pytorch一步一步在VGG16上训练自己的数据集_torch vgg训练自己的数据集-程序员宅基地
技术标签: CRNN图像序列预测 数据集加载 pytorch
准备数据集及加载,ImageFolder
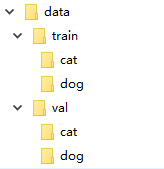
在很多机器学习或者深度学习的任务中,往往我们要提供自己的图片。也就是说我们的数据集不是预先处理好的,像mnist,cifar10等它已经给你处理好了,更多的是原始的图片。比如我们以猫狗分类为例。在data文件下,有两个分别为train和val的文件夹。然后train下是cat和dog两个文件夹,里面存的是自己的图片数据,val文件夹同train。这样我们的数据集就准备好了。
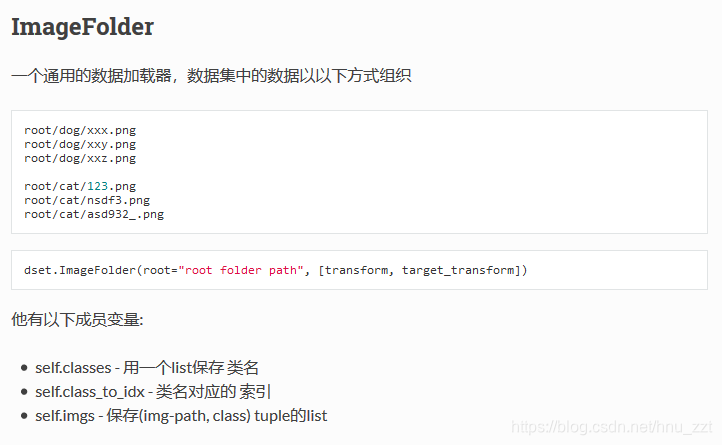
ImageFolder能够以目录名作为标签来对数据集做划分,下面是pytorch中文文档中关于ImageFolder的介绍:
#对训练集做一个变换
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(224), #对图片尺寸做一个缩放切割
transforms.RandomHorizontalFlip(), #水平翻转
transforms.ToTensor(), #转化为张量
transforms.Normalize((.5, .5, .5), (.5, .5, .5)) #进行归一化
])
#对测试集做变换
val_transforms = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
train_dir = "G:/data/train" #训练集路径
#定义数据集
train_datasets = datasets.ImageFolder(train_dir, transform=train_transforms)
#加载数据集
train_dataloader = torch.utils.data.DataLoader(train_datasets, batch_size=batch_size, shuffle=True)
val_dir = "G:/datat/val"
val_datasets = datasets.ImageFolder(val_dir, transform=val_transforms)
val_dataloader = torch.utils.data.DataLoader(val_datasets, batch_size=batch_size, shuffle=True)
迁移学习以VGG16为例
下面是迁移代码的实现:
class VGGNet(nn.Module):
def __init__(self, num_classes=2): #num_classes,此处为 二分类值为2
super(VGGNet, self).__init__()
net = models.vgg16(pretrained=True) #从预训练模型加载VGG16网络参数
net.classifier = nn.Sequential() #将分类层置空,下面将改变我们的分类层
self.features = net #保留VGG16的特征层
self.classifier = nn.Sequential( #定义自己的分类层
nn.Linear(512 * 7 * 7, 512), #512 * 7 * 7不能改变 ,由VGG16网络决定的,第二个参数为神经元个数可以微调
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 128),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(128, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
完整代码如下
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
import numpy as np
from torchvision import models
batch_size = 16
learning_rate = 0.0002
epoch = 10
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
val_transforms = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
train_dir = './VGGDataSet/train'
train_datasets = datasets.ImageFolder(train_dir, transform=train_transforms)
train_dataloader = torch.utils.data.DataLoader(train_datasets, batch_size=batch_size, shuffle=True)
val_dir = './VGGDataSet/val'
val_datasets = datasets.ImageFolder(val_dir, transform=val_transforms)
val_dataloader = torch.utils.data.DataLoader(val_datasets, batch_size=batch_size, shuffle=True)
class VGGNet(nn.Module):
def __init__(self, num_classes=3):
super(VGGNet, self).__init__()
net = models.vgg16(pretrained=True)
net.classifier = nn.Sequential()
self.features = net
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 512),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 128),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(128, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
#--------------------训练过程---------------------------------
model = VGGNet()
if torch.cuda.is_available():
model.cuda()
params = [{'params': md.parameters()} for md in model.children()
if md in [model.classifier]]
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
loss_func = nn.CrossEntropyLoss()
Loss_list = []
Accuracy_list = []
for epoch in range(100):
print('epoch {}'.format(epoch + 1))
# training-----------------------------
train_loss = 0.
