数据挖掘——序列模式挖掘-程序员宅基地
技术标签: 数据挖掘
数据挖掘之序列模式挖掘
时间序列:将某一指标在不同时间上的不同数值,按照时间先后顺序排列而成的数列。
时间序列的建模方法:
- 一元时间序列:通过单变量随机过程的观察获得规律性信息。
- 多元时间序列:通过多个变量描述变化规律。
- 离散型时间序列:序列中的每一个序列值所对应的时间参数为间断点。
- 连续型时间序列:序列中的每个序列值所对应的时间参数为连续函数。
序列模式挖掘:
从序列数据集中寻找频繁子序列作为模式的知识发现过程。
• 序列模式挖掘最早是由Agrawal等人提出的,最初动机是针对带有交易时间属性的交易数据库中发现频繁项目序列以发现某一时间段内客户的购买活动规律。
序列模式挖掘和关联规则挖掘的区别:
• 序列模式是找出序列数据集中数据之间的先后顺序。
• 关联规则是找出事务数据集中数据之间的并发关系。
• 关联规则挖掘不关注事务之间的先后顺序,序列模式挖掘需要考虑序列间的先后顺序。
基本概念
- 定义1:设 I = { i1,i2,…,im} 为项集,称S=<( s1,h1 ), ( s2,h2 ),…,( sn,hn )>为一个时间事务序列,si 属于I, hi 为 si 发生的时间且hi < hi+1( i=1,2,…,n-1 )。
不关心前后两个事务发生的时间跨度的话,则时
间事务序列可简记为S=<s1, s2,…,sn)>,并称为一个序列(Sequence)。其中项集 si 称为序列 S 的元素。 - 定义2:若序列 S 中包含 k 个项,则称 S 为 k -序列或长度为 k 的序列。
- 定义3:设序列 α = α1→α2→⋯→αn,序列
β = β1→β2→⋯→βm 。若存在整数i1<i2<⋯<in,使得α1<βi1, α2<βi2,…, αn<βin
则称序列α是序列β的子序列,或序列β包含序列α。【序列α的每一个元素都是序列β中的元素的真子集,且元素存在次序关系,则序列α是序列β的子序列】
在一组序列中,如果某序列α不包含其他任何序列中,则称α是该组中最长序列(Maximal sequence)。 - 定义4:给定序列S,序列数据集DT,序列S的支持度(Support)是指S在DT中相对于整个数据集元组而言所包含S的元组出现的百分比。
• 支持度大于最小支持度(min-sup)的k-序列,称为DT上的频繁k-序列。 - 序列模式挖掘:给定序列数据集D和用户指定的最小支持度minsup,找出支持度大于或等于minsup的所有序列。
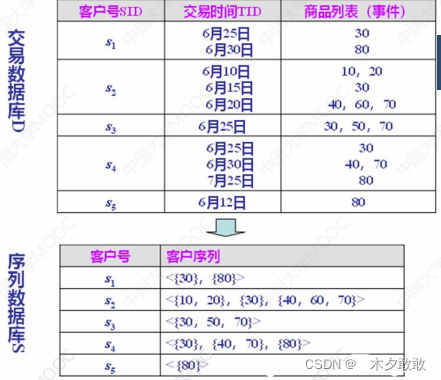
数据源形式:带交易时间的交易数据库的典型形式是由存放客户号(Customer-id)、交易时间(Transaction-Time)以及在交易中购买的项(Item)等的交易记录表组成。
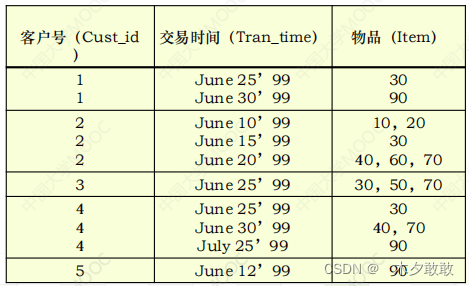
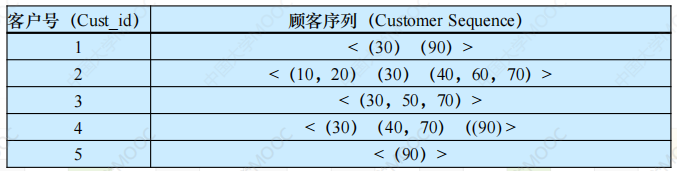
→ 形式化整理:理想的预处理方法就是转换成顾客序列,即将一个顾客的交易按交易时间排序成项目序列。
一般步骤
基于水平格式的Apriori类算法将序列模式挖掘过程分五个具体阶段, 分别是排序阶段、大项集阶段、转换阶段、序列阶段以及选最大阶段。
- 排序阶段
