HashMap面试题整理-程序员宅基地
一. 存储结构
1.HashMap的底层数据结构是什么?
在JDK1.7 和JDK1.8 中有所差别:
在JDK1.7 中,由“数组+链表”组成,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的。
在JDK1.8 中,由“数组+链表+红黑树”组成。当链表过长,则会严重影响 HashMap 的性能,红黑树搜索时间复杂度是 O(logn),而链表是糟糕的 O(n)。因此,JDK1.8 对数据结构做了进一步的优化,引入了红黑树,链表和红黑树在达到一定条件会进行转换:
首先JDK1.7的HashMap当出现Hash碰撞的时候,最后插入的元素会放在前面,这个称为 “头插法”
在JDK1.8以后,由头插法改成了尾插法,因为头插法还存在一个死链的问题
https://blog.csdn.net/weixin_33977645/article/details/113076222
- 当链表超过 8 且数据总量超过 64 才会转红黑树。
- 将链表转换成红黑树前会判断,如果当前数组的长度小于64,那么会选择先进行数组扩容,而不是转换为红黑树,以减少搜索时间。
2.为什么在解决 hash 冲突的时候,不直接用红黑树?而选择先用链表,再转红黑树?
因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要。当元素小于 8 个的时候,此时做查询操作,链表结构已经能保证查询性能。当元素大于 8 个的时候, 红黑树搜索时间复杂度是 O(logn),而链表是 O(n),此时需要红黑树来加快查询速度,但是新增节点的效率变慢了。
因此,如果一开始就用红黑树结构,元素太少,新增效率又比较慢,无疑这是浪费性能的。
3.不用红黑树,用二叉查找树可以么?
可以。但是二叉查找树在特殊情况下会变成一条线性结构(这就跟原来使用链表结构一样了,造成很深的问题),遍历查找会非常慢。
4.为什么链表改为红黑树的阈值是 8?
首先和hashcode碰撞次数的泊松分布有关,主要是为了寻找一种时间和空间的平衡。在负载因子0.75(HashMap默认)的情况下,单个hash槽内元素个数为8的概率小于百万分之一,将7作为一个分水岭,等于7时不做转换,大于等于8才转红黑树,小于等于6才转链表。链表中元素个数为8时的概率已经非常小,再多的就更少了,所以原作者在选择链表元素个数时选择了8,是根据概率统计而选择的。
5.默认加载因子是多少?为什么是 0.75,不是 0.6 或者 0.8 ?
1、负载因子是1.0
数据一开始是保存在数组里,当发生了Hash碰撞的时候,就是在这个数据节点上,生出一个链表,当链表长度达到一定长度的时候,就会把链表转化为红黑树。
当负载因子是1.0时,也就意味着,只有当数组的8个值(这个图表示了8个)全部填充了,才会发生扩容。这就带来了很大的问题,因为Hash冲突时避免不了的。
后果:当负载因子是1.0的时候,意味着会出现大量的Hash的冲突,底层的红黑树变得异常复杂。对于查询效率极其不利。这种情况就是牺牲了时间来保证空间的利用率。
因此一句话总结就是负载因子过大,虽然空间利用率上去了,但是时间效率降低了。
2、负载因子是0.5
后果:负载因子是0.5的时候,这也就意味着,当数组中的元素达到了一半就开始扩容,既然填充的元素少了,Hash冲突也会减少,那么底层的链表长度或者是红黑树的高度就会降低。查询效率就会增加。
但是,此时空间利用率就会大大的降低,原本存储1M的数据,现在就意味着需要2M的空间。
总之,就是负载因子太小,虽然时间效率提升了,但是空间利用率降低了。
3、负载因子0.75
经过前面的分析,基本上为什么是0.75的答案也就出来了,这是时间和空间的权衡。当然这个答案不是我自己想出来的。
二.索引计算
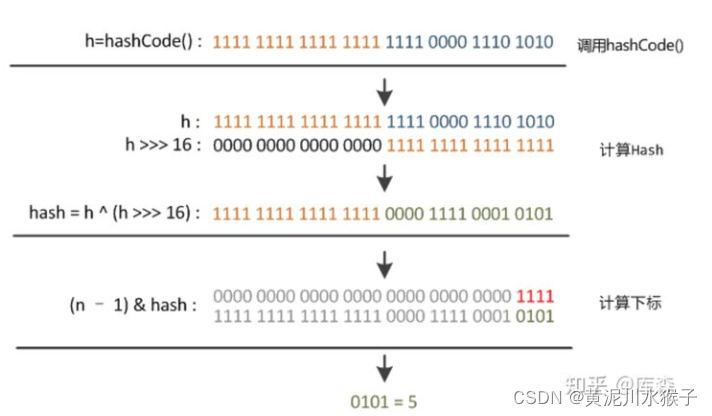
1.JDK1.8 为什么要 hashcode 异或其右移十六位的值?
