计算机视觉迎来GPT时刻!UC伯克利三巨头祭出首个纯CV大模型!-程序员宅基地
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文,强烈推荐!

在CVer微信公众号后台回复:LVM,即可下载论文pdf和代码链接!快学起来!
转载自:机器之心
仅靠视觉(像素)模型能走多远?UC 伯克利、约翰霍普金斯大学的新论文探讨了这一问题,并展示了大型视觉模型(LVM)在多种 CV 任务上的应用潜力。
最近一段时间以来,GPT 和 LLaMA 等大型语言模型 (LLM) 已经风靡全球。
另一个关注度同样很高的问题是,如果想要构建大型视觉模型 (LVM) ,我们需要的是什么?
LLaVA 等视觉语言模型所提供的思路很有趣,也值得探索,但根据动物界的规律,我们已经知道视觉能力和语言能力二者并不相关。比如许多实验都表明,非人类灵长类动物的视觉世界与人类的视觉世界非常相似,尽管它们和人类的语言体系「两模两样」。
在最近一篇论文中,UC 伯克利和约翰霍普金斯大学的研究者探讨了另一个问题的答案 —— 我们仅靠像素本身能走多远?

论文地址:https://arxiv.org/abs/2312.00785
项目主页:https://yutongbai.com/lvm.html
研究者试图在 LVM 中效仿的 LLM 的关键特征:1)根据数据的规模增长进行扩展,2)通过提示(上下文学习)灵活地指定任务。
他们指定了三个主要组件,即数据、架构和损失函数。