按照客户号和交易时间对数据库进行排序(Sort),把同一用户的事件合并,将原始的数据库转换成序列数据库。
- 大项集阶段
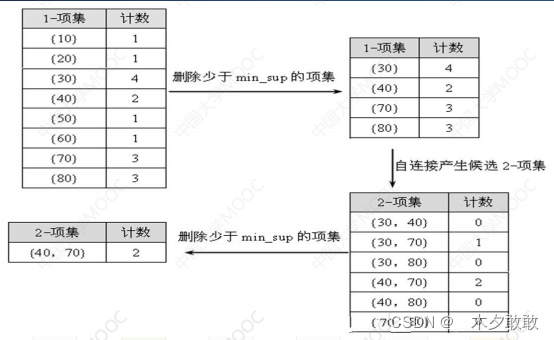
根据min_sup找出所有的频繁项集,也同步得到所有频繁1-序列组成的集合L1。实际操作中,为了处理的方便和高效,经常将大项集映射成连续的整数。
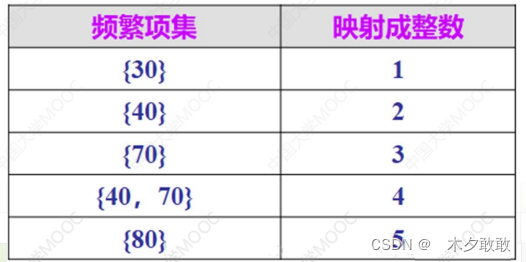
- 转换阶段
• 每个事件被包含于该事件中所有频繁项集替换。
• 如果一个事件不包含任何频繁项集,则将其删除。
• 如果一个客户序列不包含任何频繁项集,则将该序列删除。
转换后,一个客户序列由一个频繁项集组成的集合所取代。每个频繁项集的集合表示为{e1,e2,…,ek},其中ei(1≤i≤k)表示一个频繁项集。
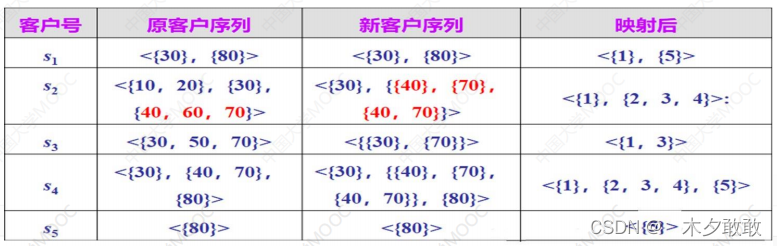
- 序列阶段
(使用不同的序列模式算法)
• 利用转换后的数据库寻找频繁的序列,即大序列(Large Sequence)。 - 选最大阶段
在大序列集中找出最长序列(Maximal Sequences)。
经典算法
1)基于Apriori特性的算法:Apriori算法、AprioriSome算法、AprioriAll算法、DynamicSome算法等等
2)基于垂直格子的算法:SPADE算法
3)增量式序列模式挖掘:研究当序列增加时,如何维护序列模式,提高数据挖掘效率的问题,典型算法有:ISM、ISE、IUS。
4)多维序列模式挖掘:Uni-Seq、Seq-Dim,Dim-Seq。
5)基于约束的序列模式挖掘:通过添加约束条件,挖掘用户最感兴趣、最优价值的序列模式。
各种序列模式挖掘算法的适用范围:
数据集可分为稠密数据集和稀疏数据集。
• Apriori类算法在稀疏数据集的应用中比较合适,不适合稠密数据集的应用。
• 对于有约束条件(例如相邻事务的时间间隔约束)序列模式挖掘,GSP更适用。
• PrefixSpan在两种数据集中都适用,而且在稠密数据集中它的优势更加明显PrefixSpan的性能
更好一些。
1. AprioriAll算法
• AprioriAll本质上是Apriori思想的扩张,它把Apriori的基本思想扩展到序列挖掘中,也是一个多遍扫描数据集的算法,只是在产生候选序列和频繁序列方面考虑序列元素有序的特点,将项集的处理改为序列的处理。
• 在每一遍扫描中都利用前一遍的大序列/频繁序列来产生候选序列,然后在完成遍历整个数据集后测试它们的支持度。
• 在第一次遍历前,所有在大项集阶段得到的大1-序列组成了种子集。
算法步骤:
- 排序阶段:根据交易时间和ID进行排序
- “大项集”阶段:执行一次Apriori算法,找到所有support不小于min_sup的频繁序列/大1-序列
- 转化阶段:根据上一步产生的大1-序列,扫描交易数据,根据MAP映射得到新的序列项集
替换原则:
· 如果该事务中不包含任何的大1-序列,则删除事务;
· 如果一个客户序列中不包含任何大1-序列,则删除序列。 - 序列阶段:根据上一步得到的新序列项集,再次执行Apriori算法,找到新的频繁序列/大序列
自连接的原则类似于apriori:前k-2项相同的序列才能连接,生成对应的候选k序列。首先连接生成第k-1项小于第k项的候选k序列,再将最后两项的顺序调换生成另外
