[Android] [Android的视窗系统及显示机制][下] [底层显示子系统Surface与SurfaceFlinger]_android 修改surfaceflinger 显示的位置-程序员宅基地
技术标签: Android
前注: 原分析文章来自深入理解Android卷一
一、Surface绘制的精简流程
二、深入分析Surface与SurfaceFlinger
2.1 Surface
2.1.1 与Surface相关的基础知识介绍
- 显示层(Layer)和屏幕组成
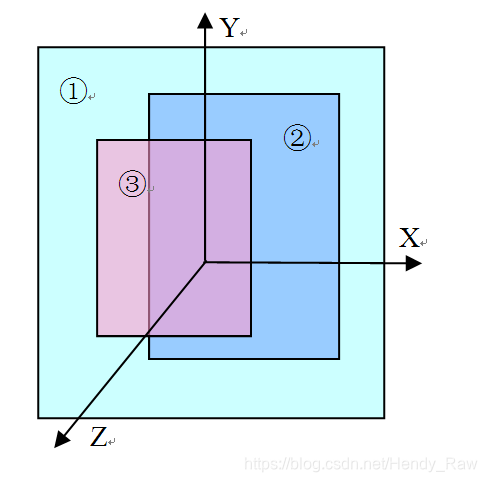
图8-10 屏幕组成示意图
从图8-10中可以看出:
· 屏幕位于一个三维坐标系中,其中Z轴从屏幕内指向屏幕外。
· 编号为①②③的矩形块叫显示层(Layer)。每一层有自己的属性,例如颜色、透明度、所处屏幕的位置、宽、高等。除了属性之外,每一层还有自己对应的显示内容,也就是需要显示的图像。
在Android中,Surface系统工作时,会由SurfaceFlinger对这些按照Z轴排好序的显示层进行图像混合,混合后的图像就是在屏幕上看到的美妙画面了。这种按Z轴排序的方式符合我们在日常生活中的体验,例如前面的物体会遮挡住后面的物体。
注意,Surface系统中定义了一个名为Layer类型的类,为了区分广义概念上的Layer和代码中的Layer,这里称广义层的Layer为显示层,以免混淆。
- FrameBuffer和PageFlipping
我们知道,在Audio系统中,音频数据传输的过程是:
· 由客户端把数据写到共享内存中。
· 然后由AudioFlinger从共享内存中取出数据再往Audio HAL中发送。
根据以上介绍可知,在音频数据传输的过程中,共享内存起到了数据承载的重要作用。 无独有偶,Surface系统中的数据传输也存在同样的过程,但承载图像数据的是鼎鼎大名的FrameBuffer(简称FB)。下面先来介绍FrameBuffer,然后再介绍Surface的数据传输过程。
(1)FrameBuffer的介绍
FrameBuffer的中文名叫帧缓冲,它实际上包括两个不同的方面:
· Frame:帧,就是指一幅图像。在屏幕上看到的那幅图像就是一帧。
· Buffer:缓冲,就是一段存储区域,可这个区域存储的是帧。
FrameBuffer的概念很清晰,它就是一个存储图形/图像帧数据的缓冲。这个缓冲来自哪里?理解这个问题,需要简单介绍一下Linux平台的虚拟显示设备FrameBuffer Device(简称FBD)。FBD是Linux系统中的一个虚拟设备,设备文件对应为/dev/fb%d(比如/dev/fb0)。这个虚拟设备将不同硬件厂商实现的真实设备统一在一个框架下,这样应用层就可以通过标准的接口进行图形/图像的输入和输出了。图8-12展示了FBD示意图:

图8-12 Linux系统中的FBD示意图
从上图中可以看出,应用层通过标准的ioctl或mmap等系统调用,就可以操作显示设备,用起来非常方便。这里,把mmap的调用列出来,相信大部分读者都知道它的作用了。
FrameBuffer中的Buffer,就是通过mmap把设备中的显存映射到用户空间的,在这块缓冲上写数据,就相当于在屏幕上绘画。
(2)PageFlipping
图形/图像数据和音频数据不太一样,我们一般把音频数据叫音频流,它是没有边界的, 而图形/图像数据是一帧一帧的,是有边界的。这一点非常类似UDP和TCP之间的区别。所以在图形/图像数据的生产/消费过程中,人们使用了一种叫PageFlipping的技术。
PageFlipping的中文名叫画面交换,其操作过程如下所示:
· 分配一个能容纳两帧数据的缓冲,前面一个缓冲叫FrontBuffer,后面一个缓冲叫BackBuffer。
· 消费者使用FrontBuffer中的旧数据,而生产者用新数据填充BackBuffer,二者互不干扰。
· 当需要更新显示时,BackBuffer变成FrontBuffer,FrontBuffer变成BackBuffer。如此循环,这样就总能显示最新的内容了。这个过程很像我们平常的翻书动作,所以它被形象地称为PageFlipping。
说白了,PageFlipping其实就是使用了一个只有两个成员的帧缓冲队列,以后在分析数据传输的时候还会见到诸如dequeue和queue的操作。
- 图像混合
我们知道,在AudioFlinger中有混音线程,它能将来自多个数据源的数据混合后输出,那么,SurfaceFlinger是不是也具有同样的功能呢?
答案是肯定的,否则它就不会叫Flinger了。Surface系统支持软硬两个层面的图像混合:
· 软件层面的混合:例如使用copyBlt进行源数据和目标数据的混合。
· 硬件层面的混合:使用Overlay系统提供的接口。
无论是硬件还是软件层面,都需将源数据和目标数据进行混合,混合需考虑很多内容,例如源的颜色和目标的颜色叠加后所产生的颜色。关于这方面的知识,读者可以学习计算机图形/图像学。这里只简单介绍一下copyBlt和Overlay。
· copyBlt,从名字上看,是数据拷贝,它也可以由硬件实现,例如现在很多的2D图形加速就是将copyBlt改由硬件来实现,以提高速度的。但不必关心这些,我们只需关心如何调用copyBlt相关的函数进行数据混合即可。
· Overlay方法必须有硬件支持才可以,它主要用于视频的输出,例如视频播放、摄像机摄像等,因为视频的内容往往变化很快,所以如改用硬件进行混合效率会更高。
2.1.2 客户端进程的Surface相关操作精简流程
这里,先总结一下前面讲解中和Surface有关的流程:
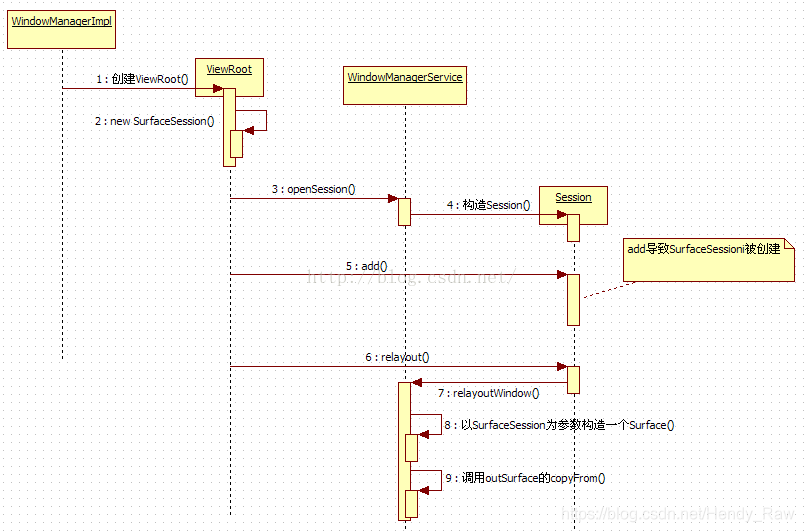
· 在ViewRoot构造时,会创建一个Surface,它使用无参构造函数,
· ViewRoot通过IWindowSession和WMS交互,而WMS中会调用的一个attach函数,会构造一个SurfaceSession,
· ViewRoot在performTransval的处理过程中会调用IWindowSession的relayout函数。从WMS获取有效显存的SurfaceControl对象,而后构造有效的Surface对象
· ViewRoot调用Surface的lockCanvas,得到一块画布。
· ViewRoot调用Surface的unlockCanvasAndPost释放这块画布。
2.1.3 Surface之乾坤大挪移
1. 乾坤大挪移的表象
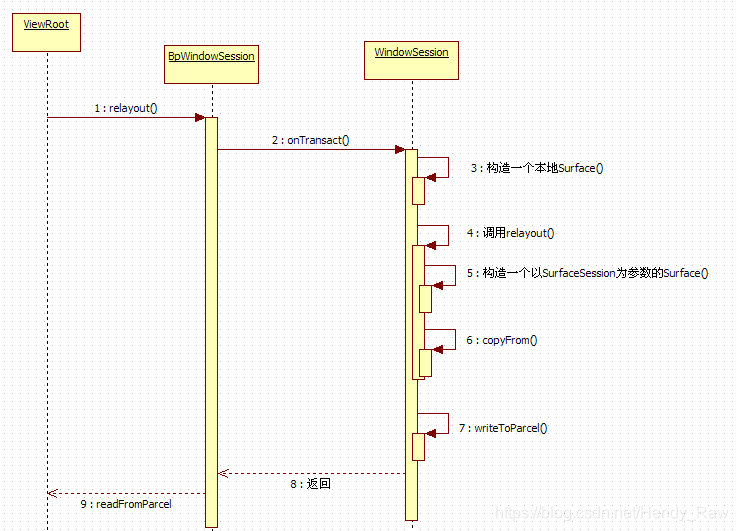
relayout的函数是一个跨进程的调用,由WMS完成实际处理。先到ViewRoot中看看调用方的用法,代码如下所示:
relayout的函数是一个跨进程的调用,由WMS完成实际处理。
先到ViewRoot中看看调用方的用法,代码如下所示:
[–>ViewRoot.java]
private int relayoutWindow(WindowManager.LayoutParams params,
int viewVisibility, boolean insetsPending)
throws RemoteException {
int relayoutResult = sWindowSession.relayout(
mWindow, params,
(int) (mView.mMeasuredWidth * appScale + 0.5f),
(int) (mView.mMeasuredHeight * appScale + 0.5f),
viewVisibility, insetsPending, mWinFrame,
mPendingContentInsets, mPendingVisibleInsets,
mPendingConfiguration, mSurface);//mSurface传了进去
......
