cuda编程(一)基础-程序员宅基地
- 基于c/c++的编程方法
- 支持异构编程的扩展方法
- 简单明了的apis,能够轻松的管理存储系统
cuda支持的编程语言:c/c++/python/fortran/java…
1、CUDA并行计算基础
- 异构计算
- CUDA 安装
- CUDA 程序的编写
- CUDA 程序编译
- 利用NVProf查看程序执行情况
gpu不是单独的在计算机中完成任务,而是通过协助cpu和整个系统完成计算机任务,把一部分代码和更多的计算任务放到gpu上处理,逻辑控制、变量处理以及数据预处理等等放在cpu上处理。
host 指的是cpu和内存
device 指的是gpu和显存
nvidia-smi 查看当前gpu的运行状态
2、第一个cuda程序
系统中安装了cuda但是执行nvcc找不到命令。
添加环境变量。
vim ~/.bashrc
加入环境变量
export PATH="/usr/local/cuda-10.2/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH"
source ~/.bashrc
再次执行nvcc -V结果如下。

2.1 helloword
nvcc也可以支持纯c的代码,所以先写一个helloword的代码进行,使用nvcc进行编译!
cuda程序的编译器驱动nvcc支持编译纯粹的c++代码,一个标准的CUDA程序中既有C++代码也有不属于C++的cuda代码。cuda程序的编译器驱动nvcc在编译一个cuda程序时,会将纯粹的c++代码交给c++的编译器,他自己负责编译剩下的部分(cuda)代码。
创建hell.cu文件,cuda的代码需要以cu为后缀结尾。
#include<stdio.h>
int main()
{
printf("helloword\n");
return 0;
}
~
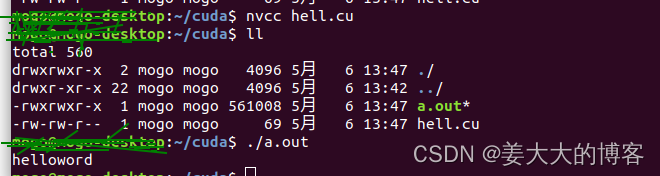
nvcc hell.cu
./a.out
运行结果如下。
2.2 核函数
cuda 中的核函数与c++中的函数是类似的,cuda的核函数必须被限定词__global__修饰,核函数的返回类型必须是空类型,即void.
#include<stdio.h>
__global__ void hello_from_gpu()
{
printf("hello word from the gpu!\n");
}
int main()
{
hello_from_gpu<<<1,1>>>();
cudaDeviceSynchronize();
printf("helloword\n");
return 0;
}
~
运行结果如下。

在核函数的调用格式上与普通C++的调用不同,调用核函数的函数名和()之间有一对三括号,里面有逗号隔开的两个数字。因为一个GPU中有很多计算核心,可以支持很多个线程。主机在调用一个核函数时,必须指明需要在设备中指派多少个线程,否则设备不知道怎么工作。三括号里面的数就是用来指明核函数中的线程数以及排列情况的。核函数中的线程常组织为若干线程块(thread block)。
三括号中的第一个数时线程块的个数,第二个数可以看作每个线程中的线程数。一个核函数的全部线程块构成一个网格,而线程块的个数记为网格大小,每个线程块中含有同样数目的线程,该数目称为线程块大小。所以核函数中的总的线程就等与网格大小乘以线程块大小,即<<<网格大小,线程块大小 >>>
核函数中的printf函数的使用方法和C++库中的printf函数的使用方法基本上是一样的,而在核函数中使用printf函数时也需要包含头文件<stdio.h>,核函数中不支持C++的iostream。
cudaDeviceSynchronize();这条语句调用了CUDA运行时的API函数,去掉这个函数就打印不出字符了。因为cuda调用输出函数时,输出流是先放在缓存区的,而这个缓存区不会核会自动刷新,只有程序遇到某种同步操作时缓存区才会刷新。这个函数的作用就是同步主机与设备,所以能够促进缓存区刷新。
3、cuda中的线程组织
