Memcached源码分析 - TCP命令解析实现(2)_try_read_command-程序员宅基地
技术标签: Memcache源码分析
目录
10. 向客户端写数据conn_mwrite&transmit
11. 继续解析命令conn_new_cmd&reset_cmd_handler
一、前言
从我们上一章《Memcached源码分析 - Memcached源码分析之基于Libevent的网络模型(1)》我们基本了解了Memcached的网络模型。这一章节,我们需要详细解读Memcached的命令解析。
我们回顾上一章发现Memcached会分成主线程和N个工作线程。主线程主要用于监听accpet客户端的Socket连接,而工作线程主要用于接管具体的客户端连接。
主线程和工作线程之间主要通过基于Libevent的pipe的读写事件来监听,当有连接练上来的时候,主线程会将连接交个某一个工作线程去接管,后期客户端和服务端的读写工作都会在这个工作线程中进行。
工作线程也是基于Libevent的事件的,当有读或者写的事件进来的时候,就会触发事件的回调函数。
那么Memcached是如何来解析客户端上传的命令数据报文的呢?这一章我们详细讲解命令的解析过程,下一章会讲解Memcached对客户端的回应。
二、Memcached的命令解析源码分析
1. 连接句柄数据结构conn
每一个连接都会有自己的一个conn数据结构。这个结构主要存储每个连接的基本信息。
这一章中用到的几个比较重要的参数:
- char * rbuf:用于存储客户端数据报文中的命令。
- int rsize:rbuf的大小。
- char * rcurr:未解析的命令的字符指针。
- int rbytes:未解析的命令的长度。

typedef struct conn conn;
struct conn {
int sfd;
sasl_conn_t *sasl_conn;
bool authenticated;
enum conn_states state;
enum bin_substates substate;
rel_time_t last_cmd_time;
struct event event;
short ev_flags;
short which; /** which events were just triggered */
char *rbuf; /** buffer to read commands into */
char *rcurr; /** but if we parsed some already, this is where we stopped */
int rsize; /** total allocated size of rbuf */
int rbytes; /** how much data, starting from rcur, do we have unparsed */
char *wbuf;
char *wcurr;
int wsize;
int wbytes;
/** which state to go into after finishing current write */
enum conn_states write_and_go;
void *write_and_free; /** free this memory after finishing writing */
char *ritem; /** when we read in an item's value, it goes here */
int rlbytes;
/* data for the nread state */
/**
* item is used to hold an item structure created after reading the command
* line of set/add/replace commands, but before we finished reading the actual
* data. The data is read into ITEM_data(item) to avoid extra copying.
*/
void *item; /* for commands set/add/replace */
/* data for the swallow state */
int sbytes; /* how many bytes to swallow */
/* data for the mwrite state */
struct iovec *iov;
int iovsize; /* number of elements allocated in iov[] */
int iovused; /* number of elements used in iov[] */
struct msghdr *msglist;
int msgsize; /* number of elements allocated in msglist[] */
int msgused; /* number of elements used in msglist[] */
int msgcurr; /* element in msglist[] being transmitted now */
int msgbytes; /* number of bytes in current msg */
item **ilist; /* list of items to write out */
int isize;
item **icurr;
int ileft;
