详解双向链表的基本操作(C语言)_c语言双向链表的移动功能-程序员宅基地
技术标签: 嵌入式软件 C语言 双向链表 双向循环链表 数据结构与算法分析
工科生一枚,热衷于底层技术开发,有强烈的好奇心,感兴趣内容包括单片机,嵌入式Linux,Uboot等,欢迎学习交流!
爱好跑步,打篮球,睡觉。
欢迎加我QQ1500836631(备注CSDN),一起学习交流问题,分享各种学习资料,电子书籍,学习视频等。
1.双向链表的定义
上一节学习了单向链表单链表详解。今天学习双链表。学习之前先对单向链表和双向链表做个回顾。
单向链表特点:
1.我们可以轻松的到达下一个节点, 但是回到前一个节点是很难的.
2.只能从头遍历到尾或者从尾遍历到头(一般从头到尾)
双向链表特点
1.每次在插入或删除某个节点时, 需要处理四个节点的引用, 而不是两个. 实现起来要困难一些
2.相对于单向链表, 必然占用内存空间更大一些.
3.既可以从头遍历到尾, 又可以从尾遍历到头
双向链表的定义:
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。下图为双向链表的结构图。

从上中可以看到,双向链表中各节点包含以下 3 部分信息:
指针域:用于指向当前节点的直接前驱节点;
数据域:用于存储数据元素。
指针域:用于指向当前节点的直接后继节点;

双向循环链表的定义:
双向链表也可以进行首尾连接,构成双向循环链表,如下图所示
在创建链表时,只需要在最后将收尾相连即可(创建链表代码中已经标出)。其他代码稍加改动即可。

双链表的节点结构用 C 语言实现为:
/*随机数的范围*/
#define MAX 100
/*节点结构*/
typedef struct Node{
struct Node *pre;
int data;
struct Node *next;
}Node;
2.双向链表的创建
同单链表相比,双链表仅是各节点多了一个用于指向直接前驱的指针域。因此,我们可以在单链表的基础轻松实现对双链表的创建。
需要注意的是,与单链表不同,双链表创建过程中,每创建一个新节点,都要与其前驱节点建立两次联系,分别是:
将新节点的 prior 指针指向直接前驱节点;
将直接前驱节点的 next 指针指向新节点;
这里给出创建双向链表的 C 语言实现代码:
#define MAX 100
Node *CreatNode(Node *head)
{
head=(Node*)malloc(sizeof(Node));//鍒涘缓閾捐〃绗竴涓粨鐐癸紙棣栧厓缁撶偣锛?
if(head == NULL)
{
printf("malloc error!\r\n");
return NULL;
}
head->pre=NULL;
head->next=NULL;
head->data=rand()%MAX;
return head;
}
Node* CreatList(Node * head,int length)
{
if (length == 1)
{
return( head = CreatNode(head));
}
else
{
head = CreatNode(head);
Node * list=head;
for (int i=1; i<length; i++)
/*创建并初始化一个新结点*/
{
Node * body=(Node*)malloc(sizeof(Node));
body->pre=NULL;
body->next=NULL;
body->data=rand()%MAX;
/*直接前趋结点的next指针指向新结点*/
list->next=body;
/*新结点指向直接前趋结点*/
body->pre=list;
/*把body指针给list返回*/
list=list->next;
}
}
/*加上以下两句就是双向循环链表*/
// list->next=head;
// head->prior=list;
return head;
}
3.双向链表的插入
根据数据添加到双向链表中的位置不同,可细分为以下 3 种情况:
1.添加至表头
将新数据元素添加到表头,只需要将该元素与表头元素建立双层逻辑关系即可。
换句话说,假设新元素节点为 temp,表头节点为 head,则需要做以下 2 步操作即可:
temp->next=head; head->prior=temp;
将 head 移至 temp,重新指向新的表头;
将新元素 7 添加至双链表的表头,则实现过程如下图所示:

版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/qq_16933601/article/details/105351119
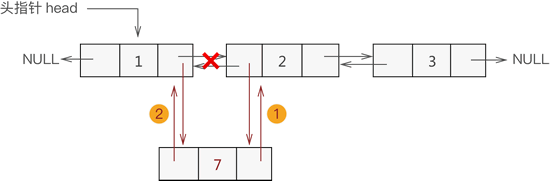
2.添加至表的中间位置
同单链表添加数据类似,双向链表中间位置添加数据需要经过以下 2 个步骤,如下图所示:
新节点先与其直接后继节点建立双层逻辑关系;
