。这属于指定模型参数子集进行微调的Specification-based方法。
| Delta-tuning (Ding et al., 2023b) provides optimization and optimal control perspectives for theoretical analyzation. Intuitively, delta-tuning performs subspace optimization by restricting tuning to a low-dimensional manifold. The tuned parameters act as optimal controllers guiding model behavior on downstream tasks. |
Delta-tuning(Ding等,2023b)提供了优化和最优控制的理论分析视角。直观地说,Delta-tuning通过将调整限制在低维流形上来执行子空间优化。调整的参数充当引导模型在下游任务中行为的最优控制器。 |
8、Evaluation, Analysis and Criticism评估、分析和批评
8.1、HELM Evaluation:整体评估+提高LM透明度+关注三因素(广泛性+多指标性+标准化)
| HELM(Liang et al., 2022) is a holistic evaluation of Language Models (LMs) to improve the transparency of language models, providing a more comprehensive understanding of the capabilities, risks, and limitations of language models. Specifically, differing from other evaluation methods, HELM holds that a holistic evaluation of language models should focus on the following three factors: |
HELM(Liang等,2022)是对语言模型(LMs)进行整体评估,旨在提高语言模型的透明度,从而更全面地了解语言模型的能力、风险和限制。与其他评估方法不同,HELM认为对语言模型进行整体评估应关注以下三个因素: |
| (1)、Broad coverage. During the development, language models can be adapted to various NLP tasks (e.g., sequence labeling and question answering), thus, the evaluation of language models needs to be carried out in a wide range of scenarios. To involve all potential scenarios, HELM proposed a top-down taxonomy, which begins by compiling all existing tasks in a major NLP conference (ACL2022) into a task space and dividing each task into the form of scenarios (e.g., languages) and metrics (e.g., accuracy). Then when facing a specific task, the taxonomy would select one or more scenarios and metrics in the task space to cover it. By analyzing the structure of each task, HELM clarifies the evaluation content (task scenarios and metrics) and improves the scenario coverage of language models from 17.9% to 96.0%. (2)、Multi-metric measurement. In order to enable human to weigh language models from different perspectives, HELM proposes multi- metric measurement. HELM has covered 16 different scenarios and 7 metrics. To ensure the results of intensive multi-metric measurement, HELM measured 98 of 112 possible core scenarios (87.5%). (3)、Standardization. The increase in the scale and training complexity of language models has seriously hindered human’s understanding of the structure of each language model. To establish a unified understanding of existing language models, HELM benchmarks 30 well-known language models, covering such institutions as Google (UL2(Tay et al., 2022)), OpenAI (GPT-3(Brown et al., 2020b)), and EleutherAI (GPT-NeoX(Black et al., 2022)). Interestingly, HELM pointed out that LMs such as T5 (Raffel et al., 2019) and Anthropic- LMv4-s3 (Bai et al., 2022a) had not been directly compared in the initial work, while LLMs such as GPT-3 and YaLM were still different from their corresponding reports after multiple evaluations. |
