faster rcnn解读【原理篇】-程序员宅基地
技术标签: 《deep learning for computer vi
看了DL4CV的第三卷的15章faster rcnn之后,收获很多,特此做一下记录
一.RCNN

RCNN一共分为四步:
step1:输入图片
step2:采用selective search的方法获取潜在的roi,一共提取了2000个潜在roi,然后放入conv当中进行训练
step3:使用迁移学习【用到了conv层】方法,提取step2的特征,从而获得最终的roi
step4:使用SVM来进行物体分类
注:
RCNN算法使用了selective search用来提取潜在的roi区域,而非使用sliding window+图像金字塔的方法,也就是:seletive search是智能版的sliding window。
二.fast rcnn

fast rcnn一共分为四步:
step1:输入图片+ground truth
step2:提取图像特征,使用selective search的方法来进行提取潜在roi区域,将结果传入step 3
step3:通过roi pooling 来获取最终的roi区域。使用roi pooling层之后的结果是一个固定大小的roi 区域{ 这个收到了SPPnet的启发,通过引入金字塔池化通过max pooling固定了roi区域,从而不需要将图片resize成为固定大小再去训练}
step4:将step3的输出,作为step4的输入,分为两个部分。第一部分用于分类,第二部分用于定位检测
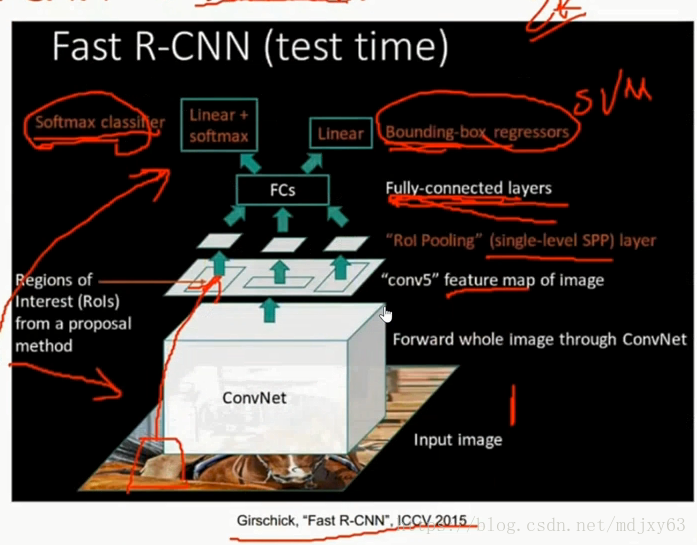
注:fast rcnn相比于rcnn有2个贡献:
1)第一次使用end to end结构进行检测,具体体现在:最终的输出:分为两个部分。第一部分用于分类,【得益于引入了全连接层】,第二部分用于定位检测
2)引入了roi pooling层,使得roi 区域的大小固定
3)与rcnn不同的是:fast rcnn先进行conv层,然后再进行selective search提取潜在roi,而rcnn先使用selective search提取出2000个潜在roi,然后再送人conv中,这样速度就慢很多
三.faster rcnn
因为fast rcnn使用了selective search的方法,因此检测速度取决于selective search的效率,所以faster rcnn的唯一的贡献是,使用RPN layer来代替selective search,大大的提高了region proposal的效率。
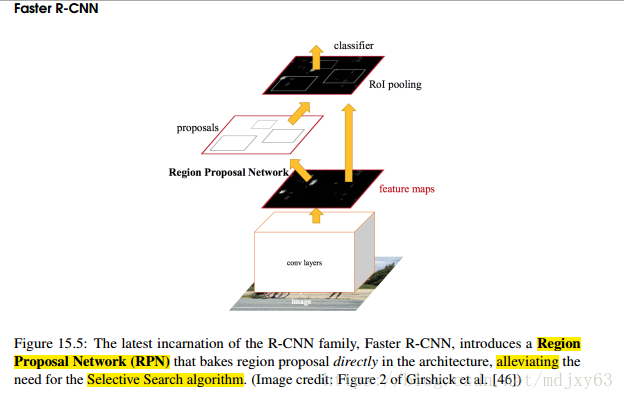
RPN仅仅是定位物体潜在区域,并不会输出该区域的类别,是确定roi区域的stage1。输出是物体的概率值,用来做二分类【前景和背景】,如果被认为是背景,直接被过滤掉,如果是前景,那么继续放入到roi pooling当中
roi pooling层,用来精细化roi区域位置,是确定roi区域的第二阶段,也是最后一步,然后将roi区域作为输入分别放到分类+定位两个分支
=======================================================================
参考这篇文章:https://www.cnblogs.com/hellocwh/p/8671029.html
Faster RCNN在Fast RCNN上更进一步,将Region Proposal也用神经网络来做,如果说Fast RCNN的最大贡献是ROI pooling layer和Multi task,那么RPN(Region Proposal Networks)就是Faster RCNN的最大亮点了。使用RPN产生的proposals比selective search要少很多(300vs2000)候选框要少很多,计算量大大减少,因此也一定程度上减少了后面detection的计算量。
Introduction
Fast RCNN之后,detection的计算瓶颈就卡在了Region Proposal上。一个重要原因就是,Region Proposal是用CPU算的,但是直接将其用GPU实现一遍也有问题,许多提取规则其实是可以重用的,因此有必要找一种能够共享算力的GPU版Region Proposal。
Faster RCNN则是专门训练了一个卷积神经网络来回归bounding box,从而代替region proposal。这个网络完全由卷积操作实现,并且引入anchor以应对对象形状尺寸各异的问题,测试速度与Fast RCNN相比速度极快。
这个网络叫做region proposal layer.
RPN