新节点的直接前驱节点与之建立双层逻辑关系;
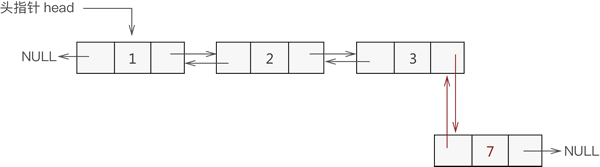
3.添加至表尾
与添加到表头是一个道理,实现过程如下:
找到双链表中最后一个节点;
让新节点与最后一个节点进行双层逻辑关系;
/*在第add位置的前面插入data节点*/
Node * InsertListHead(Node * head,int add,int data)
{
/*新建数据域为data的结点*/
Node * temp=(Node*)malloc(sizeof(Node));
if(temp== NULL)
{
printf("malloc error!\r\n");
return NULL;
}
else
{
temp->data=data;
temp->pre=NULL;
temp->next=NULL;
}
/*插入到链表头,要特殊考虑*/
if (add==1)
{
temp->next=head;
head->pre=temp;
head=temp;
}
else
{
Node * body=head;
/*找到要插入位置的前一个结点*/
for (int i=1; i<add-1; i++)
{
body=body->next;
}
/*判断条件为真,说明插入位置为链表尾*/
if (body->next==NULL)
{
body->next=temp;
temp->pre=body;
}
else
{
body->next->pre=temp;
temp->next=body->next;
body->next=temp;
temp->pre=body;
}
}
return head;
}
/*在第add位置的后面插入data节点*/
Node * InsertListEnd(Node * head,int add,int data)
{
int i = 1;
/*新建数据域为data的结点*/
Node * temp=(Node*)malloc(sizeof(Node));
temp->data=data;
temp->pre=NULL;
temp->next=NULL;
Node * body=head;
while ((body->next)&&(i<add+1))
{
body=body->next;
i++;
}
/*判断条件为真,说明插入位置为链表尾*/
if (body->next==NULL)
{
body->next=temp;
temp->pre=body;
temp->next=NULL;
}
else
{
temp->next=body->pre->next;
temp->pre=body->pre;
body->next->pre=temp;
body->pre->next=temp;
}
return head;
}
4.双向链表的删除
双链表删除结点时,只需遍历链表找到要删除的结点,然后将该节点从表中摘除即可。
例如,删除元素 2 的操作过程如图 所示:

Node * DeleteList(Node * head,int data)
{
Node * temp=head;
/*遍历链表*/
while (temp)
{
/*判断当前结点中数据域和data是否相等,若相等,摘除该结点*/
if (temp->data==data)
{
/*判断是否是头结点*/
if(temp->pre == NULL)
{
head=temp->next;
temp->next = NULL;
free(temp);
return head;
}
/*判断是否是尾节点*/
else if(temp->next == NULL)
{
temp->pre->next=NULL;
free(temp);
return head;
}
else
{
temp->pre->next=temp->next;
temp->next->pre=temp->pre;
free(temp);
return head;
}
}
temp=temp->next;
}
printf("Can not find %d!\r\n",data);
return head;
}
5.双向链表更改节点数据
更改双链表中指定结点数据域的操作是在查找的基础上完成的。实现过程是:通过遍历找到存储有该数据元素的结点,直接更改其数据域即可。
/*更新函数,其中,add 表示更改结点在双链表中的位置,newElem 为新数据的值*/
Node *ModifyList(Node * p,int add,int newElem)
{
Node * temp=p;
/*遍历到被删除结点*/
for (int i=1; i<add; i++)
{
temp=temp->next;
}
temp->data=newElem;
return p;
}
6.双向链表的查找
通常,双向链表同单链表一样,都仅有一个头指针。因此,双链表查找指定元素的实现同单链表类似,都是从表头依次遍历表中元素。
