SKlearn学习笔记——神经网络概述_sklearn.neural_network-程序员宅基地
SKlearn学习笔记——神经网络概述
前言: scikit-learn,又写作sklearn,是一个开源的基于python语言的机器学习工具包。它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。
以下内容整理自 菜菜的机器学习课堂.
sklearn官网链接: 点击这里.
1 打开深度学习的大门:神经网络概述
1.1 打开深度学习的大门
人工神经网络(Artificial Neural Network,ANN),通常简称为神经网络,是深度学习的基础,它是受到人类大脑 结构启发而诞生的一种算法。神经学家们发现,人类大脑主要由称为神经元的神经细胞组成,通过名为轴突的纤维束 与其他神经元连接在一起。每当神经元从其他的神经元接受到信号,神经元便会受到刺激,此时纤维束会将信号从一 个神经元传递到另一个神经元上。人类正是通过相同的冲动反复地刺激神经元,改变神经元之间的链接的强度来进行 学习。

这其实和我们在过去十二周内经历的机器学习过程非常类似。在机器学习中,我们建模,将特征矩阵输入模型中,然 后算法为我们输出预测结果。只不过在人脑中,数以亿计的神经细胞相互链接来构建一个生物神经网络(一个神经细 胞当然可以和众多个神经细胞相连),我们的机器学习中,往往只有一个模型或者一种算法在运行。人脑通过构建复 杂的网络可以进行逻辑,语言,情感的学习,相信模拟这种结构的机器也可以有很强大的学习能力,于是人工神经网 络应运而生。
神经网络算法试图模拟生物神经系统的学习过程,以此实现强大的预测性能。不过由于是模仿人类大脑,所以神经网 络的模型复杂度很高也是众所周知。在现实应用中,神经网络可以说是解释性最差的模型之一,商业环境中很少使用 神经网络。然而出了商业分析,还有许多算法应用的部分,其中最重要的是深度学习和人工智能的领域,现在大部分 已经成熟的人工智能技术:图像识别,语音识别等等,背后都是基于神经网络的深度学习算法。因此,作为机器学习 中(可能是)最复杂的,深度学习中基础的算法,神经网络的了解和学习是很有必要的。
1.2 神经网络的基本原理

注意,在这个过程中,有两个非常重要的核心要点:
- 每个输入的特征会被匹配到一个参数 w ,我们都知道参数向量 中含有的参数数量与我们的特征数目是一致的, 在感知机中也是如此。也就是说,任何基于感知机的算法,必须至少要有参数向量 w 可求。
- 一个线性关系 z ,z 是由参数和输入的数据共同决定的。这个线性关系,往往就是我们的决策边界,或者它也可 以是多元线性回归,逻辑回归等算法的线性表达式
- 激活函数的结果,是基于激活函数本身,参数向量 w 和输入的数据一同计算出来的。也就是说,任何基于感知机的算法,必须要存在一个激活函数。
神经网络就相当于众多感知机的集成,因此,确定激活函数,并找出参数向量 也是神 经网络的计算核心。只不过对 于只运行一次激活函数的感知机来说,神经网络大大增加了的模型的复杂度,激活函数在这个过程中可能被激活非常 多次,参数向量的数量也呈指数级增长。我们来看看神经网络的基本结构:

首先,神经网络有三层。第一层叫做输入层(Input layer),输入特征矩阵用,因此每个神经元上都是一个特征向 量。极端情况下,如果一个神经网络只训练一个样本,则每个输入层的神经元上都是这个样本的一个特征取值。
最后一层叫做输出层(output layer),输出预测标签用。如果是回归类,一般输出层只有一个神经元,回归的是所 有输入的样本的标签向量。如果是分类,可能会有多个神经元。二分类有两个神经元,多分类有多个神经元,分别输 出所有输入的样本对应的每个标签分类下的概率。但无论如何,输出层只有一层,是用于输出预测结果用。