3.1 使用多个线程的核函数
核函数中允许指派很多线程,一个GPU往往有几千个计算核心,而总的线程数必须至少等与计算核心数时才有可能充分利用GPU的全部计算资源。实际上,总的线程数大于计算核心数时才能更充分地利用GPU中的计算资源,因为这会让计算和内存访问之间及不同的计算之间合理地重叠,从而减小计算核心空闲的时间。
使用网格数为2,线程块大小为4的计算核心,所以总的线程数就是2x4=8,所以核函数的调用将指派8个线程完成。
核函数中的代码的执行方式是“单指令-多线程”,即每一个线程都执行同一指令的内容。
#include<stdio.h>
__global__ void hello_from_gpu()
{
printf("hello word from the gpu!\n");
}
int main()
{
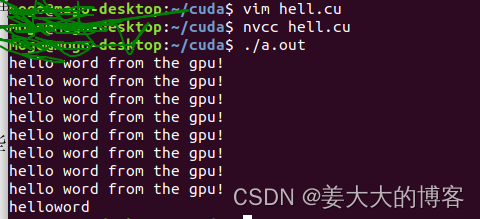
hello_from_gpu<<<2,4>>>();
cudaDeviceSynchronize();
printf("helloword\n");
return 0;
}
运行结果如下。
3.2 线程索引的使用
一个核函数可以指派多个线程,而这些线程的组织结构是由执行配置(<<<网格大小,线程块大小 >>>)来决定的,这是的网格大小和线程块大小一般来说是一个结构体类型的变量,也可以是一个普通的整形变量。
一个核函数允许指派的线程数是巨大的,能够满足几乎所有应用程序的要求。但是一个核函数中虽然可以指派如此巨大数目的线程数,但在执行时能够同时活跃(不活跃的线程处于等待状态)的线程数是由硬件(主要是CUDA核心数)和软件(核函数的函数体)决定的。
每个线程在核函数中都有一个唯一的身份标识。由于我们在三括号中使用了两个参数制定了线程的数目,所以线程的身份可以由两个参数确定。在程序内部,程序是知道执行配置参数grid_size和block_size的值的,这两个值分别保存在内建变量(built-in vari-
able)中。
gridDim.x :该变量的数值等与执行配置中变量grid_size的数值。
blockDim.x: 该变量的数值等与执行配置中变量block_size的数值。
在核函数中预定义了如下标识线程的内建变量:
blockIdx.x :该变量指定一个线程在一个网格中的线程块指标。其取值范围是从0到gridDim.x-1
threadIdx.x:该变量指定一个线程在一个线程块中的线程指标,其取值范围是从0到blockDim.x-1
代码如下。
#include<stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
printf("hello word from block %d and thread %d\n",bid,tid);
}
int main()
{
hello_from_gpu<<<2,4>>>();
cudaDeviceSynchronize();
printf("helloword\n");
return 0;
}
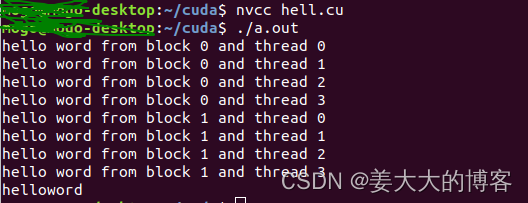
有时候线程块的顺序会发生改变,有时候是第1个先执行有时候是第0个先执行,这说明了cuda程序执行时每个线程块的计算都是相互独立的,不管完成计算的次序如何,每个线程块中间的每个线程都进行一次计算。
3.3 cuda多维网格
上述四个内建变量都使用了C++中的结构体或者类的成员变量的语法,其中blockIdx和threadIdx是类型为uint3的变量,该类型是一个结构体,具有x,y,z三个成员变量。所以blockIdx只是三个成员中的一个,threadIdx也有xyz三个成员变量。结构体uint3在头文件vector_types.h中定义有。
 同样的gridDim和blockDim是dim3类型的变量。也有xyz三个成员变量。
同样的gridDim和blockDim是dim3类型的变量。也有xyz三个成员变量。
在前面三括号内的网格大小和线程块大小都是通过一维表示,可以通过dim3定义多维网格和线程块,通过C++的构造函数的方法实现。di3 grid_size(Gx.Gy,Gz);