/*head为原双链表,elem表示被查找元素*/
int FindList(Node * head,int elem)
{
/*新建一个指针t,初始化为头指针 head*/
Node * temp=head;
int i=1;
while (temp)
{
if (temp->data==elem)
{
return i;
}
i++;
temp=temp->next;
}
/*程序执行至此处,表示查找失败*/
return -1;
}
7.双向链表的打印
/*输出链表的功能函数*/
void PrintList(Node * head)
{
Node * temp=head;
while (temp)
{
/*如果该节点无后继节点,说明此节点是链表的最后一个节点*/
if (temp->next==NULL)
{
printf("%d\n",temp->data);
}
else
{
printf("%d->",temp->data);
}
temp=temp->next;
}
}
8.测试函数及结果
int main()
{
Node * head=NULL;
//创建双链表
head=CreatList(head,5);
printf("新创建双链表为\t");
PrintList(head);
//在表中第 5 的位置插入元素 1
head=InsertListHead(head, 5,1);
printf("在表中第 5 的位置插入元素 1\t");
PrintList(head);
//在表中第 3 的位置插入元素 7
head=InsertListEnd(head, 3, 7);
printf("在表中第 3 的位置插入元素 7\t");
PrintList(head);
// //表中删除元素 7
head=DeleteList(head, 7);
printf("表中删除元素 7\t\t\t");
PrintList(head);
printf("元素 1 的位置是\t:%d\n",FindList(head,1));
//表中第 3 个节点中的数据改为存储 6
head = ModifyList(head,3,6);
printf("表中第 3 个节点中的数据改为存储6\t");
PrintList(head);
return 0;
}

大家的鼓励是我继续创作的动力,如果觉得写的不错,欢迎关注,点赞,收藏,转发,谢谢!
以上代码均为测试后的代码。如有错误和不妥的地方,欢迎指出。
部分内容参考网络,如有侵权,请联系删除。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/qq_16933601/article/details/105351119
智能推荐
初步解析小程序前端框架vant-ui源码_微信小程序vantpopup源码-程序员宅基地
文章浏览阅读4.9k次,点赞2次,收藏2次。初步解析小程序前端框架vant-ui源码本学期的系统分析课程要求我们做一个小项目,我们以微信小程序为框架进行了项目的前端搭建,在UI上以开源组件库vant-ui为基础进行了设计,其中用到了许多该开源库的设计,对于项目前端起到了很大的帮助。组件库的使用教程在 https://youzan.github.io/vant-weapp/#/intro ,介绍说明比较详细且简单,因此这里不再赘述,这里..._微信小程序vantpopup源码
树状数组上二分-程序员宅基地
文章浏览阅读3.2k次。树状数组+二分考虑一个简单的问题,维护一个数组,支持每次修改一个数的值,保证每时每刻每个数都为非负数。每次查询求前缀和kkk lower_bound 的值。对于修改,可以用树状数组、线段树等数据结构维护。二分查找可以在[l,r][l,r][l,r]的范围上二分答案,mid=⌊l+r2⌋mid = \lfloor \frac{l+r}{2} \rfloormid=⌊2l+r⌋,验证midmidmid的前缀和是否大于kkk,并调整midmidmid。时间复杂度O(log22n)O(log^2_2n)O_树状数组上二分
数据结构——顺序串(定义初始化、赋值、遍历、两串比较)_串的初始化-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏47次。S;串的组成1length用length记录串的长度是为了减少后期的遍历串获取串长度的时间复杂度。如果不设置length的话,每一次获取字符串长度都需要一次循环,时间复杂度为O(n),如果设置了length的话,给串新增字符的过程中就记录当前串的长度,未来需要串的长度的时候直接获取length就可以了,时间复杂度降低为O(1)。2chch是串里的字符串。......_串的初始化
Maven的dependency中无版本号的可能情况_android studio dependencies里没有版本信息-程序员宅基地