return relayoutResult;
}
再看接收方的处理。它在WMS的Session中,代码如下所示:
[–>WindowManagerService.java::Session]
public int relayout(IWindow window,WindowManager.LayoutParams attrs,
int requestedWidth, int requestedHeight, int viewFlags,
boolean insetsPending, Rect outFrame, Rect outContentInsets,
Rect outVisibleInsets, Configuration outConfig,
Surface outSurface) {
//注意最后这个参数的名字,叫outSurface
//调用外部类对象的relayoutWindow
returnrelayoutWindow(this, window, attrs,
requestedWidth,requestedHeight, viewFlags, insetsPending,
outFrame, outContentInsets,outVisibleInsets, outConfig,
outSurface);
}
[–>WindowManagerService.java]
public int relayoutWindow(Session session,IWindow client,
WindowManager.LayoutParams attrs, int requestedWidth,
int requestedHeight, int viewVisibility, boolean insetsPending,
Rect outFrame, Rect outContentInsets, Rect outVisibleInsets,
Configuration outConfig, SurfaceoutSurface){
.....
try {
//win就是WinState,这里将创建一个本地的Surface对象
Surfacesurface = win.createSurfaceLocked();
if(surface != null) {
//先创建一个本地surface,然后在outSurface的对象上调用copyFrom
//将本地Surface的信息拷贝到outSurface中,为什么要这么麻烦呢?
outSurface.copyFrom(surface);
......
}
[–>WindowManagerService.java::WindowState]
Surface createSurfaceLocked() {
......
try {
//mSurfaceSession就是在Session上创建的SurfaceSession对象
//这里,以它为参数,构造一个新的Surface对象
mSurface = new Surface(
mSession.mSurfaceSession, mSession.mPid,
mAttrs.getTitle().toString(),
0, w, h, mAttrs.format, flags);
}
Surface.openTransaction();//打开一个事务处理
......
Surface.closeTransaction();//关闭一个事务处理。关于事务处理以后再分析
......
}
上面的代码段好像有点混乱。用图8-7来表示一下这个流程:
根据图8-7可知:
· WMS中的Surface是乾坤中的乾,它的构造使用了带SurfaceSession参数的构造函数。
· ViewRoot中的Surface是乾坤中的坤,它的构造使用了无参构造函数。
· copyFrom就是挪移,它将乾中的Surface信息,拷贝到坤中的Surface即outSurface里。
要是觉得乾坤大挪移就是这两三下,未免就太小看它了。为彻底揭示这期间的复杂过程,我们将使用必杀技——aidl工具。
2. 揭秘Surface的乾坤大挪移
aidl可以把XXX.aidl文件转换成对应的Java文件。刚才所说的乾坤大挪移发生在ViewRoot调用IWindowSession的relayout函数中,它在IWindowSession.adil中的定义如下:
[–>IWindowSesson.aidl]
interface IWindowSession {
......
intrelayout(IWindow window, in WindowManager.LayoutParams attrs,
int requestedWidth, int requestedHeight, int viewVisibility,
boolean insetsPending, out Rect outFrame, out Rect outContentInsets,
out Rect outVisibleInsets, out Configuration outConfig,
out Surface outSurface);
… 略
3. 乾坤大挪移的真相
这里,总结一下乾坤大挪移的整个过程,如图8-8表示:
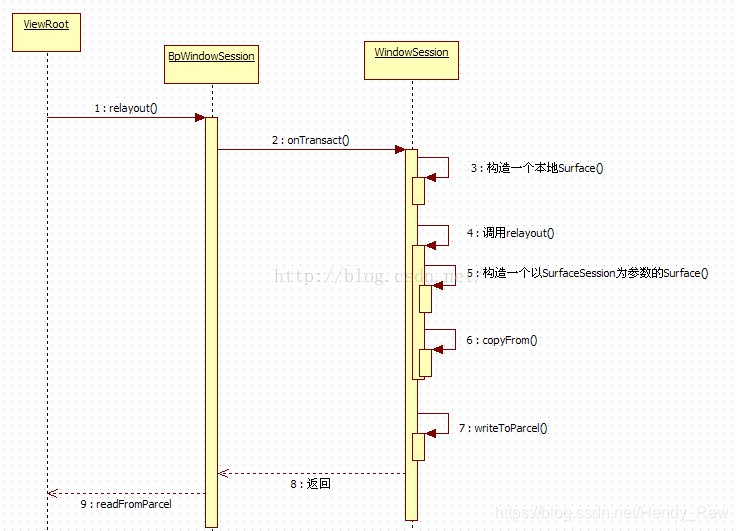
8.3.3 分析乾坤大挪移的JNI层
前文讲述的内容都集中在Java层,下面要按照流程顺序分析JNI层的内容。
- Surface的无参构造分析
在JNI层,第一个被调用的是Surface的无参构造函数,其代码如下所示:
[–>Surface.java]
public Surface() {
......
//CompatibleCanvas从Canvas类派生
mCanvas = new CompatibleCanvas();
}
- SurfaceSession的构造
现在要分析的是SurfaceSession,其构造函数如下所示:
[–>SurfaceSession.java]
public SurfaceSession() {
init();//这是一个native函数
}
init是一个native函数。去看看它的JNI实现,它在android_view_Surface.cpp中,代码如下所示:
[–>android_view_Surface.cpp]
static void SurfaceSession_init(JNIEnv* env,jobject clazz)
{
//创建一个SurfaceComposerClient对象
sp<SurfaceComposerClient> client = new SurfaceComposerClient;
client->incStrong(clazz);
//在Java对象中保存这个client对象的指针,类型为SurfaceComposerClient
env->SetIntField(clazz, sso.client, (int)client.get());
}
这里先不讨论SurfaceComposerClient的内容,拟继续把乾坤大挪移的流程走完。
3. Surface的有参构造
下一个调用的是Surface的有参构造,其参数中有一个SurfaceSession。先看Java层的代码,如下所示:
[–>Surface.java]
publicSurface(SurfaceSession s,//传入一个SurfaceSession对象
int pid, String name, int display, int w, int h, int format, int flags)
throws OutOfResourcesException {
......
mCanvas = new CompatibleCanvas();
//又一个native函数,注意传递的参数:display以后再说,w,h代表绘图区域的宽高值
init(s,pid,name,display,w,h,format,flags);
mName = name;
}
Surface的native init函数的JNI实现,也在android_view_Surface.cpp中,一起来看:
[–>android_view_Surface.cpp]
Surface的native init函数的JNI实现,也在android_view_Surface.cpp中,一起来看:
[–>android_view_Surface.cpp]
static void Surface_init(
JNIEnv*env, jobject clazz,
jobject session,
jint pid, jstring jname, jint dpy, jint w, jint h, jint format, jintflags)
{
//从SurfaceSession对象中取出之前创建的那个SurfaceComposerClient对象
SurfaceComposerClient* client =
(SurfaceComposerClient*)env->GetIntField(session, sso.client);
sp<SurfaceControl> surface;//注意它的类型是SurfaceControl
if (jname == NULL) {
/*
调用SurfaceComposerClient的createSurface函数,返回的surface是一个
SurfaceControl类型。
*/
surface = client->createSurface(pid, dpy, w, h, format, flags);
} else{
......