char **suffixlist;
int suffixsize;
char **suffixcurr;
int suffixleft;
enum protocol protocol; /* which protocol this connection speaks */
enum network_transport transport; /* what transport is used by this connection */
/* data for UDP clients */
int request_id; /* Incoming UDP request ID, if this is a UDP "connection" */
struct sockaddr_in6 request_addr; /* udp: Who sent the most recent request */
socklen_t request_addr_size;
unsigned char *hdrbuf; /* udp packet headers */
int hdrsize; /* number of headers' worth of space is allocated */
bool noreply; /* True if the reply should not be sent. */
/* current stats command */
struct {
char *buffer;
size_t size;
size_t offset;
} stats;
/* Binary protocol stuff */
/* This is where the binary header goes */
protocol_binary_request_header binary_header;
uint64_t cas; /* the cas to return */
short cmd; /* current command being processed */
int opaque;
int keylen;
conn *next; /* Used for generating a list of conn structures */
LIBEVENT_THREAD *thread; /* Pointer to the thread object serving this connection */
};2. 状态机流程分析
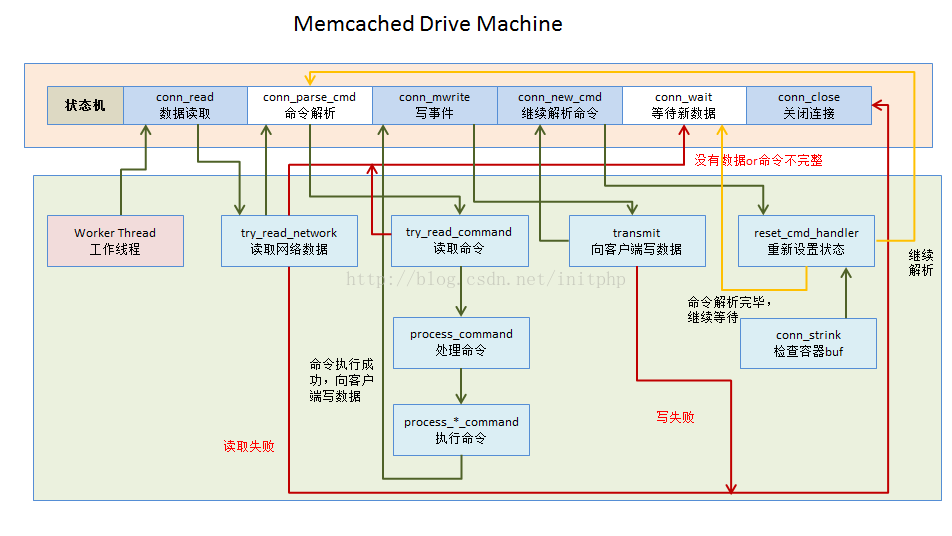
- 当客户端和Memcached建立TCP连接后,Memcached会基于Libevent的event事件来监听客户端是否有可以读取的数据。
- 当客户端有命令数据报文上报的时候,就会触发drive_machine方法中的conn_read这个Case。
- memcached通过try_read_network方法读取客户端的报文。如果读取失败,则返回conn_closing,去关闭客户端的连接;如果没有读取到任何数据,则会返回conn_waiting,继续等待客户端的事件到来,并且退出drive_machine的循环;如果数据读取成功,则会将状态转交给conn_parse_cmd处理,读取到的数据会存储在c->rbuf容器中。
- conn_parse_cmd主要的工作就是用来解析命令。主要通过try_read_command这个方法来读取c->rbuf中的命令数据,通过\n来分隔数据报文的命令。如果c->buf内存块中的数据匹配不到\n,则返回继续等待客户端的命令数据报文到来conn_waiting;否则就会转交给process_command方法,来处理具体的命令(命令解析会通过\0符号来分隔)。
- process_command主要用来处理具体的命令。其中tokenize_command这个方法非常重要,将命令拆解成多个元素(KEY的最大长度250)。例如我们以get命令为例,最终会跳转到process_get_command这个命令 process_*_command这一系列就是处理具体的命令逻辑的。
- 我们进入process_get_command,当获取数据处理完毕之后,会转交到conn_mwrite这个状态。如果获取数据失败,则关闭连接。
- 进入conn_mwrite后,主要是通过transmit方法来向客户端提交数据。如果写数据失败,则关闭连接或退出drive_machine循环;如果写入成功,则又转交到conn_new_cmd这个状态。
- conn_new_cmd这个状态主要是处理c->rbuf中剩余的命令。主要看一下reset_cmd_handler这个方法,这个方法回去判断c->rbytes中是否还有剩余的报文没处理,如果未处理,则转交到conn_parse_cmd(第四步)继续解析剩余命令;如果已经处理了,则转交到conn_waiting,等待新的事件到来。在转交之前,每次都会执行一次conn_shrink方法。
- conn_shrink方法主要用来处理命令报文容器c->rbuf和输出内容的容器是否数据满了?是否需要扩大buffer的大小,是否需要移动内存块。接受命令报文的初始化内存块大小2048,最大8192。
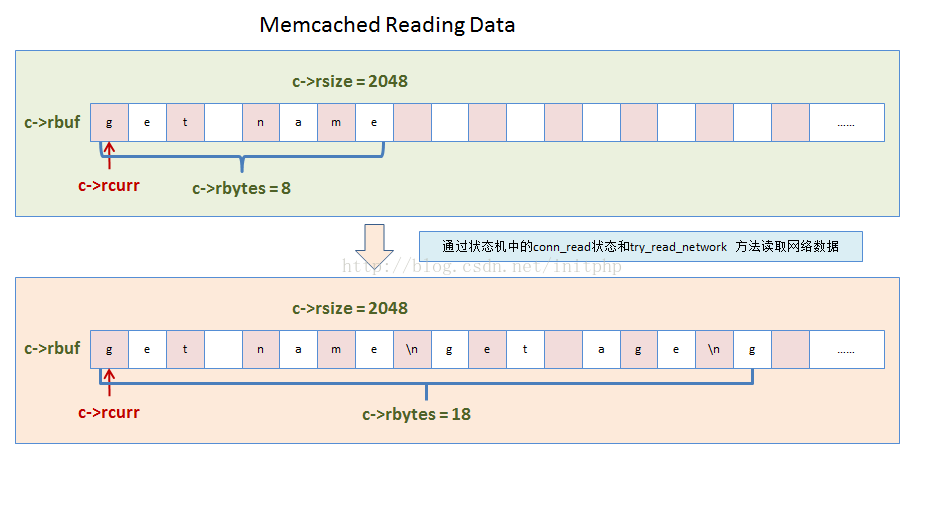
3. 命令的数据结构变化rbuf
1. 读取客户端的数据
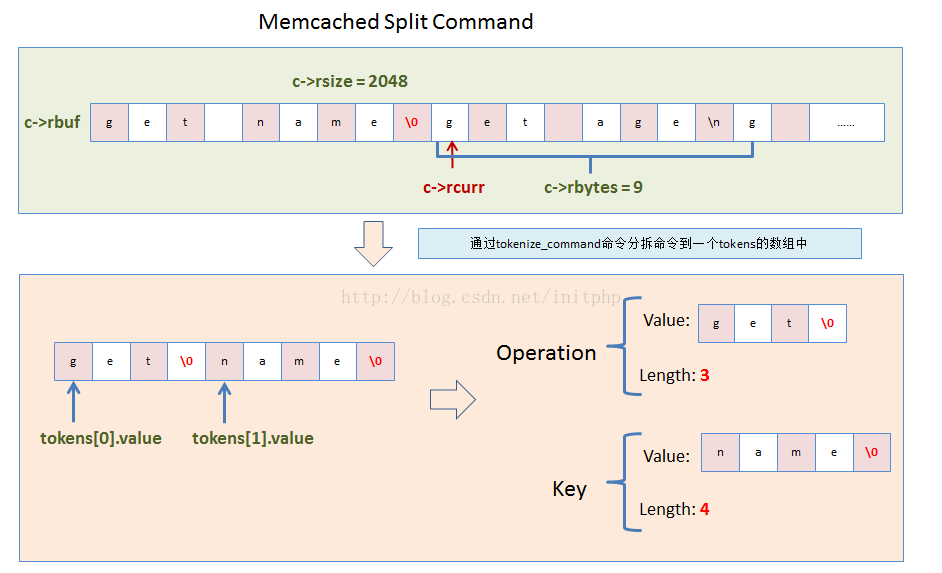
2. 解析buf中的命令。如果遇到\n,则表明是一个命令语句的结尾标识符。