输入层和输出层中间的所有层,叫做隐藏层(Hidden layers),最少一层。也就是说整个神经网络是最少三层。隐 藏层是我们用来让算法学习的网络层级,从更靠近输入层的地方开始叫做"上层",相对而言,更靠近输出层的一层, 叫做"下层"。在隐藏层上,每个神经元中都存在一个激活函数,我们的数据被逐层传递,每个下层的神经元都 必须处 理上层的神经元中的激活函数处理完毕的数据,本质是一个感知器嵌套的过程。隐藏层中上层的每个神经元,都与下 层中的每个神经元相连,因此隐藏层的结构随着神经元的变多可以变得非常非常复杂。神经网络的两个要点:参数 和激活函数,也都在这一层发挥作用,因此理解隐藏层是神经网络原理中最难的部分。
- 参数 w
我们接下来,就来举一个非常简单的例子,为大家梳理一下神经网络的过程。假设我们的线性关系 z = w * x,我们 将截距 b 包括在了 w 当中。我们现在有一个最简单的三层神经网络中,带大家来了解一下我们的参数 w。感知机上每 条神经键上都有一个参数 w,对神经网络也是如此,只不过神经网络中神经元众多,每个神经元又和相邻层的神经元 全部相连,因此参数 w 的数量也众多。来看下面的三层神经网络,我们总共有322条神经键,因此总共有12个参数 w。这12个参数 的表示法非常复杂,具体如下:

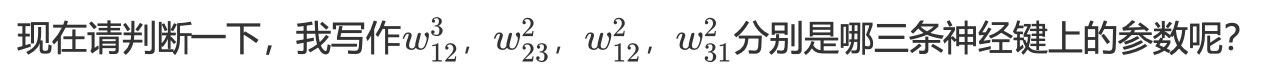
来看正确答案:





- 我们神经网络的每一层的结果之间的关系是嵌套,不是迭代。
回忆一下我们在逻辑回归中如何迭代参数?我们执行梯度下降,每下降一步,上一步的参数就被下一步的参数 所替换掉,最终我们使用来求解预测结果y的只是我们最后一次迭代出的参数组合。但在我们的神经网络中,上 一层的结果和参数,会被放到下一层中去求解新的结果,但是上一层的参数还会被保留,没有被覆盖每次求解 都还需要执行整个嵌套过程,需要每一层上的每个参数。 - 由于我们执行的是嵌套,不是迭代,所以我们的每一个系数之间是相互独立的,每一层的系数之间也是相互独立的,我们不是在执行使用上一层或者上一个神经元的参数来求解下一层或者下一个神经元的参数的过程。我 们不断求解的,是激活函数的结果 a,不是参数 w,重要的事情说三遍,在一次神经网络计算中,我们没有迭代参数w ,没有迭代参数 w,没有迭代参数w 。
了解了这个过程,其实大家就知道神经网络是如何工作的了。大家可以看到,光是一个四层的神经网络,我们对于w 的标号就已经有点一团乱麻的感觉了。试想一下我们的真实数据中,往往有多少特征需要在输入层被输入,那我们需 要多少层,多少个神经元去输出我们的预测值呢?真实的神经网络,可能很多都长这样:

这张图还不算真实数据中特别复杂的情况,但已经含有总共 89994 = 23,328个 w,对于手算或者自行理解来 说,已经是不可能了,更别说存在高维特征,比如说100,1000个特征的情况了。现实中神经网络常常被用于处理大 型数据,所以最后神经网络究竟是怎样产出了我们的 y,中间发生了这样的过程,产出了多少个系数,完全就是一 个“黑箱”过程了——我们是无法理解的。
从上面的讲解来看,神经网络的计算本身其实并不晦涩,它所涉及到的概念:比如感知机,比如嵌套,比如之后我们 要讲解的梯度下降,都是我们曾经在其他算法中见过的过程,它难在计算过程过于复杂,元素太多,不在原理本身的 数学水平或者机器学习水平。
到这里,你就算是理解了神经网络的…开头!我们仅仅讲解了神经网络的冰山一角。深度学习中的众多算法,都是 基于我们刚才讲解的最简单的神经网络进行的一些变化和改进。基于这个简单的原理,我们其实已经可以预见我们神 经网络的重点,以及我们的sklearn中都会有什么样的参数来供我们调整了:

- 激活函数:就如同核函数一样,必然有各种各样的激活函数可以供我们选择
- 神经网络的结构:隐藏层有多少,每层有多少神经元?必然是一个超参数,需要我们自己来进行调整
- w怎么确定:之前一直说得非常理所当然,每个神经键上都有一个参数 w,然而这些参数从哪里来的呢?在SVM 中和逻辑回归中,我们写了十页数学计算来求解我们的 w,在神经网络中,求解参数必然也不会轻松。是不是要 最优化呢?如果要最优化的话,是不是有损失函数呢?有损失函数的话,是不是有梯度下降呢?如果我们使用 的是类似于梯度下降,最小二乘这样的数学过程,则必然有众多的数学过程相关的参数在sklearn中等待着我们。
- 除此之外,我们还想知道一些其他的问题:比如说,神经网络为什么要使用嵌套的方式进行?为什么需要多层,一层不行吗?