}
//把这个surfaceControl对象设置到Java层的Surface对象中,对这个函数就不再分析了
setSurfaceControl(env, clazz, surface);
}
- copyFrom的分析
现在要分析的就是copyFrom了。它就是一个native函数。看它的JNI层代码:
[–>android_view_Surface.cpp]
static void Surface_copyFrom(JNIEnv* env,jobject clazz, jobject other)
{
//根据JNI函数的规则,clazz是copyFrom的调用对象,而other是copyFrom的参数。
//目标对象此时还没有设置SurfaceControl,而源对象在前面已经创建了SurfaceControl
constsp<SurfaceControl>& surface = getSurfaceControl(env, clazz);
constsp<SurfaceControl>& rhs = getSurfaceControl(env, other);
if (!SurfaceControl::isSameSurface(surface, rhs)) {
//把源SurfaceControl对象设置到目标Surface中。
setSurfaceControl(env, clazz, rhs);
}
}
这一步还是比较简单的,下面看第五步writeToParcel函数的调用。
- writeToParcel的分析
多亏了必杀技aidl工具的帮忙,才挖出这个隐藏的writeToParcel函数调用,下面就来看看它,代码如下所示:
[–>android_view_Surface.cpp]
static void Surface_writeToParcel(JNIEnv* env,jobject clazz,
jobject argParcel, jint flags)
{
Parcel* parcel = (Parcel*)env->GetIntField(argParcel, no.native_parcel);
//clazz就是Surface对象,从这个Surface对象中取出保存的SurfaceControl对象
const sp<SurfaceControl>&control(getSurfaceControl(env, clazz));
/*
把SurfaceControl中的信息写到Parcel包中,然后利用Binder通信传递到对端,
对端通过readFromParcel来处理Parcel包。
*/
SurfaceControl::writeSurfaceToParcel(control, parcel);
if (flags & PARCELABLE_WRITE_RETURN_VALUE) {
//还记得PARCELABLE_WRITE_RETURN_VALUE吗?flags的值就等于它
//所以本地Surface对象的SurfaceControl值被置空了
setSurfaceControl(env, clazz, 0);
}
}
- readFromParcel的分析
再看作为客户端的ViewRoot所调用的readFromParcel函数。它也是一个native函数,JNI层的代码如下所示:
[–>android_view_Surface.cpp]
static void Surface_readFromParcel(
JNIEnv* env, jobject clazz, jobject argParcel)
{
Parcel* parcel = (Parcel*)env->GetIntField( argParcel,no.native_parcel);
//注意下面定义的变量类型是Surface,而不是SurfaceControl
const sp<Surface>&control(getSurface(env, clazz));
//根据服务端传递的Parcel包来构造一个新的surface。
sp<Surface> rhs = new Surface(*parcel);
if (!Surface::isSameSurface(control, rhs)) {
//把这个新surface赋给ViewRoot中的mSurface对象。
setSurface(env,clazz, rhs);
}
}
7. Surface乾坤大挪移的小结
可能有人会问,乾坤大挪移怎么这么复杂?这期间出现了多少对象?来总结一下,在此期间一共有三个关键对象(注意我们这里只考虑JNI层的Native对象),它们分别是:
· SurfaceComposerClient。
· SurfaceControl。
· Surface,这个Surface对象属于Native层,和Java层的Surface相对应。
其中转移到ViewRoot成员变量mSurface中的,就是最后这个Surface对象了。这一路走来,真是异常坎坷。来回顾并概括总结一下这段历程。至于它的作用应该是很清楚了。以后要破解SurfaceFlinger,靠的就是这个精简的流程。
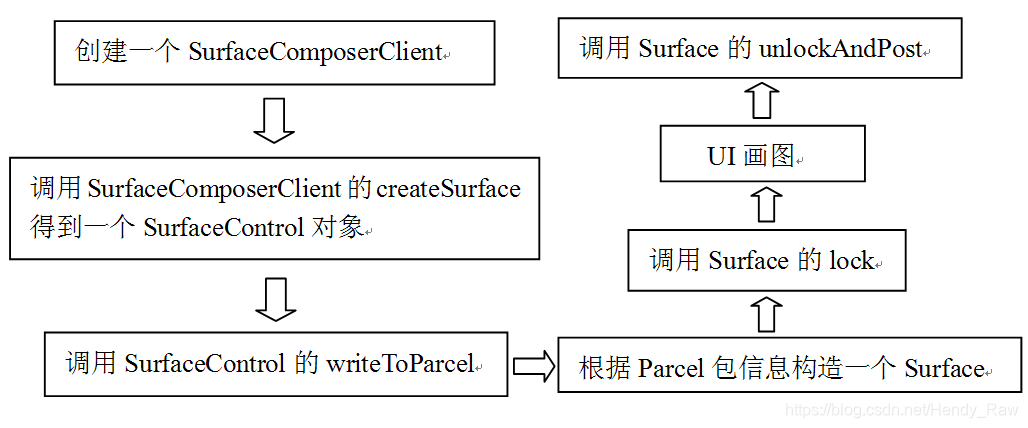
· 创建一个SurfaceComposerClient。
· 调用SurfaceComposerClient的createSurface得到一个SurfaceControl对象。
· 调用SurfaceControl的writeToParcel把一些信息写到Parcel包中。
· 根据Parcel包的信息构造一个Surface对象。这个Surface对象保存到Java层的mSurface对象中。这样,大挪移的结果是ViewRoot得到一个Native的Surface对象。
精简流程后,寥寥数语就可把过程说清楚。以后我们在研究代码时,也可以采取这种方式。
这个Surface对象非常重要,可它到底有什么用呢?这正是下一节要讲的内容。
2.1.4 Surface详细构造过程
2.1.4.1 Surface底层相关类概览
Java层只认识Surface,而实际上,底层错踪复杂
Surface包含一个SurfaceControl对象,SurfaceControl包含SurfaceComposerClient对象,这只是开始,其余的关系如下图
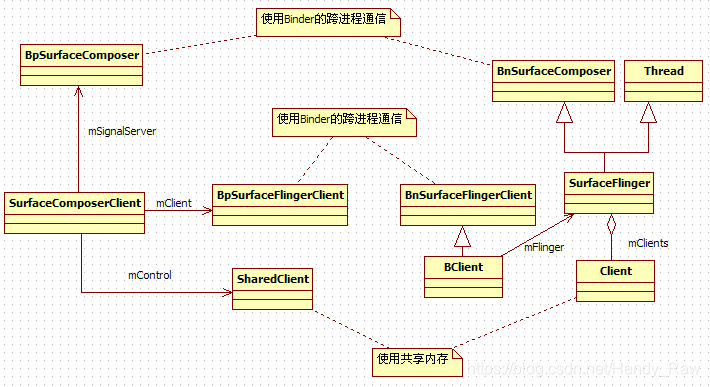
2.1.4.2 SurfaceComposerClient的分析
SurfaceComposerClient的出现是因为:
Java层SurfaceSession对象的构造函数会调用Native的SurfaceSession_init函数,而该函数的主要目的就是创建SurfaceComposerClient。
先回顾一下SurfaceSession_init函数,代码如下所示:
[–>android_view_Surface.cpp]
static void SurfaceSession_init(JNIEnv* env,jobject clazz)
{
//new 一个SurfaceComposerClient对象
sp client = newSurfaceComposerClient;
//sp的使用也有让人烦恼的地方,有时需要显式地增加强弱引用计数,要是忘记,可就麻烦了
client->incStrong(clazz);
env->SetIntField(clazz, sso.client,(int)client.get());
}
上面代码中,显式地构造了一个SurfaceComposerClient对象。接下来看它是何方神圣。
1. 创建SurfaceComposerClient
SurfaceComposerClient这个名字隐含的意思是:
这个对象会和SurfaceFlinger进行交互,因为SurfaceFlinger派生于SurfaceComposer。
通过它的构造函数来看是否是这样的。代码如下所示:
[–>SurfaceComposerClient.cpp]
SurfaceComposerClient::SurfaceComposerClient()
{
//getComposerService()将返回SF的Binder代理端的BpSurfaceFlinger对象
sp sm(getComposerService());
//先调用SF的createConnection,再调用_init
_init(sm, sm->createConnection());
if(mClient != 0) {
Mutex::Autolock _l(gLock);
//gActiveConnections是全局变量,把刚才创建的client保存到这个map中去
gActiveConnections.add(mClient->asBinder(), this);
}
}
果然如此,SurfaceComposerClient建立了和SF的交互通道,下面直接转到SF的createConnection函数去观察。
(1)createConnection的分析
直接看代码,如下所示:
[–>SurfaceFlinger.cpp]
sp<ISurfaceFlingerClient>SurfaceFlinger::createConnection()
{
Mutex::Autolock _l(mStateLock);
uint32_t token = mTokens.acquire();
//先创建一个Client。
sp<Client> client = new Client(token, this);
//把这个Client对象保存到mClientsMap中,token是它的标识。
status_t err = mClientsMap.add(token, client);
。。。
创建一个用于Binder通信的BClient,BClient派生于ISurfaceFlingerClient,
它的作用是接受客户端的请求,然后把处理提交给SF,注意,并不是提交给Client。
Client会创建一块共享内存,该内存由getControlBlockMemory函数返回
*/
sp<BClient> bclient =
new BClient(this, token,client->getControlBlockMemory());
returnbclient;
}
上面代码中提到,Client会创建一块共享内存。熟悉Audio的读者或许会认为,这可能是Surface的ControlBlock对象了!是的。CB对象在协调生产/消费步调时,起到了决定性的控制作用,所以非常重要,下面来看:
[–>SurfaceFlinger.cpp]
Client::Client(ClientID clientID, constsp<SurfaceFlinger>& flinger)
:ctrlblk(0), cid(clientID), mPid(0), mBitmap(0), mFlinger(flinger)
{
const int pgsize = getpagesize();
//下面这个操作会使cblksize为页的大小,目前是4096字节。
constint cblksize = ((sizeof(SharedClient)+(pgsize-1))&~(pgsize-1));
//MemoryHeapBase是我们的老朋友了,不熟悉的读者可以回顾Audio系统中所介绍的内容
mCblkHeap = new MemoryHeapBase(cblksize, 0,
"SurfaceFlinger Clientcontrol-block");
ctrlblk = static_cast<SharedClient *>(mCblkHeap->getBase());
if(ctrlblk) {
new(ctrlblk) SharedClient; //再一次觉得眼熟吧?使用了placement new
}
}
原来,Surface的CB对象就是在共享内存中创建的这个SharedClient对象。先来认识一下这个SharedClient。
(2)SharedClient的分析
SharedClient定义了一些成员变量,代码如下所示:
class SharedClient
{
public:
SharedClient();
~SharedClient();
status_t validate(size_t token) const;
uint32_t getIdentity(size_t token) const;//取出标识本Client的token
private:
Mutexlock;
Condition cv; //支持跨进程的同步对象
//NUM_LAYERS_MAX为31,SharedBufferStack是什么?
SharedBufferStack surfaces[ NUM_LAYERS_MAX ];
};
//SharedClient的构造函数,没什么新意,不如Audio的CB对象复杂
SharedClient::SharedClient()
:lock(Mutex::SHARED), cv(Condition::SHARED)
{
}
SharedClient的定义似乎简单到极致了,不过不要高兴得过早,在这个SharedClient的定义中,没有发现和读写控制相关的变量,那怎么控制读写呢?
**答案就在看起来很别扭的SharedBufferStack数组中,它有31个元素。**关于它的作用就不必卖关子了,答案是:
**一个Client最多支持31个显示层。每一个显示层的生产/消费步调都由会对应的SharedBufferStack来控制。**而它内部就用了几个成员变量来控制读写位置。
认识一下SharedBufferStack的这几个控制变量,如下所示:
[–>SharedBufferStack.h]
class SharedBufferStack{
......
//Buffer是按块使用的,每个Buffer都有自己的编号,其实就是数组中的索引号。
volatile int32_t head; //FrontBuffer的编号
volatile int32_t available; //空闲Buffer的个数
volatile int32_t queued; //脏Buffer的个数,脏Buffer表示有新数据的Buffer
volatile int32_t inUse; //SF当前正在使用的Buffer的编号
volatilestatus_t status; //状态码
......
