Redis源码解析——有序整数集_intrev32-程序员宅基地
技术标签: 开源项目 Redis 缓存 开源项目解析、实现及使用 数据库 redis
有序整数集是Redis源码中一个以大尾(big endian)形式存储,由小到大排列且无重复的整型集合。它存储的类型包括16位、32位和64位的整型数。在介绍这个库的实现前,我们还需要先熟悉下大小尾内存存储机制。(转载请指明出于breaksoftware的csdn博客)
大小尾(Big Endian/Little Endian)
第一次接触这个概念还是在大学时上“计算机原理”时,当时只是简单的知道它的特点,但是丝毫没有深究它们产生的原因和特点。这次借着解析Redis源码,重新学习了一下大小尾。
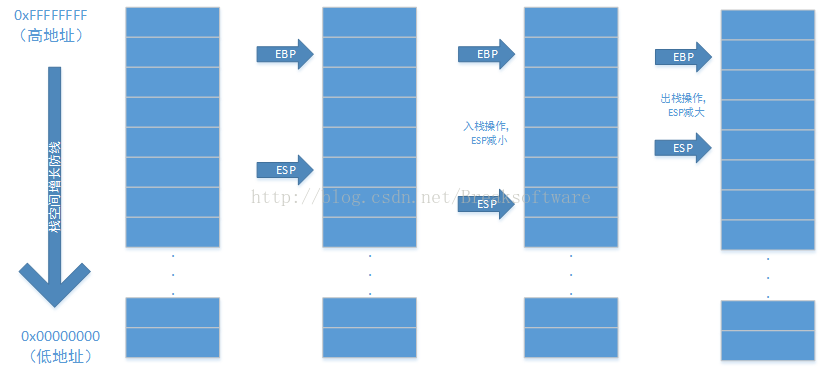
如果进行过逆向的同学一般都会知道ESP指针的作用,它指向当前函数栈Frame的栈顶。相应的,EBP寄存器指向当前函数栈Frame的栈底。在逆向的汇编代码中,我们会发现一般使用EBP结合偏移的方法去表示栈上的一个变量,如:
mov eax, dword ptr [ebp+0ch]
mov ebx, dword ptr [ebp+08h]但是为什么没有使用ESP表示变量呢?这是因为ESP指针在当前调用堆栈中也不是稳定的,比如我们进行函数调用,会将一些信息进行入栈处理,这个时候栈顶指针就会减小以扩大有效栈的区域。为什么是栈顶值减小以扩大栈区域呢?这是因为栈结构的特点:栈底地址比栈顶地址大。
我们再看下大小尾数据在栈空间的布局。
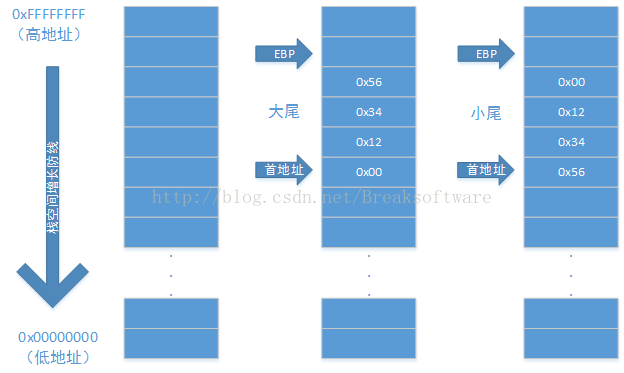
大尾结构将数据的高位放在地址低处,而小尾结构将数据的高位放在地址的高位。于是我们看下0x00123456在不同结构中的布局
如果我们直接在内存中查看,则是这样展现的
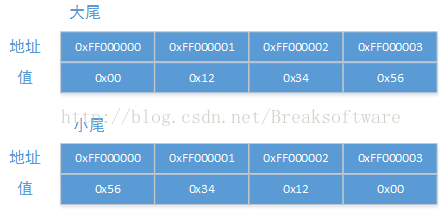
可以发现大尾的结构比较正常,它展现的数据的形式和人类的认知方式是相同的——高位在前,低位在后。但是小尾的展现形式则比较反人类——需要倒着看。但是存在即合理,那么小尾结构那么反人类为什么它还存在呢?
