Hadoop3与Hadoop2及Spark比较_hadoop3 vs hadoop2-程序员宅基地
技术标签: spark hadoop3 大数据 hadoop2
2017年12月发布的Hadoop 3标志着数据科学新时代的开始。Hadoop框架是整个Hadoop生态系统的核心,其他各种库都依赖它。
在本文中,我们将讨论Hadoop 3与Hadoop 2相比的主要变化。我们还将解释Hadoop和Apache Spark之间的差异,并建议如何为您的特定任务选择最佳工具。
概要
Hadoop 2和Hadoop 3是用Java开发的数据处理引擎,分别于2013年和2017年发布。创建Hadoop的主要目标是维护磁盘上的数据分析,称为批处理。因此,原生Hadoop不支持实时分析和交互性。
Spark 2.X是Scala开发的处理和分析引擎,于2016年发布。对信息的实时分析变得至关重要,因为许多巨型互联网服务强烈依赖于立即处理数据的能力。因此,Apache Spark是为实时数据处理而构建的,现在很受欢迎,因为它可以在交互模式下有效地处理实时信息流和处理数据。
Hadoop和Spark都是开源的,Apache 2许可。
抽象程度和学习和使用的难度
这些框架之间的主要区别之一是抽象级别,Hadoop低,Spark高。因此,Hadoop的学习和使用更具挑战性,因为开发人员必须知道如何编写大量基本操作。Hadoop只是核心引擎,因此使用高级功能需要其他组件的插件,这使得系统更加复杂。
与Hadoop不同,Apache Spark是一个完整的数据分析工具。它具有许多有用的内置高级功能,可以使用弹性分布式数据集(RDD) - Spark中的核心概念。该框架包含许多有用的库。例如,MLlib允许使用机器学习,Spark SQL可用于执行SQL查询等。
硬件和成本
Hadoop适用于磁盘,因此无需大量RAM即可运行。这可能比拥有大RAM便宜。由于容错提供系统的变化,Hadoop 3比Hadoop 2需要更少的磁盘空间。
Spark需要大量RAM才能在内存模式下运行,因此总成本可能比Hadoop更昂贵。
支持编程语言
两个版本的Hadoop都支持使用Hadoop Streaming的几种编程语言,但主要的是Java。Spark 2.X支持Scala,Java,Python和R。
速度
通常,Hadoop比Spark慢,因为它适用于磁盘。Hadoop无法将数据缓存在内存中。由于向MapReduce添加了map输出收集器的原生Java实现,Hadoop 3的工作速度比Hadoop 2快30%。
Spark在处理内存中信息,所以可以比Hadoop快100倍。如果使用磁盘,Spark比Hadoop快10倍。
安全
由于使用了Kerberos(计算机网络身份验证协议)和访问控制列表(ACL)的支持,Hadoop被认为比Spark更安全。Spark依次使用共享密码提供身份验证。
容错
Hadoop 2中的容错是由复制技术提供的,其中复制每个信息块以创建2个副本。这意味着Hadoop 2存储的信息不是存储1条信息,而是存储3条信息。这引起了浪费磁盘空间的问题。
