otter配置文档_otter集群配置-程序员宅基地
技术标签: spring 数据库架构 java 数据库开发 etl 大数据 docker
工作原理
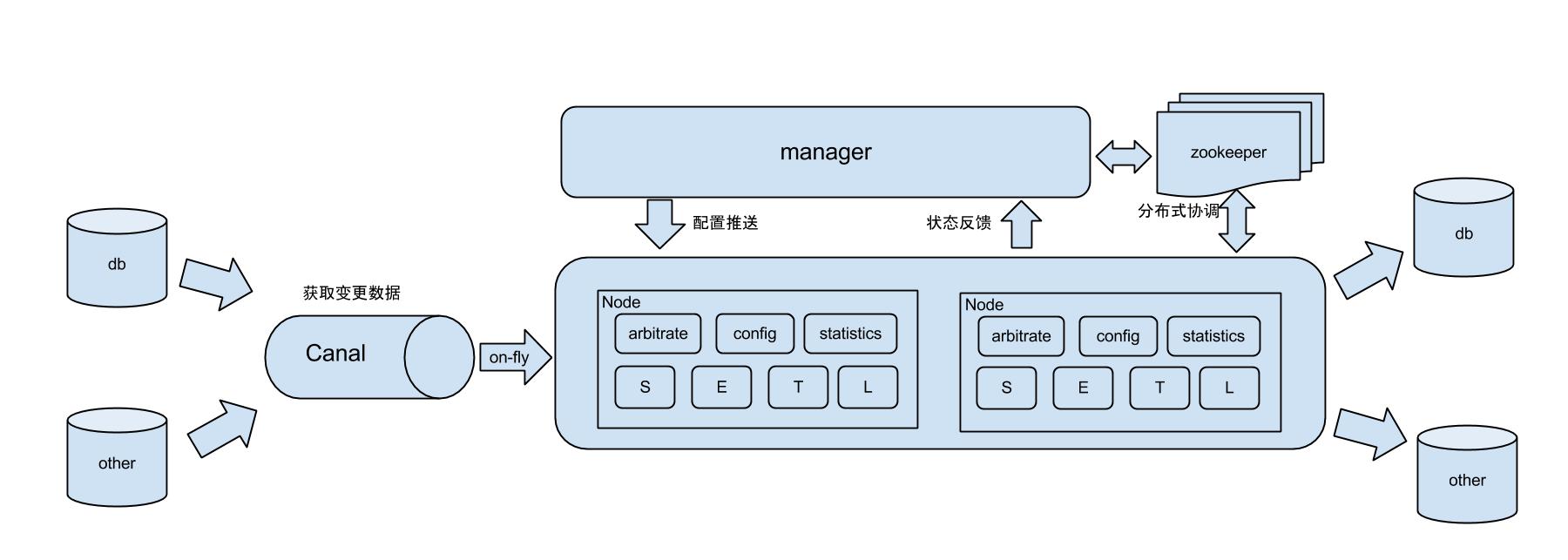
原理描述:
-
基于Canal开源产品,获取数据库增量日志数据。
-
典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
-
基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
环境配置
-
目前zookeeper为单机版,配置在该服务器中的docker中,后面有需求可以在下面配置中加入
-
目前node只配了一个,后面有需求也可以在下面配置加入,node主要负责SETL工作,如果项目较大,可以将分别在两台机器上装node,负责S、E模块的机器靠近源数据库,负责T、L模块的靠近目标数据库。
Zookeeper配置

node配置


-
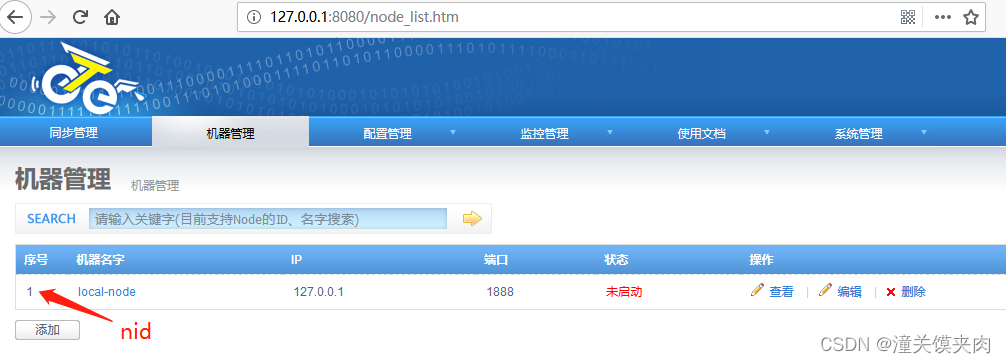
机器名称:可以随意定义,方便记忆即可
-
机器ip:对应node节点将要部署的机器ip,如果有多ip时,可选择其中一个ip进行暴露. (此ip是整个集群通讯的入口,实际情况千万别使用127.0.0.1,否则多个机器的node节点会无法识别)
-
机器端口:对应node节点将要部署时启动的数据通讯端口
-
下载端口:对应node节点将要部署时启动的数据下载端口
-
外部ip :对应node节点将要部署的机器ip,存在的一个外部ip,允许通讯的时候走公网处理
-
zookeeper集群:为提升通讯效率,不同机房的机器可选择就近的zookeeper集群
-
node这种设计,是为解决单机部署多实例而设计的,允许单机多node指定不同的端口