(1)广泛涵盖。在开发过程中,语言模型可以适应各种自然语言处理任务(例如序列标注和问题回答),因此需要在广泛的情景下进行语言模型的评估。为了涵盖所有潜在情景,HELM提出了一种自上而下的分类法,首先将主要的自然语言处理会议(ACL2022)中的所有现有任务编译成任务空间,并将每个任务划分为情景(例如语言)和指标(例如准确性)的形式。然后在面对特定任务时,分类法会选择任务空间中的一个或多个情景和指标来涵盖它。通过分析每个任务的结构,HELM明确了评估内容(任务情景和指标),并将语言模型的情景涵盖范围从17.9%提高到96.0%。 (2)多指标测量。为了使人类能够从不同角度权衡语言模型,HELM提出了多指标测量。HELM涵盖了16种不同的情景和7个指标。为了确保密集的多指标测量结果,HELM对112个可能的核心情景中的98个进行了测量(87.5%)。 (3)标准化。语言模型规模和训练复杂性的增加严重阻碍了人类对每个语言模型结构的理解。为了建立对现有语言模型的统一理解,HELM对30个知名语言模型进行了基准测试,涵盖了Google(UL2(Tay等,2022))、OpenAI(GPT-3(Brown等,2020b))和EleutherAI(GPT-NeoX(Black等,2022))等机构。有趣的是,HELM指出,例如T5(Raffel等,2019)和Anthropic- LMv4-s3(Bai等,2022a)等LLMs在初始工作中尚未直接进行比较,而GPT-3和YaLM等LLMs在多次评估后仍与其对应的报告不同。 |
8.2、Low-resource Instruction Tuning低资源指令微调:STL需要数据量的25%、MTL需要数据量的6%
| Gupta et al. (2023) attempts to estimate the minimal downstream training data required by IT models to match the SOTA supervised models over various tasks. Gupta et al. (2023) conducted experiments on 119 tasks from Super Natural Instructions (SuperNI) in both single-task learning (STL) and multi-task learning (MTL) settings. The results indicate that in the STL setting, IT models with only 25% of downstream training data outperform the SOTA models on those tasks, while in the MTL setting, just 6% of downstream training data can lead IT models to achieve the SOTA performance. These findings suggest that instruction tuning can effectively assist a model in quickly learning a task even with limited data. However, due to resource limitations, Gupta et al. (2023) did not conduct experiments on LLMs, like T5-11B. So, to gain a more comprehensive understanding of the IT models, further investigation using larger language models and datasets is necessary. |
Gupta等人(2023)试图估计IT模型需要多少最少的下游训练数据,才能在各种任务上匹配SOTA监督模型。Gupta等人(2023)在超自然指令(SuperNI)的119个任务上进行了实验,包括单任务学习(STL)和多任务学习(MTL)设置。结果表明,在STL设置下,只需使用下游训练数据的25%即可在这些任务上胜过SOTA模型,而在MTL设置下,只需使用下游训练数据的6%即可使IT模型达到SOTA性能。这些发现表明,即使数据有限,指令微调也能有效地帮助模型迅速学习任务。 然而,由于资源限制,Gupta等人(2023)并没有对像T5-11B这样的LLMs进行实验。因此,为了更全面地了解IT模型,需要进一步使用更大的语言模型和数据集进行调查。 |
8.3、Smaller Instruction Dataset更小的指令数据集:LIMA(精选1,000个训练示例)表面可过少数精心策划的指令进行微调
| IT requires a substantial amount of specialized instruction data for training. Zhou et al. (2023) hypothesized that the pre-trained LLM only has to learn the style or format to interact with users and proposed LIMA that achieves strong performance by fine-tuning an LLM on only 1,000 carefully selected training examples. Specifically, LIMA first manually curates 1,000 demonstrations with high-quality prompts and responses. Then the 1,000 demonstrations are used to fine-tune the pre-trained 65B-parameter LLaMa (Touvron et al., 2023b). By comparison, across more than 300 challenging tasks, LIMA outperfrms GPT-davinci003 (Brown et al., 2020b), which was fine-tuned on 5,200 examples by human feedback tuning. Moreover, with only half amount of demonstrations, LIMA achieves equivalent results to GPT-4 (OpenAI, 2023), Claude (Bai et al., 2022b), and Bard. Above all, LIMA demonstrated that LLMs’ powerful knowledge and capabilities can be exposed to users with only a few carefully curated instructions to fine-tune. |