这就要从CPU的历史讲起来。历史上关于选择大尾还是小尾有着很多争论,各派都有自己的理论依据。我在网上找到一篇关于这段历史的文档——《ON HOLY WARS AND A PLEA FOR PEACE》,鉴于文档稍长,我没有仔细阅读,有兴趣的读者可以去了解下。我在这儿简单讲一下我个人的认识:大尾结构便于人类理解,小尾结构便于计算机计算。
大尾结构便于人类理解,这点我们在上面的图中已经发现了。现行的网络传输协议也是采用大尾结构,很明显作为协议,其重点是协议的可被理解性,而非其参与计算的能力。
小尾结构便于计算机计算怎么理解呢?举个例子,比如我们要对上面数据(假设为a)执行加法操作,操作数是0x12efcdab。那么计算机取到a的地址是0xFF000000,然后用操作数中的0xab与0xFF000000地址的数据进行add操作,操作结果还保存在0xFF000000中;如果有进位,则参与到操作数0xcd与0xFF000001地址的数据相加中。CPU只要对操作数和被操作数的地址向后移动取值相加就可以了。我们再想像下大尾数据的处理方法,如果也是从地址低位开始计算——即是数据高位,则可能产生回溯的问题——数据低位计算有进位则要求改之前计算的值——甚至还要改之前的之前计算的值。如果从地址高位开始计算——即数据低位,则有一次通过a地址(地址低位)跳转到地址高位的过程。可能有人会说你为什么不拿减法例子呢?人类的减法操作都是从高位向低位进行的。但是计算机没有减法器——它是通过加法操作进行减法运算的。
大小尾虽然是一个非常古老的问题,但是我们在进行数据跨网络交互时要考虑,因为网络字节序和本机字节序可能不一样。跨语言传输数据时也要考虑,像Java的数据就是大尾结构的。
Redis在源码的endianconv.c提供了一系列小尾结构向大尾结构转换的方法。我们看一下64位数据的处理函数:
/* Toggle the 64 bit unsigned integer pointed by *p from little endian to
* big endian */
void memrev64(void *p) {
unsigned char *x = p, t;
t = x[0];
x[0] = x[7];
x[7] = t;
t = x[1];
x[1] = x[6];
x[6] = t;
t = x[2];
x[2] = x[5];
x[5] = t;
t = x[3];
x[3] = x[4];
x[4] = t;
}
uint64_t intrev64(uint64_t v) {
memrev64(&v);
return v;
}Redis使用大尾也印证了我之前的观点,因为Redis是重要的功能是存储和网络交互,而非进行数值计算。
接下来我们看看Redis的有序整数集的保存结构。
基础结构
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;encoding是表示该结构保存的数据类型。它可以是下列类型值:
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))至于结构中encoding最终设置为何种类型,则要视其存储的最大数据的类型来决定。比如该结构最初始的内容只有0x08,则类型是INTSET_ENC_INT16。而如果加入了0x12345678,则类型将变成INTSET_ENC_INT32。具体的判断方法是看数值的范围:
static uint8_t _intsetValueEncoding(int64_t v) {
if (v < INT32_MIN || v > INT32_MAX)
return INTSET_ENC_INT64;
else if (v < INT16_MIN || v > INT16_MAX)
return INTSET_ENC_INT32;
else
return INTSET_ENC_INT16;
}不要被上面的区间名给欺骗了,它们的定义如下。
#define INT8_MIN ((int8_t)_I8_MIN)
#define INT8_MAX _I8_MAX
#define INT16_MIN ((int16_t)_I16_MIN)
#define INT16_MAX _I16_MAX
#define INT32_MIN ((int32_t)_I32_MIN)
#define INT32_MAX _I32_MAX_IXX_MIN都是负数,其最高位为1,这样使用无符号类型强转之后便是更高区间的最大值。
intset结构中length字段表示contents数组元素的个数;contents则是整型数数组的首地址,但是不要被它类型int8_t欺骗了,它实际存储的类型可能是int32_t或者int64_t。
创建集合
集合创建通过下面方法实现
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
}可见集合结构是在堆上分配的,初始类型是INTSET_ENC_INT16,元素个数是0。此时contents指针还是无效的,这说明该结构可能没有采用预分配空间的设计,而是实时分配。之后的代码也印证了这点。
重分配集合空间
因为inset结构是个可变长度结构,其可变部分就是contents数组的长度,所以重分配集合空间主要是根据集合保存的数据类型和数组元素个数重新分配空间。
static intset *intsetResize(intset *is, uint32_t len) {
uint32_t size = len*intrev32ifbe(is->encoding);
is = zrealloc(is,sizeof(intset)+size);
return is;
}获取集合长度
即返回intset的length字段,它表示其保存的数字个数
/* Return intset length */
uint32_t intsetLen(intset *is) {
return intrev32ifbe(is->length);
}获取集合占用空间大小
集合结构的设计说明其是一个可变长结构,所以计算空间大小要把结构的头大小和可变长度数组长度相加
/* Return intset blob size in bytes. */
size_t intsetBlobLen(intset *is) {
return sizeof(intset)+intrev32ifbe(is->length)*intrev32ifbe(is->encoding);