在数据上,研究者想要利用视觉数据中显著的多样性。首先只是未标注的原始图像和视频,然后利用过去几十年产生的各种标注视觉数据源(包括语义分割、深度重建、关键点、多视图 3D 对象等)。他们定义了一种通用格式 —— 「视觉句子」(visual sentence),用它来表征这些不同的注释,而不需要任何像素以外的元知识。训练集的总大小为 16.4 亿图像 / 帧。
在架构上,研究者使用大型 transformer 架构(30 亿参数),在表示为 token 序列的视觉数据上进行训练,并使用学得的 tokenizer 将每个图像映射到 256 个矢量量化的 token 串。
在损失函数上,研究者从自然语言社区汲取灵感,即掩码 token 建模已经「让位给了」序列自回归预测方法。一旦图像、视频、标注图像都可以表示为序列,则训练的模型可以在预测下一个 token 时最小化交叉熵损失。
通过这一极其简单的设计,研究者展示了如下一些值得注意的行为:
随着模型尺寸和数据大小的增加,模型会出现适当的扩展行为;
现在很多不同的视觉任务可以通过在测试时设计合适的 prompt 来解决。虽然不像定制化、专门训练的模型那样获得高性能的结果, 但单一视觉模型能够解决如此多的任务这一事实非常令人鼓舞;
大量无监督数据对不同标准视觉任务的性能有着显著的助益;
在处理分布外数据和执行新的任务时,出现了通用视觉推理能力存在的迹象,但仍需进一步研究。
论文共同一作、约翰霍普金斯大学 CS 四年级博士生、伯克利访问博士生 Yutong Bai 发推宣传了她们的工作。