3. 命令拆分。命令解析出来之后,对命令进行分解,分解是通过空格来分离的。第一个参数一般为操作方法,第二个参数一般为KEY。
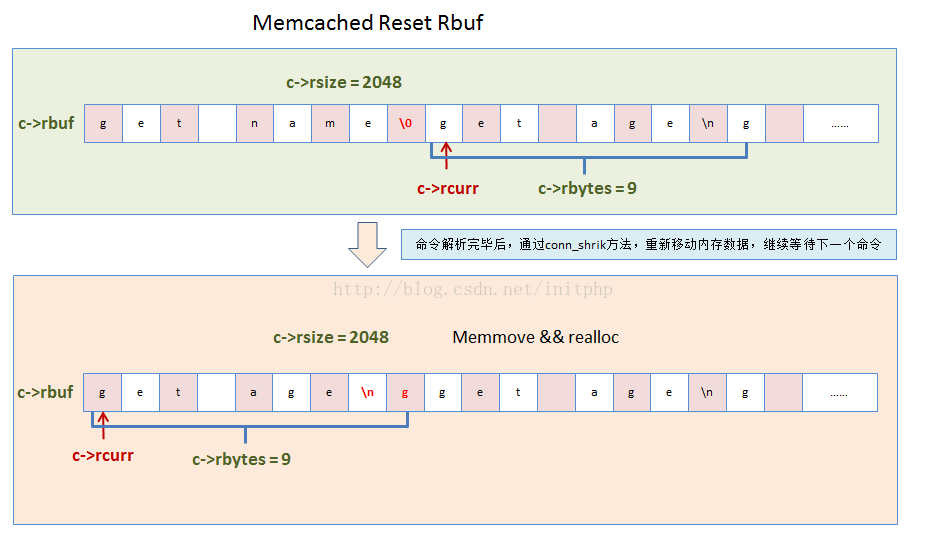
4. 内存块重设置。如果rbuf内存块使用空间不足,或者大于8k,则需要进行重新分配内存块。
4. 状态机启动drive_machine
我们上一节看到客户端连接的读写事件回调函数:event_handler,这个方法中最终调用的是drive_machine。
void event_handler(const int fd, const short which, void *arg) {
conn *c;
//组装conn结构
c = (conn *) arg;
assert(c != NULL);
c->which = which;
/* sanity */
if (fd != c->sfd) {
if (settings.verbose > 0)
fprintf(stderr, "Catastrophic: event fd doesn't match conn fd!\n");
conn_close(c);
return;
}
//最终转交给了drive_machine这个方法
drive_machine(c);
/* wait for next event */
return;
}drive_machine:drive_machine这个方法中,都是通过c->state来判断需要处理的逻辑。
- conn_listening:监听状态
- conn_waiting:等待状态
- conn_read:读取状态
- conn_parse_cmd:命令行解析
- conn_mwrite:向客户端写数据
- conn_new_cmd:解析新的命令
static void drive_machine(conn *c) {
bool stop = false;
int sfd;
socklen_t addrlen;
struct sockaddr_storage addr;
int nreqs = settings.reqs_per_event;
int res;
const char *str;
#ifdef HAVE_ACCEPT4
static int use_accept4 = 1;
#else
static int use_accept4 = 0;
#endif
assert(c != NULL);
while (!stop) {
switch (c->state) {
case conn_listening:
//.......更多代码
}我们继续看一下conn_read、conn_wait和conn_parse_cmd状态的代码。
//这边是继续等待客户端的数据报文到来
case conn_waiting:
if (!update_event(c, EV_READ | EV_PERSIST)) {
if (settings.verbose > 0)
fprintf(stderr, "Couldn't update event\n");
conn_set_state(c, conn_closing);
break;
}
//等待的过程中,将连接状态设置为读取状态,并且stop设置为true,退出while(stop)的循环
conn_set_state(c, conn_read);
stop = true;
break;
//读取数据的事件,当客户端有数据报文上传的时候,就会触发libevent的读事件
case conn_read:
//try_read_network 主要读取TCP数据
//返回try_read_result的枚举类型结构,通过这个枚举类型,来判断是否已经读取到数据,是否读取失败等情况
res = IS_UDP(c->transport) ? try_read_udp(c) : try_read_network(c);
switch (res) {
//没有读取到数据,那么继续将事件设置为等待。
//while(stop)会继续循环,去调用conn_waiting这个case
case READ_NO_DATA_RECEIVED:
conn_set_state(c, conn_waiting);
break;
//如果有数据读取到了,这个时候就需要调用conn_parse_cmd逻辑
//conn_parse_cmd:主要用来解析读取到的命令
case READ_DATA_RECEIVED:
conn_set_state(c, conn_parse_cmd);
break;
//读取失败的状态,则直接调用conn_closing 关闭客户端的连接
case READ_ERROR:
conn_set_state(c, conn_closing);
break;
case READ_MEMORY_ERROR: /* Failed to allocate more memory */
/* State already set by try_read_network */
break;
}
break;
//这边是解析Memcached的客户端命令,例如解析:set username zhuli
case conn_parse_cmd:
//try_read_command方法很关键,用来读取命令
//如果这个方法返回为0,则表示解析命令失败(因为TCP粘包拆包的原因,可能命令不完整,需要继续等待数据到来)
if (try_read_command(c) == 0) {
/* wee need more data! */
//这边的注释貌似写错误了吧,应该是we need more data!