}
**注意,上面定义的SharedBufferStack是一个通用的控制结构,而不仅是针对于只有两个Buffer的情况。**根据前面介绍的PageFlipping知识,如果只有两个FB,那么,SharedBufferStack的控制就比较简单了:
要么SF读1号Buffer,客户端写0号Buffer,要么SF读0号Buffer,客户端写1号Buffer。
图8-13是展示了SharedClient的示意图:
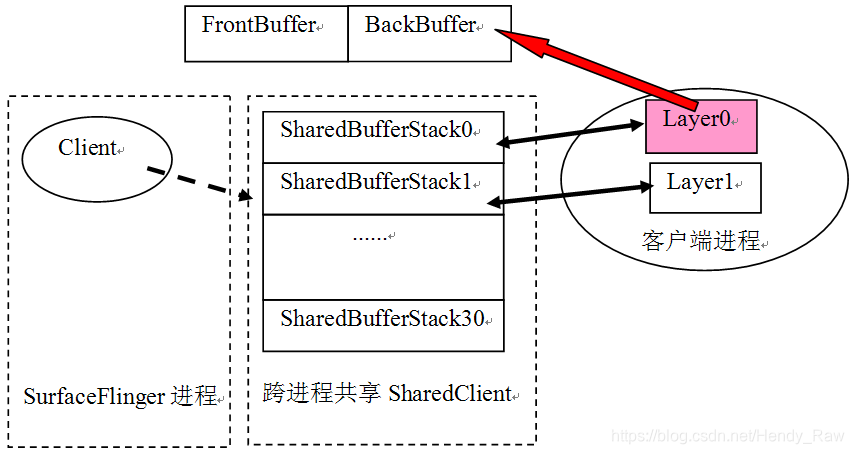
图8-13 SharedClient的示意图
从上图可知:
· SF的一个Client分配一个跨进程共享的SharedClient对象。这个对象有31个SharedBufferStack元素,每一个SharedBufferStack对应于一个显示层。
· 一个显示层将创建两个Buffer,后续的PageFlipping就是基于这两个Buffer展开的。
另外,每一个显示层中,其数据的生产和消费并不是直接使用SharedClient对象来进行具体控制的,而是基于SharedBufferServer和SharedBufferClient两个结构,由这两个结构来对该显示层使用的SharedBufferStack进行操作,这些内容在以后的分析中还会碰到。
注意,这里的显示层指的是Normal类型的显示层。
来接着分析后面的_init函数。
(3)_init函数的分析
先回顾一下之前的调用,代码如下所示:
[–>SurfaceComposerClient.cpp]
SurfaceComposerClient::SurfaceComposerClient()
{
…
_init(sm, sm->createConnection());
…
}
来看这个_init函数,代码如下所示:
[–>SurfaceComposerClient.cpp]
void SurfaceComposerClient::_init(
const sp<ISurfaceComposer>& sm, constsp<ISurfaceFlingerClient>& conn)
{
mPrebuiltLayerState = 0;
mTransactionOpen = 0;
mStatus = NO_ERROR;
mControl = 0;
**mClient = conn;//mClient就是BClient的客户端**
mControlMemory =mClient->getControlBlock();
mSignalServer = sm;// mSignalServer就是BpSurfaceFlinger
//mControl就是那个创建于共享内存之中的SharedClient
mControl = static_cast<SharedClient*>(mControlMemory->getBase());
}
_init函数的作用,就是初始化SurfaceComposerClient中的一些成员变量。最重要的是得到了三个成员:
· mSignalServer ,它其实是SurfaceFlinger在客户端的代理BpSurfaceFlinger,它的主要作用是,在客户端更新完BackBuffer后(也就是刷新了界面后),通知SF进行PageFlipping和输出等工作。
· mControl,它是跨进程共享的SharedClient,是Surface系统的ControlBlock对象。
· mClient,它是BClient在客户端的对应物。
- 到底有多少种对象?
这一节,出现了好几种类型的对象,通过图8-14来看看它们:
图8-14 类之间关系展示图
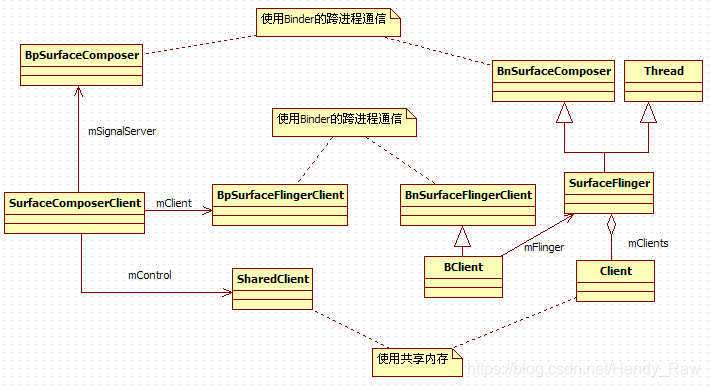
从上图中可以看出:
· SurfaceFlinger是从Thread派生的,所以它会有一个单独运行的工作线程。
· BClient和SF之间采用了Proxy模式,BClient支持Binder通信,它接收客户端的请求,并派发给SF执行。
· SharedClient构建于一块共享内存中,SurfaceComposerClient和Client对象均持有这块共享内存。
在精简流程中,关于SurfaceComposerClient就分析到这里,下面分析第二个步骤中的SurfaceControl对象。
8.4.3 SurfaceControl的分析
- SurfaceControl的来历
根据精简的流程可知,这一节要分析的是SurfaceControl对象。先回顾一下这个对象的创建过程,代码如下所示:
[–>android_view_Surface.cpp]
- SurfaceControl的来历
根据精简的流程可知,这一节要分析的是SurfaceControl对象。先回顾一下这个对象的创建过程,代码如下所示:
[–>android_view_Surface.cpp]
static void Surface_init(JNIEnv* env, jobjectclazz, jobject session,
jint pid, jstring jname, jint dpy, jint w, jint h, jint format, jintflags)
{
SurfaceComposerClient* client =
(SurfaceComposerClient*)env->GetIntField(session, sso.client);
//注意这个变量,类型是SurfaceControl,名字却叫surface,稍不留神就出错了。
sp<SurfaceControl>surface;
if (jname == NULL) {
//调用Client的createSurface函数,得到一个SurfaceControl对象。
surface= client->createSurface(pid, dpy, w, h, format, flags);
}
…
//将这个SurfaceControl对象设置到Java层的对象中保存。
setSurfaceControl(env, clazz, surface);
}
**通过上面的代码可知,SurfaceControl对象由createSurface得来,**下面看看这个函数。
此时,读者或许会被代码中随意起的变量名搞糊涂,因为我的处理方法碰到了容易混淆的地方,尽量以对象类型来表示这个对象。
(1)分析createSurface的请求端
在createSurface内部会使用Binder通信将请求发给SF,所以它分为请求和响应两端,先看请求端,代码如下所示:
[–>SurfaceComposerClient.cpp]
spSurfaceComposerClient::createSurface(
int pid,
DisplayID display,//DisplayID是什么意思?
uint32_t w,
uint32_t h,
PixelFormat format,
uint32_t flags)
{
String8 name;
constsize_t SIZE = 128;
charbuffer[SIZE];
snprintf(buffer, SIZE, “<pid_%d>”, getpid());
name.append(buffer);
//调用另外一个createSurface,多一个name参数
returnSurfaceComposerClient::createSurface(pid, name, display,
w, h, format, flags);
}
在分析另外一个createSurface之前,应先介绍一下DisplayID的含义:
typedef int32_t DisplayID;
DisplayID是一个int整型,它的意义是屏幕编号,例如**双屏手机就有内屏和外屏两块屏幕。**由于目前Android的Surface系统只支持一块屏幕,所以这个变量的取值都是0。
再分析另外一个createSurface函数,它的代码如下所示:
[–>SurfaceComposerClient.cpp]
spSurfaceComposerClient::createSurface(
int pid,const String8& name,DisplayID display,uint32_t w,
uint32_t h,PixelFormat format,uint32_t flags)
{
sp result;
if(mStatus == NO_ERROR) {
ISurfaceFlingerClient::surface_data_t data;
//调用BpSurfaceFlingerClient的createSurface函数
sp<ISurface> surface = mClient->createSurface(&data, pid,name,
display, w, h,format, flags);
if(surface != 0) {
if (uint32_t(data.token) < NUM_LAYERS_MAX) {
//以返回的ISurface对象创建一个SurfaceControl对象
result = new SurfaceControl(this, surface, data, w, h,
format, flags);
}
}
}
returnresult;//返回的是SurfaceControl对象
}
请求端的处理比较简单:
· 调用跨进程的createSurface函数,得到一个ISurface对象,根据Binder一章的知识可知,这个对象的真实类型是BpSurface。不过以后统称之为ISurface。
· 以这个ISurface对象为参数,构造一个SurfaceControl对象。
createSurface函数的响应端在SurfaceFlinger进程中,下面去看这个函数。
在Surface系统定义了很多类型,咱们也中途休息一下,不妨来看看和字符串“Surface”有关的有多少个类,权当其为小小的娱乐:
Native层有Surface、ISurface、SurfaceControl、SurfaceComposerClient。
Java层有Surface、SurfaceSession。
上面列出的还只是一部分,后面还有呢!&@&%¥*
(2)分析createSurface的响应端
前面讲过,可把BClient看作是SF的Proxy,它会把来自客户端的请求派发给SF处理,通过代码来看看,是不是这样的?如下所示:
[–>SurfaceFlinger.cpp]
sp BClient::createSurface(
ISurfaceFlingerClient::surface_data_t* params, int pid,
const String8& name,
DisplayID display, uint32_t w, uint32_t h, PixelFormat format,
uint32_t flags)
{
//果然是交给SF处理,以后我们将跳过BClient这个代理。
return mFlinger->createSurface(mId, pid,name, params, display, w, h,
format, flags);
}
来看createSurface函数,它的目的就是创建一个ISurface对象,不过这中间的玄机还挺多,代码如下所示:
[–>SurfaceFlinger.cpp]
spSurfaceFlinger::createSurface(ClientID clientId, int pid,
const String8& name, ISurfaceFlingerClient::surface_data_t* params,
DisplayID d, uint32_t w, uint32_t h, PixelFormat format,
uint32_t flags)
{
sp layer;//LayerBaseClient是Layer家族的基类
//这里又冒出一个LayerBaseClient的内部类,它也叫Surface,是不是有点头晕了?
spLayerBaseClient::Surface surfaceHandle;
Mutex::Autolock _l(mStateLock);
//根据clientId找到createConnection时加入的那个Client对象
sp client = mClientsMap.valueFor(clientId);
......
