ES(Elasticsearch)入门学习教程_elasticsearch菜鸟教程-程序员宅基地
Elasticsearch 入门学习教程
- 0x02 参考链接
1.1 为什么要学Elasticsearch
为什么要学Elasticsearch(ES)
我想这是一个存留于很多初学者内心比较困惑的问题。
但是在回答之前,我们还需要先大致了解下它是啥。
毕竟如果一个技术你都不了解它是啥,何谈为什么要学它?
那么, 什么是ES呢?
Elasticsearch 简称ES, 经常与Logstash 和Kibana 一起使用,江湖人称ELK.
- 这E 自然指的就是Elasticsearch,简称ES, 具有分布式存储,搜索和分析的功能。
- L 指的就是Logstash,分布式日志收集框架
- K 指的就是Kibana,可视化分析框架。
接下来我们聊聊为什么我们要学传说中的ES。
这个问题的本质其实是ES 可以做啥?回答清楚这个问题,问题的答案自然就有了。
我翻开了官方文档,在网络中流浪,终于寻找到了答案。
其中分享一些经典的使用案例如下:
- 使用案例一:
ELK 结合使用,用于微服务架构下不同机器上微服务的日志聚合,日志分析。- 使用案例二:
当我们打开淘宝,京东,等电商网站的时候,尝试输入一些关键词,然后系统就会给我们提供一些搜索建议。
这种场景其实也是ES 使用的一个经典案例。- 使用案例三:
Github使用Elasticsearch检索1300亿行的代码- 使用案例四:
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-as-you-type)和搜索纠错(did-you-mean)等搜索建议功能。- 使用案例五:
StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案
1.2 如何下载安装使用ES
ES 官网: https://www.elastic.co/cn/
1.2.1 ES 安装使用条件
ES 的安装需要JDK 8+
- 下载地址一:Oracle JDK 英文官网下载
- 下载地址二:JDK中文网下载
- 下载地址三:Open JDK

1.2.2 ES 下载须知
如果是企业需要注意的是ES 的下载安装包默认包含一个基础的免费许可证,它包含开源和免费的部分商业功能。
如果想30天试用一些完整的付费商业功能,可以去这里申请,传送门
关于免费和付费版本的区别见:

1.2.3 ES 官方下载
- 我们可以从 Download Elasticsearch获取最新的ES 官方下载安装包。
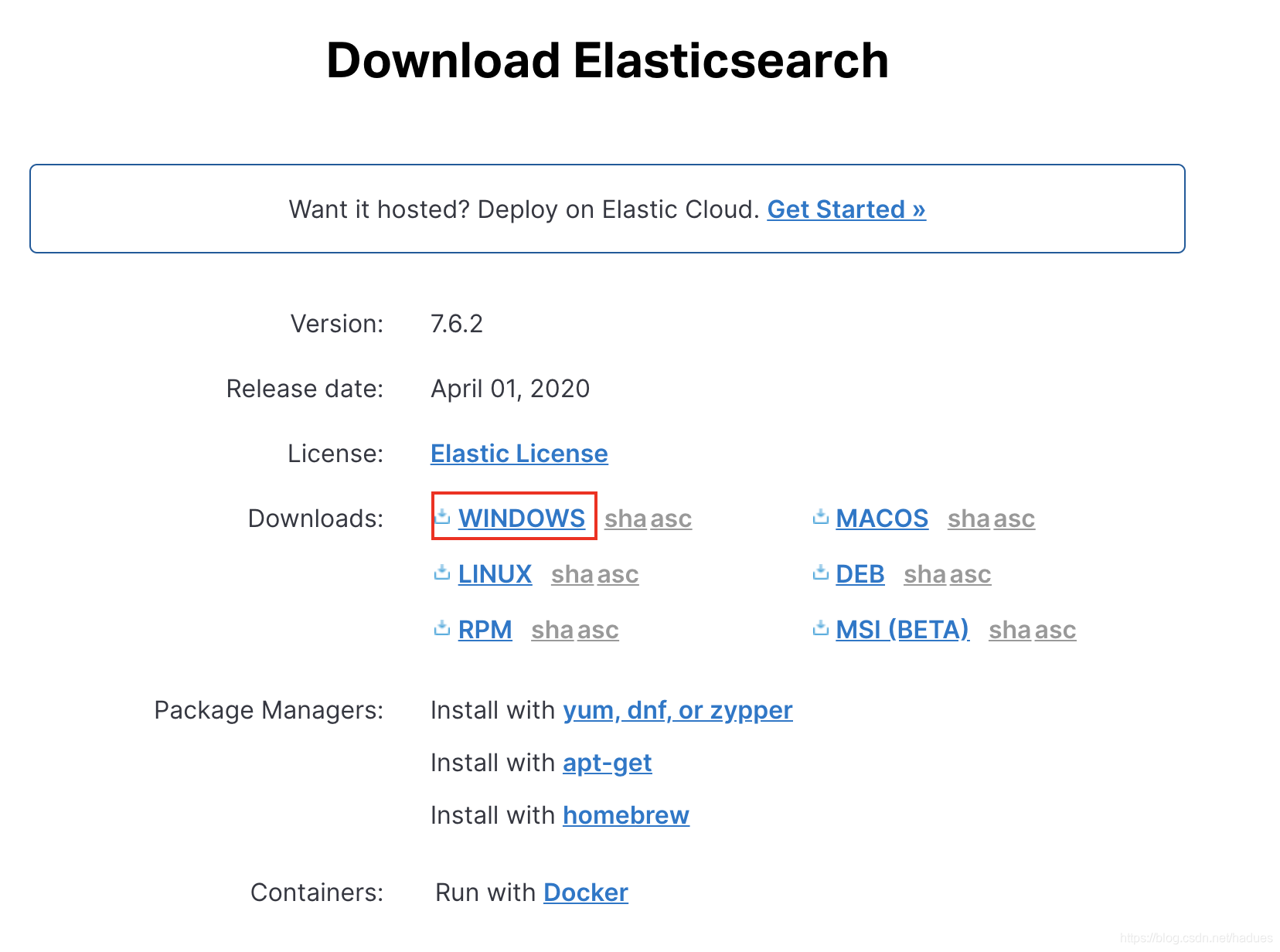
1.2.3.1 Windows 系统下载安装
Windows 系统可以直接点击下图中WINDOWS 超链接 即可下载安装包。
1.2.3.1 Mac OSX 系统下载安装
Mac OSX 自带了HomeBrew ,因此可以通过包管理器方式进行下载安装。
-
首先输入命令:
brew tap elastic/tap
-
然后输入命令:
brew install elastic/tap/elasticsearch-full