conn_set_state(c, conn_waiting);
}
break;
5. 读取TCP网络数据try_read_network
- 这个方法主要是读取TCP网络数据。读取到的数据会放进c->rbuf的buf中。
- 如果buf没有空间存储更多数据的时候,就会触发内存块的重新分配。重新分配,memcached限制了4次,估计是担忧客户端的恶意攻击导致存储命令行数据报文的buf不断的realloc。
//这个方法是通过TCP的方式读取客户端传递过来的命令数据
static enum try_read_result try_read_network(conn *c) {
//这个方法会最终返回try_read_result的枚举类型
//默认设置READ_NO_DATA_RECEIVED:没有接受到数据
enum try_read_result gotdata = READ_NO_DATA_RECEIVED;
int res;
int num_allocs = 0;
assert(c != NULL);
//c->rcurr 存放未解析命令内容指针 c->rbytes 还有多少没解析过的数据
//c->rbuf 用于读取命令的buf,存储命令字符串的指针 c->rsize rbuf的size
//这边每次都会将前一次剩余的命令报文,移动到c->rbuf的头部。
if (c->rcurr != c->rbuf) {
if (c->rbytes != 0) /* otherwise there's nothing to copy */
memmove(c->rbuf, c->rcurr, c->rbytes);
c->rcurr = c->rbuf;
}
//循环从fd中读取数据
while (1) {
//如果buf满了,则需要重新分配一块更大的内存
//当未解析的数据size 大于等于 buf块的size,则需要重新分配
if (c->rbytes >= c->rsize) {
//最多分配4次
if (num_allocs == 4) {
return gotdata;
}
++num_allocs;
//从新分配一块新的内存块,内存大小为rsize的两倍
char *new_rbuf = realloc(c->rbuf, c->rsize * 2);
if (!new_rbuf) {
STATS_LOCK();
stats.malloc_fails++;
STATS_UNLOCK();
if (settings.verbose > 0) {
fprintf(stderr, "Couldn't realloc input buffer\n");
}
c->rbytes = 0; /* ignore what we read */
out_of_memory(c, "SERVER_ERROR out of memory reading request");
c->write_and_go = conn_closing;
return READ_MEMORY_ERROR;
}
//c->rcurr和c->rbuf指向到新的buf块
c->rcurr = c->rbuf = new_rbuf;
c->rsize *= 2; //rsize则乘以2
}
//avail可以计算出buf块中剩余的空间多大
int avail = c->rsize - c->rbytes;
//这边我们可以看到Socket的读取方法
//c->sfd为Socket的ID
//c->rbuf + c->rbytes 意思是从buf块中空余的内存地址开始存放新读取到的数据
//avail 每次接收最大能读取多大的数据
res = read(c->sfd, c->rbuf + c->rbytes, avail);
//如果接受到的结果res大于0,则说明Socket中读取到了数据
//设置成READ_DATA_RECEIVED枚举类型,表明读取到了数据
if (res > 0) {
pthread_mutex_lock(&c->thread->stats.mutex); //线程锁
c->thread->stats.bytes_read += res;
pthread_mutex_unlock(&c->thread->stats.mutex);
gotdata = READ_DATA_RECEIVED;
c->rbytes += res; //未处理的数据量 + 当前读取到的命令size
if (res == avail) {
continue;
} else {
break;
}
}
//判断读取失败的两种情况
if (res == 0) {
return READ_ERROR;
}
if (res == -1) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
break;
}
return READ_ERROR;
}
}
return gotdata;
}6. 读取rbuf中的命令try_read_command
- 这个方法主要是用来读取rbuf中的命令的。例如命令:set username zhuli\r\n get username \n
- 则会通过\n这个换行符来分隔数据报文中的命令。因为数据报文会有粘包和拆包的特性,所以只有等到命令行完整了才能进行解析。所有只有匹配到了\n符号,才能匹配一个完整的命令。
//如果我们已经在c->rbuf中有可以处理的命令行了,则就可以调用此函数来处理命令解析
static int try_read_command(conn *c) {
assert(c != NULL);
assert(c->rcurr <= (c->rbuf + c->rsize)); //这边断言
assert(c->rbytes > 0);
if (c->protocol == negotiating_prot || c->transport == udp_transport) {
if ((unsigned char) c->rbuf[0] == (unsigned char) PROTOCOL_BINARY_REQ) {
c->protocol = binary_prot;
} else {
c->protocol = ascii_prot;
}
if (settings.verbose > 1) {
fprintf(stderr, "%d: Client using the %s protocol\n", c->sfd,
prot_text(c->protocol));
}
}
//有两种模式,是否是二进制模式还是ascii模式
if (c->protocol == binary_prot) {
//更多代码
} else {
//这边主要处理非二进制模式的命令解析
char *el, *cont;
//如果c->rbytes==0 表示buf容器中没有可以处理的命令报文,则返回0
//0 是让程序继续等待接收新的客户端报文
if (c->rbytes == 0)
return 0;
//查找命令中是否有\n,memcache的命令通过\n来分割
//当客户端的数据报文过来的时候,Memcached通过查找接收到的数据中是否有\n换行符来判断收到的命令数据包是否完整
//例如命令:set username 10234344 \n get username \n
//这个命令就可以分割成两个命令,分别是set和get的命令
//el返回\n的字符指针地址
el = memchr(c->rcurr, '\n', c->rbytes);
//如果没有找到\n,说明命令不完整,则返回0,继续等待接收新的客户端数据报文
if (!el) {
//c->rbytes是接收到的数据包的长度
//这边非常有趣,如果一次接收的数据报文大于了1K,则Memcached回去判断这个请求是否太大了,是否有问题?
//然后会关闭这个客户端的链接
if (c->rbytes > 1024) {
/*
* We didn't have a '\n' in the first k. This _has_ to be a
* large multiget, if not we should just nuke the connection.