图源:https://twitter.com/YutongBAI1002/status/1731512110247473608
在论文作者中,后三位都是 UC 伯克利在 CV 领域的资深学者。Trevor Darrell 教授是伯克利人工智能研究实验室 BAIR 创始联合主任、Jitendra Malik 教授获得过 2019 年 IEEE 计算机先驱奖、 Alexei A. Efros 教授尤以最近邻研究而闻名。

从左到右依次为 Trevor Darrell、Jitendra Malik、Alexei A. Efros。
方法介绍
本文采用两阶段方法:1)训练一个大型视觉 tokenizer(对单个图像进行操作),可以将每个图像转换为一系列视觉 token;2)在视觉句子上训练自回归 transformer 模型,每个句子都表示为一系列 token。方法如图 2 所示:
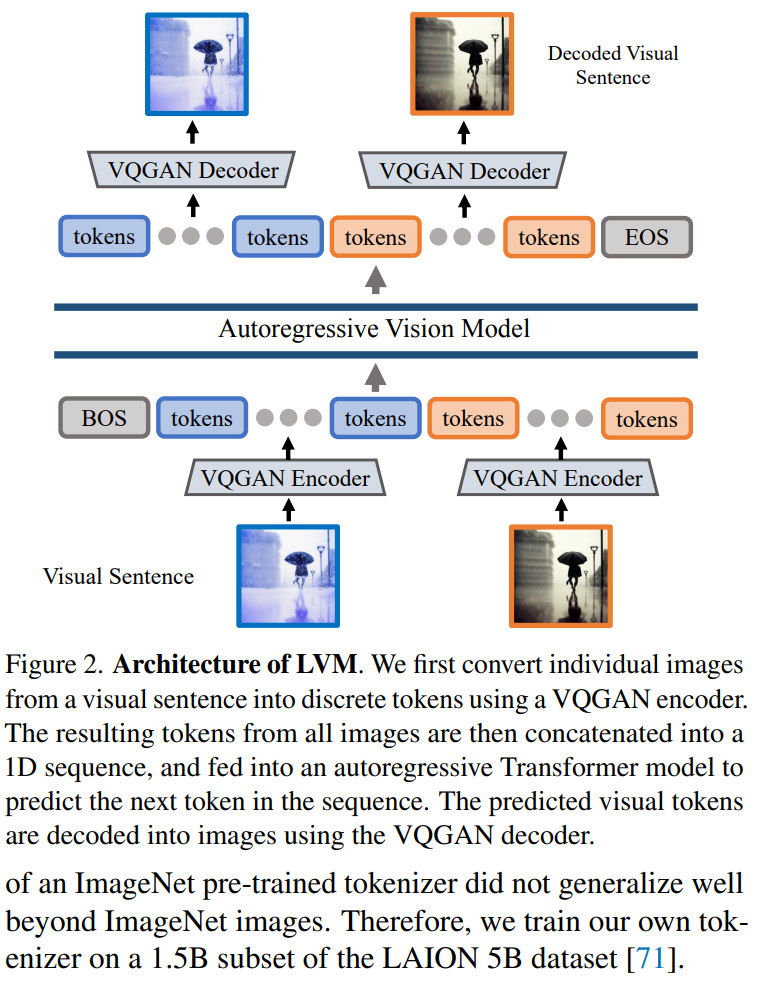
图像 Token 化
为了将 Transformer 模型应用于图像,典型的操作包括:将图像划分为 patch,并将其视为序列;或者使用预训练的图像 tokenizer,例如 VQVAE 或 VQGAN,将图像特征聚集到离散 token 网格中。本文采用后一种方法,即用 VQGAN 模型生成语义 token。
LVM 框架包括编码和解码机制,还具有量化层,其中编码器和解码器是用卷积层构建的。编码器配备了多个下采样模块来收缩输入的空间维度,而解码器配备了一系列等效的上采样模块以将图像恢复到其初始大小。对于给定的图像,VQGAN tokenizer 会生成 256 个离散 token。