在Hadoop 3中,通过擦除编码提供容错。该方法允许使用另一个块和奇偶校验块来恢复信息块。Hadoop 3在每两个数据块上创建一个奇偶校验块。这需要的磁盘空间仅为1.5倍,而Hadoop 2中的复制次数则为3倍.Hadoop 3中的容错级别保持不变,但其操作所需的磁盘空间更少。
Spark可以通过重新计算DAG(有向无环图)来恢复信息。DAG由顶点和边形成。顶点表示RDD,边表示RDD上的操作。在某些部分数据丢失的情况下,Spark可以通过将操作序列应用于RDD来恢复它。请注意,每次需要重新计算RDD时,都需要等到Spark执行所有必要的计算。Spark还创建了检查点以防止故障。
YARN版
Hadoop 2使用YARN版本1. YARN(Yet Another Resource Negotiator)是资源管理器。它管理可用资源(CPU,内存,磁盘)。此外,YARN执行作业调度。
YARN在Hadoop 3中更新为版本2.有几个重大变化提高了可用性和可伸缩性。YARN 2支持流 - YARN应用程序的逻辑组,并在流级别提供聚合度量。收集过程(写入数据)和服务过程(读取数据)之间的分离提高了可伸缩性。此外,YARN 2使用Apache HBase作为主要后备存储。
Spark可以在具有YARN的群集上独立运行,也可以与Mesos一起运行。
NameNodes的数量
Hadoop 2支持整个命名空间的单活动NameNode和单备用NameNode,而Hadoop 3支持多个备用NameNode。
Spark在管理SparkContext的主节点上运行驱动程序。
文件系统
主要的Hadoop 2文件系统是HDFS - Hadoop分布式文件系统。该框架还兼容其他几个文件系统,如Amazon S3和Azure存储的Blob存储,以及分布式文件系统。
Hadoop 3支持所有文件系统,如Hadoop 2.此外,Hadoop 3 与Microsoft Azure Data Lake和Aliyun对象存储系统兼容。
Spark支持本地文件系统,Amazon S3和HDFS。
为方便起见,我们创建了一个表格,总结了上述所有信息,并简要比较了两个版本的Hadoop和Spark 2.X的关键参数。
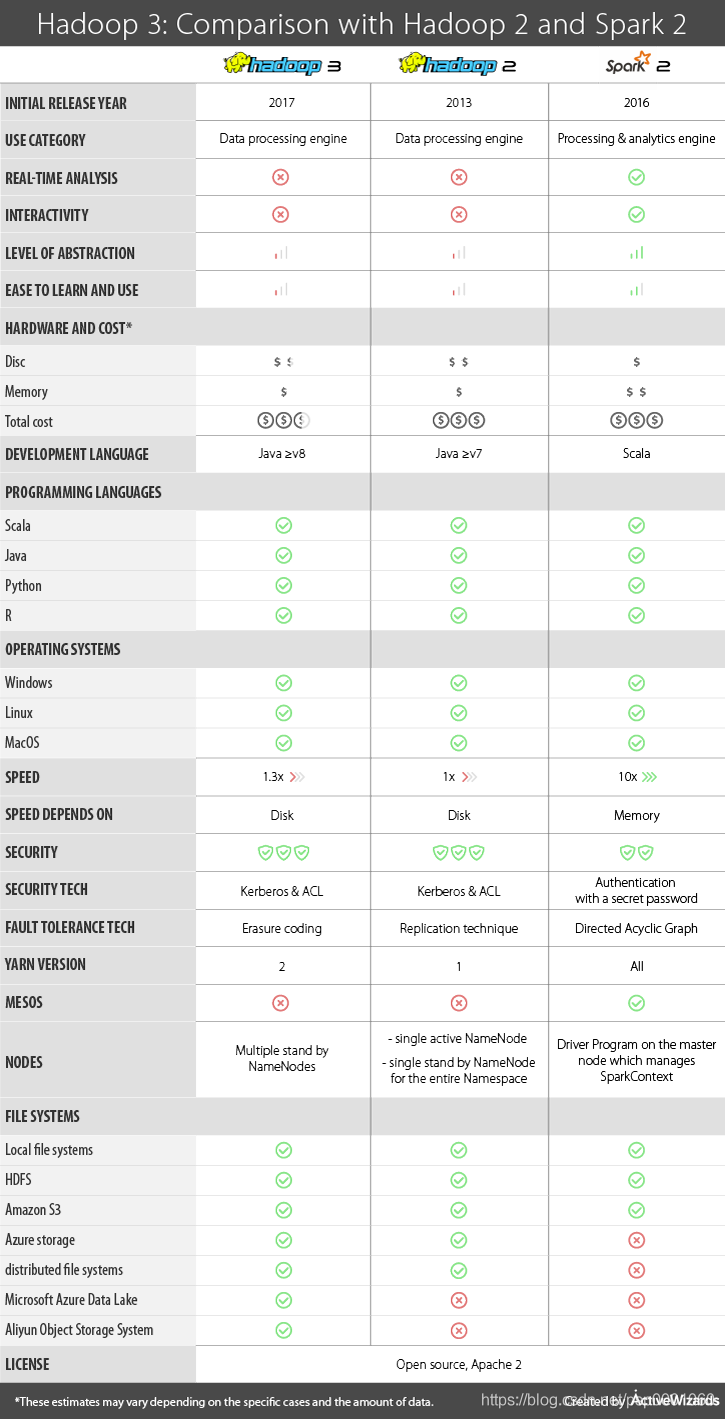
结论
Hadoop 3和2之间的主要区别在于新版本提供了更好的优化和可用性,以及某些体系结构改进。
Spark和Hadoop主要在抽象层次上有所不同。Hadoop被创建为处理大量现有数据的引擎。它具有较低的抽象级别,允许执行复杂的操作,但可能导致学习和管理困难。Spark更容易,更快捷,具有许多方便的高级工具和功能,可以简化您的工作。Spark在Hadoop之上运行,并且拥有许多优秀的库,如Spark SQL或机器学习库MLlib。总而言之,如果您的工作不需要特殊功能,Spark可能是最合理的选择。
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象