*/
char *ptr = c->rcurr;
while (*ptr == ' ') { /* ignore leading whitespaces */
++ptr;
}
if (ptr - c->rcurr > 100
|| (strncmp(ptr, "get ", 4) && strncmp(ptr, "gets ", 5))) {
conn_set_state(c, conn_closing);
return 1;
}
}
return 0;
}
//如果找到了\n,说明c->rcurr中有完整的命令了
cont = el + 1; //下一个命令开始的指针节点
//这边判断是否是\r\n,如果是\r\n,则el往前移一位
if ((el - c->rcurr) > 1 && *(el - 1) == '\r') {
el--;
}
//然后将命令的最后一个字符用 \0(字符串结束符号)来分隔
*el = '\0';
assert(cont <= (c->rcurr + c->rbytes));
c->last_cmd_time = current_time; //最后命令时间
//处理命令,c->rcurr就是命令
process_command(c, c->rcurr);
c->rbytes -= (cont - c->rcurr); //这个地方为何不这样写?c->rbytes = c->rcurr - cont
c->rcurr = cont; //将c->rcurr指向到下一个命令的指针节点
assert(c->rcurr <= (c->rbuf + c->rsize));
}
return 1;
}7. 处理命令函数process_command
这个方法主要用来处理具体的命令。将命令分解后,分发到不同的具体操作中去。
//命令处理函数
//前一个方法中,我们找到了rbuf中\n的字符,然后将其替换成\0
static void process_command(conn *c, char *command) {
//tokens结构,这边会将c->rcurr(command)命令拆分出来
//并且将命令通过空格符号来分隔成多个元素
//例如:set username zhuli,则会拆分成3个元素,分别是set和username和zhuli
//MAX_TOKENS最大值为8,说明memcached的命令行,最多可以拆分成8个元素
token_t tokens[MAX_TOKENS];
size_t ntokens;
int comm;
assert(c != NULL);
MEMCACHED_PROCESS_COMMAND_START(c->sfd, c->rcurr, c->rbytes);
if (settings.verbose > 1)
fprintf(stderr, "<%d %s\n", c->sfd, command);
/*
* for commands set/add/replace, we build an item and read the data
* directly into it, then continue in nread_complete().
*/
c->msgcurr = 0;
c->msgused = 0;
c->iovused = 0;
if (add_msghdr(c) != 0) {
out_of_memory(c, "SERVER_ERROR out of memory preparing response");
return;
}
//tokenize_command非常重要,主要就是拆分命令的
//并且将拆分出来的命令元素放进tokens的数组中
//参数:command为命令
ntokens = tokenize_command(command, tokens, MAX_TOKENS);
//tokens[COMMAND_TOKEN] COMMAND_TOKEN=0
//分解出来的命令的第一个参数为操作方法
if (ntokens >= 3
&& ((strcmp(tokens[COMMAND_TOKEN].value, "get") == 0)
|| (strcmp(tokens[COMMAND_TOKEN].value, "bget") == 0))) {
//处理get命令
process_get_command(c, tokens, ntokens, false);
} else if ((ntokens == 6 || ntokens == 7)
&& ((strcmp(tokens[COMMAND_TOKEN].value, "add") == 0 && (comm =
NREAD_ADD))
|| (strcmp(tokens[COMMAND_TOKEN].value, "set") == 0
&& (comm = NREAD_SET))
|| (strcmp(tokens[COMMAND_TOKEN].value, "replace") == 0
&& (comm = NREAD_REPLACE))
|| (strcmp(tokens[COMMAND_TOKEN].value, "prepend") == 0
&& (comm = NREAD_PREPEND))
|| (strcmp(tokens[COMMAND_TOKEN].value, "append") == 0
&& (comm = NREAD_APPEND)))) {
//处理更新命令
process_update_command(c, tokens, ntokens, comm, false);
//更多代码....
}8. 分解命令tokenize_command
- 这个方法主要用于分解命令。具体是将一个命令语句分解成多个元素。
- 例如:set username zhuli\n
- 则会分解成三个元素:set和username和zhuli这三个元素。
//拆分命令方法
static size_t tokenize_command(char *command, token_t *tokens,
const size_t max_tokens) {
char *s, *e;
size_t ntokens = 0; //命令参数游标
size_t len = strlen(command); //命令长度
unsigned int i = 0;
assert(command != NULL && tokens != NULL && max_tokens > 1);
s = e = command;
for (i = 0; i < len; i++) {
//指针不停往前走,如果遇到空格,则会停下来,将命令元素拆分出来,放进tokens这个数组中
if (*e == ' ') {
if (s != e) {
tokens[ntokens].value = s;
tokens[ntokens].length = e - s;
ntokens++;
//这边将空格替换成\0
//Memcached这边的代码写的非常的好,这边的命令进行切割的时候,并没有将内存块进行拷贝,而是在原来的内存块上进行切割
*e = '\0';
//最多8个元素
if (ntokens == max_tokens - 1) {
e++;
s = e; /* so we don't add an extra token */
break;
}
}
s = e + 1;
}
e++;
}
if (s != e) {
tokens[ntokens].value = s;
tokens[ntokens].length = e - s;
ntokens++;
}
/*
* If we scanned the whole string, the terminal value pointer is null,
* otherwise it is the first unprocessed character.