train_acc = 0.
for batch_x, batch_y in train_dataloader:
batch_x, batch_y = Variable(batch_x).cuda(), Variable(batch_y).cuda()
out = model(batch_x)
loss = loss_func(out, batch_y)
train_loss += loss.data[0]
pred = torch.max(out, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.data[0]
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(
train_datasets)), train_acc / (len(train_datasets))))
# evaluation--------------------------------
model.eval()
eval_loss = 0.
eval_acc = 0.
for batch_x, batch_y in val_dataloader:
batch_x, batch_y = Variable(batch_x, volatile=True).cuda(), Variable(batch_y, volatile=True).cuda()
out = model(batch_x)
loss = loss_func(out, batch_y)
eval_loss += loss.data[0]
pred = torch.max(out, 1)[1]
num_correct = (pred == batch_y).sum()
eval_acc += num_correct.data[0]
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
val_datasets)), eval_acc / (len(val_datasets))))
Loss_list.append(eval_loss / (len(val_datasets)))
Accuracy_list.append(100 * eval_acc / (len(val_datasets)))
x1 = range(0, 100)
x2 = range(0, 100)
y1 = Accuracy_list
y2 = Loss_list
plt.subplot(2, 1, 1)
plt.plot(x1, y1, 'o-')
plt.title('Test accuracy vs. epoches')
plt.ylabel('Test accuracy')
plt.subplot(2, 1, 2)
plt.plot(x2, y2, '.-')
plt.xlabel('Test loss vs. epoches')
plt.ylabel('Test loss')
plt.show()
# plt.savefig("accuracy_loss.jpg")
智能推荐
【数字信号处理】关于实现FIR滤波器的一些问题_信号与fir滤波器长度不同-程序员宅基地
文章浏览阅读2.8k次。在知乎上看到了一个提问,稍微整理了一下关于这些问题的回答https://www.zhihu.com/question/29945169FIR其实就是下面这个公式,其中数组x[]为输入,数组h[]为滤波参数(已知),数组y[]为滤波输出:问题1“实现FIR滤波过程就是上面这个过程?这么简单?还是自己理解错了根本不是这么回事?(想确认:对于实现这块,上面的理解对不对)”从理论上,FIR就是上面这个过程,但是做成实际使用的系统会遇到各种问题阻止你实现这个公式。情况1:已知FIR滤波器在时域的序列这可_信号与fir滤波器长度不同
用JavaScript实现选项卡功能,当选择全选按钮的时候,下边的复选框所以按钮被选中,当取消一个复选框按钮时,全选框按钮失去效果,当再次把所有复选框按钮选择实现全选_、实现操作复选框,要求是可以选择部分选项,也可以全选,全选按钮的状态根据选中的选项个数自动变化,即全-程序员宅基地
文章浏览阅读779次。点击全选,让下边的按钮都被选中,以及复选框的交互简单上代码啦~~CSS样式<style> * { padding: 0; margin: 0; } .wrap { width: 300px; margin: 100px auto 0; } table { border-collapse: _、实现操作复选框,要求是可以选择部分选项,也可以全选,全选按钮的状态根据选中的选项个数自动变化,即全选按钮的状态回自动取消或者自动勾选。
http请求工具类HttpClientUtil(get使用body,post乱码问题解决)_((httpentityenclosingrequestbase) httppost.setenti-程序员宅基地