如果第三个维度是1,可以省去不写。
多维的网格和线程块本质上还是一维的,就像多维数组本质上也是一维数组一样。一个多维线程指标threadIdx.x、threadIdx.y、threadIdx.z对应的一维指标为。
int tid = threadIdx.z * blockDim.x * blockDim.y +threadIdx.y * blockDim.x + threadIdx.x;
也就是说,x维度是最内层的变化最快的,而z维度是最外层的变化最满的。
代码如下。
#include<stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int yid = threadIdx.y;
printf("hello word from block %d and thread (%d,%d)\n",bid,tid,yid);
}
int main()
{
const dim3 block_size(2,4);
hello_from_gpu<<<1,block_size>>>();
cudaDeviceSynchronize();
printf("helloword\n");
return 0;
}
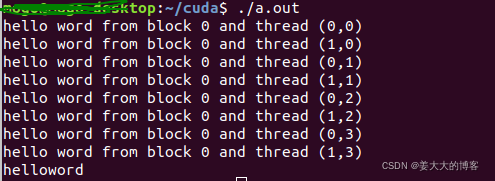
因为线程块的大小是2*4,所以在核函数中,blockDim.x的值为2,blokcDim.y值是4,threadIdx.x的取值是0到1,threadIdx.y的取值是0到3。
从结果可以看到。x维度是变量最快的是最内层的,是因为结果中,前两行的x层发生了0-1的转变,但是y层依然表示0。
3.3 网格与线程块大小的限制
cuda中对能够定义的网格大小和线程块大小做了限制,一个线程块最多只能有1024个线程。
4 cuda中的头文件
cuda有自己的头文件,但是在使用nvcc编译器驱动.cu文件时,将自动包含必要的cuda头文件,如<cuda.h>个和<cuda_runtime.h>。因为<cuda.h>包含了<stdlib.h>,所以在使用nvcc编译的cuda程序也不需要包含stdlib头文件。
5 nvcc编译cuda程序
cuda的编译器驱动nvcc会先将全部源代码分离为主机代码和设备代码。设备代码完全支持C++语法,但设备代码只部分地支持C++。nvcc先将设备代码编译为PTX伪汇编代码,再将PTX代码编译为二进制的文件cubin目标代码。在将源代码编译为PTX代码时,需要用选项-arch=compute_XY指定一个虚拟架构的计算能力,用以确定代码中共能够使用的cuda功能。在将PTX代码编译为cubin代码时,需要用选项-code=sm_ZW指定一个真实架构的计算能力,用以确定可执行文件能够使用的GPU。真实架构的计算能力必须等与或者大于虚拟架构的计算能力。
智能推荐
js-选项卡原理_选项卡js原理-程序员宅基地
文章浏览阅读90次。【代码】js-选项卡原理。_选项卡js原理
设计模式-原型模式(Prototype)-程序员宅基地
文章浏览阅读67次。原型模式是一种对象创建型模式,它采用复制原型对象的方法来创建对象的实例。它创建的实例,具有与原型一样的数据结构和值分为深度克隆和浅度克隆。浅度克隆:克隆对象的值类型(基本数据类型),克隆引用类型的地址;深度克隆:克隆对象的值类型,引用类型的对象也复制一份副本。UML图:具体代码:浅度复制:import java.util.List;/*..._prototype 设计模式
个性化政府云的探索-程序员宅基地
文章浏览阅读59次。入选国内首批云计算服务创新发展试点城市的北京、上海、深圳、杭州和无锡起到了很好的示范作用,不仅促进了当地产业的升级换代,而且为国内其他城市发展云计算产业提供了很好的借鉴。据了解,目前国内至少有20个城市确定将云计算作为重点发展的产业。这势必会形成新一轮的云计算基础设施建设的**。由于云计算基础设施建设具有投资规模大,运维成本高,投资回收周期长,地域辐射性强等诸多特点,各地在建...