当然Mac OSX 系统也可以通过输入如下命令进行下载安装
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-darwin-x86_64.tar.gz
解压命令如下:
tar -xzf elasticsearch-7.6.2-linux-x86_64.tar.gz
- 或点击进行直接下载
1.2.3.2 Docker方式下载安装
除了上面列举的方法之外,使用Docker 下载安装是一个更棒的选择。
-
首先需要安装好Docker,如果没有安装可以查看Docker 入门学习教程
-
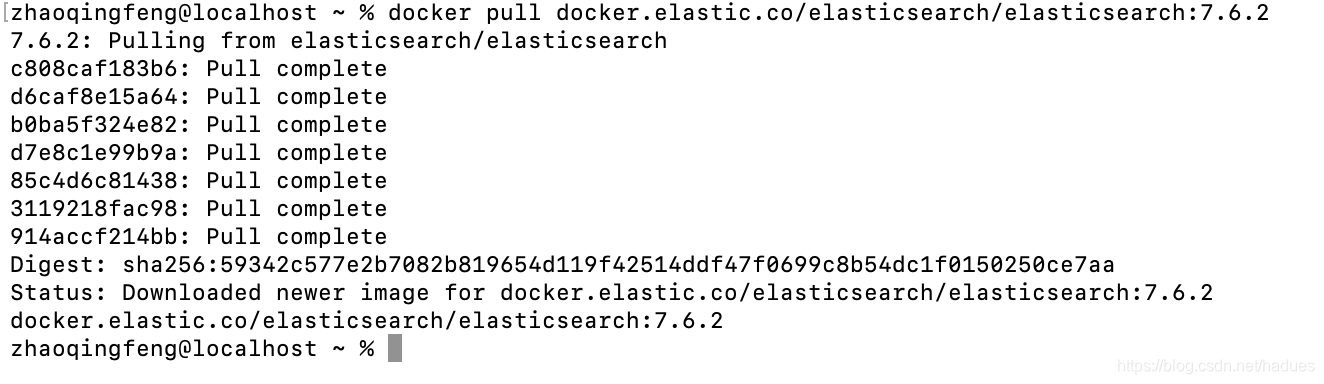
然后输入如下命令从远程Docker仓库下载ES
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.6.2
执行成功如下图所示:
1.2.4 使用Docker 启动ES单节点实例
上面通过Docker 安装好ES之后我们可以通过输入如下命令启动一个单节点的ES实例:
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.6.2
运行成功如下所示:

-
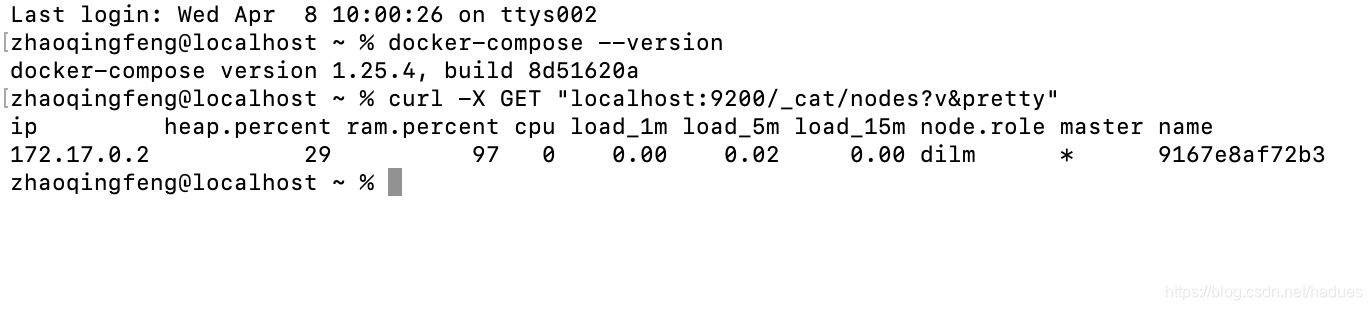
输入如下命令调用接口测试
curl -X GET “localhost:9200/_cat/nodes?v&pretty”
执行成功后输出内容如下:
Mac OSX 自带了curl命令,Windows用户如果也想用可以点击下载并配置环境变量
1.2.5 使用Docker启动ES多节点实例
-
为了方便文件管理,我们首先在
/Users/zhaoqingfeng/documents/app目录下创建一个叫做es 的文件夹
Mac OSX 可以通过输入mkdir es命令进行创建,Windows 可以图形用户界面创建即可。 -
创建一个docker-compose.yml 配置文件内容如下:
version: ‘2.2’
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- “ES_JAVA_OPTS=-Xms512m -Xmx512m”
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- “ES_JAVA_OPTS=-Xms512m -Xmx512m”
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- “ES_JAVA_OPTS=-Xms512m -Xmx512m”
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elasticvolumes:
data01:
driver: local
data02:
driver: local
data03:
driver: localnetworks:
elastic:
driver: bridge -