}通过位置设置值
因为contents保存的数值长度要视intset的encoding类型决定,所以通过位置定位元素时,需要将contents强转为相应类型的指针。这样通过加法操作,可以让指针步进的长度为元素类型的长度
static void _intsetSet(intset *is, int pos, int64_t value) {
uint32_t encoding = intrev32ifbe(is->encoding);
if (encoding == INTSET_ENC_INT64) {
((int64_t*)is->contents)[pos] = value;
memrev64ifbe(((int64_t*)is->contents)+pos);
} else if (encoding == INTSET_ENC_INT32) {
((int32_t*)is->contents)[pos] = value;
memrev32ifbe(((int32_t*)is->contents)+pos);
} else {
((int16_t*)is->contents)[pos] = value;
memrev16ifbe(((int16_t*)is->contents)+pos);
}
}通过位置获取值
获取值时同样要根据intset保存的数据类型决定对contents进行加法操作时步进的长度
/* Return the value at pos, given an encoding. */
static int64_t _intsetGetEncoded(intset *is, int pos, uint8_t enc) {
int64_t v64;
int32_t v32;
int16_t v16;
if (enc == INTSET_ENC_INT64) {
memcpy(&v64,((int64_t*)is->contents)+pos,sizeof(v64));
memrev64ifbe(&v64);
return v64;
} else if (enc == INTSET_ENC_INT32) {
memcpy(&v32,((int32_t*)is->contents)+pos,sizeof(v32));
memrev32ifbe(&v32);
return v32;
} else {
memcpy(&v16,((int16_t*)is->contents)+pos,sizeof(v16));
memrev16ifbe(&v16);
return v16;
}
}
/* Return the value at pos, using the configured encoding. */
static int64_t _intsetGet(intset *is, int pos) {
return _intsetGetEncoded(is,pos,intrev32ifbe(is->encoding));
}查找元素
查找元素时,先看待查找的元素数值是否在该集合可以表达的数值空间之内。如果不在则直接认为找不到元素,这样可以免去查找操作
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
/* The value can never be found when the set is empty */
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
} 由于intset保存的是有序数字,且数字从小到大排列。这样如果元素数值比第一个元素小,或者比最后一个元素大,则说明待查元素也不在数组中。
else {
/* Check for the case where we know we cannot find the value,
* but do know the insert position. */
if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}其他情况则说明待查元素,这个时候就采用二分查找的方式进行
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}检测元素是否在集合中
检测操作非常简单,只是简单的调用intsetSearch方法
/* Determine whether a value belongs to this set */
uint8_t intsetFind(intset *is, int64_t value) {
uint8_t valenc = _intsetValueEncoding(value);
return valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,NULL);
}新增一个更大数值类型元素
如果一开始时,集合中保存的元素只有0x01,那么集合的类型是INTSET_ENC_INT16。contents数组的长度也是INTSET_ENC_INT16的长度。现在要往集合中新增一个元素0x12345678,这个时候INTSET_ENC_INT16类型长度的空间已经不能保存该数据了。于是需要对整个结构进行升级
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
uint8_t curenc = intrev32ifbe(is->encoding);
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);先要获取以前集合类型和长度,还要计算新集合为何种类型
int prepend = value < 0 ? 1 : 0;然后检查新增的值是否为负数。因为该数值的绝对值比之前数组中所有元素都要大,所以如果该数如果是负数,则它比之前任何元素都小,这样它就要插在头部。相反,如果它是正数,则可能是插在尾部。
/* First set new encoding and resize */
is->encoding = intrev32ifbe(newenc);
is = intsetResize(is,intrev32ifbe(is->length)+1);
/* Upgrade back-to-front so we don't overwrite values.