IT需要大量的专门指令数据进行训练。Zhou等人(2023)假设预训练LLM只需学习与用户互动的样式或格式,并提出了LIMA,通过仅在1,000个精选的训练示例上微调LLM,实现了强大的性能。 具体而言,LIMA首先手动策划了1,000个具有高质量提示和回复的演示。然后,这1,000个演示用于微调预训练的65B参数LLaMa(Touvron等,2023b)。相比之下,在超过300个具有挑战性的任务中,LIMA在表现上胜过了通过人工反馈微调的GPT-davinci003(Brown等,2020b)。此外,只有一半数量的示范,LIMA就可以实现与GPT-4(OpenAI,2023)、Claude(Bai等,2022b)和Bard相当的结果。总之,LIMA表明LLMs的强大知识和能力可以通过少数精心策划的指令进行微调。 |
8.4、Evaluating Instruction-tuning Datasets评估指令微调数据集:缺乏开放性和主观性的评估
| The performance of IT model highly depends on the IT datasets. However, there lacks of evaluations for these IT datasets from open-ended and subjective aspects. To address this issue, Wang et al. (2023c) performs dataset evaluation by fine-tuning the LLaMa model (Touvron et al., 2023b) on various of open IT datasets and measure different fine- tuned models through both automatic and human evaluations. An additional model is trained on the combination of IT datasets. For the results, Wang et al. (2023c) showed that there is not a single best IT dataset across all tasks, while by manually combining datasets it can achieve the best overall performance. Besides, Wang et al. (2023c) pointed out that though IT can bring large benefits on LLMs at all sizes, smaller models and models with a high base quality benefit most from IT. For human evaluations, Wang et al. (2023c) a larger model is more likely to gain a higher acceptability score. |
IT模型的性能在很大程度上取决于IT数据集。然而,这些IT数据集在开放性和主观性方面缺乏评估。 为了解决这个问题,Wang等人(2023c)通过在各种开放IT数据集上微调LLaMa模型(Touvron等,2023b),并通过自动和人工评估来测量不同的微调模型。还有一个模型是在IT数据集的组合上进行训练的。根据结果,Wang等人(2023c)表明,并没有一个单一的最佳IT数据集适用于所有任务,但通过手动组合数据集可以实现最佳整体性能。此外,Wang等人(2023c)指出,尽管IT在所有规模的LLMs上都能带来很大的好处,但较小的模型和具有高基础质量的模型最能从IT中受益。对于人类评估,Wang等人(2023c)发现较大的模型更有可能获得更高的可接受性评分。 |
8.5、Do IT just learn Pattern Copying?IT是否只是学习模式复制?——有论文指出基于IT的显著改进只是捕获表面级别模式而非理解了本质
| To address the lack of clarity about the specific knowledge that models acquire through instruction tuning, Kung and Peng (2023) delves into the analysis of how models make use of instructions during IT by comparing the tuning when provided with altered instructions versus the original instructions. Specifically, Kung and Peng (2023) creates simplified task definitions that remove all semantic components, leaving only the output information. In addition, Kung and Peng (2023) also incorporates delusive examples that contain incorrect input-output mapping. Surprisingly, the experiments show that models trained on these simplified task definitions or delusive examples can achieve comparable performance to the ones trained on the original instructions and examples. Moreover, the paper also introduces a baseline for the classification task with zero-shot, which achieves similar performance to IT in low-resource settings. In summary, according to Kung and Peng (2023), the notable performance improvements observed in current IT models may be attributed to their ability to capture surface-level patterns, such as learning the output format and making guesses, rather than comprehending and learning the specific task. |
为了解决关于模型通过指令微调获取特定知识的缺乏清晰性的问题,Kung和Peng(2023)通过比较在提供修改后的指令与原始指令时的微调情况,深入分析了模型在指令微调过程中如何使用指令。 具体而言,Kung和Peng(2023)创建了简化的任务定义,去除了所有语义成分,只留下输出信息。此外,Kung和Peng(2023)还包括包含不正确输入-输出映射的误导性示例。令人惊讶的是,实验表明,训练在这些简化的任务定义或误导性示例上的模型可以达到与在原始指令和示例上训练的模型相当的性能。此外,该论文还引入了零样本分类任务的基线,其在低资源设置下实现了与IT相似的性能。 总之,根据Kung和Peng(2023)的观点,当前IT模型中观察到的显著性能改进可能归因于其捕捉表面级别的模式,例如学习输出格式和进行猜测,而不是理解和学习特定任务。 |