//注意这个id,它的值表示Client创建的是第几个显示层,根据图8-14可以看出,这个id
//同时也表示将使用SharedBufferStatck数组的第id个元素。
int32_t id = client->generateId(pid);
//一个Client不能创建多于NUM_LAYERS_MAX个的Layer。
if(uint32_t(id) >= NUM_LAYERS_MAX) {
return surfaceHandle;
}
//根据flags参数来创建不同类型的显示层,我们在8.4.1节介绍过相关知识
switch(flags & eFXSurfaceMask) {
case eFXSurfaceNormal:
if (UNLIKELY(flags & ePushBuffers)) {
//创建PushBuffer类型的显示层,我们将在拓展思考部分分析它
layer = createPushBuffersSurfaceLocked(client, d, id,
w, h, flags);
} else {
//①创建Normal类型的显示层,我们分析待会这个
layer = createNormalSurfaceLocked(client, d, id,
w, h, flags, format);
}
break;
case eFXSurfaceBlur:
//创建Blur类型的显示层
layer = createBlurSurfaceLocked(client, d, id, w, h, flags);
break;
case eFXSurfaceDim:
//创建Dim类型的显示层
layer = createDimSurfaceLocked(client, d, id, w, h, flags);
break;
}
if(layer != 0) {
layer->setName(name);
setTransactionFlags(eTransactionNeeded);
//从显示层对象中取出一个ISurface对象赋值给SurfaceHandle
surfaceHandle = layer->getSurface();
if(surfaceHandle != 0) {
params->token = surfaceHandle->getToken();
params->identity = surfaceHandle->getIdentity();
params->width = w;
params->height = h;
params->format = format;
}
}
returnsurfaceHandle;//ISurface的Bn端就是这个对象。
}
上面代码中的函数倒是很简单,知识代码里面冒出来的几个新类型和它们的名字却让人有点头晕。先用文字总结一下:
· LayerBaseClient:前面提到的显示层在代码中的对应物,就是这个LayerBaseClient,不过这是一个大家族,不同类型的显示层将创建不同类型的LayerBaseClient。
· LayerBaseClient中有一个内部类,名字叫Surface,这是一个支持Binder通信的类,它派生于ISurface。
关于Layer的故事,后面会有单独的章节来介绍。这里先继续分析createNormalSurfaceLocked函数。它的代码如下所示:
[–>SurfaceFlinger.cpp]
spSurfaceFlinger::createNormalSurfaceLocked(
const sp<Client>& client, DisplayID display,
int32_t id, uint32_t w, uint32_t h, uint32_t flags,
PixelFormat& format)
{
switch(format) { //一些图像方面的参数设置,可以不去管它。
casePIXEL_FORMAT_TRANSPARENT:
casePIXEL_FORMAT_TRANSLUCENT:
format = PIXEL_FORMAT_RGBA_8888;
break;
casePIXEL_FORMAT_OPAQUE:
format = PIXEL_FORMAT_RGB_565;
break;
}
//①创建一个Layer类型的对象
sp layer = new Layer(this, display,client, id);
//②设置Buffer
status_t err = layer->setBuffers(w, h, format, flags);
if (LIKELY(err == NO_ERROR)) {
//初始化这个新layer的一些状态
layer->initStates(w, h, flags);
//③ 还记得在图8-10中提到的Z轴吗?下面这个函数把这个layer加入到Z轴大军中。
addLayer_l(layer);
}
…
returnlayer;
}
createNormalSurfaceLocked函数有三个关键点,它们是:
· 构造一个Layer对象。
· 调用Layer对象的setBuffers函数。
· 调用SF的addLayer_l函数。
暂且记住这三个关键点,后文有单独章节分析它们。先继续分析SurfaceControl的流程。
(3)创建SurfaceControl对象
当跨进程的createSurface调用返回一个ISurface对象时,将通过下面的代码创建一个SurfaceControl对象:
result = new SurfaceControl(this, surface, data,w, h,format, flags);
下面来看这个SurfaceControl对象为何物。它的代码如下所示:
[–>SurfaceControl.cpp]
SurfaceControl::SurfaceControl(
const sp<SurfaceComposerClient>& client,
const sp<ISurface>& surface,
const ISurfaceFlingerClient::surface_data_t& data,
uint32_t w, uint32_t h, PixelFormat format, uint32_t flags)
//mClient为SurfaceComposerClient,而mSurface指向跨进程createSurface调用
//返回的ISurface对象。
:mClient(client), mSurface(surface),
mToken(data.token), mIdentity(data.identity),
mWidth(data.width), mHeight(data.height), mFormat(data.format),
mFlags(flags)
{
}
SurfaceControl类可以看作是一个wrapper类:
它封装了一些函数,通过这些函数可以方便地调用mClient或ISurface提供的函数。
在SurfaceControl的分析过程中,还遗留了和Layer相关的部分,下面就来解决它们。
2. Layer和它的家族
**我们在createSurface中创建的是Normal的Layer,**下面先看这个Layer的构造函数。
(1)Layer的构造
Layer是从LayerBaseClient派生的,其代码如下所示:
[–>Layer.cpp]
Layer::Layer(SurfaceFlinger* flinger, DisplayIDdisplay,
const sp<Client>& c, int32_t i)//这个i表示SharedBufferStack数组的索引
: LayerBaseClient(flinger, display, c, i),//先调用基类构造函数
mSecure(false),
mNoEGLImageForSwBuffers(false),
mNeedsBlending(true),
mNeedsDithering(false)
{
//getFrontBuffer实际取出的是FrontBuffer的位置
mFrontBufferIndex = lcblk->getFrontBuffer();
}
再来看基类LayerBaseClient的构造函数,代码如下所示:
[–>LayerBaseClient.cpp]
LayerBaseClient::LayerBaseClient(SurfaceFlinger*flinger, DisplayID display,
const sp<Client>& client, int32_t i)
:LayerBase(flinger, display), lcblk(NULL), client(client), mIndex(i),
mIdentity(uint32_t(android_atomic_inc(&sIdentity)))
{
/*
创建一个SharedBufferServer对象,注意它使用了SharedClient对象,
并且传入了表示SharedBufferStack数组索引的i和一个常量NUM_BUFFERS
*/
lcblk = new SharedBufferServer(
client->ctrlblk, i, NUM_BUFFERS,//该值为常量2,在Layer.h中定义
mIdentity);
}
SharedBufferServer是什么?它和SharedClient有什么关系?
其实,之前在介绍SharedClient时曾提过与此相关的内容,这里再来认识一下,先看图8-15:
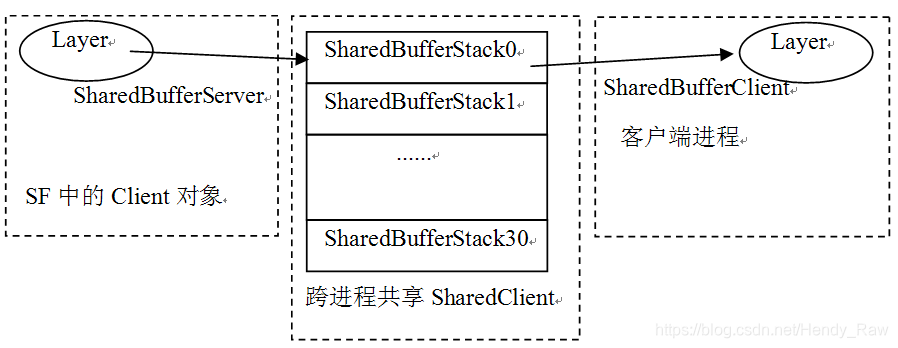
图8-15 ShardBufferServer的示意图
根据上图并结合前面的介绍,可以得出以下结论:
· 在SF进程中,Client的一个Layer将使用SharedBufferStack数组中的一个成员,并通过SharedBufferServer结构来控制这个成员,我们知道SF是消费者,所以可由SharedBufferServer来控制数据的读取。
· 与之相对应,客户端的进程也会有一个对象来使用这个SharedBufferStatck,可它是通过另外一个叫SharedBufferClient的结构来控制的。客户端为SF提供数据,所以可由SharedBufferClient控制数据的写入。在后文的分析中还会碰到SharedBufferClient。
注意,在拓展思考部分,会有单独章节来分析生产/消费过程中的读写控制。
通过前面的代码可知**,Layer对象被new出来后,传给了一个sp对象,读者还记得sp中的onFirstRef函数吗?Layer家族在这个函数中还有一些处理。一起去看看,但这个函数由基类LayerBaseClient实现。**
[–>LayerBase.cpp]
void LayerBaseClient::onFirstRef()
{
sp client(this->client.promote());
if (client != 0) {
//把自己加入client对象的mLayers数组中,这部分内容比较简单,读者可以自行研究
client->bindLayer(this, mIndex);
}
}
好,Layer创建完毕,下面来看第二个重要的函数setBuffers。
(2)setBuffers的分析
setBuffers,Layer类以及Layer的基类都有实现。由于创建的是Layer类型的对象,所以请读者直接到Layer.cpp中寻找setBuffers函数。**这个函数的目的就是创建用于PageFlipping的FrontBuffer和BackBuffer。**一起来看,代码如下所示:
[–>Layer.cpp]
status_t Layer::setBuffers( uint32_t w, uint32_th,
PixelFormat format,uint32_t flags)
{
PixelFormatInfo info;
status_t err = getPixelFormatInfo(format, &info);
if(err) return err;
//DisplayHardware是代表显示设备的HAL对象,0代表第一块屏幕的显示设备。
//这里将从HAL中取出一些和显示相关的信息。
constDisplayHardware& hw(graphicPlane(0).displayHardware());
uint32_t const maxSurfaceDims = min(
hw.getMaxTextureSize(), hw.getMaxViewportDims());
PixelFormatInfo displayInfo;
getPixelFormatInfo(hw.getFormat(),&displayInfo);
constuint32_t hwFlags = hw.getFlags();
......