输入如下命令启动集群
docker-compose up
这里科普下
docker-compose的用法
- 格式为
docker-compose up [options] [SERVICE...]- 该命令可以自动完成包括构建镜像,(重新)创建服务,启动服务,并关联服务相关容器的一系列操作
docker-compose up启动的容器都在前台,方便调试和查看- 如果想后台启动它,可以通过输入如下命令
bash docker-compose up -d
-
执行一个Restful API 请求测
curl -X GET “localhost:9200/_cat/nodes?v&pretty”
-
执行成功如下

1.2.6 ES 在生产环境配置
1.2.6.1 vm.max_map_count 必须至少设置262144
- Linux 服务器
首先需要编辑这个/etc/sysctl.conf文件
grep vm.max_map_count /etc/sysctl.conf
vm.max_map_count=262144
vm.max_map_count至少要设置26214
然后如果想要配置立即生效,需要输入如下命令
sysctl -w vm.max_map_count=262144
1.2.6.2 elasticsearch 用户必须拥有读取配置文件权限
默认情况下,Elasticsearch使用uid:gid 1000:0作为elasticsearch用户在容器内运行。
如果您要绑定安装本地目录或文件,则elasticsearch用户必须可以读取它。 此外,该用户必须对数据和日志目录具有写权限。 一个好的策略是授予组对本地目录的gid 0的访问权限。
例如,要准备一个本地目录以通过绑定安装存储数据:
mkdir esdatadir
chmod g+rwx esdatadir
chgrp 0 esdatadir
作为最后的选择,您可以通过环境变量TAKE_FILE_OWNERSHIP强制容器更改用于数据和日志目录的任何绑定安装的所有权。 执行此操作时,它们将由uid:gid 1000:0拥有,它提供对Elasticsearch进程的必需读/写访问权限。
1.2.6.3 增加nofile和nprocedit的ulimit
nofile和nproc的增加的ulimit必须对Elasticsearch容器可用。
验证Docker守护程序的初始化系统是否将它们设置为可接受的值。
要检查Docker守护程序默认值是否为ulimits,请运行:
docker run --rm centos:7 /bin/bash -c 'ulimit -Hn && ulimit -Sn && ulimit -Hu && ulimit -Su'
如果需要,请在守护程序中调整它们,或对每个容器覆盖它们。 例如,当使用docker run时,设置:
--ulimit nofile=65535:65535
1.2.6.4 禁用交换
为了性能和节点稳定性,需要禁用交换。 有关执行此操作的方法的信息,请参阅禁用交换。
