<转载>原文链接:https://blog.csdn.net/chengqiuming/article/details/89816566
一 点睛
map的排序默认按照key从小到大进行排序,但有以下几点需要注意:
1 按照key从大到小进行排序。
2 key的第1个元素是结构体。
3 想按value(第二个元素)排序。
二 让map中的元素按照key从大到小排序
此处set也适用。
1 代码
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main(){
map<string, int, greater<string> > mapStudent; //关键是这句话
mapStudent["LiMin"]=90;
mapStudent["ZiLinMi"]=72;
mapStudent["BoB"]=79;
map<string, int>::iterator iter=mapStudent.begin();
for(iter=mapStudent.begin();iter!=mapStudent.end();iter++)
{
cout<<iter->first<<" "<<iter->second<<endl;
}
return 0;
}
2 运行
[root@localhost charpter03]# g++ 0327.cpp -o 0327
[root@localhost charpter03]# ./0327
ZiLinMi 72
LiMin 90
BoB 79
三 重定义map内部的Compare函数,按照键字符串长度大小进行排序
此处set也适用
1 代码
```cpp
#include <map>
#include <string>
#include <iostream>
using namespace std;
// 自己编写的Compare,实现按照字符串长度进行排序
struct CmpByKeyLength {
bool operator()(const string& k1, const string& k2) {
return k1.length() < k2.length();
}
};
int main(){
map<string, int, CmpByKeyLength > mapStudent; //这里注意要换成自己定义的compare
mapStudent["LiMin"]=90;
mapStudent["ZiLinMi"]=72;
mapStudent["BoB"]=79;
map<string, int>::iterator iter=mapStudent.begin();
for(iter=mapStudent.begin();iter!=mapStudent.end();iter++){
cout<<iter->first<<" "<<iter->second<<endl;
}
return 0;
}
2 运行
[root@localhost charpter03]# g++ 0328.cpp -o 0328
[root@localhost charpter03]# ./0328
BoB 79
LiMin 90
ZiLinMi 72
四 key是结构体的排序
此处set也适用
1 代码
#include <map>
#include <string>
#include <iostream>
using namespace std;
typedef struct tagStudentInfo
{
int iID;
string strName;
bool operator < (tagStudentInfo const& r) const {
//这个函数指定排序策略,按iID排序,如果iID相等的话,按strName排序
if(iID < r.iID) return true;
if(iID == r.iID) return strName.compare(r.strName) < 0;
return false;
}
}StudentInfo;//学生信息
int main(){
/*用学生信息映射分数*/
map<StudentInfo, int>mapStudent;
StudentInfo studentInfo;
studentInfo.iID = 1;
studentInfo.strName = "student_one";
mapStudent[studentInfo]=90;
studentInfo.iID = 2;
studentInfo.strName = "student_two";
mapStudent[studentInfo]=80;
map<StudentInfo, int>::iterator iter=mapStudent.begin();
for(;iter!=mapStudent.end();iter++){
cout<<iter->first.iID<<" "<<iter->first.strName<<" "<<iter->second<<endl;
}
return 0;
}
2 运行
[root@localhost charpter03]# g++ 0329.cpp -o 0329
[root@localhost charpter03]# ./0329
1 student_one 90
2 student_two 80
五 将map按value排序
切记,按照value排序时无法直接使用sort,应借助vector和pair来实现这个操作。
1 代码
#include <algorithm>
#include <map>
#include <vector>
#include <string>
#include <iostream>
using namespace std;
typedef pair<string, int> PAIR;
bool cmp_by_value(const PAIR& lhs, const PAIR& rhs) {
return lhs.second < rhs.second;
}
struct CmpByValue {
bool operator()(const PAIR& lhs, const PAIR& rhs) {
return lhs.second < rhs.second;
}
};
int main(){
map<string, int> name_score_map;
name_score_map["LiMin"] = 90;
name_score_map["ZiLinMi"] = 79;
name_score_map["BoB"] = 92;
name_score_map.insert(make_pair("Bing",99));
name_score_map.insert(make_pair("Albert",86));
/*把map中元素转存到vector中*/