*/
tokens[ntokens].value = *e == '\0' ? NULL : e;
tokens[ntokens].length = 0;
ntokens++;
//返回值为参数个数,例如分解出3个元素,则返回3
return ntokens;
}9. get命令处理process_get_command
get的命令例子。get请求拿到Memcached Item中的数据后,又会跳转到conn_mwrite这个状态,将进入向客户端写数据的状态。
//处理GET请求的命令
static inline void process_get_command(conn *c, token_t *tokens, size_t ntokens,
bool return_cas) {
//处理GET命令
char *key;
size_t nkey;
int i = 0;
item *it;
//&tokens[0] 是操作的方法
//&tokens[1] 为key
//token_t 存储了value和length
token_t *key_token = &tokens[KEY_TOKEN];
char *suffix;
assert(c != NULL);
do {
//如果key的长度不为0
while (key_token->length != 0) {
key = key_token->value;
nkey = key_token->length;
//判断key的长度是否超过了最大的长度,memcache key的最大长度为250
//这个地方需要非常注意,我们在平常的使用中,还是要注意key的字节长度的
if (nkey > KEY_MAX_LENGTH) {
//out_string 向外部输出数据
out_string(c, "CLIENT_ERROR bad command line format");
while (i-- > 0) {
item_remove(*(c->ilist + i));
}
return;
}
//这边是从Memcached的内存存储快中去取数据
it = item_get(key, nkey);
if (settings.detail_enabled) {
//状态记录,key的记录数的方法
stats_prefix_record_get(key, nkey, NULL != it);
}
//如果获取到了数据
if (it) {
//c->ilist 存放用于向外部写数据的buf
//如果ilist太小,则重新分配一块内存
if (i >= c->isize) {
item **new_list = realloc(c->ilist,
sizeof(item *) * c->isize * 2);
if (new_list) {
c->isize *= 2;
c->ilist = new_list;
} else {
STATS_LOCK();
stats.malloc_fails++;
STATS_UNLOCK();
item_remove(it);
break;
}
}
/*
* Construct the response. Each hit adds three elements to the
* outgoing data list:
* "VALUE "
* key
* " " + flags + " " + data length + "\r\n" + data (with \r\n)
*/
//初始化返回出去的数据结构
if (return_cas) {
MEMCACHED_COMMAND_GET(c->sfd, ITEM_key(it), it->nkey,
it->nbytes, ITEM_get_cas(it));
/* Goofy mid-flight realloc. */
if (i >= c->suffixsize) {
char **new_suffix_list = realloc(c->suffixlist,
sizeof(char *) * c->suffixsize * 2);
if (new_suffix_list) {
c->suffixsize *= 2;
c->suffixlist = new_suffix_list;
} else {
STATS_LOCK();
stats.malloc_fails++;
STATS_UNLOCK();
item_remove(it);
break;
}
}
suffix = cache_alloc(c->thread->suffix_cache);
if (suffix == NULL) {
STATS_LOCK();
stats.malloc_fails++;
STATS_UNLOCK();
out_of_memory(c,
"SERVER_ERROR out of memory making CAS suffix");
item_remove(it);
while (i-- > 0) {
item_remove(*(c->ilist + i));
}
return;
}
*(c->suffixlist + i) = suffix;
int suffix_len = snprintf(suffix, SUFFIX_SIZE, " %llu\r\n",
(unsigned long long) ITEM_get_cas(it));
if (add_iov(c, "VALUE ", 6) != 0
|| add_iov(c, ITEM_key(it), it->nkey) != 0
|| add_iov(c, ITEM_suffix(it), it->nsuffix - 2) != 0
|| add_iov(c, suffix, suffix_len) != 0
|| add_iov(c, ITEM_data(it), it->nbytes) != 0) {
item_remove(it);
break;
}
} else {
MEMCACHED_COMMAND_GET(c->sfd, ITEM_key(it), it->nkey,
it->nbytes, ITEM_get_cas(it));
if (add_iov(c, "VALUE ", 6) != 0
|| add_iov(c, ITEM_key(it), it->nkey) != 0
|| add_iov(c, ITEM_suffix(it),
it->nsuffix + it->nbytes) != 0) {
item_remove(it);
break;
}
}
if (settings.verbose > 1) {
int ii;
fprintf(stderr, ">%d sending key ", c->sfd);
for (ii = 0; ii < it->nkey; ++ii) {
fprintf(stderr, "%c", key[ii]);
}
fprintf(stderr, "\n");
}
/* item_get() has incremented it->refcount for us */
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.slab_stats[it->slabs_clsid].get_hits++;
c->thread->stats.get_cmds++;
pthread_mutex_unlock(&c->thread->stats.mutex);
item_update(it);
*(c->ilist + i) = it;
i++;
} else {
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.get_misses++;
c->thread->stats.get_cmds++;
pthread_mutex_unlock(&c->thread->stats.mutex);
MEMCACHED_COMMAND_GET(c->sfd, key, nkey, -1, 0);
}
key_token++;
}
/*
* If the command string hasn't been fully processed, get the next set
* of tokens.
*/
//如果命令行中的命令没有全部被处理,则继续下一个命令
//一个命令行中,可以get多个元素
if (key_token->value != NULL) {
ntokens = tokenize_command(key_token->value, tokens, MAX_TOKENS);
key_token = tokens;
}
} while (key_token->value != NULL);
c->icurr = c->ilist;
c->ileft = i;
if (return_cas) {
c->suffixcurr = c->suffixlist;
c->suffixleft = i;
}
if (settings.verbose > 1)
fprintf(stderr, ">%d END\n", c->sfd);
/*
If the loop was terminated because of out-of-memory, it is not
reliable to add END\r\n to the buffer, because it might not end
in \r\n. So we send SERVER_ERROR instead.
*/
if (key_token->value != NULL || add_iov(c, "END\r\n", 5) != 0
|| (IS_UDP(c->transport) && build_udp_headers(c) != 0)) {
out_of_memory(c, "SERVER_ERROR out of memory writing get response");
} else {
//将状态修改为写,这边读取到item的数据后,又开始需要往客户端写数据了。
conn_set_state(c, conn_mwrite);
c->msgcurr = 0;
}
}10. 向客户端写数据conn_mwrite&transmit
主要用于向客户端写数据。写完数据后,如果写失败,则关闭连接;如果写成功,则会将状态修改成conn_new_cmd,继续解析c->rbuf中剩余的命令
//drive_machine方法
//这个conn_mwrite是向客户端写数据
case conn_mwrite:
if (IS_UDP(c->transport) && c->msgcurr == 0
&& build_udp_headers(c) != 0) {
if (settings.verbose > 0)
fprintf(stderr, "Failed to build UDP headers\n");
conn_set_state(c, conn_closing);
break;
}
//transmit这个方法非常重要,主要向客户端写数据的操作都在这个方法中进行
//返回transmit_result枚举类型,用于判断是否写成功,如果失败,则关闭连接
switch (transmit(c)) {
//如果向客户端发送数据成功
case TRANSMIT_COMPLETE:
if (c->state == conn_mwrite) {
conn_release_items(c);
/* XXX: I don't know why this wasn't the general case */