如果您选择bootstrap.memory_lock:true方法,则还需要在Docker Daemon中定义memlock:true ulimit,或为示例组成文件中所示的容器显式设置。 使用docker run时,您可以指定:
-e "bootstrap.memory_lock=true" --ulimit memlock=-1:-1
1.2.6.5 随机发布已发布的端口
该映像公开了TCP端口9200和9300。对于生产集群,建议使用–publish-all将发布的端口随机化,除非您要为每个主机固定一个容器。
1.2.6.6 设置堆大小
使用ES_JAVA_OPTS环境变量来设置堆大小。
例如,要使用16GB,请在运行docker run时指定-e ES_JAVA_OPTS="-Xms16g -Xmx16g。 请注意,尽管默认配置文件jvm.options设置了1GB的默认堆,但是您在ES_JAVA_OPTS中设置的任何值都将覆盖它。
即使要限制对容器的内存访问,也必须配置堆大小。
虽然建议通过环境变量设置堆大小,但也可以通过将自己的jvm.options文件绑定安装在/usr/share/elasticsearch/config/下来进行配置。
Elasticsearch提供的文件包含一些重要的设置,因此您应该首先从Elasticsearch容器中获取jvm.options的副本,然后根据需要对其进行编辑。
1.2.6.7 将部署固定到特定的映像版本
将您的部署固定到Elasticsearch Docker映像的特定版本。
例如docker.elastic.co/elasticsearch/elasticsearch:7.6.2。
1.2.6.8 始终绑定数据卷
出于以下原因,您应该使用/ usr / share / elasticsearch / data上绑定的卷:
如果容器被杀死,您的Elasticsearch节点的数据将不会丢失
Elasticsearch对I / O敏感,而Docker存储驱动程序对于快速I / O而言并不理想
它允许使用高级Docker卷插件
1.2.6.9 避免使用loop-lvm模式
如果使用devicemapper存储驱动程序,请不要使用默认的loop-lvm模式。 将docker-engine配置为使用direct-lvm。
1.2.6.10 集中您的日志
考虑使用其他日志记录驱动程序集中化日志。 还要注意,默认的json文件日志记录驱动程序不适合用于生产环境。
1.2.7 在Docker中配置ES
在Docker中运行时,Elasticsearch配置文件从/usr/share/elasticsearch/config/加载。
要使用自定义配置文件,请将文件绑定安装在映像中的配置文件上。
您可以使用Docker环境变量来设置各个Elasticsearch配置参数。 样本撰写文件和单节点示例都使用此方法。
要使用文件的内容设置环境变量,请在环境变量名后加上_FILE。 这对于将密码之类的机密传递给Elasticsearch而无需直接指定它们很有用。
例如,要从文件设置Elasticsearch引导程序密码,您可以绑定安装文件并将ELASTIC_PASSWORD_FILE环境变量设置为安装位置。 如果将密码文件安装到/run/secrets/password.txt,请指定