/*
创建Buffer,这里将创建两个GraphicBuffer。这两个GraphicBuffer就是我们前面
所说的FrontBuffer和BackBuffer。
*/
for (size_t i=0 ; i<NUM_BUFFERS ; i++) {
//注意,这里调用的是GraphicBuffer的无参构造函数,mBuffers是一个二元数组。
mBuffers[i] = new GraphicBuffer();
}
//又冒出来一个SurfaceLayer类型,#¥%……&*!@
mSurface = new SurfaceLayer(mFlinger, clientIndex(), this);
returnNO_ERROR;
}
setBuffers函数的工作内容比较简单,就是:
· 创建一个GraphicBuffer缓冲数组,元素个数为2,即FrontBuffer和BackBuffer。
· 创建一个SurfaceLayer,关于它的身世我们后续再介绍。
GraphicBuffer是Android提供的显示内存管理类,关于它的故事,将在8.4.7节中介绍。我们暂把它当做普通的Buffer即可。
setBuffers中出现的SurfaceLayer类是什么?读者可能对此感觉有些晕乎。待把最后一个关键函数addLayer_l介绍完,或许就不太晕了。
(3)addLayer_l的分析
addLayer_l把这个新创建的layer加入自己的Z轴大军,下面来看:
[–>SurfaceFlinger.cpp]
status_t SurfaceFlinger::addLayer_l(constsp& layer)
{
/*
mCurrentState是SurfaceFlinger定义的一个结构,它有一个成员变量叫
layersSortedByZ,其实就是一个排序数组。下面这个add函数将把这个新的layer按照
它在Z轴的位置加入到排序数组中。mCurrentState保存了所有的显示层。
*/
ssize_t i = mCurrentState.layersSortedByZ.add(
layer,&LayerBase::compareCurrentStateZ);
sp lbc =
LayerBase::dynamicCast< LayerBaseClient*>(layer.get());
if(lbc != 0) {
mLayerMap.add(lbc->serverIndex(), lbc);
}
returnNO_ERROR;
}
对Layer的三个关键函数都已分析过了,下面正式介绍Layer家族。
(4)Layer家族的介绍
前面的内容确让人头晕眼花,现在应该帮大家恢复清晰的头脑。先来“一剂猛药”,见图8-16:
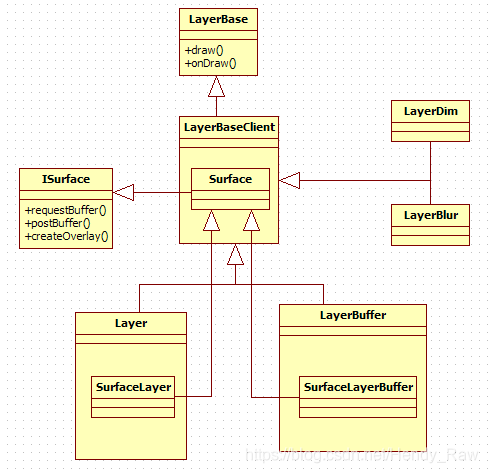
图8-16 Layer家族
通过上图可知:
· LayerBaseClient从LayerBase类派生。
· LayerBaseClient还有四个派生类,分别是Layer、LayerBuffer、LayerDim和LayerBlur。
· LayerBaseClient定义了一个内部类Surface,这个Surface从ISurface类派生,它支持Binder通信。
· 针对不同的类型,Layer和LayerBuffer分别有一个内部类SurfaceLayer和SurfaceLayerBuffer,它们继承了LayerBaseClient的Surface类。所以对于Normal类型的显示层来说,getSurface返回的ISurface对象的真正类型是SurfaceLayer。
· LayerDim和LayerBlur类没有定义自己的内部类,所以对于这两种类型的显示层来说,它们直接使用了LayerBaseClient的Surface。
· ISurface接口提供了非常简单的函数,如requestBuffer、postBuffer等。
这里大量使用了内部类。我们知道,内部类最终都会把请求派发给外部类对象来处理,既然如此,在以后分析中,如果没有特殊情况,就会直接跳到外部类的处理函数中。
强烈建议Google把Surface相关代码好好整理一下,至少让类型名取得更直观些,现在这样确实有点让人头晕。好,来小小娱乐一下。看之前介绍的和“Surface”有关的名字:
Native层有Surface、ISurface、SurfaceControl、SurfaceComposerClient。
Java层有Surface、SurfaceSession。
在介绍完Layer家族后,与它相关的名字又多了几个,它们是
LayerBaseClient::Surface、Layer::SurfaceLayer、LayerBuffer::SurfaceLayerBuffer。
3. SurfaceControl总结
SurfaceControl创建后得到了什么呢?可用图8-17来表示:
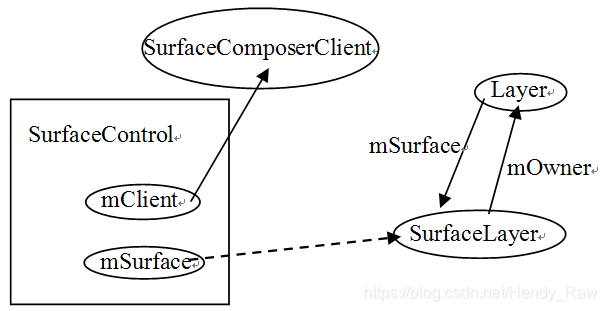
图8-17 SurfaceControl创建后的结果图
通过上图可以知道:
· mClient成员变量指向SurfaceComposerClient。
· mSurface的Binder通信响应端为SurfaceLayer。
· SurfaceLayer有一个变量mOwner指向它的外部类Layer,而Layer有一个成员变量mSurface指向SurfaceLayer。这个SurfaceLayer对象由getSurface函数返回。
注意,mOwner变量由SurfaceLayer的基类Surface(LayBaseClient的内部类)定义。
接下来就是writeToParcel分析和Native Surface对象的创建了。注意,这个Native的Surface可不是LayBaseClient的内部类Surface。
8.4.4 writeToParcel和Surface对象的创建
从乾坤大挪移的知识可知,前面创建的所有对象都在WindowManagerService所在的进程system_server中,而writeToParcel则需要把一些信息打包到Parcel后,发送到Activity所在的进程。到底哪些内容需要回传给Activity所在的进程呢?
后文将Activity所在的进程简称为Activity端。
- writeToParcel分析
writeToParcel比较简单,就是把一些信息写到Parcel中去。代码如下所示:
[–>SurfaceControl.cpp]
status_t SurfaceControl::writeSurfaceToParcel(
const sp<SurfaceControl>& control, Parcel* parcel)
{
uint32_t flags = 0;
uint32_t format = 0;
SurfaceID token = -1;
uint32_t identity = 0;
uint32_t width = 0;
uint32_t height = 0;
sp client;
sp sur;
if(SurfaceControl::isValid(control)) {
token = control->mToken;
identity= control->mIdentity;
client = control->mClient;
sur = control->mSurface;
width = control->mWidth;
height = control->mHeight;
format = control->mFormat;
flags = control->mFlags;
}
//SurfaceComposerClient的信息需要传递到Activity端,这样客户端那边会构造一个
//SurfaceComposerClient对象
parcel->writeStrongBinder(client!=0 ? client->connection() : NULL);
//把ISurface对象信息也写到Parcel中,这样Activity端那边也会构造一个ISurface对象
parcel->writeStrongBinder(sur!=0?sur->asBinder(): NULL);
parcel->writeInt32(token);
parcel->writeInt32(identity);
parcel->writeInt32(width);
parcel->writeInt32(height);
parcel->writeInt32(format);
parcel->writeInt32(flags);
returnNO_ERROR;
}
Parce包发到Activity端后,readFromParcel将根据这个Parcel包构造一个Native的Surface对象,一起来看相关代码。
2. 分析Native的Surface创建过程
[–>android_view_Surface.cpp]
static void Surface_readFromParcel(
JNIEnv* env, jobject clazz, jobject argParcel)
{
Parcel* parcel = (Parcel*)env->GetIntField( argParcel, no.native_parcel);
const sp& control(getSurface(env,clazz));
//根据服务端的parcel信息来构造客户端的Surface
sp rhs = new Surface(*parcel);
if(!Surface::isSameSurface(control, rhs)) {
setSurface(env, clazz, rhs);
}
}
Native的Surface是怎么利用这个Parcel包的?代码如下所示:
[–>Surface.cpp]
Surface::Surface(const Parcel& parcel)
:mBufferMapper(GraphicBufferMapper::get()),
mSharedBufferClient(NULL)
{
/*
Surface定义了一个mBuffers变量,它是一个sp的二元数组,也就是说Surface也存在二个GraphicBuffer,而之前在创建Layer的时候也有两个GraphicBuffer,难道一共有四个GraphicBuffer?这个问题,后面再解答。
*/
sp clientBinder =parcel.readStrongBinder();
//得到ISurface的Bp端BpSurface。
mSurface =interface_cast(parcel.readStrongBinder());
mToken = parcel.readInt32();
mIdentity = parcel.readInt32();
mWidth = parcel.readInt32();
mHeight = parcel.readInt32();
mFormat = parcel.readInt32();
mFlags = parcel.readInt32();
if (clientBinder != NULL) {
/*
根据ISurfaceFlingerClient对象构造一个SurfaceComposerClient对象,注意我们
现在位于Activity端,这里还没有创建SurfaceComposerClient对象,所以需要创建一个
*/
mClient = SurfaceComposerClient::clientForConnection(clientBinder);
//SharedBuffer家族的最后一员ShardBufferClient终于出现了。
mSharedBufferClient = new SharedBufferClient(
mClient->mControl, mToken, 2,mIdentity);
}
init();//做一些初始化工作。
}
在Surface创建完后,得到什么了呢?看图8-18就可知道:
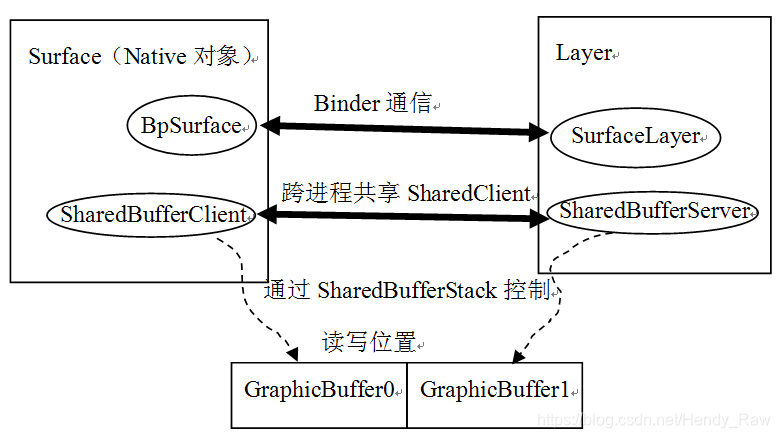
图8-18 Native Surface的示意图
上图很清晰地说明:
· ShardBuffer家族依托共享内存结构SharedClient与它共同组成了Surface系统生产/消费协调的中枢控制机构,它在SF端的代表是SharedBufferServer,在Activity端的代表是SharedBufferClient。
· Native的Surface将和SF中的SurfaceLayer建立Binder联系。
另外,图中还特意画出了承载数据的GraphicBuffer数组,在代码的注释中也针对GraphicBuffer提出了一个问题:Surface中有两个GraphicBuffer,Layer也有两个,一共就有四个GraphicBuffer了,可是为什么这里只画出两个呢?