1.3 sklearn中的神经网络
神经网络对于机器学习来说,尤其是对于业务分析的机器学习来说,可以说是位置尴尬。虽然它效果很好,但它的可 解释性太差,别说完全不理解机器学习的老板和同事们,就连把机器学习学了个遍,听了十二周课来到这里的你,可 能都无法理解神经网络中究竟发什么了什么。再加上神经网络的学习能力超强,所以它是一个非常容易过拟合的模 型,很多时候也许都不是一个好的选择。所以神经网络其实并不如大家想象得那么受欢迎,尤其是在业务分析的领 域。当然,在深度学习的领域是完全另一番风景,老板也不会去问你,为什么你研究的程序能够识别出图像。
sklearn是专注于机器学习的库,它在神经网络的模块中特地标注:sklearn不是用于深度学习的平台,因此这个神经 网络不具备做深度学习的功能,也不具备处理大型数据的能力,所以神经网络在sklearn中颇有被冷落的意思。原理 讲解也非常简单,并没有详细的描述。但是使用神经网络的类还是有很多参数,写法详细。

今天我们的重点是带大家来了解一下两个以多层感知机为基础的类:MLPClassifier和MLPRegressor。
2 neural_network.MLPClassifier
class sklearn.neural_network.MLPClassifier (hidden_layer_sizes=(100, ), activation=’relu’, solver=’adam’, alpha=0.0001, batch_size=’auto’, learning_rate=’constant’, learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10)
2.1 隐藏层与神经元:重要参数hidden_layer_sizes
神经网络算法中要考虑的第一件事情就是我们的隐藏层的结构,如果不设定结构,神经网络本身甚至无法构建,因此 这是一个超参数。
| 参数 | 含义 |
|---|---|
| hidden_layer_sizes | 元组,长度= n_layers - 2,默认值(100, ); 元祖中包含多少个元素,就表示设定多少隐藏层; 元祖中的第i个元素表示第i个隐藏层中的神经元数量 |
先来建立一个神经网络吧。
- 导入需要的数据和库,导入数据集
import numpy as np
from sklearn.neural_network import MLPClassifier as DNN
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score as cv
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.model_selection import train_test_split as TTS
from time import time
import datetime
data = load_breast_cancer() X = data.data
y = data.target
Xtrain, Xtest, Ytrain, Ytest = TTS(X,y,test_size=0.3,random_state=420)
- 建模,使用交叉验证导出分数
times = time()
dnn = DNN(hidden_layer_sizes=(100,),random_state=420)
print(cv(dnn,X,y,cv=5).mean())
print(time() - times)
#使用决策树进行一个对比
times = time()
clf = DTC(random_state=420)
print(cv(clf,X,y,cv=5).mean())
print(time() - times)
- 查看如何使用参数hidden_layer_sizes
dnn = DNN(hidden_layer_sizes=(100,),random_state=420).fit(Xtrain,Ytrain)
dnn.score(Xtest,Ytest)
#使用重要参数n_layers_
dnn.n_layers_
#可见,默认层数是三层,由于必须要有输入和输出层,所以默认其实就只有一层隐藏层
#如果增加一个隐藏层上的神经元个数,会发生什么呢?