-e ELASTIC_PASSWORD_FILE=/run/secrets/bootstrapPassword.txt
您还可以覆盖图像的默认命令,以将Elasticsearch配置参数作为命令行选项传递。 例如:
docker run <various parameters> bin/elasticsearch -Ecluster.name=mynewclustername
虽然绑定安装配置文件通常是生产中的首选方法,但您也可以创建一个包含配置的自定义Docker映像。
1.2.7.1 挂载Elasticsearch配置文件
创建自定义配置文件,并将其绑定安装在Docker映像中的相应文件上。 例如,要将docker run绑定到custom_elasticsearch.yml,请指定:
-v full_path_to/custom_elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
容器使用uid:gid 1000:0作为elasticsearch用户运行Elasticsearch。 该用户必须可以访问绑定的已挂载主机目录和文件,并且该用户必须可以写数据和日志目录。
1.2.7.2 使用自定义Docker镜像
在某些环境中,准备包含您的配置的自定义映像可能更有意义。
一个用于实现此目的的Dockerfile可能很简单:
FROM docker.elastic.co/elasticsearch/elasticsearch:7.6.2
COPY --chown=elasticsearch:elasticsearch elasticsearch.yml /usr/share/elasticsearch/config/
然后,您可以使用以下命令构建映像:
docker build --tag=elasticsearch-custom .
运行镜像
docker run -ti -v /usr/share/elasticsearch/data elasticsearch-custom
一些插件需要其他安全权限。 您必须通过以下方式明确接受它们:
- 运行Docker映像时附加
tty,并在出现提示时允许权限。 - 通过在插件安装命令中添加
--batch标志,检查安全权限并接受(如果适用)。
0x02 参考链接
- ES 官网首页
- ES 文档
- Getting Stared Guide
- Install Elasticsearch with Dockeredit
- docker-compose up命令
- Elasticsearch权威指南(中文版)
- 滴滴ElasticSearch平台跨版本升级以及平台重构之路
本篇完~
智能推荐
C#连接OPC C#上位机链接PLC程序源码 1.该程序是通讯方式是CSharp通过OPC方式连接PLC_c#opc通信-程序员宅基地