8.6、Proprietary LLMs Imitation专有LLMs模仿:微调模型能效仿ChatGPT的表达风格,但不等于提升其通用能力→更应注重基模型及指导实例的质量
Gudibande等人通过收集ChatGPT在多个领域的输出数据,用于微调开源模型,旨在使开源模型在部分领域的能力接近专有模型。他们的实验显示,在有模仿数据集支持的任务上,微调后模型的表现明显提高,输出与ChatGPT相似;但在没有模仿数据集的任务上,微调模型无效甚至效果下降。他们指出微调模型能效仿ChatGPT的表达风格,但不等于提升其通用能力。研究者应注重基模型及指导实例的质量,而不是模仿专有模型。
| LLMs imitation is an approach that collects outputs from a stronger model, such as a proprietary system like ChatGPT, and uses these outputs to fine-tune an open-source LLM. Through this way, an open- source LLM may get competitive capabilities with any proprietary model. Gudibande et al. (2023) conducted several experiments to critically analyze the efficacy of model imitation. Specifically, Gudibande et al. (2023) first collected datasets from outputs of ChatGPT over broad tasks. Then these datasets were used to fine-tune a range of models covering sizes from 1.5B to 13B, base models GPT-2 and LLaMA, and data amounts from 0.3M tokens to 150M tokens. For evaluations, Gudibande et al. (2023) demonstrated that on tasks with supported datasets, imitation models are far better than before, and their outputs appear similar to ChatGPT’s. While on tasks without imitation datasets, imitation models do not have improvement or even decline in accuracy. Thus, Gudibande et al. (2023) pointed out that it’s the phenomenon that imitation models are adept at mimicking ChatGPT’s style (e.g., being fluent, confident and well-structured) that makes researchers have the illusion about general abilities of imitation models. So, Gudibande et al. (2023) suggested that instead of imitating proprietary models, researchers had better focus on improving the quality of base models and instruction examples. |
LLMs模仿是一种方法,它收集来自更强大模型(例如ChatGPT等专有系统)的输出,并使用这些输出对开源LLM进行微调。通过这种方式,开源LLM可以获得与任何专有模型相当的能力。 Gudibande等人(2023)进行了多项实验,以批判性地分析模型模仿的效果。具体而言,Gudibande等人(2023)首先从广泛的任务中收集了ChatGPT的输出数据集。然后,这些数据集被用于微调覆盖从1.5B到13B大小的一系列模型,基础模型为GPT-2和LLaMA,数据量为0.3M到150M个标记。 在评估方面,Gudibande等人(2023)证明,在有支持数据集的任务上,模仿模型远远优于以前,其输出与ChatGPT的输出相似。然而,在没有模仿数据集的任务中,模仿模型没有提高甚至在准确性方面下降。 因此,Gudibande等人(2023)指出,模仿模型擅长模仿ChatGPT的风格(例如流利、自信和良好结构),这使得研究人员产生了有关模仿模型的普遍能力的错觉。因此,Gudibande等人(2023)建议,研究人员不应该模仿专有模型,而应该专注于提高基础模型和指令示例的质量。 |
9、Conclusion结论
| This work surveys recent advances in the fast growing field of instruction tuning. We make a systematic review of the literature, including the general methodology of IT, the construction of IT datasets, the training of IT models, IT’s applications to different modalities, domains and application. We also review analysis on IT models to discover both their advantages and potential pitfalls. We hope this work will act as a stimulus to motivate further endeavors to address the deficiencies of current IT models. |
本文对迅速发展的指令微调领域的最新进展进行了综述。我们对文献进行了系统性的回顾,包括IT的一般方法论、IT数据集的构建、IT模型的训练,以及IT在不同形式、领域和应用中的应用。我们还对IT模型的分析进行了回顾,以发现它们的优势和潜在问题。我们希望本文能够作为一个刺激,激励更多的努力来解决当前IT模型的不足之处。 |
References参考文献
更新中……
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线