端口默认即可,添加完node后,列表中第一列是nid(此id要保存到node/conf/nid文件中的值):
设置同步任务(增量同步)
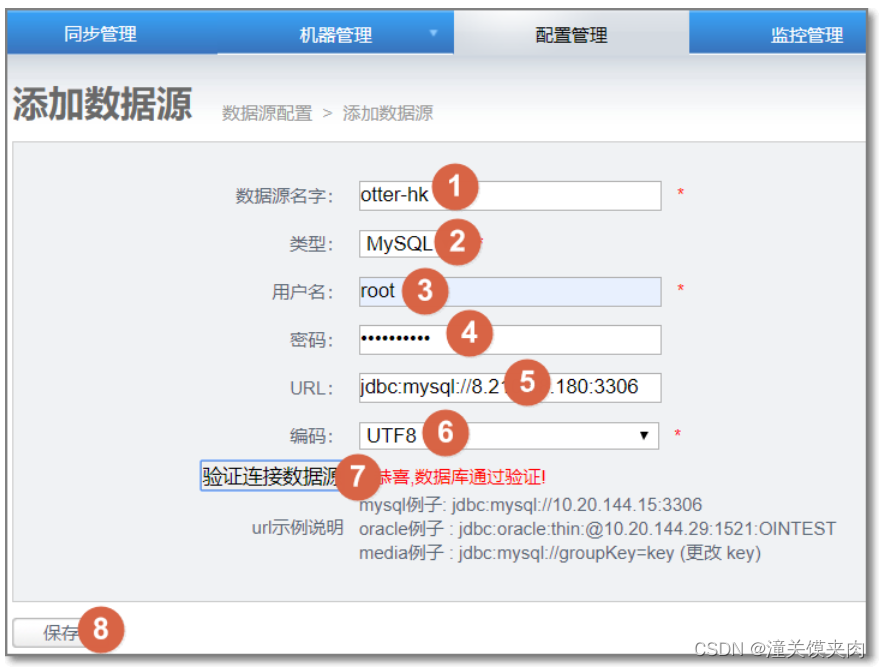
数据源配置
配置源数据库:

验证失败的时候可以试试在URL后面加上 ?useSSL=false
其中编码也要跟数据库编码对应,不然也不通过
配置目标数据库:
添加完成:

数据表配置
添加源数据库表和目标数据库表

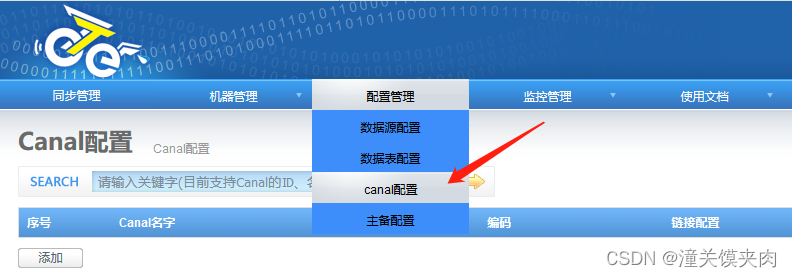
添加canal
otter是内嵌了canal配置,选择直接选嵌入式,由于是基于源库的binlog进行增量订阅,所以数据库地址为源库

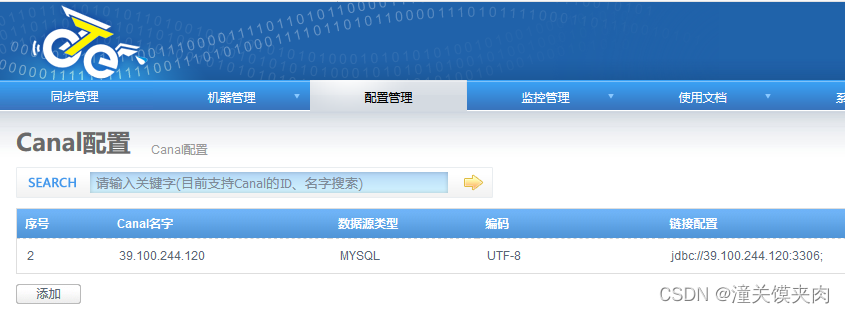
1. 数据库地址:指源库的ip和端口
2. connectionCharset ==> 获取binlog时指定的编码
3. 位点自定义设置 ==> 格式:{“journalName”:"",“position”:0,“timestamp”:0};
指定位置:{“journalName”:"",“position”:0};
指定时间:{“timestamp”:0};
4. 内存存储batch获取模式 ==> MEMSIZE/ITEMSIZE,前者为内存控制,后者为数量控制. 针对MEMSIZE模式的内存大小计算 = 记录数 * 记录单元大小
内存存储buffer记录数
内存存储buffer记录单元大小
5. 心跳SQL配置 ==> 可配置对应心跳SQL,如果配置 是否启用心跳HA,当心跳SQL检测失败后,canal就会自动进行主备切换.
添加channel

行记录模式:如果目标库中不存在记录时,执行插入。(一般用这个) 列记录模式:变更哪个字段就同步哪个字段,在双A同步时,为减少数据冲突,建议使用此选项。(双A只的是双主、且会同时修改同一条记录)