实现细节。本文采用 Chang 等人提出的 VQGAN 架构,并遵循 Chang 等人使用的设置,在此设置下,下采样因子 f=16,码本大小 8192。这意味着对于大小为 256 × 256 的图像,VQGAN tokenizer 会生成 16 × 16 = 256 个 token,其中每个 token 可以采用 8192 个不同的值。此外,本文在 LAION 5B 数据集的 1.5B 子集上训练 tokenizer。
视觉句子序列建模
使用 VQGAN 将图像转换为离散 token 后,本文通过将多个图像中的离散 token 连接成一维序列,并将视觉句子视为统一序列。重要的是,所有视觉句子都没有进行特殊处理 —— 即不使用任何特殊的 token 来指示特定的任务或格式。
视觉句子允许将不同的视觉数据格式化成统一的图像序列结构。
实现细节。在将视觉句子中的每个图像 token 化为 256 个 token 后,本文将它们连接起来形成一个 1D token 序列。在视觉 token 序列上,本文的 Transformer 模型实际上与自回归语言模型相同,因此他们采用 LLaMA 的 Transformer 架构。
本文使用的上下文长度为 4096 个 token,与语言模型类似,本文在每个视觉句子的开头添加一个 [BOS](begin of sentence)token,在末尾添加一个 [EOS](end of sentence)token,并在训练期间使用序列拼接提高效率。