一个候选k序列。 - 最大化序列阶段:找出长度最长的序列模式

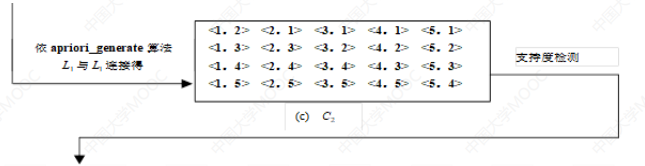
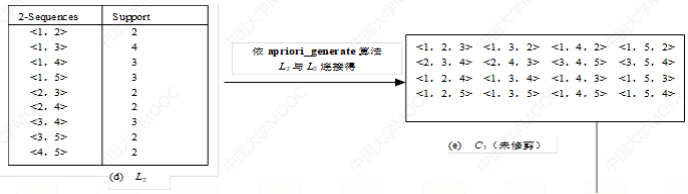
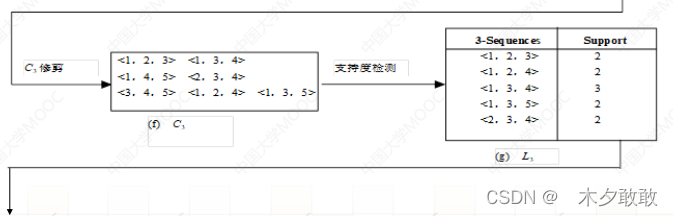

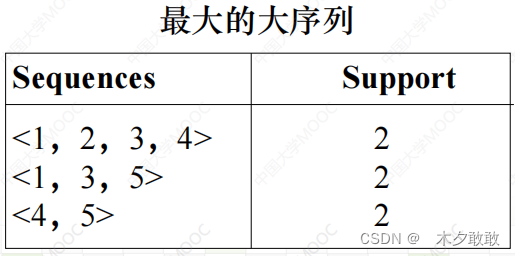
个人理解:
项集是I,对应商品,不重复计(考虑购买的顺序)
该算法存在的问题:
– 容易生成大量的候选项集
– 需要对数据库进行多次扫描
– 很难找到长序列模式
– 在转换阶段产生巨大的开销
2. AprioriSome算法
AprioriSome算法可以看作是AprioriAll算法的改进,具体过程分为两个阶段:
• 前推阶段:找出指定长度的所有大序列。
• 回溯阶段:查找其他长度的所有大序列。
AprioriSome算法性能:
• AprioriSome跳跃式计算候选,会在某种程度上减少遍历数据集次数
• AprioriSome会产生比较多的候选,可能在回溯阶段前就占满内存。
• 对于较低的支持度,数据集中有较长的大序列的情况下,采用AprioriSome比较好。
3. GSP算法
GSP(generalized sequential pattern)算法是AprioriAll算法的扩展算法,其执行过程和
AprioriAll类似:首先产生较短的候选项集,然后将短候选项集进行剪枝,接着通过连接生成长候选序列模式,最后计算其支持度。
• GSP 算法对AprioriAll算法进行的改进:
一:对冗余候选模式进行剪枝。
二:采用哈希树来存储候选模式。
GSP算法存在的问题:
– 当序列数据集比较大时,容易生成庞大的候选序列
– 需要对序列数据集进行多次扫描
– 对长序列模式的处理效率比较低
优点
• GSP引入了时间约束、滑动时间窗和分类层次技术,增加了扫描约束条件,有效地减少了需要扫描的候选序列的数量,同时还克服了基本序列模型的局限性,更切合实际,减少多余的无用模式的产生。
• GSP利用哈希树来存储候选序列,减小了需要扫描的序列数量,同时对数据序列的表示方法进行转换,这样就可以有效地发现一个侯选项是否是数据序列的子序列。
4. PrefixSpan算法
性能分析:
1.不产生候选序列的模式增长
PrefixSpan算法是一个基于模式增长的算法,不产生任何没用序列,而基于最优化的算法会花费大量呈指数增长的时间去处理一个很小的数据库。
2.采用基于投影的分治法作为减小数据的有效方法
3.PrefixSpan算法消耗相对稳定的内存
问题:
- 该算法需要构造大量的投影数据库,并且构造投影数据库的开销较大;
- 该算法需要递归的扫描投影数据库,耗费大量的时空代价,同时也大大降低了算法的挖掘效率;
- 该算法挖掘出的频繁序列模式,都是按照字典序进行排列,不能满足实际的需求。
智能推荐
ehcache 使用说明_withevictionadvisor-程序员宅基地
文章浏览阅读463次。ehcache 使用说明_withevictionadvisor
在Windows环境配置多版本Java(Java8+Java16为例)_windows下可以按照 java 8+吗-程序员宅基地