添加pipeline

pipeline参数
-
并行度. ==> 查看文档:Otter调度模型,主要是并行化调度参数.(滑动窗口大小)
-
数据反查线程数. ==> 如果选择了同步一致性为反查数据库,在反查数据库时的并发线程数大小
-
数据载入线程数. ==> 在目标库执行并行载入算法时并发线程数大小
-
文件载入线程数. ==> 数据带文件同步时处理的并发线程数大小
-
主站点. ==> 双A同步中的主站点设置
-
消费批次大小. ==> 获取canal数据的batchSize参数
-
获取批次超时时间. ==> 获取canal数据的timeout参数
pipeline 高级设置
-
使用batch. ==> 是否使用jdbc batch提升效率,部分分布式数据库系统不一定支持batch协议
-
跳过load异常. ==> 比如同步时出现目标库主键冲突,开启该参数后,可跳过数据库执行异常
-
仲裁器调度模式. ==> 查看文档:Otter调度模型
-
负载均衡算法. ==> 查看文档:Otter调度模型
-
传输模式. ==> 多个node节点之间的传输方式,RPC或HTTP. HTTP主要就是使用aria2c,如果测试环境不装aria2c,可强制选择为RPC
-
记录selector日志. ==> 是否记录简单的canal抓取binlog的情况
-
记录selector详细日志. ==> 是否记录canal抓取binlog的数据详细内容
-
记录load日志. ==> 是否记录otter同步数据详细内容
-
dryRun模式. ==> 只记录load日志,不执行真实同步到数据库的操作
-
支持ddl同步. ==> 是否同步ddl语句
-
是否跳过ddl异常. ==> 同步ddl出错时,是否自动跳过
-
文件重复同步对比 ==> 数据带文件同步时,是否需要对比源和目标库的文件信息,如果文件无变化,则不同步,减少网络传输量.