本文在整个 UVDv1 数据集(4200 亿个 token)上训练模型,总共训练了 4 个具有不同参数数量的模型:3 亿、6 亿、10 亿和 30 亿。
实验结果
该研究进行实验评估了模型的扩展能力,以及理解和回答各种任务的能力。
扩展
如下图 3 所示,该研究首先检查了不同大小的 LVM 的训练损失。
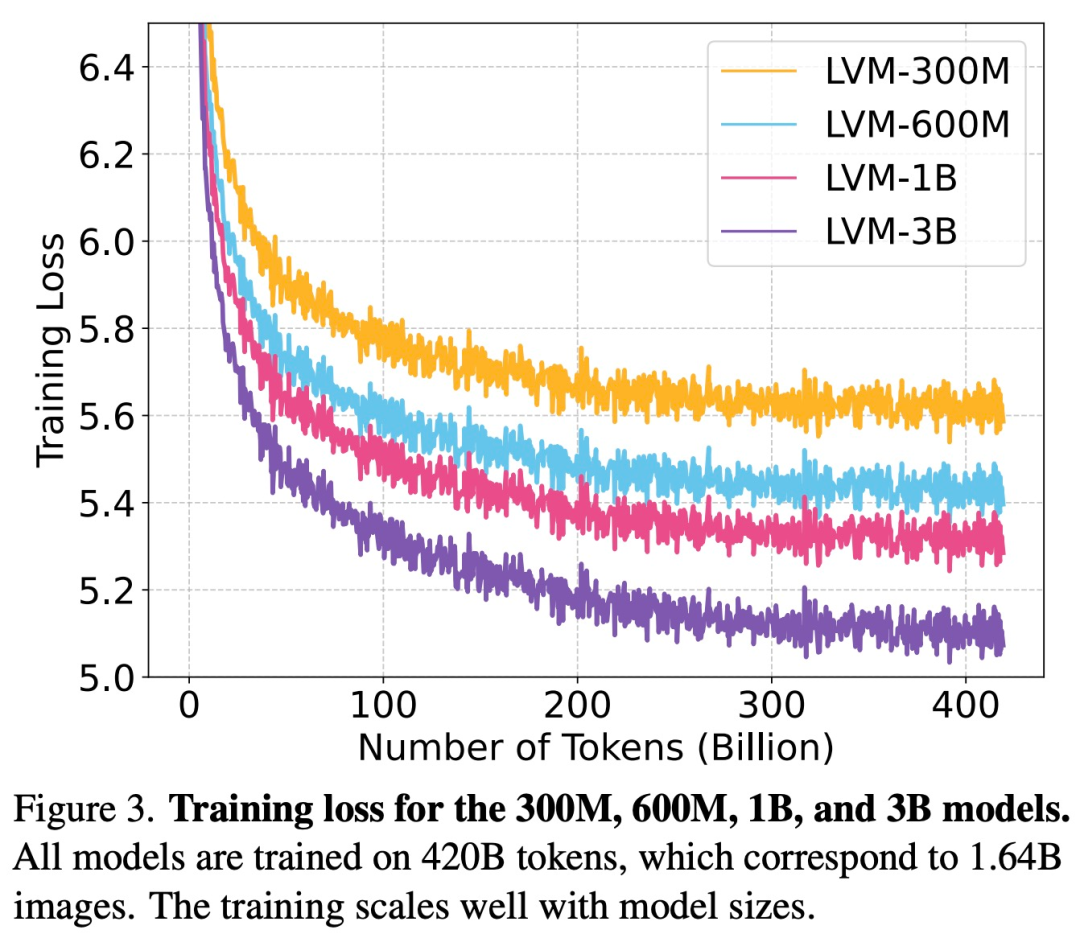
如下图 4 所示,较大的模型在所有任务中复杂度都是较低的,这表明模型的整体性能可以迁移到一系列下游任务上。
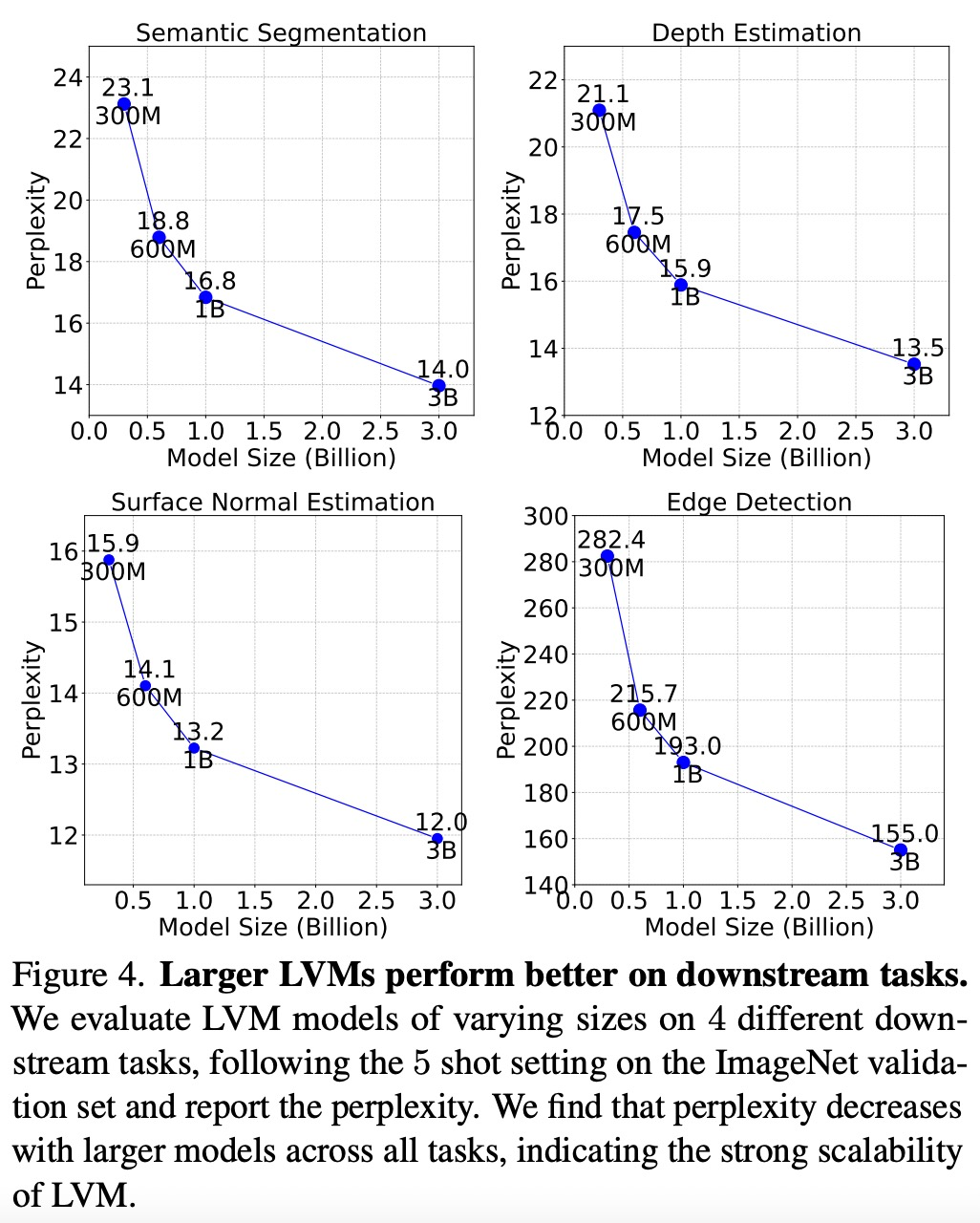
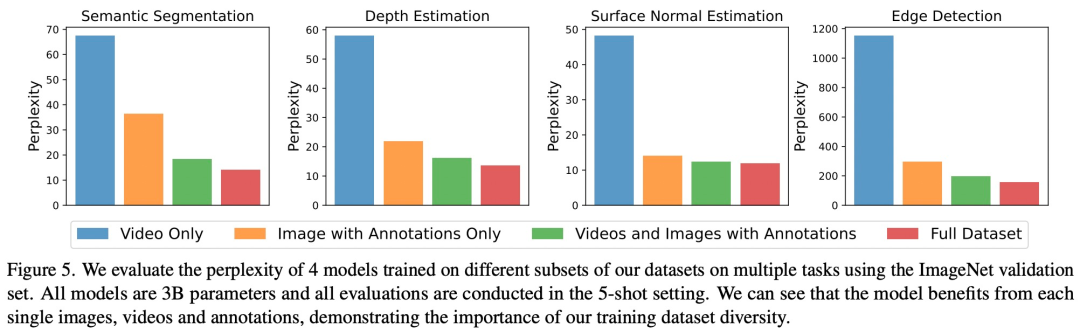
如下图 5 所示,每个数据组件对下游任务都有重要作用。LVM 不仅会受益于更大的数据,而且还随着数据集的多样性而改进。
序列 prompt
为了测试 LVM 对各种 prompt 的理解能力,该研究首先在序列推理任务上对 LVM 进行评估实验。其中,prompt 非常简单:向模型提供 7 张图像的序列,要求它预测下一张图像,实验结果如下图 6 所示:

该研究还将给定类别的项目列表视为一个序列,让 LVM 预测同一类的图像,实验结果如下图 15 所示:

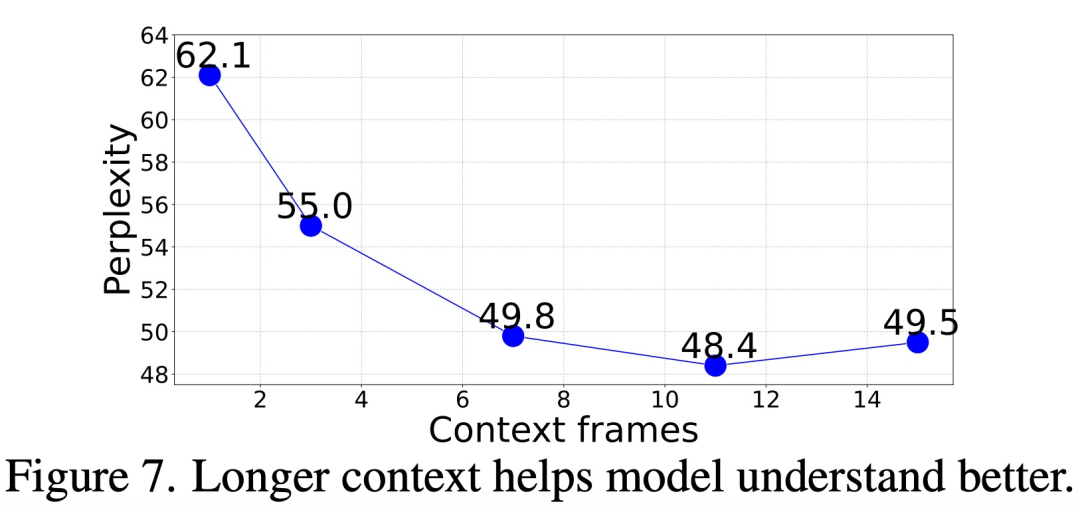
那么,需要多少上下文(context)才能准确预测后续帧?