dnn = DNN(hidden_layer_sizes=(200,),random_state=420)
dnn = dnn.fit(Xtrain,Ytrain) dnn.score(Xtest,Ytest)
#看似结果会
#来试试看学习曲线
s = []
for i in range(100,2000,100):
dnn = DNN(hidden_layer_sizes=(int(i),),random_state=420).fit(Xtrain,Ytrain)
s.append(dnn.score(Xtest,Ytest))
print(i,max(s))
plt.figure(figsize=(20,5))
plt.plot(range(200,2000,100),s)
plt.show()
#那如果增加隐藏层,控制神经元个数,会发生什么呢?
s = []
layers = [(100,),(100,100),(100,100,100),(100,100,100,100),(100,100,100,100,100),
(100,100,100,100,100,100)]
for i in layers:
dnn = DNN(hidden_layer_sizes=(i),random_state=420).fit(Xtrain,Ytrain)
s.append(dnn.score(Xtest,Ytest))
print(i,max(s))
plt.figure(figsize=(20,5))
plt.plot(range(3,9),s)
plt.xticks([3,4,5,6,7,8])
plt.xlabel("Total number of layers")
plt.show()
#如果同时增加隐藏层和神经元个数,会发生什么呢? s = []
layers = [(100,),(150,150),(200,200,200),(300,300,300,300)]
for i in layers:
dnn = DNN(hidden_layer_sizes=(i),random_state=420).fit(Xtrain,Ytrain)
s.append(dnn.score(Xtest,Ytest))
print(i,max(s))
plt.figure(figsize=(20,5))
plt.plot(range(3,7),s)
plt.xticks([3,4,5,6])
plt.xlabel("Total number of layers")
plt.show()
我们不可能无尽地画学习曲线画下去,并且,无论是什么样的学习曲线,看起来数据上的表现都没有明确的提升或下 降,可见这不是一种有效的方法。有没有既定的规则可以帮助我们确定隐藏层到底需要多少层,而每个隐藏层上到底 需要多少个神经元呢?
2.2 激活函数:重要参数activation
2.3 反向传播与梯度下降
智能推荐
每天计划完成打勾的app 做完一个打一个勾那种便签_有没有app 计划多少个 实际完成多少个-程序员宅基地
文章浏览阅读1.2k次。对于忙碌的职场人士来说,每天都有很多事情要处理。为了不把重要的事情漏掉,需要把待办的事项列下来,做完一个打勾一个,这样一看待办列表,自己做了多少事、还有多少事情没做就可以一目了然。现在有做完一个打一个勾的那种便签,可以帮助用户很好地记录待办事项,这样的便签就是敬业签。一起来看看,敬业签怎么新建待办并打勾完成吧!以手机敬业签为例:1:打开并登录敬业签后,点击底部的“待办”,新增一个待办分类。2:在分类管理页面点右上角+,启动新增待办分类菜单,分类类型选择“待办”,然后填写分类名称并点右下角新增,就可_有没有app 计划多少个 实际完成多少个
ONVIF Server 鉴权实现代码(服务端)_digest&ws-username token-程序员宅基地
文章浏览阅读2.6k次。ONVIF鉴权实现代码生成gSOAP框架代码,这个网上有很多教程,需要加入很多文件,并且需要openssl库。加入需要鉴权的文件和openssl库以后,只需要加每个接口中加入鉴权操作的代码,调用的时候就能实现鉴权。ONVIF的鉴权分两种: HTTP Digest 和 WS-Username Token在ONVIF Device Test Tool上可以对两种鉴权分别进行测试。authenticate.h#ifndef __AUTHENTICATE_H__#define __AUTHENTICAT_digest&ws-username token
优化APK体积_android apk 大小优化-程序员宅基地
文章浏览阅读1.2k次。该篇文章主要来介绍如何减少APK体积,以帮助用户更快地下载App,并加速安装/更新过程。_android apk 大小优化
通用存储过程分页(top max模式)版本(性能相对之前的not in版本极大提高) _top 搭配not in 性能-程序员宅基地