-
文件传输加密 ==> 基于HTTP协议传输时,对应文件数据是否需要做加密处理
-
启用公网同步 ==> 每个node节点都会定义一个外部ip信息,如果启用公网同步,同步时数据传递会依赖外部ip.
-
跳过自由门数据 ==> 自定义数据同步的内容
-
跳过反查无记录数据 ==> 反查记录不存在时,是否需要进行忽略处理,不建议开启.
-
启用数据表类型转化 ==> 源库和目标库的字段类型不匹配时,开启改功能,可自动进行字段类型转化
-
兼容字段新增同步 ==> 同步过程中,源库新增了一个字段(必须无默认值),而目标库还未增加,是否需要兼容处理
-
自定义同步标记 ==> 级联同步中屏蔽同步的功能.
添加映射关系表

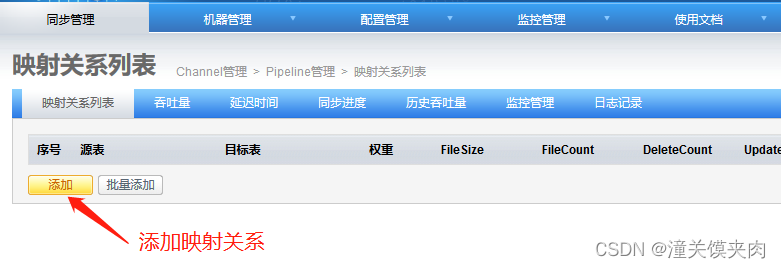


添加完成:
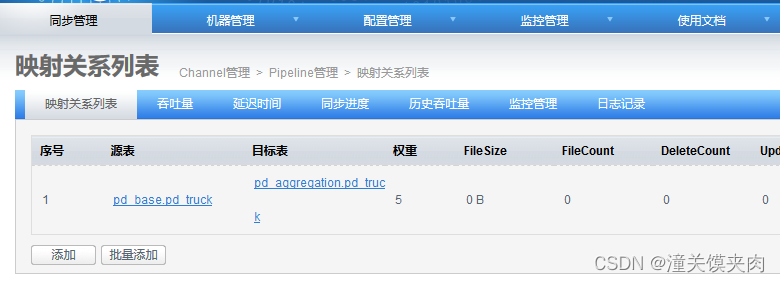
测试验证
启动channel
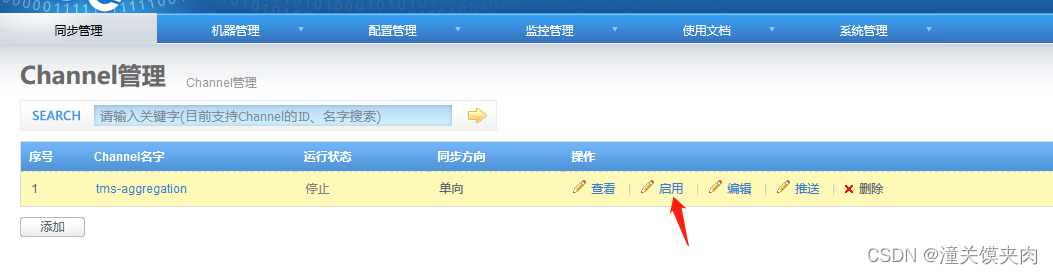
在源表中插入条记录,数据同步到目标表中。
设置全量同步
自定义数据同步(自由门)
主要功能是在不修改原始表数据的前提下,触发一下数据表中的数据同步。
可用于:
-
同步数据订正
-
全量数据同步. (自 由 门触发全量,同时otter增量同步,需要配置为行记录模式,避免update时因目标库不存在记录而丢失update操作)
主要原理:
a. 基于otter系统表retl_buffer,插入特定的数据,包含需要同步的表名,pk信息。
b. otter系统感知后会根据表名和pk提取对应的数据(整行记录),和正常的增量同步一起同步到目标库。
retl_buffer表要创建在源数据库中,并且进行全量同步前要先开启channal服务
retl_buffer表结构:
CREATE TABLE retl_buffer
(
ID BIGINT AUTO_INCREMENT, ## 无意义,自增即可
TABLE_ID INT(11) NOT NULL, ## tableId, 即序号这一列,如果配置的是正则,需要指定full_name,当前table_id设置为0.