训练数据就是图片和bounding box
- 输入任意尺寸的图片,缩放到(800×600)作为输入
- 输入到一个基础卷积神经网络,比如ZF或者VGG,以ZF为例,得到一个51×39的feature map
- 用一个小的网络在feature map上滑窗,算每个3x3窗口的feature,输出一个长度为256的向量,这个操作很自然就是用3×3卷积来实现,于是可以得到一个51×39×256的feature map
-
每个256向量跟feature map上一个3×3窗口对应,也跟800×600的原图上9个区域相对应,具体讲一下这个9个区域:
- 卷积后feature map上的每个3x3的区域对应原图上一个比较大的感受野,用ZF做前面的卷积层,感受野为171×171,用VGG感受野为228×228
- 我们想用feature map来判断它的感受野是否是前景,但是对象并不总是正方形的(因此我们需要将128,256,512;分别与1:1,1:2,2:1做3*3的anchor,生成不同比例的前景区域),于是我们需要对感受野做一个替换
- 我们让每个3x3的区域(图中橙色方格【window3*3】)和原图上九个区域相对应,这九个区域的中心(灰色方格)就是3x3对应原图区域的中心
- 九个区域有九种尺寸分别是
128x128 128x64 64x128
256x256 256x128 128x256
512x512 512x256 256x512- 这九个区域我们也称为9个anchor,或者9个reference box
- 如此,每个特征就能和原图上形状和尺寸各异的区域对应起来了
- 回到刚刚的256向量,将这个向量输入一个FC,得到2x9个输出【上图右半部分的橙色部分】,代表9个anchor为前景还是背景的概率
- 学习用的标签设置:如果anchor与真实bounding box重叠率大于0.7,就当做是前景,如果小于0.3,就当做背景
- 将256向量输入另一个FC,得到4x9个输出,代表9个anchor的修正后的位置信息(x,y,w,h)【上图右半部分的蓝色区域】
- 学习用的标签就是真实的bounding box,用的还是之前Faster RCNN的bounding box regression
两个FC在实现的时候是分别用两个1x1卷积实现的
以橙色为例,256向量和W1矩阵相乘,得到长度为18的向量,这样的操作在51x39个feature都要做一遍,实现起来就很自然变成了用一个1x1的卷积核在feature map上做卷积啦,这样也暗含了一个假设,不同位置的slide window对于anchor的偏好是相同的,是一个参数数量与精度的权衡问题。