文章浏览阅读2.1w次,点赞38次,收藏76次。在Windows环境配置多版本Java相信很多小伙伴在开发springboot后端或者玩minecraft的时候都会遇到上古Java的版本要求(比如Java8),但是如今最新的Java版本已经到Java16了,如何在电脑安装多个版本的Java并做到切换呢?下面来一起看看吧0、准备的准备多版本的Java需求一般是Java1.8+Java11之后版本的组合,本文就将以Java8和Java16两种版本的安装与配置为例。如果你的电脑之前没有安装过任何版本的Java,请直接跳到第2步如果你的电脑之前已经安_windows下可以按照 java 8+吗
北航GPA计算器-程序员宅基地
文章浏览阅读9.3k次。北航GPA计算器北京航空航天大学的GPA计算方法为: 制度 计算公式 百分制 $4-3\times\frac{(100-X)^2}{1600}$ 五级制 优秀:4 良好:3.5 中等:2.8 及格:1.7 不及格:0 两级制 不计入GPA,但计入总学分 ..._北航gpa计算器
苹果付费软件18个,最高499元的软件。_ios付费软件推荐-程序员宅基地
文章浏览阅读1.7w次,点赞8次,收藏15次。(苹果锤子三件套)需要的人多的话,我给大家发一个Thor抓{ T子会员}的教程!Thor三件套(抓包工具)●Thor俗称锤子是一款os平台的抓包调试Htp或Htts协议的工具,在众多抓包调试Htp或Htps协议的工具中功能方面相比较完善和稳定,用户可以通过Thor对绝大多数app进行一些项目的调试,或者抓取一些需要的图片、音频、压缩包、下载链接等,从而制作出来的便是Thor过器。●Anubis是一款网络开发调试和HTTP学习的工具,用来调试API或者学习理解HTTP协议,配合hor使用,可以进行日期._ios付费软件推荐
Python零基础教程7——AI辅助编程之我解-程序员宅基地
文章浏览阅读1.3k次,点赞49次,收藏28次。作为Python编程高手,你精通Python语言的各种特性和功能,对编程有着深入的理解和丰富的经验。你熟悉Python的常见应用领域,如数据分析、机器学习、Web开发等,并能根据需求选择合适的库和框架进行开发。作为一名Python编程高手,你的职责是通过编写高效、可靠的Python代码来解决实际问题,帮助他人理解和应用Python编程技术。无论是初学者还是有经验的开发者,你都能够提供专业的指导和建议,分享最佳实践,帮助他们在Python编程的道路上不断进步。那么他就可以准确度很高的还原已有的正确的编程。
python高级进阶_3_ @property 装饰器的意义01_@property 意义-程序员宅基地
文章浏览阅读400次。这个章节大部分人都明白@property 的作用。难道不是把方法转化成属性,可以直接赋值?那我们说说为什么这么做有什么意义呢?先用代码一点点引导。1.避免直接赋值,绕过校验class Student: def __init__(self,name,age): self.name=name self.age=agestu=Student("La..._@property 意义
随便推点
RabbitMQ详解(六)------RabbitMQ可靠性投递_rabbitmq consumer tag-程序员宅基地