FULL_NAME varchar(512), ## schemaName + '.' + tableName (如果明确指定了table_id,可以不用指定full_name)
TYPE CHAR(1) NOT NULL, ## I/U/D ,分别对应于insert/update/delete
PK_DATA VARCHAR(256) NOT NULL, ## 多个pk之间使用char(1)进行分隔
GMT_CREATE TIMESTAMP NOT NULL, ## 无意义,系统时间即可
GMT_MODIFIED TIMESTAMP NOT NULL, ## 无意义,系统时间即可
CONSTRAINT RETL_BUFFER_ID PRIMARY KEY (ID)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;然后将要同步的数据插入即可
全量同步操作示例:
insert into retl.retl_buffer(ID,TABLE_ID, FULL_NAME,TYPE,PK_DATA,GMT_CREATE,GMT_MODIFIED) (select null,0,'你的源数据库.源数据表','I',id,now(),now() from `你的源数据库`.`源数据表`);
如果针对多主键时,对应的PK_DATA需要将需要同步表几个主键按照(char)1进行拼接,比如concat(id,char(1),name)
智能推荐
Dynamic Proxy模式_dyproxy-程序员宅基地
文章浏览阅读966次。 Dynamic Proxy 是JDK 1.3 版本中新引入的一种代理机制。严格来讲,Dynamic Proxy本身并非一种模式,只能算是Proxy 模式的一种动态实现方式,不过为了与传统Proxy 模式相区分,这里暂且将其称为“Dynamic Proxy 模式”来泛指通过Dynamic Proxy 机制实现的Proxy 模式。 通过Decorator模式,我们可以改写接口_dyproxy
【Cisco Packet Tracer】运输层端口与DHCP的作用_cisco dhcp端口-程序员宅基地
文章浏览阅读1.7w次,点赞81次,收藏65次。这篇文章摘要将介绍人工智能在医疗领域的应用。随着技术的迅猛发展,人工智能在医疗诊断、治疗和研究方面展现出巨大的潜力。我们将深入探讨人工智能在医学影像解读上的应用,如何通过深度学习算法提高医生对X光、MRI等图像的准确性。_cisco dhcp端口
JavaScript----闭包函数-程序员宅基地
文章浏览阅读3.2k次,点赞5次,收藏16次。闭包函数 作用域链 优缺点_闭包函数
时序分解 | EEMD集合经验模态分解时间序列信号分解Matlab实现_eemd matlab-程序员宅基地
文章浏览阅读953次,点赞19次,收藏14次。信号去噪是信号处理中的一个重要课题,其目的是从含有噪声的信号中提取出有用信号。近年来,经验模态分解(EMD)算法因其在信号去噪方面的优异性能而备受关注。然而,传统EMD算法存在分解结果不稳定、易受噪声影响等问题。为了克服这些问题,本文提出了一种基于总体平均经验模态分解(EEMD)算法的信号去噪方法。_eemd matlab
Android腾讯微薄客户端开发八:微博查看(转播,对话,点评)-程序员宅基地
文章浏览阅读86次。Android如果是自己的微博,可以干掉它下面三幅图是转播,对话以及点评界面Java代码publicclassWeiboDetailActivityextendsActivity{privateDataHelperdataHelper;privateUserInfouser;p...