- 于是我们会得到图片上51x39x9≈20K个anchor为前景的概率【背景过滤掉了】,以及修正后的位置
上面这个过程可以完全独立地训练,得到一个很好的Region Proposal Network
理论上我们可以用上面这个流程去训练RPN,但训练RPN的时候,一个batch会直接跑20K个anchor开销太大了。
- 因此每个batch是采一张图里的256个anchor来训练全连接层和卷积层;
- 这256个anchor里正负样本比例为1:1,正样本128个,负样本128个,
- 如果正样本不足128个,用负样本填充,这也意味着并非所有的背景anchor都会拿来训练RPN,因为前景的anchor会远少于背景的anchor,丢掉一些背景anchor才能保证样本平衡。
- 具体实现上,先算所有anchor,再算所有anchor与bounding box的重叠率,然后选择batch中的256个anchor,参与训练。同一张图会多次参与训练,直到图中的正anchor用完。【每次训练,同一张图用不同的256个anchor进行训练】
因此最终的一个mini batch的训练损失函数为:

其中,
- pi是一个batch中的多个anchor属于前景/后景的预测概率向量,ti是一个batch中正anchor对应的bounding box位置向量
- Lcls是softmax二分类损失【前景和背景】
- Lreg跟Fast RCNN中的bounding box regression loss一样,乘一个pi*,意味着只有前景计算bounding box regression loss
- 论文中说Ncls为256,也就是mini-batch size,Nreg约为256*9=2304(论文中说约等于2400),这意味着一对p对应9个t,这种对应关系也体现在全连接层的输出个数上,由于两个task输出数量差别比较大,所以要做一下归一化。
但这就意味着loss中的mini-batch size是以3x3的slide window为单位的,因为只有slide window和anchor的个数才有这种1:9的关系,而挑选训练样本讲的mini-batch size却是以anchor为单位的,所以我猜实际操作是这样的:
- 先选256个anchor,
- 然后找它们对应的256个slide window,
- 然后再算这256个slide window对应的256×9个anchor的loss,每个slide window对应一个256特征,有一个Lcls,同时对应9个anchor,有9个Lreg
论文这里讲得超级混乱:

Proposal layer
其实这也可以算是RPN的一部分,不过这部分不需要训练,所以单独拉出来讲
- 接下来我们会进入一个proposal layer,根据前面得到的这些信息,挑选region给后面的fast rcnn训练
- 图片输入RPN后,我们手头的信息:anchor,anchor score,anchor location to fix
- 用全连接层的位置修正结果修正anchor位置
- 将修正后的anchor按照前景概率从高到底排序,取前6000个
- 边缘的anchor可能超出原图的范围,将严重超出边缘的anchor过滤掉

- 对anchor做非极大抑制,跟RCNN一样的操作
- 再次将剩下的anchor按照anchor score从高到低排序(仍然可能有背景anchor的),取前300个作为proposals输出,如果不足300个就…也没啥关系,比如只有100个就100个来用,其实不足300个的情况很少的,你想Selective Search都有2000个。
Fast RCNN
接下来就是按照Fast RCNN的模式来训练了,我们可以为每张图前向传播从proposal_layer出来得到300个proposals,然后
- 取一张图的128个proposal作为样本,一张图可以取多次,直到proposal用完

- 喂给Fast RCNN做分类和bounding box回归,这里跟RPN很像,但又有所不同,
- BB regressor:拟合proposal和bounding box,而非拟合anchor和bounding box
- Classifier:Object多分类,而非前景背景二分类
迭代训练
RPN和Fast RCNN其实是很像的,因此可以一定程度上共享初始权重,实际训练顺序如下(MATLAB版):
- 先用ImageNet pretrain ZF或VGG
- 训练RPN
- 用RPN得到的proposal去训练Fast RCNN
- 用Fast RCNN训练得到的网络去初始化RPN
- 冻结RPN与Fast RCNN共享的卷积层,Fine tune RPN
- 冻结RPN与Fast RCNN共享的卷积层,Fine tune Fast RCNN
论文中还简单讲了一下另外两种方法:
- 将整个网络合起来一块训练,而不分步,但由于一开始训练时RPN还不稳定,所以训练Fast RCNN用的proposal是固定的anchor,最后效果差不多,训练速度也快。