文章浏览阅读1.3k次。 --/*-----存储过程 分页处理 孙伟 2005-03-28创建 -------*/--/*----- 对数据进行了2分处理使查询前半部分数据与查询后半部分数据性能相同 -------*/--/*-----存储过程 分页处理 孙伟 2005-04-21修改 添加Distinct查询功能-------*/--/*-----存储过程 分页处理 孙伟 2005-05-18修改 多字段排序规则问题-_top 搭配not in 性能
vue新玩法VueUse-工具库@vueuse/core-程序员宅基地
文章浏览阅读1.5w次,点赞3次,收藏10次。VueUse官方链接一、什么是VueUseVueUse不是Vue.use !!!它是一个基于 Composition API 的实用函数集合,下面是具体的一些用法二、如何引入import { 具体方法 } from ‘@vueuse/core’三、下面来看看一些具体的用法1、useMouse:监听当前鼠标坐标的一个方法,他会实时的获取鼠标的当前的位置2、usePreferredDark:判断用户是否喜欢深色的方法,他会实时的判断用户是否喜欢深色的主题3、useLocalStorage:数据_vueuse/core
统计学5大基本概念,建议收藏!(文末送书)-程序员宅基地
文章浏览阅读736次。转自:爱数据LoveD大家好,我是小z,也可以叫我阿粥~今天给大家分享一波统计学重要概念,顺便前排提示文末送书~从高的角度来看,统计学是一种利用数学理论来进行数据分析的技术。象柱状图这种基本的可视化形式,会给你更加全面的信息。但是,通过统计学我们可以以更富有信息驱动力和针对性的方式对数据进行操作。所涉及的数学理论帮助我们形成数据的具体结论,而不仅仅是猜测。利用统计学,我们可以更深入、更细致地观察数..._统计学五大基本原理
随便推点
Python3输入输出与字符串格式化_%s.%d' %()-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏12次。介绍了输入(input)、输出(print),及字符串格式化(F-string、format与%)方式_%s.%d' %()
EL表达式比较字符串或是数字格式的数值是否相等,为true,却不执行为true时的代码_el 表达式 判断字符串和数字相等-程序员宅基地
文章浏览阅读9.3k次。问题:EL表达式比较字符串或是数字格式的数值是否相等,为true,却不执行为true时的代码。示例:true原因:有可能是test="${ 1 == 1}(这里多个空格)",即大括号与双引号之间多了空格,这个时候,就不会打印true。去掉多余的空格就可以了_el 表达式 判断字符串和数字相等
GCC-3.4.6源代码学习笔记(26续1)_-feliminate-unused-debug-types-程序员宅基地
文章浏览阅读2k次。common_handle_option (continue) 909 case OPT_fcall_used_:910 fix_register (arg, 0, 1);911 break;912 913 case OPT_fcall_saved_:914 fix_register (arg, 0, 0)_-feliminate-unused-debug-types
python语言程序设计实践教程陈东上海交通大学答案_《软件开发训练营:ASP.NET开发一站式学习难点》杨云著【摘要 书评 在线阅读】-苏宁易购图书...-程序员宅基地
文章浏览阅读2.7k次。商品参数作者:杨云著出版社:清华大学出版社出版时间:2013-8-1版次:1印次:1印刷时间:2013-8-1页数:434开本:16开装帧:平装ISBN:9787302318286版权提供:清华大学出版社编辑推荐《软件开发训练营·ASP.NET开发一站式学习:难点·案例·练习》特色:1.《软件开发训练营·ASP.NET开发一站式学习:难点·案例·练习》所讲内容既避开艰涩难懂的理论知识,又覆盖了编程..._python语言程序设计实践教程陈东课后习题答案解析
解决:Qt项目构建成功,但是运行异常退出。_qt安装后构建可以,运行就一直提示程序异常-程序员宅基地
文章浏览阅读2k次。构建:从debug换成release:就可以正常运行了_qt安装后构建可以,运行就一直提示程序异常
李宏毅2021机器学习笔记(一)_李宏毅2021机器学习笔记 百度-程序员宅基地
文章浏览阅读601次。什么是机器学习?简单来说就是让机器帮我们找一个函数,即一个映射。如声音—>文字的语音识别函数自变量可以是向量,矩阵(图像识别),序列输出是数值、图片等课程讲什么?一、监督学习,给定图片人工的告诉机器其类型,训练模型,让机器拥有 f(图片)—>类型 这一函数二、训练模型之前进行Pre-train,让机器学习如何辨别图片这一基本功,因为人工输入图片类型过于繁琐。只需传入大量图片资料即可自动训练。如把图片翻转、变色,询问机器是不是可以..._李宏毅2021机器学习笔记 百度