【lssvm分类】基于算术算法优化最小二乘支持向量机AOA-LSSVM实现数据分类附matlab-程序员宅基地
文章浏览阅读44次。在机器学习领域,支持向量机(Support Vector Machines,SVM)是一种广泛应用的分类算法。然而,传统的SVM算法在处理大规模数据集时存在一些问题,如计算复杂度高和内存占用大等。为了解决这些问题,一种基于算术算法优化的最小二乘支持向量机(AOA-LSSVM)被提出。AOA-LSSVM是一种改进的支持向量机算法,它通过对算术算法进行优化,提高了算法的效率和性能。它采用了最小二乘支持向量机(LSSVM)的思想,通过优化算法的求解过程,使得算法在处理大规模数据集时更加高效。_aoa-lssvm
随便推点
基于matlab的稀疏表示KSVD算法图像去噪_字典学习 稀疏编码 图像去噪-程序员宅基地
文章浏览阅读441次。稀疏表示KSVD算法是图像去噪问题中比较有效的方法之一,本文将详细介绍在matlab平台上如何使用KSVD算法进行图像去噪,并提供完整的源代码。KSVD算法是一种基于字典的稀疏表达方法,其核心思想是将待处理图像分解为一些基础元素的线性组合形式,即通过求解一个优化问题,来获取合适的基础元素和系数表达式。稀疏编码则负责计算每个字典元素的系数,使得最终重构得到的图像与原始图像之间的误差最小。2)初始化字典D,通常采用大小为[KxN]的随机矩阵,其中K表示字典中元素的数量,N表示图像块的大小。_字典学习 稀疏编码 图像去噪
golang基础 第3章 (struct,函数,方法,接口,泛型,类型集,类型)_go 泛型 struct-程序员宅基地
文章浏览阅读1k次,点赞19次,收藏25次。golang 基础之struct func 方法 接口 泛型_go 泛型 struct
socket.io-client的4.0封装使用-程序员宅基地
文章浏览阅读4.3k次,点赞2次,收藏10次。socket.io-client的二次封装,4.0版本,含有心跳连接、连接超时、连接错误等监听_socket.io-client
git基础教程(21)git restore还原改动-程序员宅基地
文章浏览阅读8.3k次,点赞3次,收藏2次。git restore <file>表示将在工作空间但是不在暂存区的文件撤销更改.git restore --staged <file>作用是将暂存区的文件从暂存区撤出,但不会更改文件。演示1:1、仓库初始状态:干净的仓库,下面有一个readme文件小静静@DESKTOP-MD21325 MINGW64 /d/test1/test1 (master)$ git statusOn branch masterYour branch is up to date with_git restore
远古项目实战丨用Python一秒搞定垃圾分类_python垃圾分类-程序员宅基地
文章浏览阅读1.7k次,点赞4次,收藏18次。这是一个严肃又欢乐的七月,哲学界迎来新拷问。传统古典哲学的代表,是门口的保安大叔,他提出了三个经典问题:“你是谁?你从哪儿来?要到哪儿去?而后现代主义哲学的四位代表人物冒了出来,发出直指人内心的提问。食堂大妈:你要饭吗?配钥匙师傅:你配吗?算命先生:你算什么东西?滴滴司机:你搞清楚自己的定位没有?从本月起,魔都正式步入生活垃圾强制分类的时代。个人一旦违规混合投放垃圾,将被处以最高200元的罚款。新兴哲学代表垃圾分类阿姨正式上岗:你是什么垃圾?_python垃圾分类
【机器学习】机器学习之数据清洗_数据清洗论文包括代码-程序员宅基地
文章浏览阅读1.9w次,点赞9次,收藏8次。在实验中探索数据清洗的重要性以及清洗过程中的一些关键步骤,理解数据清洗是一个必要的预处理过程,用来帮助从原始数据中去除不准确、不完整或不适用于模型的记录,以确保所使用的数据是准确、可靠且适合用于模型训练,也可以帮助发现和纠正数据中的错误、缺失和不一致之处,以提高数据的质量和准确性。_数据清洗论文包括代码