STM32问题集之BOOT0和BOOT1的作用_stm32boot0和boot1作用-程序员宅基地
文章浏览阅读9.4k次,点赞2次,收藏20次。一、功能及目的 在每个STM32的芯片上都有两个管脚BOOT0和BOOT1,这两个管脚在芯片复位时的电平状态决定了芯片复位后从哪个区域开始执行程序。BOOT1=x BOOT0=0 // 从用户闪存启动,这是正常的工作模式。BOOT1=0 BOOT0=1 // 从系统存储器启动,这种模式启动的程序_stm32boot0和boot1作用
C语言函数递归调用-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏22次。C语言函数递归调用_c语言函数递归调用
明日方舟抽卡模拟器wiki_明日方舟bilibili服-明日方舟bilibili服下载-程序员宅基地
文章浏览阅读410次。明日方舟bilibili服是一款天灾驾到战斗热血的创新二次元废土风塔防手游,精妙的二次元纸片人设计,为宅友们源源不断更新超多的纸片人老婆老公们,玩家将扮演废土正义一方“罗德岛”中的指挥官,与你身边的感染者们并肩作战。与同类塔防手游与众不同的几点,首先你可以在这抽卡轻松获得稀有,同时也可以在战斗体系和敌军走位机制看到不同。明日方舟bilibili服设定:1、起因不明并四处肆虐的天灾,席卷过的土地上出..._明日方舟抽卡模拟器
随便推点
Maven上传Jar到私服报错:ReasonPhrase: Repository version policy: SNAPSHOT does not allow version: xxx_repository version policy snapshot does not all-程序员宅基地
文章浏览阅读437次。Maven上传Jar到私服报错:ReasonPhrase: Repository version policy: SNAPSHOT does not allow version: xxx_repository version policy snapshot does not all
斐波那契数列、素数、质数和猴子吃桃问题_斐波那契日-程序员宅基地
文章浏览阅读1.2k次。斐波那契数列(Fibonacci Sequence)是由如下形式的一系列数字组成的:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, …上述数字序列中反映出来的规律,就是下一个数字是该数字前面两个紧邻数字的和,具体如下所示:示例:比如上述斐波那契数列中的最后两个数,可以推导出34后面的数为21+34=55下面是一个更长一些的斐波那契数列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,_斐波那契日
PHP必会面试题_//该层循环用来控制每轮 冒出一个数 需要比较的次数-程序员宅基地
文章浏览阅读363次。PHP必会面试题1. 基础篇1. 用 PHP 打印出前一天的时间格式是 2017-12-28 22:21:21? //>>1.当前时间减去一天的时间,然后再格式化echo date('Y-m-d H:i:s',time()-3600*24);//>>2.使用strtotime,可以将任何字符串时间转换成时间戳,仅针对英文echo date('Y-m-d H:i:s',str..._//该层循环用来控制每轮 冒出一个数 需要比较的次数
windows用mingw(g++)编译opencv,opencv_contrib,并install安装_opencv mingw contrib-程序员宅基地
文章浏览阅读1.3k次,点赞26次,收藏26次。windows下用mingw编译opencv貌似不支持cuda,选cuda会报错,我无法解决,所以没选cuda,下面两种编译方式支持。打开cmake gui程序,在下面两个框中分别输入opencv的源文件和编译目录,build-mingw为你创建的目录,可自定义命名。1、如果已经安装Qt,则Qt自带mingw编译器,从Qt安装目录找到编译器所在目录即可。1、如果已经安装Qt,则Qt自带cmake,从Qt安装目录找到cmake所在目录即可。2、若未安装Qt,则安装Mingw即可,参考我的另外一篇文章。_opencv mingw contrib
5个高质量简历模板网站,免费、免费、免费_hoso模板官网-程序员宅基地
文章浏览阅读10w+次,点赞42次,收藏309次。今天给大家推荐5个好用且免费的简历模板网站,简洁美观,非常值得收藏!1、菜鸟图库https://www.sucai999.com/search/word/0_242_0.html?v=NTYxMjky网站主要以设计类素材为主,办公类素材也很多,简历模板大部个偏简约风,各种版式都有,而且经常会更新。最重要的是全部都能免费下载。2、个人简历网https://www.gerenjianli.com/moban/这是一个专门提供简历模板的网站,里面有超多模板个类,找起来非常方便,风格也很多样,无须注册就能免费下载,_hoso模板官网
通过 TikTok 联盟提高销售额的 6 个步骤_tiktok联盟-程序员宅基地
文章浏览阅读142次。你听说过吗?该计划可让您以推广您的产品并在成功销售时支付佣金。它提供了新的营销渠道,使您的产品呈现在更广泛的受众面前并提高品牌知名度。此外,TikTok Shop联盟可以是一种经济高效的产品或服务营销方式。您只需在有人购买时付费,因此不存在在无效广告上浪费金钱的风险。这些诱人的好处是否足以让您想要开始您的TikTok Shop联盟活动?如果是这样,本指南适合您。_tiktok联盟