文章浏览阅读2.3k次。pom文件的依赖无版本号的可能原因_android studio dependencies里没有版本信息
Logstash:运用 jdbc_streaming 来丰富我们的数据_logstash jdbc_streaming-程序员宅基地
文章浏览阅读2.8k次,点赞4次,收藏7次。在IoT物联网时代,我们经常会遇到从传感器采集数据的情况。这些传感器,可以上传物联网数据,比如温度,湿度。通常这些传感器带有自己的ID,但是它并不具有像地理位置等这样的信息。当物联网数据传到我们的数据平台时,我们希望对采集上来的数据进行数据的丰富,比如我们对物联网的数据加上它所在的位置等信息,这将对我们的数据分析非常有用。这些需要丰富的数据通常会存放于一个关系数据库的表格中,比如MySQL的数据库..._logstash jdbc_streaming
工业数据分析技术与实战之入门——昆仑数据田春华培训听课记录_工业数据分析 实战培训-程序员宅基地
文章浏览阅读512次。田老师发音不标准啊,好多词听好几遍,再关联上下文,连猜带蒙的才勉强能明白,不过有的也不一定对。记录以反复学习。视频链接:https://appgzdr0r6c3350.h5.xiaoeknow.com/v1/course/column/p_5e90181d2f5c2_Ut1xWLXN?type=3&share_user_id=u_5e91169429c27_G0xxVfLReS&share_type=2&scene=%E5%88%86%E4%BA%AB&access_en_工业数据分析 实战培训
随便推点
物联网能为企业带来哪些创新?看看这些成功案例!-程序员宅基地
文章浏览阅读108次。物联网(Internet of Things,IoT)是指通过互联网连接各种设备和物品,使它们能够相互通信和交换数据的网络。在这个数字化时代,物联网已经成为了企业数字化转型的重要驱动力。通过物联网技术,企业可以实现对企业数据的实时监控、数据分析和智能化决策,从而提高企业的效率和效益,实现更高的商业价值。下面,我们将介绍一些成功的物联网应用案例,以帮助您更好地了解物联网的潜力。
阶次跟踪的角域重采样matlab,一种基于包络提取的高精度无键相信号阶次跟踪方法及系统与流程...-程序员宅基地
文章浏览阅读1.7k次。本发明涉及一种基于包络提取的高精度无键相信号阶次跟踪方法及系统,属于故障诊断技术与信号处理分析技术领域。背景技术:传统的阶次齿轮箱故障信号特征提取针对的是恒定转速运转下的测试信号,但对于工程机械等现代大型复杂机械装备中,恶劣的工作环境导致其运行工况复杂,转速和负荷等工况参数的变化将导致其振动信号具有明显的非平稳性,因此其采集的振动信号不直接满足傅里叶变换的平稳性要求。针对此问题出现了阶次跟踪方法,..._matlab阶次跟踪
python高阶知识之——字典/集合推导式_字典推导式 key自增怎么写-程序员宅基地
文章浏览阅读205次。什么是推导式:推导式是用来快速的生成数据1、推导式类型2、字典推导式推导式结合条件语句语法:dict = { key:value for i in xxx if 条件}推导式结合三元运算符语法:dict = { key:value if 条件 else key2:value2 for i in xxx}3、字典推导式原则4、注意事项5、集合推导式......_字典推导式 key自增怎么写
C语言经典编程之字符串_char ch : input-程序员宅基地
文章浏览阅读1.5k次,点赞6次,收藏18次。C语言经典编程之字符串:按特定顺序输出压缩,IP地址判断是否合法,字符串压缩、解压、排序,查找相同的字串,单词升序排列,统计单词个数,Objective-C和C++命名之争,字符串删除、插入、替换、抽取、交换、拼接、分割,统计字母在字符串中出现的次数等。_char ch : input
EXCEL高级技巧_在exce设置t形-程序员宅基地
文章浏览阅读917次。也许你已经在Excel中完成过上百张财务报表,也许你已利用Excel函数实现过上千次的复杂运算,也许你认为Excel也不过如此,甚至了无新意。但我们平日里无数次重复的得心应手的使用方法只不过是Excel全部技巧的百分之一。本专题从Excel中的一些鲜为人知的技巧入手,领略一下关于Excel的别样风情。 一、让不同类型数据用不同颜色显示 在工资表中,如果想让大于等于2000元_在exce设置t形
java解析xml文件_java 解析 xml 版本2.0-程序员宅基地
文章浏览阅读1.4w次,点赞7次,收藏33次。java解析xml常用的2种方法第一种 dom解析第二种 dom4j解析<?xml version="1.0" encoding="UTF-8"?><books> <book id="001"> <id>9</id> <title>Harry Potter</title> <author>J K. Rowling</author> </bo_java 解析 xml 版本2.0