该研究在给出不同长度(1 到 15 帧)的上下文 prompt 情况下,评估了模型的帧生成困惑度,结果如下图 7 所示,困惑度从 1 帧到 11 帧有明显改善,之后趋于稳定(62.1 → 48.4)。
Analogy Prompt
该研究还评估了更复杂的 prompt 结构 ——Analogy Prompt,来测试 LVM 的高级解释能力。
下图 8 显示了对许多任务进行 Analogy Prompt 的定性结果:

与视觉 Prompting 的比较如下所示, 序列 LVM 在几乎所有任务上都优于以前的方法。

合成任务。图 9 展示了使用单个 prompt 组合多个任务的结果。

其他 prompt
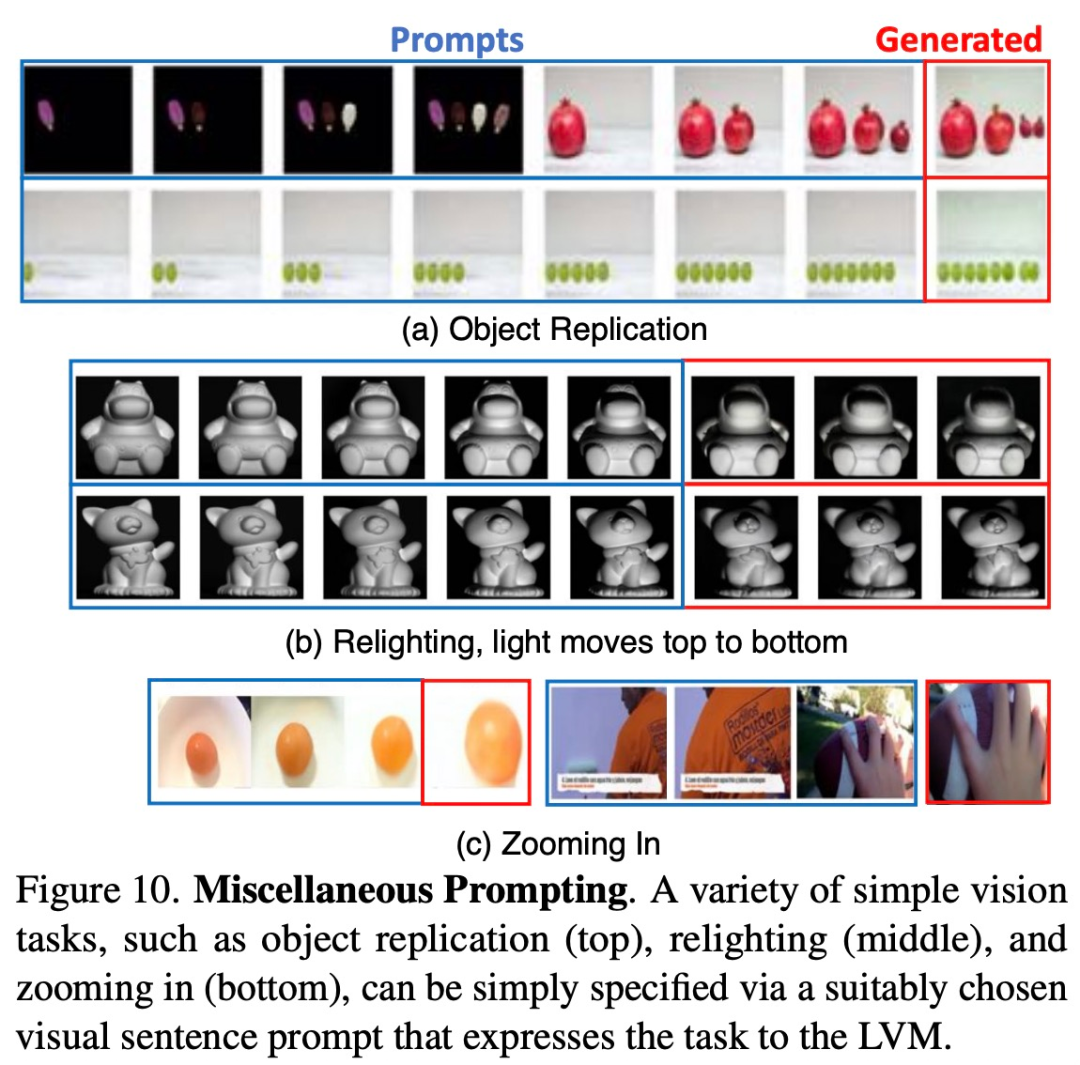
研究者试图通过向模型提供它以往未见过的各种 prompt,来观察模型的扩展能力到底怎样。下图 10 展示了一些运行良好的此类 prompt。
下图 11 展示了一些用文字难以描述的 prompt,这些任务上 LVM 最终可能会胜过 LLM。
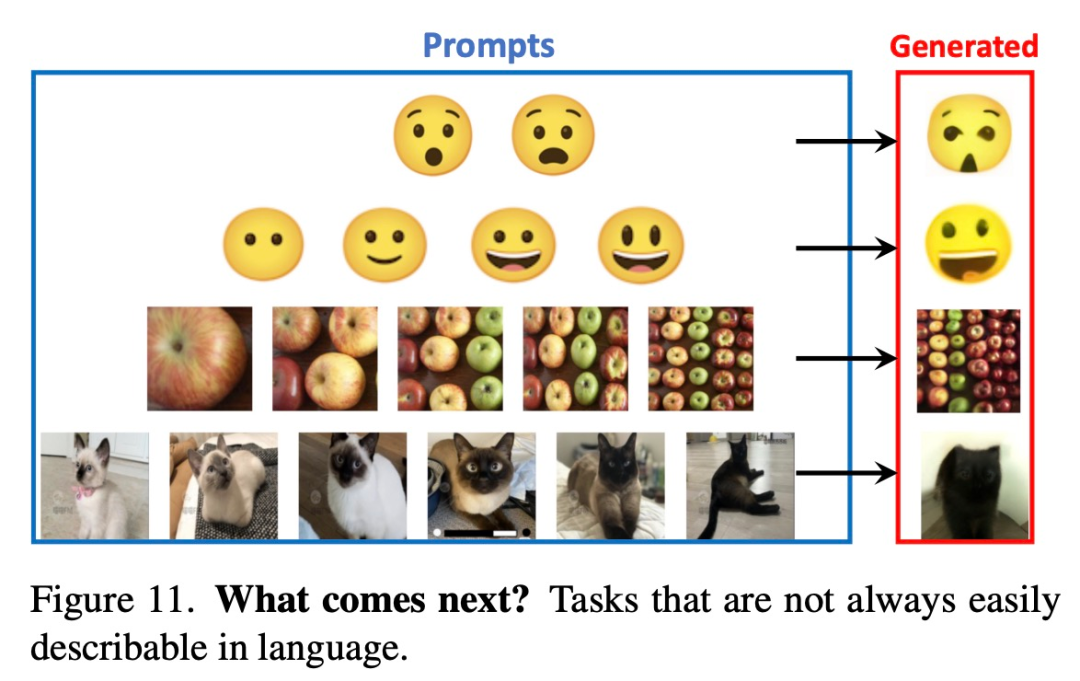
图 13 显示了在非语言人类 IQ 测试中发现的典型视觉推理问题的初步定性结果。

阅读原文,了解更多细节。
在CVer微信公众号后台回复:LVM,即可下载论文pdf和代码链接!快学起来!
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集计算机视觉和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号智能推荐
termux获取sd卡读写权限_stm32 SPI读写储存卡(MicroSD TF卡)-程序员宅基地
文章浏览阅读2.4k次。简述花了较长的时间,来弄读写储存卡(大部分教程讲的比较全但是不是很容易懂),这里希望我的代码经验能够帮助到你。操作分析及实现0.整个流程1、上电以后储存卡的初始化2、如何进行读写实现1.上电以后储存卡的初始化上电给MicroSD卡至少74个时钟信号发送CDM0 (x041)复位发送CMD1 让MicroSD卡进入SPI模式2.如何进行读写这里主要对1,3进行详细的讨论你需要知道的是spi通信是怎样..._termux sd卡权限
VS code 配置java环境并运行_visio studio code java project怎么运行-程序员宅基地
文章浏览阅读6.4k次,点赞5次,收藏27次。环境准备jdk1.8 jdk1.8.0_121maven apache-maven-3.6.01、安装java运行环境插件Language Support for Java by Red HatDebugger for JavaJavaTest RunnerMaven for JavaProject Manager for JavaJava Extension Pack插件用途java运行环境调试(debug)java所需单元测试java所需maven 环境,如果你是_visio studio code java project怎么运行