if (c->protocol == binary_prot) {
conn_set_state(c, c->write_and_go);
} else {
//这边是TCP的状态
//状态又会切回到conn_new_cmd这个状态
//conn_new_cmd主要是继续解析c->rbuf容器中剩余的命令参数
conn_set_state(c, conn_new_cmd);
}
} else if (c->state == conn_write) {
if (c->write_and_free) {
free(c->write_and_free);
c->write_and_free = 0;
}
conn_set_state(c, c->write_and_go);
} else {
if (settings.verbose > 0)
fprintf(stderr, "Unexpected state %d\n", c->state);
conn_set_state(c, conn_closing);
}
break;
case TRANSMIT_INCOMPLETE:
case TRANSMIT_HARD_ERROR:
break; /* Continue in state machine. */
//失败的情况
case TRANSMIT_SOFT_ERROR:
stop = true;
break;
}
break;
这个方法主要是向客户端发送数据。
//这个方法主要向客户端写数据
static enum transmit_result transmit(conn *c) {
assert(c != NULL);
if (c->msgcurr < c->msgused && c->msglist[c->msgcurr].msg_iovlen == 0) {
/* Finished writing the current msg; advance to the next. */
c->msgcurr++;
}
if (c->msgcurr < c->msgused) {
ssize_t res;
//msghdr 发送数据的结构
struct msghdr *m = &c->msglist[c->msgcurr];
//sendmsg 发送数据方法
res = sendmsg(c->sfd, m, 0);
//发送成功
if (res > 0) {
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.bytes_written += res;
pthread_mutex_unlock(&c->thread->stats.mutex);
/* We've written some of the data. Remove the completed
iovec entries from the list of pending writes. */
while (m->msg_iovlen > 0 && res >= m->msg_iov->iov_len) {
res -= m->msg_iov->iov_len;
m->msg_iovlen--;
m->msg_iov++;
}
/* Might have written just part of the last iovec entry;
adjust it so the next write will do the rest. */
if (res > 0) {
m->msg_iov->iov_base = (caddr_t) m->msg_iov->iov_base + res;
m->msg_iov->iov_len -= res;
}
return TRANSMIT_INCOMPLETE;
}
if (res == -1 && (errno == EAGAIN || errno == EWOULDBLOCK)) {
if (!update_event(c, EV_WRITE | EV_PERSIST)) {
if (settings.verbose > 0)
fprintf(stderr, "Couldn't update event\n");
conn_set_state(c, conn_closing);
return TRANSMIT_HARD_ERROR;
}
return TRANSMIT_SOFT_ERROR;
}
/* if res == 0 or res == -1 and error is not EAGAIN or EWOULDBLOCK,
we have a real error, on which we close the connection */
if (settings.verbose > 0)
perror("Failed to write, and not due to blocking");
if (IS_UDP(c->transport))
conn_set_state(c, conn_read);
else
conn_set_state(c, conn_closing);
return TRANSMIT_HARD_ERROR;
} else {
return TRANSMIT_COMPLETE;
}
}11. 继续解析命令conn_new_cmd&reset_cmd_handler
继续解析c->rbuf中剩余的命令。
//处理c->rbuf中剩余的命令
case conn_new_cmd:
/* Only process nreqs at a time to avoid starving other
connections */
--nreqs;
if (nreqs >= 0) {
reset_cmd_handler(c); //会跳转到reset_cmd_handler这个方法
} else {
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.conn_yields++;
pthread_mutex_unlock(&c->thread->stats.mutex);
if (c->rbytes > 0) {
/* We have already read in data into the input buffer,
so libevent will most likely not signal read events
on the socket (unless more data is available. As a
hack we should just put in a request to write data,
because that should be possible ;-)
*/
if (!update_event(c, EV_WRITE | EV_PERSIST)) {
if (settings.verbose > 0)
fprintf(stderr, "Couldn't update event\n");
conn_set_state(c, conn_closing);
break;
}
}
stop = true;
}
break;//重新设置命令handler
static void reset_cmd_handler(conn *c) {
c->cmd = -1;
c->substate = bin_no_state;
if (c->item != NULL) {
item_remove(c->item);
c->item = NULL;
}
conn_shrink(c); //这个方法是检查c->rbuf容器的大小
//如果剩余未解析的命令 > 0的话,继续跳转到conn_parse_cmd解析命令
if (c->rbytes > 0) {
conn_set_state(c, conn_parse_cmd);
} else {
//如果命令都解析完成了,则继续等待新的数据到来
conn_set_state(c, conn_waiting);
}
}12. 容器状态检测conn_shrink
这个方法主要检查命令行容器的大小。
//检查rbuf的大小
static void conn_shrink(conn *c) {
assert(c != NULL);
if (IS_UDP(c->transport))
return;
//如果bufsize大于READ_BUFFER_HIGHWAT(8192)的时候需要重新处理
//DATA_BUFFER_SIZE等于2048,所以我们可以看到之前的代码中对rbuf最多只能进行4次recalloc
if (c->rsize > READ_BUFFER_HIGHWAT && c->rbytes < DATA_BUFFER_SIZE) {
char *newbuf;
if (c->rcurr != c->rbuf)
memmove(c->rbuf, c->rcurr, (size_t) c->rbytes); //内存移动
newbuf = (char *) realloc((void *) c->rbuf, DATA_BUFFER_SIZE);
if (newbuf) {
c->rbuf = newbuf;
c->rsize = DATA_BUFFER_SIZE;
}
/* TODO check other branch... */
c->rcurr = c->rbuf;
}
if (c->isize > ITEM_LIST_HIGHWAT) {
item **newbuf = (item**) realloc((void *) c->ilist,
ITEM_LIST_INITIAL * sizeof(c->ilist[0]));
if (newbuf) {
c->ilist = newbuf;
c->isize = ITEM_LIST_INITIAL;
}
/* TODO check error condition? */
}
if (c->msgsize > MSG_LIST_HIGHWAT) {
struct msghdr *newbuf = (struct msghdr *) realloc((void *) c->msglist,
MSG_LIST_INITIAL * sizeof(c->msglist[0]));
if (newbuf) {
c->msglist = newbuf;
c->msgsize = MSG_LIST_INITIAL;
}
/* TODO check error condition? */
}
if (c->iovsize > IOV_LIST_HIGHWAT) {
struct iovec *newbuf = (struct iovec *) realloc((void *) c->iov,
IOV_LIST_INITIAL * sizeof(c->iov[0]));
if (newbuf) {
c->iov = newbuf;
c->iovsize = IOV_LIST_INITIAL;
}
/* TODO check return value */
}
}
智能推荐
稀疏编码的数学基础与理论分析-程序员宅基地
文章浏览阅读290次,点赞8次,收藏10次。1.背景介绍稀疏编码是一种用于处理稀疏数据的编码技术,其主要应用于信息传输、存储和处理等领域。稀疏数据是指数据中大部分元素为零或近似于零的数据,例如文本、图像、音频、视频等。稀疏编码的核心思想是将稀疏数据表示为非零元素和它们对应的位置信息,从而减少存储空间和计算复杂度。稀疏编码的研究起源于1990年代,随着大数据时代的到来,稀疏编码技术的应用范围和影响力不断扩大。目前,稀疏编码已经成为计算...