* Note that the "prepend" variable is used to make sure we have an empty
* space at either the beginning or the end of the intset. */
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));使用新的类型更新集合encoding字段,再通过intsetResize重新分配集合的内存。因为当前内存数据分布和之前的一致(除了变长了),所以还要通过之后的while循环将之前的值转移到其现在应该在的位置。
/* Set the value at the beginning or the end. */
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}最后视新增数据的正负情况插入到新结构的不同位置。
数组尾部空间平移
这步操作在要往数组中间插入或者删除元素时发生。如果插入元素,则需要将插入位置的元素及之后的元素一起向后平移。如果删除元素,则要将被删除元素之后的元素向前平移
static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) {
void *src, *dst;
uint32_t bytes = intrev32ifbe(is->length)-from;
uint32_t encoding = intrev32ifbe(is->encoding);
if (encoding == INTSET_ENC_INT64) {
src = (int64_t*)is->contents+from;
dst = (int64_t*)is->contents+to;
bytes *= sizeof(int64_t);
} else if (encoding == INTSET_ENC_INT32) {
src = (int32_t*)is->contents+from;
dst = (int32_t*)is->contents+to;
bytes *= sizeof(int32_t);
} else {
src = (int16_t*)is->contents+from;
dst = (int16_t*)is->contents+to;
bytes *= sizeof(int16_t);
}
memmove(dst,src,bytes);
}增加元素
增加元素时,要先判断待添加的元素是否比现在的集合类型大。如果是,则要重新分配和更新整个集合内存空间
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is,value);
}如果之前集合的类型可以承载待添加的元素,则先去检查元素是否已经在数组中。如果已经存在,则不再进行添加操作,直接认为操作成功
else {
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;
return is;
}如果不在数组中,则上面的intsetSearch方法将计算出待添加的数据需要被插入到数组中的的位置。这个时候就需要重新分配集合长度,并将要插入的位置及之后的数据向后平移,并把待添加数据设置到数组的相应位置。
is = intsetResize(is,intrev32ifbe(is->length)+1);
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}删除元素
删除元素比较简单,只要通过intsetSearch找到元素的位置,将该位置之后的元素向前平移就行了
/* Delete integer from intset */
intset *intsetRemove(intset *is, int64_t value, int *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 0;
if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,&pos)) {
uint32_t len = intrev32ifbe(is->length);
/* We know we can delete */
if (success) *success = 1;
/* Overwrite value with tail and update length */
if (pos < (len-1)) intsetMoveTail(is,pos+1,pos);
is = intsetResize(is,len-1);
is->length = intrev32ifbe(len-1);
}
return is;
}通过上面的函数,我们发现Redis的整数集在增删改元素时要自动调整元素排序。在新增绝对值超过当前集合可以表达的数据时,升级当前集合。但是如果删除元素时,即使现存的数字都比当前集合表达的区间的最小值还要小,也不会发生降级的操作。
智能推荐
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
数据结构与算法(Python版)三:变位词判断问题_所谓“变位词”是指两个词之间存在组成字母的重新排列关系。如:heart和earth,pyth-程序员宅基地
文章浏览阅读370次。算法分析的概念程序和算法的区别算法是对问题解决的分步描述。程序是采用某种编程语言实现的算法算法分析主要就是从计算资源消耗的角度来评判和比较算法更高效利用计算资源,或者更少占用计算资源的算法就是好算法。计算资源指标一种是算法解决问题过程中需要的存储空间或内存存储空间收到问题自身数据规模的变化影响要区分哪些存储空间是问题本身描述所需,哪些是算法占用不容易另一种是算法的执行时间可以对程序进行实际运行测试,获得真实的运行时间运行时间检测Python中有一个time模块,可以获取计算机系统当前_所谓“变位词”是指两个词之间存在组成字母的重新排列关系。如:heart和earth,pyth
随便推点
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象
二叉树的各种创建方法_二叉树的建立-程序员宅基地
文章浏览阅读6.9w次,点赞73次,收藏463次。1.前序创建#include<stdio.h>#include<string.h>#include<stdlib.h>#include<malloc.h>#include<iostream>#include<stack>#include<queue>using namespace std;typed_二叉树的建立