分布式光纤传感器的全球与中国市场2022-2028年:技术、参与者、趋势、市场规模及占有率研究报告_预计2026年中国分布式传感器市场规模有多大-程序员宅基地
文章浏览阅读3.2k次。本文研究全球与中国市场分布式光纤传感器的发展现状及未来发展趋势,分别从生产和消费的角度分析分布式光纤传感器的主要生产地区、主要消费地区以及主要的生产商。重点分析全球与中国市场的主要厂商产品特点、产品规格、不同规格产品的价格、产量、产值及全球和中国市场主要生产商的市场份额。主要生产商包括:FISO TechnologiesBrugg KabelSensor HighwayOmnisensAFL GlobalQinetiQ GroupLockheed MartinOSENSA Innovati_预计2026年中国分布式传感器市场规模有多大
07_08 常用组合逻辑电路结构——为IC设计的延时估计铺垫_基4布斯算法代码-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏12次。常用组合逻辑电路结构——为IC设计的延时估计铺垫学习目的:估计模块间的delay,确保写的代码的timing 综合能给到多少HZ,以满足需求!_基4布斯算法代码
OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏5次。OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版
关于美国计算机奥赛USACO,你想知道的都在这_usaco可以多次提交吗-程序员宅基地
文章浏览阅读2.2k次。USACO自1992年举办,到目前为止已经举办了27届,目的是为了帮助美国信息学国家队选拔IOI的队员,目前逐渐发展为全球热门的线上赛事,成为美国大学申请条件下,含金量相当高的官方竞赛。USACO的比赛成绩可以助力计算机专业留学,越来越多的学生进入了康奈尔,麻省理工,普林斯顿,哈佛和耶鲁等大学,这些同学的共同点是他们都参加了美国计算机科学竞赛(USACO),并且取得过非常好的成绩。适合参赛人群USACO适合国内在读学生有意向申请美国大学的或者想锻炼自己编程能力的同学,高三学生也可以参加12月的第_usaco可以多次提交吗
随便推点
macOS使用brew包管理器_brew清理缓存-程序员宅基地
文章浏览阅读2.1k次。macOS使用brew包管理器安装brewbrew权限修复brew常用命令Brew-cask相关命令brew serivces 相关命令brew 指南https://www.cnblogs.com/gee1k/p/10655037.html安装brew#- 该教程适用于macOS10.13以上版本#- 先安装XCode或者Command Line Tools for Xcode。Xcode可以从AppStore里下载安装,Command Line Tools for Xcode需要在终端中输入以下_brew清理缓存