因为在JDK 1.7 中扰动了 4 次,计算 hash 值的性能会稍差一点点。 从速度、功效、质量来考虑,JDK1.8 优化了高位运算的算法,通过hashCode()的高16位异或低16位实现:(h = k.hashCode()) ^ (h >>> 16)。这么做可以在数组 table 的 length 比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
2.为什么 hash 值要与length-1相与?
把 hash 值对数组长度取模运算,模运算的消耗很大,没有位运算快。
当 length 总是 2 的n次方时,h& (length-1) 运算等价于对length取模,也就是 h%length,但是 & 比 % 具有更高的效率。
3.HashMap数组的长度为什么是 2 的幂次方?
这样做效果上等同于取模,在速度、效率上比直接取模要快得多。除此之外,2 的 N 次幂有助于减少碰撞的几率。如果 length 为2的幂次方,则 length-1 转化为二进制必定是11111……的形式,在与h的二进制与操作效率会非常的快,而且空间不浪费
三.put方法
HashMap 的put方法流程?
简要流程如下:
首先根据 key 的值计算 hash 值,找到该元素在数组中存储的下标;
如果数组是空的,则调用 resize 进行初始化;
如果没有哈希冲突直接放在对应的数组下标里;
如果冲突了,且 key 已经存在,就覆盖掉 value;
如果冲突后,发现该节点是红黑树,就将这个节点挂在树上;
如果冲突后是链表,判断该链表是否大于 8 ,如果大于 8 并且数组容量小于 64,就进行扩容;如果链表节点大于 8 并且数组的容量大于 64,则将这个结构转换为红黑树;否则,链表插入键值对,若 key 存在,就覆盖掉 value。
扩展的问题
JDK1.7 和1.8 的put方法区别是什么?
区别在两处:
解决哈希冲突时,JDK1.7 只使用链表,JDK1.8 使用链表+红黑树,当满足一定条件,链表会转换为红黑树。
链表插入元素时,JDK1.7 使用头插法插入元素,在多线程的环境下有可能导致环形链表的出现,扩容的时候会导致死循环。因此,JDK1.8使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了,但JDK1.8 的 HashMap 仍然是线程不安全的,具体原因会在另一篇文章分析。
扩容机制
HashMap 的扩容方式?
Hashmap 在容量超过负载因子所定义的容量之后,就会扩容。Java 里的数组是无法自动扩容的,方法是将 Hashmap 的大小扩大为原来数组的两倍,并将原来的对象放入新的数组中。
为什么默认初始容量必须是2的n次幂?若创建HashMap传入的initialCapacity不是2的次幂会发生什么?
答:因为(2的次幂数 - 1)的二进制形式表示都是1,这样在和经过异或运算的h进行按位与运算的时候才可以最多地保留其特性,减少产生哈希碰撞的概率,让数组空间均匀分配。
如果传入的initialCapacity不是2的次幂数,则HashMap会通过一通位移运算和或运算得到一个容量比传入的initialCapacity大的最小的2的次幂数,并将其作为HashMap的初始容量。例如传入7得到初始容量为8的HashMap,传入9得到初始容量为16的HashMap。
Hashmap的扩容机制及扩容后元素迁移-resize()
JDK7的元素迁移
JDK7中,HashMap的内部数据保存的都是链表。因此逻辑相对简单:在准备好新的数组后,map会遍历数组的每个“桶”,然后遍历桶中的每个Entity,重新计算其hash值(也有可能不计算),找到新数组中的对应位置,以头插法插入新的链表。
这里有几个注意点:
是否要重新计算hash值的条件这里不深入讨论,读者可自行查阅源码。
因为是头插法,因此新旧链表的元素位置会发生转置现象。
元素迁移的过程中在多线程情境下有可能会触发死循环(无限进行链表反转)。
JDK8的元素迁移
JDK8则因为巧妙的设计,性能有了大大的提升:由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在原长度+原位置的位置。原因如下图:

数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标确定。此时,一个元素通过hash转换坐标的方法计算后,恰好出现一个现象:最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标”。如下图:

因此,在扩容时,不需要重新计算元素的hash了,只需要判断最高位是1还是0就好了。
JDK8的HashMap还有以下细节:
JDK8在迁移元素时是正序的,不会出现链表转置的发生。
如果某个桶内的元素超过8个,则会将链表转化成红黑树,加快数据查询效率。
其他
key 可以为 Null 吗?
可以,key 为 Null 的时候,hash算法最后的值以0来计算,也就是放在数组的第一个位置。
一般用什么作为HashMap的key?