答案是,咱们不是有共享内存吗?这四个GraphicBuffer其实操纵的是同一段共享内存,所以为了简单,就只画了两个GraphicBuffer。在8.4.7节再介绍GraphicBuffer的故事。
下面,来看中枢控制机构的SharedBuffer家族。
3. SharedBuffer家族介绍
(1)SharedBuffer家族成员
SharedBuffer是一个家族名称,它包括多少成员呢?来看SharedBuffer的家族图谱,如图8-19所示:
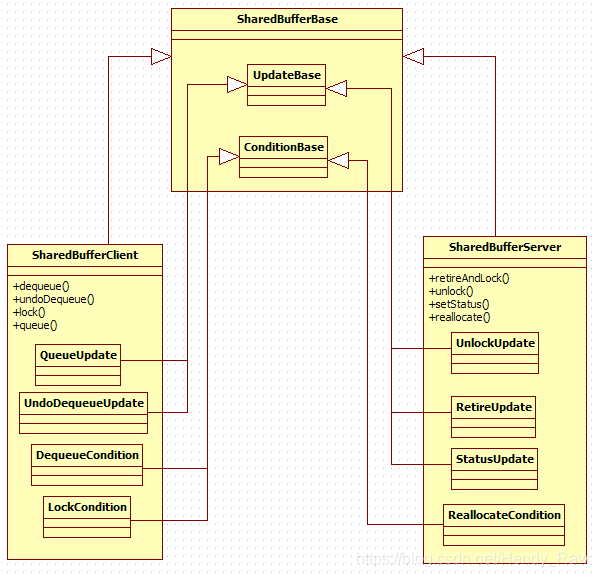
图8-19 SharedBuffer家族介绍
从上图可以知道:
· XXXCondition、XXXUpdate等都是内部类,它们主要是用来更新读写位置的。不过这些操作,为什么要通过类来封装呢?因为SharedBuffer的很多操作都使用了C++中的Function Object(函数对象),而这些内部类的实例就是函数对象。函数对象是什么?它怎么使用?对此,在以后的分析中会介绍。
(2)SharedBuffer家族和SharedClient的关系
前面介绍过,SharedBufferServer和SharedBufferClient控制的其实只是SharedBufferStack数组中的一个,下面通过SharedBufferBase的构造函数,来看是否如此。
[–>SharedBufferStack.cpp]
SharedBufferBase::SharedBufferBase(SharedClient*sharedClient,
int surface, int num, int32_t identity)
: mSharedClient(sharedClient),
mSharedStack(sharedClient->surfaces+ surface),
mNumBuffers(num), //根据前面PageFlipping的知识可知,num值为2
mIdentity(identity)
{
/*
上面的赋值语句中最重要的是第二句:
mSharedStack(sharedClient->surfaces +surface)
这条语句使得这个SharedBufferXXX对象,和SharedClient中SharedBufferStack数组
的第surface个元素建立了关系
*/
}
4. Native Surface总结
至此,Activity端Java的Surface对象**,终于和一个Native Surface对象挂上了钩,并且这个Native Surface还准备好了绘图所需的一切,其中包括:
· 两个GraphicBuffer,这就是PageFlipping所需要的FrontBuffer和BackBuffer。
· SharedBufferServer和SharedBufferClient结构,这两个结构将用于生产/消费的过程控制。
· 一个ISurface对象,这个对象连接着SF中的一个SurfaceLayer对象。
· 一个SurfaceComposerClient对象,这个对象连接着SF中的一个BClient对象。
资源都已经准备好了,可以开始绘制UI了。下面,分析两个关键的函数lockCanvas和unlockCanvasAndPost。**
8.4.5 lockCanvas和unlockCanvasAndPost的分析
这一节,分析精简流程中的最后两个函数lockCanvas和unlockCanvasAndPost。
- lockCanvas分析
据前文分析可知,UI在绘制前都需要通过lockCanvas得到一块存储空间,也就是所说的BackBuffer。这个过程中最终会调用Surface的lock函数。其代码如下所示:
[–>Surface.cpp]
status_t Surface::lock(SurfaceInfo* other,Region* dirtyIn, bool blocking)
{
//传入的参数中,other用来接收一些返回信息,dirtyIn表示需要重绘的区域
…
if (mApiLock.tryLock() != NO_ERROR) {//多线程的情况下要锁住
......
returnWOULD_BLOCK;
}
//设置usage标志,这个标志在GraphicBuffer分配缓冲时有指导作用
setUsage(GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN);
//定义一个GraphicBuffer,名字就叫backBuffer。
sp<GraphicBuffer>backBuffer;
//①还记得我们说的2个元素的缓冲队列吗?下面的dequeueBuffer将取出一个空闲缓冲
status_terr = dequeueBuffer(&backBuffer);
if (err== NO_ERROR) {
//② 锁住这块buffer
err = lockBuffer(backBuffer.get());
if(err == NO_ERROR) {
const Rect bounds(backBuffer->width, backBuffer->height);
Region scratch(bounds);
Region& newDirtyRegion(dirtyIn ? *dirtyIn : scratch);
......
//mPostedBuffer是上一次绘画时使用的Buffer,也就是现在的frontBuffer
const sp<GraphicBuffer>& frontBuffer(mPostedBuffer);
if (frontBuffer !=0 &&
backBuffer->width ==frontBuffer->width &&
backBuffer->height == frontBuffer->height &&
!(mFlags & ISurfaceComposer::eDestroyBackbuffer))
{
const Region copyback(mOldDirtyRegion.subtract(newDirtyRegion));
if (!copyback.isEmpty() && frontBuffer!=0) {
/③把frontBuffer中的数据拷贝到BackBuffer中,这是为什么?
copyBlt(backBuffer,frontBuffer, copyback);
}
}
mDirtyRegion = newDirtyRegion;
mOldDirtyRegion = newDirtyRegion;
void* vaddr;
//调用GraphicBuffer的lock得到一块内存,内存地址被赋值给了vaddr,
//后续的作画将在这块内存上展开
status_t res = backBuffer->lock(
GRALLOC_USAGE_SW_READ_OFTEN |GRALLOC_USAGE_SW_WRITE_OFTEN,
newDirtyRegion.bounds(),&vaddr);
mLockedBuffer = backBuffer;
//other用来接收一些信息。
other->w =backBuffer->width; //宽度信息
other->h =backBuffer->height;
other->s =backBuffer->stride;
other->usage =backBuffer->usage;
other->format = backBuffer->format;
other->bits = vaddr; //最重要的是这个内存地址
}
}
mApiLock.unlock();
returnerr;
}
在上面的代码中,列出了三个关键点:
· 调用dequeueBuffer得到一个空闲缓冲,也可以叫空闲缓冲出队。
· 调用lockBuffer。
· 调用copyBlt函数,把frontBuffer数据拷贝到backBuffer中,这是为什么?