文章浏览阅读565次。本文主要介绍如何使用C#通过OPC方式连接PLC,并提供了相应的程序和学习资料,以便读者学习和使用。OPC服务器是一种软件,可以将PLC的数据转换为标准的OPC格式,允许其他软件通过标准接口读取或控制PLC的数据。此外,本文还提供了一些学习资料,包括OPC和PLC的基础知识,C#编程语言的教程和实例代码。这些资料可以帮助读者更好地理解和应用本文介绍的程序。1.该程序是通讯方式是CSharp通过OPC方式连接PLC,用这种方式连PLC不用考虑什么种类PLC,只要OPC服务器里有的PLC都可以连。_c#opc通信
Hyper-V内的虚拟机复制粘贴_win10 hyper-v ubuntu18.04 文件拷贝-程序员宅基地
文章浏览阅读1.6w次,点赞3次,收藏10次。实践环境物理机:Windows10教育版,操作系统版本 17763.914虚拟机:Ubuntu18.04.3桌面版在Hyper-V中的刚安装好Ubuntu虚拟机之后,会发现鼠标滑动很不顺畅,也不能向虚拟机中拖拽文件或者复制内容。在VMware中,可以通过安装VMware tools来使物理机和虚拟机之间达到更好的交互。在Hyper-V中,也有这样的工具。这款工具可以完成更好的鼠标交互,我的..._win10 hyper-v ubuntu18.04 文件拷贝
java静态变量初始化多线程,持续更新中_类初始化一个静态属性 为线程池-程序员宅基地
文章浏览阅读156次。前言互联网时代,瞬息万变。一个小小的走错,就有可能落后于别人。我们没办法去预测任何行业、任何职业未来十年会怎么样,因为未来谁都不能确定。只能说只要有互联网存在,程序员依然是个高薪热门行业。只要跟随着时代的脚步,学习新的知识。程序员是不可能会消失的,或者说不可能会没钱赚的。我们经常可以听到很多人说,程序员是一个吃青春饭的行当。因为大多数人认为这是一个需要高强度脑力劳动的工种,而30岁、40岁,甚至50岁的程序员身体机能逐渐弱化,家庭琐事缠身,已经不能再进行这样高强度的工作了。那么,这样的说法是对的么?_类初始化一个静态属性 为线程池
idea 配置maven,其实不用单独下载Maven的。以及设置新项目配置,省略每次创建新项目都要配置一次Maven_安装idea后是不是不需要安装maven了?-程序员宅基地
文章浏览阅读1w次,点赞13次,收藏43次。说来也是惭愧,一直以来,在装环境的时候都会从官网下载Maven。然后再在idea里配置Maven。以为从官网下载的Maven是必须的步骤,直到今天才得知,idea有捆绑的 Maven 我们只需要搞一个配置文件就行了无需再官网下载Maven包以后再在新电脑装环境的时候,只需要下载idea ,网上找一个Maven的配置文件 放到 默认的 包下面就可以了!也省得每次创建项目都要重新配一次Maven了。如果不想每次新建项目都要重新配置Maven,一种方法就是使用默认的配置,另一种方法就是配置 .._安装idea后是不是不需要安装maven了?
奶爸奶妈必看给宝宝摄影大全-程序员宅基地
文章浏览阅读45次。家是我们一生中最重要的地方,小时候,我们在这里哭、在这里笑、在这里学习走路,在这里有我们最真实的时光,用相机把它记下吧。 很多家庭在拍摄孩子时有一个看法,认为儿童摄影团购必须是在风景秀丽的户外,即便是室内那也是像大酒店一样...