一般用Integer、String 这种不可变类当 HashMap 当 key,而且 String 最为常用。
因为字符串是不可变的,所以在它创建的时候 hashcode 就被缓存了,不需要重新计算。这就是 HashMap 中的键往往都使用字符串的原因。
因为获取对象的时候要用到 equals() 和 hashCode() 方法,那么键对象正确的重写这两个方法是非常重要的,这些类已经很规范的重写了 hashCode() 以及 equals() 方法。
hashmap的初始化
HashMap采用的是懒加载,在创建好map的时候,并没有初始化 Node<K,V>[] tab,在第一次put的时候才会初始化这个tab
任何一个 Object 类型的 hashCode 方法得到的 Hash 值是一个 int 型,Java 中 int 型是 4*8=32 位的
面试题:HashMap如何get一个元素?
题目分析
这一题问的是如何获取HashMap内保存的元素,考察的是HashMap底层原理的掌握。首先要知道,HashMap是如何保存元素的,之后才能够知道如何获取一个元素。
回答
想要在HashMap中获取Get一个元素,需要传入一个Key。
HashMap会计算这个key的哈希值,并对HashMap的容量进行求余,得到以数组的方式保存的数据中,key所对应的位置。
获取到HashMap中key所对应的位置之后,判断那个位置保存的的键的哈希值和键是否等于传入的Key,若相等即找到了想要的元素。
若不相等,表示发生了哈希冲突。需要进一步判断对应位置的对象类型是否为TreeNode,若不是,则表示当前位置保存的是链表,否则,表示当前位置保存的是红黑树。
若保存的是链表,则从链头开始遍历,直到发现链表中的一个的节点上保存的key等于传入的Key。
若保存的是红黑树,则从树中查找节点的key等于传入的key。若查找成功,返回节点保存到值,即为查找结果。
若查找失败,返回null。
HashMap内存内存溢出问题
没用好HashMap,性能影响这么大
hashmap初始化数组时没有初始化容量,只有put第一个元素的时候才会创建数组,属于懒加载
链表变红黑树
链表长度**大于8** 并且数组长度大于64时 链表转红黑树。如果红黑树长度小于6 红黑树转成链表。
为什么是8的时候才扩容?
1、hashMap并不是在链表元素个数大于8就一定会转换为红黑树,而是先考虑扩容,扩容达到默认限制后才转换。
2、hashMap的红黑树不一定小于6的时候才会转换为链表,而是只有在resize的时候才会根据 UNTREEIFY_THRESHOLD 进行转换。
参考
HashMap扩容时究竟对链表和红黑树做了什么?
jdk1.7在头插法会出现死循环。 jdk1.8的HashMap在多线程的情况下也会出现死循环的问题,但是1.8是在链表转换树或者对树进行操作的时候会出现线程安全的问题。
HashMap中的modCount
普通的 HashMap 的负载因子可以修改,但是 ConcurrentHashMap 不可以,因为它的负载因子使用 final关键字修饰,值是固定的 0.75
智能推荐
响应式编程库Reactor 3 Reference Guide参考文档中文版(v3.2.0)-程序员宅基地
文章浏览阅读231次。Project Reactor 是 Spring WebFlux 的御用响应式编程库,与 Spring 是兄弟项目。关于如何基于Spring的组件进行响应式应用的开发,欢迎阅读系列文章《响应式Spring的道法术器》。官方参考文档地址:http://projectreactor.io/docs/core/release/reference/中文翻译文档地址:http://htmlprevi..._reactor 指南中文版v3.0
TeamTalk部署问题及解决方案_teamtalk ../daeml: 没有那个文件或目录-程序员宅基地
文章浏览阅读727次。TeamTalk部署问题及解决方案1、部分源下载地址2、编译安装libiconv报错3、找不到tt4、编译im-server5、缺少daeml6、找不到mysql.h7、centos7 mini 安装后无法连接到网络8、使用mwget提高下载速度9、nginx: [emerg] unknown log format "access" in错误解决方法10、PHP报错1、部分源下载地址gmpwget ftp://ftp.gnu.org/gnu/gmp/gmp-5.1.3.tar.gzmpfrwge_teamtalk ../daeml: 没有那个文件或目录
java中将多文件字节流压缩成zip-程序员宅基地
文章浏览阅读2.4k次。java中将多文件字节流压缩成zip核心就是使用java.util.zip包中的ZipOutputStream直接上核心代码/** * * @param zipFilePath zip保存路径 * @param zipFileName zip文件名 * @param byteList 文件字节码Map,k:fileNam..._java将多个字节流压缩成zip
Python-Django毕业设计在线考试系统(程序+Lw)_django在线考试系统-程序员宅基地