文章浏览阅读3.4k次。最近很多发送http请求的需求存在,书写下util1:配置需要的依赖在pom.xml中配置http相关依赖 <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <s..._((httpentityenclosingrequestbase) httppost.setentity(new inputstreamentity(i
【原创】超全自用idea常用插件记录_idea feign插件-程序员宅基地
文章浏览阅读1.7k次。注:idea插件可以使用账号同步,建议使用账号同步进行设置,这里作为使用记录_idea feign插件
回文日期_输出回文日期-程序员宅基地
文章浏览阅读3.1k次。链接:https://ac.nowcoder.com/acm/contest/216/A来源:牛客网 题目描述众所周知,小K是nowcoder的暴政苟管理,所以小K很擅长踢树,虽然本题与踢树无关小K喜欢将日期排列成yyyy-mm-dd的形式(位数不足添零补齐)的形式,虽然这与小K只会做回文字符串这道水题无关,但小K觉得日期组成的回文串也是挺可爱的。作为一个凉心出题人,小K决定给你一..._输出回文日期
深入了解C语言(函数的参数传递和函数使用参数的方法) _c语言中prog03_06了解函数-程序员宅基地
文章浏览阅读1k次。 深入了解C语言(函数的参数传递和函数使用参数的方法) 深入了解C语言(函数的参数传递和函数使用参数的方法)tangl_99(原作) C语言生成的代码在执行效率上比其它高级语言都高.现在让我们来看看C语言生成的代码具体是什么样子的.当你看完本文对于C语言的了解一定会更深一步了. 本文通过一个个实际案例程序来讲解C语言. 研究案例一 工具: Turboc C v2.0,Debug_c语言中prog03_06了解函数
随便推点
3DREM16P-7X/250YG24-8K4V比例减压阀放大器-程序员宅基地
文章浏览阅读106次。比例溢流阀是一种液压压力控制阀,它通过弹簧力的大小改变溢流压力大小变化。比例电磁铁作用在弹簧上的力可以按比例调整,所以就输入信号变化比例溢流阀的压力也会变化。普通溢流阀与比例溢流阀一样,都有一个阀芯,阀芯的一端是液压油产生的压力,另一端是机械力。普通溢流阀通过调节弹簧力,来调整液压压力。而比例溢流阀是电磁铁直接产生推力,作用在阀芯上,电磁铁上的输入电压可以在0-24伏之间变化,产生的推力就随之变化,从而得到连续变化的液压压力。
python文件操作(open()、write()、writelines()、read()、readline()、readlines()、seek()、os)_python open writeline-程序员宅基地
文章浏览阅读3.7k次,点赞4次,收藏23次。python文件操作(open()、write()、writelines()、read()、readline()、readlines()、seek()、os)_python open writeline
分布式限流实战--redis实现令牌桶限流_分布式令牌限流-程序员宅基地
文章浏览阅读9.5k次,点赞4次,收藏43次。这篇文章我们主要是分析一下分布式限流的玩法。 因为限流也是一个经典用法了。1.微服务限流随着微服务的流行,服务和服务之间的稳定性变得越来越重要。缓存、降级和限流是保护微服务系统运行稳定性的三大利器。缓存的目的是提升系统访问速度和增大系统能处理的容量,而降级是当服务出问题或者影响到核心流程的性能则需要暂时屏蔽掉,待高峰或者问题解决后再打开,而有些场景并不能用缓存和降级来解决,比如稀缺资源、数据库的写操作、频繁的复杂查询,因此需有一种手段来限制这些场景的请求量,即限流。比如当我们设计了一个函数,准备上线_分布式令牌限流
【Linux】文件系统-程序员宅基地
文章浏览阅读1.7k次,点赞27次,收藏22次。了解磁盘的物理结构、磁盘的具体物理结构、逻辑抽象、软硬连接,动静态库
python实现ks算法_python, 在信用评级中,计算KS statistic值-程序员宅基地
文章浏览阅读456次。# -*- coding: utf-8 -*-import pandas as pdfrom sklearn.grid_search import GridSearchCVfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.u..._ks_statistic
类加载过程 与 代码的执行顺序_类加载后代码的执行顺序-程序员宅基地
文章浏览阅读5k次。https://www.cnblogs.com/ysocean/p/8194428.html 代码的执行顺序https://www.jianshu.com/p/3556a6cca7e5类加载过程_类加载后代码的执行顺序