文章浏览阅读883次。一.RabbitMQ的可靠性投递1.MQ实现异步通信过程中,消息丢失或重复,可能导致业务数据不一致如何解决? ps:在解决问题之前,必须清楚可靠性只是问题的一方面,发送消息的效率同样是需要考虑的问题,而这两个因素无法兼得。如果在发送消息的每一个环节都采取相关措施来保证可靠性,势必会对消息的收发效率造成影响。会产生消息丢失的四个地方:1.从生产者到Broker,Broker未接收 可能原因:网络连接或者Broker的问题(硬盘故障、硬盘写满了)导致消息发送失败,但生产者..._rabbitmq consumer tag
同程旅游 html_html酒店预约界面及代码-程序员宅基地
文章浏览阅读962次,点赞2次,收藏11次。<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <title> </title> <style type="text/css"> *{ margin: 0; padding: 0; } body{ margin: 0; } .div1{ border-style: none; disp..._html酒店预约界面及代码
git pull时出现unable to access ‘ ‘:Could not resolve host: github.com_git pull unable to access-程序员宅基地
文章浏览阅读1.3k次。unable to access ' ':Could not resolve host: github.com解决方案转载自:https://blog.csdn.net/weixin_42259631/article/details/82893426在终端输入:sudo vim /etc/resolv.conf在最后一行增加nameserver 8.8.8.8或者nameserver 114.114.114.114即可。..._git pull unable to access
php数组转请求参数,学习猿地-php 数组如何转为url参数-程序员宅基地
文章浏览阅读176次。php数组转为url参数的实现方法:首先创建一个PHP示例文件;然后定义一个数组;最后通过“http_build_query( $array )”方法将数组转为URL参数即可。php 将数组转换网址URL参数$array =array ( 'id' =123, 'name' = 'dopost' );echo http_build_query( $array );//得到结果id=123name=..._php 数组转reqeust
Linux | nslookup详细介绍一下这指令的作用以及用法_nslookup命令的作用和使用方法-程序员宅基地
文章浏览阅读4.3k次。nslookup是一个网络工具,通常用于查询域名系统(DNS)服务器以获取主机名或IP地址相关的信息。它可以用于查找主机名的IP地址,反向查找IP地址的主机名,以及查询DNS记录的其他信息。_nslookup命令的作用和使用方法
lucene、lucene.NET详细使用与优化详解-程序员宅基地
文章浏览阅读1.1k次。2019独角兽企业重金招聘Python工程师标准>>> ..._n n ___': - _* . &; v. 7_ 'v & .