文章浏览阅读141次。该项目含有源码、文档、程序、数据库、配套开发软件、软件安装教程项目运行环境配置:Pychram社区版+ python3.7.7 + Mysql5.7 + HBuilderX+list pip+Navicat11+Django+nodejs。项目技术:django + python+ Vue 等等组成,B/S模式 +pychram管理等等。环境需要1.运行环境:最好是python3.7.7,我们在这个版本上开发的。其他版本理论上也可以。2.pycharm环境:pycharm都可以。_django在线考试系统
Java关键字(二)——native_nativeadd-程序员宅基地
文章浏览阅读612次。 本篇博客我们将介绍Java中的一个关键字——native。 native 关键字在 JDK 源码中很多类中都有,在 Object.java类中,其 getClass() 方法、hashCode()方法、clone() 方法等等都是用 native 关键字修饰的。 public final native Class&l..._nativeadd
【HarmonyOS HiSpark IPC DIY Camera试用连载4 】 鸿蒙OS内核liteos-a如何启动第一个用户进程init_lite_lite_user_sec_entry原理-程序员宅基地
文章浏览阅读2.6k次。【HarmonyOS HiSpark IPC DIY Camera试用连载4 】 鸿蒙OS内核如何启动第一个用户进程init_lite1. 鸿蒙OS编译知识2. 从编译过程看鸿蒙OS代码结构3. 第一个用户态进程init_lite4. Init_lite是如何被kernel调用的?1. 鸿蒙OS编译知识(原理引自中科创达OpenHarmony研究组 鸿蒙OS开源代码精要解读之——init)OpenHarmony源码编译系统使用了google开发的gn工具以及ninjia。这二者结合起来比传统的make_lite_user_sec_entry原理
随便推点
【产品】PRD需求文档:云迹扶教(公益支教APP)_公益类app用户画像描述-程序员宅基地
文章浏览阅读2.2k次。简介:借助CSDN平台发布自己编写的需求文档。参考了前辈们的经验,编写如下(持续更新):正文:PRD:云迹扶教APP产品需求文档一、文档综述1.1版本历史 制订时间 制订人 制订内容 2021.06.13 Max 撰写文档 1.2输出环境 文档名称 云迹扶教A_公益类app用户画像描述
std::string转QString中文乱码_c++ 中文 string 转qstring乱码-程序员宅基地
文章浏览阅读2k次,点赞2次,收藏8次。std::string cstring;QString qstring;//从std::string 到QStringqstring = QString(QString::fromLocal8Bit(cstring.c_str()));//从QString 到 std::stringcstring = std::string((const char *)qstring.toLocal8Bit().constData());_c++ 中文 string 转qstring乱码
html符号中文含义大全特殊,中文标点符号大全名称-程序员宅基地
文章浏览阅读2.6k次。中文的标点符号包括句号,逗号,感叹号,问号,引号,冒号等等,接下来分享常见的中文标点符号名称。常见的中文标点符号1.句号:【。】用于句子末尾,表示陈述语气。有时也可表示较缓和的祈使语气和感叹语气。2.问号:【?】用于句子末尾,表示疑问语气(包括反问、设问等疑问类型)。在多个问句连用或表达疑问语气加重时,可叠用问号。3.叹号:【!】用于句子末尾,主要表示感叹语气,有时也可表示强烈的祈使语气、反问语气..._html顿号
【加密算法】5 种常见的摘要、加密算法_摘要加密-程序员宅基地
文章浏览阅读994次。那么上面提到的这些能力,我们都可以利用哪些加密算法来实现呢?咱们接着往下看。加密算法整体上可以分为:不可逆加密、可逆加密。可逆加密又可以分为:对称加密、非对称加密。_摘要加密
引用形参和指针形参的比较_函数用形参 指针哪个效率高-程序员宅基地
文章浏览阅读1k次。指针与引用看上去完全不同(指针用操作符’*’和’->’,引用使用操作符’.’),但是它们似乎有相同的功能。指针与引用都是让你间接引用其他对象。你如何决定在什么时候使用指针,在什么时候使用引用呢? 首先,要认识到在任何情况下都不能用指向空值的引用。一个引用必须总是指向某些对象。因此如果你使用一个变量并让它指向一个对象,但是该变量在某些时候也可能不指向任何对象,这时你应该把变量声明为指针_函数用形参 指针哪个效率高
0012-用OpenCV批量读取图片的三种方法-程序员宅基地
文章浏览阅读3.3k次。有时我们需要批量读取图片,所以我们有必要知道怎么在OpenCV开源环境下批量读取图片!批量读取图片的关键是如何让程序知道文件夹下图片的名字!第一种方法:这种方法只针对图片名字有规律的情况,比如:***(0).jpg***(1).jpg***(2).jpg***(3).jpg..................源代码如下:代码中用到的图片下载链接为:http://pan.b..._opencv批量读取图片