【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
文章浏览阅读789次,点赞6次,收藏2次。【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值
常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地
文章浏览阅读102次。本篇介绍了常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理
【Unity3d Shader】水面和岩浆效果_unity 岩浆shader-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏18次。游戏水面特效实现方式太多。咱们这边介绍的是一最简单的UV动画(无顶点位移),整个mesh由4个顶点构成。实现了水面效果(左图),不动代码稍微修改下参数和贴图可以实现岩浆效果(右图)。有要思路是1,uv按时间去做正弦波移动2,在1的基础上加个凹凸图混合uv3,在1、2的基础上加个水流方向4,加上对雾效的支持,如没必要请自行删除雾效代码(把包含fog的几行代码删除)S..._unity 岩浆shader
广义线性模型——Logistic回归模型(1)_广义线性回归模型-程序员宅基地
文章浏览阅读5k次。广义线性模型是线性模型的扩展,它通过连接函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。广义线性模型拟合的形式为:其中g(μY)是条件均值的函数(称为连接函数)。另外,你可放松Y为正态分布的假设,改为Y 服从指数分布族中的一种分布即可。设定好连接函数和概率分布后,便可以通过最大似然估计的多次迭代推导出各参数值。在大部分情况下,线性模型就可以通过一系列连续型或类别型预测变量来预测正态分布的响应变量的工作。但是,有时候我们要进行非正态因变量的分析,例如:(1)类别型.._广义线性回归模型
HTML+CSS大作业 环境网页设计与实现(垃圾分类) web前端开发技术 web课程设计 网页规划与设计_垃圾分类网页设计目标怎么写-程序员宅基地
文章浏览阅读69次。环境保护、 保护地球、 校园环保、垃圾分类、绿色家园、等网站的设计与制作。 总结了一些学生网页制作的经验:一般的网页需要融入以下知识点:div+css布局、浮动、定位、高级css、表格、表单及验证、js轮播图、音频 视频 Flash的应用、ul li、下拉导航栏、鼠标划过效果等知识点,网页的风格主题也很全面:如爱好、风景、校园、美食、动漫、游戏、咖啡、音乐、家乡、电影、名人、商城以及个人主页等主题,学生、新手可参考下方页面的布局和设计和HTML源码(有用点赞△) 一套A+的网_垃圾分类网页设计目标怎么写