- 整个网络合起来一起训练,不分步,训练Fast RCNN用的proposals是RPN修正后的anchor,但这种动态的proposal数量不好处理,用的是一种RoI warping layer来解决,这又是另一篇论文的东西了。
SUMMARY
网络结构和训练过程都介绍完了,实验效果也是依样画葫芦,就不再介绍了,整体来说,Faster RCNN这篇论文写得很乱,很多重要的细节都要去看代码才能知道是怎么回事,得亏是效果好才能中NIPS。。
=========================
mask rcnn提出了roi align,效果比roi pooling要好,因为roi pooling取了两次整数,损失精度
http://blog.leanote.com/post/afanti/b5f4f526490b
===================================
这里参考两张图,对于faster rcnn的网络结构写的很清楚,代码参考陈云的simple faster rcnn
转载自:https://www.cnblogs.com/king-lps/p/8981222.html
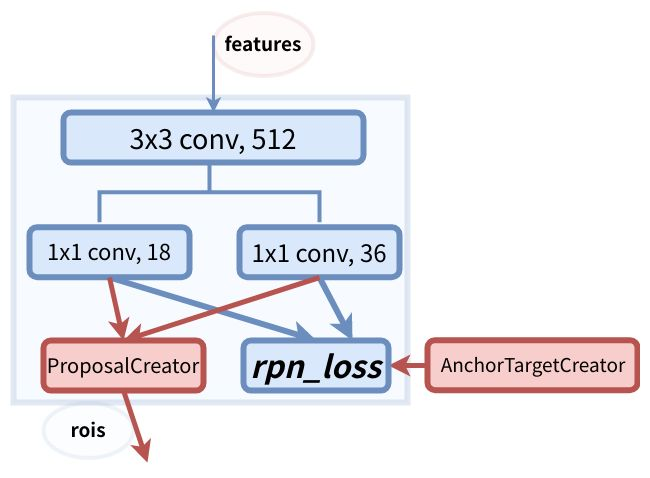
流程说明:features是vgg的conv5_3进行特征提取,然后经过3*3的conv转化一下channel,然后进行分支,9*2=18表示9个anchor的正负样本cls.9*4=36表示9个anchor的坐标。AnchorTargetCreator传入gt_bbox,anchor通过与gt_bbox进行iou计算,输出256个正负样本的gt_rpn_loc,gt_rpn_label:,与上面的1*1conv产生的预测值一起计算rpn_loss。ProposalCreator将20k个anchor经过iou筛选之后剩余2k个anchor,在经过坐标变换之后生成2k个roi
ps:这里正样本表示max iou>=0.7的区域[label=1],负样本表示max iou <=0.3的区域[label=0],还有一个类别是背景,label=-1
详见AnchorTargetCreator的前向传播函数
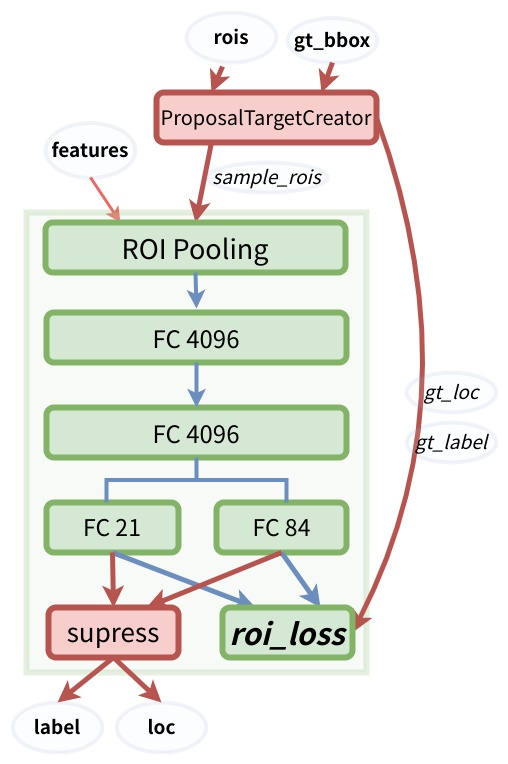
rois是ProposalCreator生成的,gt_bbox是原图的gt,经过ProposalTargetCreator之后,生成gt_loc,gt_label,以及2k个roi,将2k个roi筛选为128个sample rois.128个sample rois结合features传入roi pooling。gt_loc与gt_label,结合后面的FC层的预测结果,产生roi_loss
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象