EasyGBS国标流媒体服务器GB28181国标方案安装使用文档-程序员宅基地
文章浏览阅读217次。EasyGBS - GB28181 国标方案安装使用文档下载安装包下载,正式使用需商业授权, 功能一致在线演示在线API架构图EasySIPCMSSIP 中心信令服务, 单节点, 自带一个 Redis Server, 随 EasySIPCMS 自启动, 不需要手动运行EasySIPSMSSIP 流媒体服务, 根..._easygbs-windows-2.6.0-23042316使用文档
【Web】记录巅峰极客2023 BabyURL题目复现——Jackson原生链_原生jackson 反序列化链子-程序员宅基地
文章浏览阅读1.2k次,点赞27次,收藏7次。2023巅峰极客 BabyURL之前AliyunCTF Bypassit I这题考查了这样一条链子:其实就是Jackson的原生反序列化利用今天复现的这题也是大同小异,一起来整一下。_原生jackson 反序列化链子
一文搞懂SpringCloud,详解干货,做好笔记_spring cloud-程序员宅基地
文章浏览阅读734次,点赞9次,收藏7次。微服务架构简单的说就是将单体应用进一步拆分,拆分成更小的服务,每个服务都是一个可以独立运行的项目。这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除])这么多小服务,他们之间如何通讯?这么多小服务,客户端怎么访问他们?(网关)这么多小服务,一旦出现问题了,应该如何自处理?(容错)这么多小服务,一旦出现问题了,应该如何排错?(链路追踪)对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一个问题提供了相应的组件来解决它们。_spring cloud
Js实现图片点击切换与轮播-程序员宅基地
文章浏览阅读5.9k次,点赞6次,收藏20次。Js实现图片点击切换与轮播图片点击切换<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title></title> <script type="text/ja..._点击图片进行轮播图切换
tensorflow-gpu版本安装教程(过程详细)_tensorflow gpu版本安装-程序员宅基地
文章浏览阅读10w+次,点赞245次,收藏1.5k次。在开始安装前,如果你的电脑装过tensorflow,请先把他们卸载干净,包括依赖的包(tensorflow-estimator、tensorboard、tensorflow、keras-applications、keras-preprocessing),不然后续安装了tensorflow-gpu可能会出现找不到cuda的问题。cuda、cudnn。..._tensorflow gpu版本安装
随便推点
物联网时代 权限滥用漏洞的攻击及防御-程序员宅基地
文章浏览阅读243次。0x00 简介权限滥用漏洞一般归类于逻辑问题,是指服务端功能开放过多或权限限制不严格,导致攻击者可以通过直接或间接调用的方式达到攻击效果。随着物联网时代的到来,这种漏洞已经屡见不鲜,各种漏洞组合利用也是千奇百怪、五花八门,这里总结漏洞是为了更好地应对和预防,如有不妥之处还请业内人士多多指教。0x01 背景2014年4月,在比特币飞涨的时代某网站曾经..._使用物联网漏洞的使用者
Visual Odometry and Depth Calculation--Epipolar Geometry--Direct Method--PnP_normalized plane coordinates-程序员宅基地
文章浏览阅读786次。A. Epipolar geometry and triangulationThe epipolar geometry mainly adopts the feature point method, such as SIFT, SURF and ORB, etc. to obtain the feature points corresponding to two frames of images. As shown in Figure 1, let the first image be and th_normalized plane coordinates
开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先抽取关系)_语义角色增强的关系抽取-程序员宅基地
文章浏览阅读708次,点赞2次,收藏3次。开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先关系再实体)一.第二代开放信息抽取系统背景 第一代开放信息抽取系统(Open Information Extraction, OIE, learning-based, 自学习, 先抽取实体)通常抽取大量冗余信息,为了消除这些冗余信息,诞生了第二代开放信息抽取系统。二.第二代开放信息抽取系统历史第二代开放信息抽取系统着眼于解决第一代系统的三大问题: 大量非信息性提取(即省略关键信息的提取)、_语义角色增强的关系抽取
10个顶尖响应式HTML5网页_html欢迎页面-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏51次。快速完成网页设计,10个顶尖响应式HTML5网页模板助你一臂之力为了寻找一个优质的网页模板,网页设计师和开发者往往可能会花上大半天的时间。不过幸运的是,现在的网页设计师和开发人员已经开始共享HTML5,Bootstrap和CSS3中的免费网页模板资源。鉴于网站模板的灵活性和强大的功能,现在广大设计师和开发者对html5网站的实际需求日益增长。为了造福大众,Mockplus的小伙伴整理了2018年最..._html欢迎页面
计算机二级 考试科目,2018全国计算机等级考试调整,一、二级都增加了考试科目...-程序员宅基地
文章浏览阅读282次。原标题:2018全国计算机等级考试调整,一、二级都增加了考试科目全国计算机等级考试将于9月15-17日举行。在备考的最后冲刺阶段,小编为大家整理了今年新公布的全国计算机等级考试调整方案,希望对备考的小伙伴有所帮助,快随小编往下看吧!从2018年3月开始,全国计算机等级考试实施2018版考试大纲,并按新体系开考各个考试级别。具体调整内容如下:一、考试级别及科目1.一级新增“网络安全素质教育”科目(代..._计算机二级增报科目什么意思
conan简单使用_apt install conan-程序员宅基地
文章浏览阅读240次。conan简单使用。_apt install conan