构建Docker镜像指南,含实战案例_rocker/r-base镜像-程序员宅基地
文章浏览阅读429次。Dockerfile介绍Dockerfile是构建镜像的指令文件,由一组指令组成,文件中每条指令对应linux中一条命令,在执行构建Docker镜像时,将读取Dockerfile中的指令,根据指令来操作生成指定Docker镜像。Dockerfile结构:主要由基础镜像信息、维护者信息、镜像操作指令、容器启动时执行指令。每行支持一条指令,每条指令可以携带多个参数。注释可以使用#开头。指令说明FROM 镜像 : 指定新的镜像所基于的镜像MAINTAINER 名字 : 说明新镜像的维护(制作)人,留下_rocker/r-base镜像
随便推点
毕设基于微信小程序的小区管理系统的设计ssm毕业设计_ssm基于微信小程序的公寓生活管理系统-程序员宅基地
文章浏览阅读223次。该系统将提供便捷的信息发布、物业报修、社区互动等功能,为小区居民提供更加便利、高效的服务。引言: 随着城市化进程的加速,小区管理成为一个日益重要的任务。因此,设计一个基于微信小程序的小区管理系统成为了一项具有挑战性和重要性的毕设课题。本文将介绍该小区管理系统的设计思路和功能,以期为小区提供更便捷、高效的管理手段。四、总结与展望: 通过本次毕设项目,我们实现了一个基于微信小程序的小区管理系统,为小区居民提供了更加便捷、高效的服务。通过该系统的设计与实现,能够提高小区管理水平,提供更好的居住环境和服务。_ssm基于微信小程序的公寓生活管理系统
如何正确的使用Ubuntu以及安装常用的渗透工具集.-程序员宅基地
文章浏览阅读635次。文章来源i春秋入坑Ubuntu半年多了记得一开始学的时候基本一星期重装三四次=-= 尴尬了 觉得自己差不多可以的时候 就吧Windows10干掉了 c盘装Ubuntu 专心学习. 这里主要来说一下使用Ubuntu的正确姿势Ubuntu(友帮拓、优般图、乌班图)是一个以桌面应用为主的开源GNU/Linux操作系统,Ubuntu 是基于DebianGNU/Linux,支..._ubuntu安装攻击工具包
JNI参数传递引用_jni引用byte[]-程序员宅基地
文章浏览阅读335次。需求:C++中将BYTE型数组传递给Java中,考虑到内存释放问题,未采用通过返回值进行数据传递。public class demoClass{public native boolean getData(byte[] tempData);}JNIEXPORT jboolean JNICALL Java_com_core_getData(JNIEnv *env, jobject thisObj, jbyteArray tempData){ //resultsize为s..._jni引用byte[]
三维重建工具——pclpy教程之点云分割_pclpy.pcl.pointcloud.pointxyzi转为numpy-程序员宅基地
文章浏览阅读2.1k次,点赞5次,收藏30次。本教程代码开源:GitHub 欢迎star文章目录一、平面模型分割1. 代码2. 说明3. 运行二、圆柱模型分割1. 代码2. 说明3. 运行三、欧几里得聚类提取1. 代码2. 说明3. 运行四、区域生长分割1. 代码2. 说明3. 运行五、基于最小切割的分割1. 代码2. 说明3. 运行六、使用 ProgressiveMorphologicalFilter 分割地面1. 代码2. 说明3. 运行一、平面模型分割在本教程中,我们将学习如何对一组点进行简单的平面分割,即找到支持平面模型的点云中的所有._pclpy.pcl.pointcloud.pointxyzi转为numpy
以NFS启动方式构建arm-linux仿真运行环境-程序员宅基地
文章浏览阅读141次。一 其实在 skyeye 上移植 arm-linux 并非难事,网上也有不少资料, 只是大都遗漏细节, 以致细微之处卡壳,所以本文力求详实清析, 希望能对大家有点用处。本文旨在将 arm-linux 在 skyeye 上搭建起来,并在 arm-linux 上能成功 mount NFS 为目标, 最终我们能在 arm-linux 里运行我们自己的应用程序. 二 安装 Sky..._nfs启动 arm
攻防世界 Pwn 进阶 第二页_pwn snprintf-程序员宅基地
文章浏览阅读598次,点赞2次,收藏5次。00为了形成一个体系,想将前面学过的一些东西都拉来放在一起总结总结,方便学习,方便记忆。攻防世界 Pwn 新手攻防世界 Pwn 进阶 第一页01 4-ReeHY-main-100超详细的wp1超详细的wp203 format2栈迁移的两种作用之一:栈溢出太小,进行栈迁移从而能够写入更多shellcode,进行更多操作。栈迁移一篇搞定有个陌生的函数。C 库函数 void *memcpy(void *str1, const void *str2, size_t n) 从存储区 str2 _pwn snprintf