vector<PAIR> name_score_vec(name_score_map.begin(), name_score_map.end());
sort(name_score_vec.begin(), name_score_vec.end(), CmpByValue());
/*sort(name_score_vec.begin(), name_score_vec.end(), cmp_by_value);也是可以的*/
for (int i = 0; i != name_score_vec.size(); ++i) {
cout<<name_score_vec[i].first<<" "<<name_score_vec[i].second<<endl;
}
return 0;
}
2 运行
[root@localhost charpter03]# g++ 0330.cpp -o 0330
[root@localhost charpter03]# ./0330
ZiLinMi 79
Albert 86
LiMin 90
BoB 92
Bing 99
文章浏览阅读3.8k次,点赞2次,收藏19次。作为前端开发, HTTP 中的 POST 请求和 GET 请求是经常会用到的东西,有的人可能知道,但对其原理和如何使用并不特别清楚,那么今天来浅谈一下两者的区别与如何使用。GET请求和POST请求的区别1、 GET 请求: GET 请求顾名思义是用来获取信息。它的本质是发送一个请求来取得服务器上的某一资源。资源通过一组 HTTP 头和呈现数据(如 HTML 文本,或者图片或者视频等)返回给客户端。2、 POST 请求: POST 请求则类似于一封信将参数放在信封里传输。其本质是像服务器传送数据。.._post get 请求的区别和用法
文章浏览阅读1k次,点赞20次,收藏27次。用过国际化`i18n`的朋友都知道,天下苦国际化久矣,尤其是中文为母语的开发者,在面对代码中一堆的`$t('abc.def')`这种一点也不直观毫无可读性的代码,根本不知道自己写了啥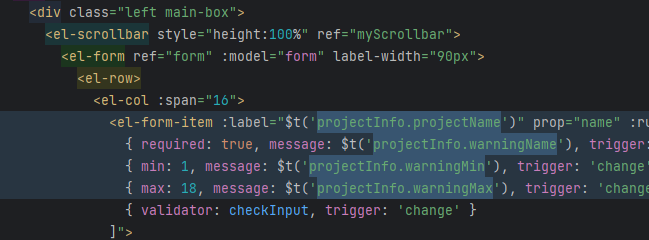 (如上图,你看得出来这是些啥吗)2. 第二个问题就是i18n各种语言版本的语言包难以维护,随着项目变大这个语言包会越来越难以维护,能不能自动去维护呢_i18n国际化键名用中文会怎么样
文章浏览阅读1k次。HotSpot虚拟机的介绍_hotspot虚拟机是什么
文章浏览阅读6.2k次,点赞3次,收藏10次。【mybatis和mybatisplus的区别】_mybatis和mybatisplus的区别
文章浏览阅读1.1k次,点赞30次,收藏17次。二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来只是元素的逻辑关系,通常的方法是链表中每个节点有三个域组成,数据域和左右指针域,左右指针分别用来给出该节点左孩子和右孩子所在的链节点的存储地址,链式结构又分为二叉链和三叉链,当前我们学习中一般都是二叉链。2.完全二叉树,完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的,对于深度为K的,由n个节点的二叉树,当且仅当每一个节点都与深度为K的满二叉树中编号从1至n的节点-一一对应时称为完全二叉树,要注意的是满二叉树是一种特殊的完全二叉树。
文章浏览阅读2k次。CentOS7运行报错kernel:NMI watchdog: BUG: soft lockup - CPU#0 stuck for 26sCentOS内核,对应的文件是/proc/sys/kernel/watchdog_thresh。CentOS内核和标准内核还有一个地方不一样,就是处理CPU占用时间过长的函数,CentOS下是watchdog_timer_fn()函数。如果你的内核是标准内核的话,可以通过修改/proc/sys/kernel/softlockup_thresh来修改超时的阈值参考_message from syslogd@centos at jul 17 18:36:38 ... kernel:nmi watchdog: bug:
文章浏览阅读1.5k次。区块链起点——避免你再错过几个亿如果对新鲜事物不够敏感,可以懊悔错过早期的机会。但是当新领域已经站在风口,请不要再视而不见。希望你的区块链知识从这里开始2013年的时候,身边的朋友就在谈论比特币,挖矿。在当时的我看来,这是个太虚的东西,没有任何实际的价值。时间进入到2017年,单个比特币价值近2万美刀的时候,我依然觉得是庞氏骗局,大家玩着击鼓传花的游戏。到2018年,自己开始从事相关工..._起点下载区块链
文章浏览阅读8.9k次,点赞10次,收藏38次。1、功能需求会签实现多个人同时审批,任意一个人不同意时,会签任务结束,不同意走八戒审批,同意走悟空审批,最后流程结束。流程图如下:绘制流程图:动态设置审批人,完成条件${(pass == 'no')||(nrOfCompletedInstances/nrOfInstances==1)}添加表单字段控件FormProperty_29f662k-_!string-_!审批意见-_!请输入-_!s,需和前端约定,控件解析格式添加执行监听器,任务结束时调用。网关..._activiti7 一个流程同时给多个人审核
文章浏览阅读4.3k次,点赞4次,收藏13次。处理脏数据的方式一般有两种,一是通过sql处理,二是通过代码处理。对于复杂的脏数据,代码处理是最推荐的,通过代码的逻辑,可以准确地控制不同情况,然后针对性测试。所以大多数情况下,开发会偏向于通过sql方式来修复数据,只需要写一个sql到线上环境跑一下(前提是可以写得出来,哈哈),都不需要上线代码,就可以解决根本性问题。本次针对重复性脏数据情况,根据不同需求场景,来通过sql方式处理脏数据。假定通过uid和gid联合作为唯一判断,那么重复的数据有:[1,2],[6,7,8]_mysql 删除重复数据
文章浏览阅读1k次。python3 dataframe中列数据为字典,拆分成多列或转存某个关键字的值文章地址_dataframe的某列是字典解析
文章浏览阅读2.7k次。打开终端(Ubuntu的快捷键Ctrl+Alt+T在这里不适用,可以自定义.但我没找到Run a terminal).使用RPM方式安装:1. wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm(Linux系统中的wget是一个下载文件的工具,用在命令行下,是World,Wide,Web和get..._centos mysql5.7允许远程连接命令
文章浏览阅读1.8k次,点赞16次,收藏27次。使用下载的镜像,启动容器,使用modelscope命令下载。模型:Qwen1.5-Qwen-7B-Chat。镜像:qwenllm/qwen:cu121。【新手入门,多有遗漏,私信交流】文件后缀改为 .py 文件。3、安装langchain。_qwen1.5 部署