来分析这三个关键点。
(1)dequeueBuffer的分析
dequeueBuffer的目的很简单,就是选取一个空闲的GraphicBuffer,其代码如下所示:
[–>Surface.cpp]
status_tSurface::dequeueBuffer(sp* buffer) {
android_native_buffer_t* out;
status_t err = dequeueBuffer(&out);//调用另外一个dequeueBuffer
if(err == NO_ERROR) {
*buffer = GraphicBuffer::getSelf(out);
}
returnerr;
}
。。。 。。。
至此,getBufferLocked的目的,已比较清晰了:
· 调用ISurface的requestBuffer得到一个GraphicBuffer对象,这个GraphicBuffer对象被设置到本地的mBuffers数组中。看来Surface定义的这两个GraphicBuffer和Layer定义的两个GraphicBuffer是有联系的,所以图8-18中只画了两个GraphicBuffer。
我们已经知道,ISurface的Bn端实际上是定义在Layer.类中的SurfaceLayer,下面来看它实现的requestBuffer。由于SurfaceLayer是Layer的内部类,它的工作最终都会交给Layer来处理,所以这里可直接看Layer的requestBuffer函数:
constuint32_t effectiveUsage = getEffectiveUsage(usage);
if(buffer!=0 && buffer->getStrongCount() == 1) {
**//①分配物理存储,后面会分析这个。
err = buffer->reallocate(w, h, mFormat, effectiveUsage);**
} else{
buffer.clear();
//使用GraphicBuffer的有参构造,这也使得物理存储被分配
buffer = new GraphicBuffer(w, h, mFormat, effectiveUsage);
err = buffer->initCheck();
}
不管怎样,此时跨进程的这个requestBuffer返回的GraphicBuffer,已经和一块物理存储绑定到一起了。所以dequeueBuffer顺利返回了它所需的东西。接下来则需调用lockBuffer。
(2)lockBuffer的分析
lockBuffer的代码如下所示:
[–>Surface.cpp]
。。。。
OK,lockCanvas返回后,应用层将在这块画布上尽情作画。假设现在已经在BackBuffer上绘制好了图像,下面就要通过unlockCanvasAndPost进行后续工作了。一起来看。
- unlockCanvasAndPost的分析
status_t Surface::unlockAndPost()
{
//调用GraphicBuffer的unlock函数
status_t err = mLockedBuffer->unlock();
//get返回这个GraphicBuffer的编号,queueBuffer将含有新数据的缓冲加入队中。
err =queueBuffer(mLockedBuffer.get());
mPostedBuffer = mLockedBuffer; //保存这个BackBuffer为mPostedBuffer
mLockedBuffer = 0;
returnerr;
}
来看queueBuffer调用,代码如下所示:
[–>Surface.cpp]
intSurface::queueBuffer(android_native_buffer_t* buffer)
{
sp client(getClient());
int32_t bufIdx =GraphicBuffer::getSelf(buffer)->getIndex();
//设置脏Region
mSharedBufferClient->setDirtyRegion(bufIdx,mDirtyRegion);
//更新写位置。
err =mSharedBufferClient->queue(bufIdx);
if (err== NO_ERROR) {
//client是BpSurfaceFlinger,调用它的signalServer,这样SF就知道新数据准备好了
client->signalServer();
}
returnerr;
}
这里,与读写控制有关的是queue函数,其代码如下所示:
[–>SharedBufferStack.cpp]
status_t SharedBufferClient::queue(int buf)
{
//QueueUpdate也是一个函数对象
QueueUpdate update(this);
//调用updateCondition函数。
status_t err = updateCondition( update );
SharedBufferStack& stack( *mSharedStack );
constnsecs_t now = systemTime(SYSTEM_TIME_THREAD);
stack.stats.totalTime = ns2us(now - mDequeueTime[buf]);
returnerr;
}
这个updateCondition函数的代码如下所示:
[–>SharedBufferStack.h]
template
status_t SharedBufferBase::updateCondition(Tupdate) {
SharedClient& client( *mSharedClient );
Mutex::Autolock _l(client.lock);
ssize_t result = update();//调用update对象的()函数
client.cv.broadcast(); //触发同步对象
returnresult;
}
updateCondition函数和前面介绍的waitForCondition函数一样,都是使用的函数对象。queue操作使用的是QueueUpdate类,关于它的故事,将在拓展部分讨论。
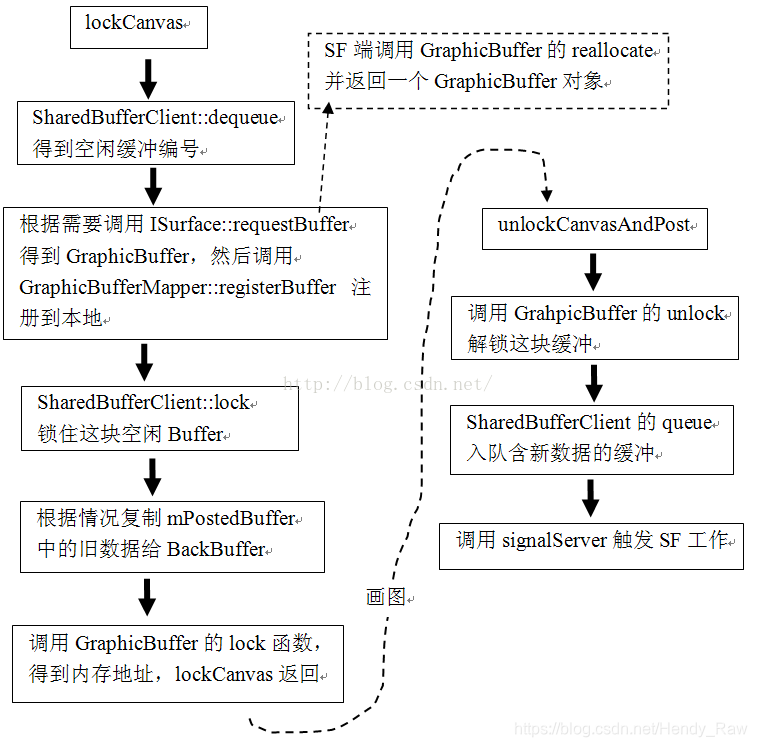
3. lockCanvas和unlockCanvasAndPost的总结
总结一下lockCanvas和unlockCanvasAndPost这两个函数的工作流程,用图8-20表示:
8.4.6 GraphicBuffer的介绍
GraphicBuffer是Surface系统中一个高层次的显示内存管理类,它封装了和硬件相关的一些细节,简化了应用层的处理逻辑。先来认识一下它。
- 初识GraphicBuffer
GraphicBuffer的代码如下所示:
[–>GraphicBuffer.h]
class GraphicBuffer
:public EGLNativeBase<android_native_buffer_t,
GraphicBuffer,LightRefBase<GraphicBuffer>>,
public Flattenable
其中,EGLNativeBase是一个模板类。它的定义,代码如下所示:
[–>Android_natives.h]
template <typename NATIVE_TYPE, typenameTYPE, typename REF>
class EGLNativeBase : public NATIVE_TYPE, publicREF
通过替换,可得到GraphicBuffer的派生关系,如图8-21所示:
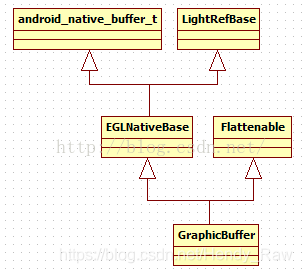
图8-21 GraphicBuffer派生关系的示意图
从图中可以看出:
· 从LightRefBase派生使GraphicBuffer支持轻量级的引用计数控制。
· 从Flattenable派生使GraphicBuffer支持序列化,它的flatten和unflatten函数用于序列化和反序列化,这样,GraphicBuffer的信息就可以存储到Parcel包中并被Binder传输了。
另外,图中的android_native_buffer_t是GraphicBuffer的父类,它是一个struct结构体。可以将C++语言中的struct和class当作同一个东西,所以GraphicBuffer能从它派生。其代码如下所示:
[–>android_native_buffer.h]
typedef struct android_native_buffer_t
{
#ifdef __cplusplus
android_native_buffer_t() {
common.magic = ANDROID_NATIVE_BUFFER_MAGIC;
common.version = sizeof(android_native_buffer_t);
memset(common.reserved, 0, sizeof(common.reserved));
}
#endif
//这个android_native_base_t是struct的第一个成员,根据C/C++编译的特性,这个成员
//在它的派生类对象所占有的内存中也是排第一个。
structandroid_native_base_t common;
intwidth;
intheight;
intstride;
intformat;
intusage;
void* reserved[2];
//这是一个关键成员,保存一些和显示内存分配/管理相关的内容
buffer_handle_t handle;
void*reserved_proc[8];
} android_native_buffer_t;
GraphicBuffer和显示内存分配相关的部分主要集中在buffer_handle_t这个变量上,它实际上是一个指针,定义如下:
[–>gralloc.h]
[–>gralloc.h]
typedef const native_handle* buffer_handle_t;
native_handle的定义如下:
[–>native_handle.h]
typedef struct
{
intversion; /* version值为sizeof(native_handle_t) */
intnumFds;
intnumInts;
intdata[0]; /* data是数据存储空间的首地址 */
} native_handle_t;
typedef native_handle_t native_handle;
读者可能要问,一个小小的GraphicBuffer为什么这么复杂?要回答这个问题,应先对GraphicBuffer有比较全面的了解。按照图8-20中的流程来看GraphicBuffer。
2. GraphicBuffer和存储的分配
GraphicBuffer的构造函数最有可能分配存储了。注意,流程中使用的是无参构造函数,所以应先看无参构造函数。
(1)无参构造函数的分析
代码如下所示:
[–>GraphicBuffer.cpp]
GraphicBuffer::GraphicBuffer()
:BASE(), mOwner(ownData), mBufferMapper(GraphicBufferMapper::get()),
mInitCheck(NO_ERROR), mVStride(0), mIndex(-1)
{
/*
其中mBufferMapper为GraphicBufferMapper类型,它的创建采用的是单例模式,也就是每个
进程只有一个GraphicBufferMapper对象,读者可以去看看get的实现。
*/
width =
height=
stride=
format=
usage = 0;
handle= NULL; //handle为空
}
在无参构造函数中没有发现和存储分配有关的操作。那么,根据流程,下一个有可能的地方就是reallocate函数了。
(2)reallocate的分析
Reallocate的代码如下所示:
[–>GraphicBuffer.cpp]
status_t GraphicBuffer::reallocate(uint32_t w,uint32_t h, PixelFormat f,
uint32_t reqUsage)
{
if(mOwner != ownData)
return INVALID_OPERATION;
if(handle) {//handle值在无参构造函数中初始化为空,所以不满足if的条件
GraphicBufferAllocator& allocator(GraphicBufferAllocator::get());
allocator.free(handle);
handle = 0;
}
returninitSize(w, h, f, reqUsage);//调用initSize函数
}
InitSize函数的代码如下所示:
[–>GraphicBuffer.cpp]
status_t GraphicBuffer::initSize(uint32_t w,uint32_t h, PixelFormat format,
uint32_t reqUsage)
{
if(format == PIXEL_FORMAT_RGBX_8888)
format = PIXEL_FORMAT_RGBA_8888;
/*
GraphicBufferAllocator才是真正的存储分配的管理类,它的创建也是采用的单例模式,
也就是每个进程只有一个GraphicBufferAllocator对象
*/
GraphicBufferAllocator& allocator =GraphicBufferAllocator::get();
//调用GraphicBufferAllocator的alloc来分配存储,注意handle作为指针
//被传了进去,看来handle的值会被修改
status_t err = allocator.alloc(w, h, format, reqUsage, &handle,&stride);
if(err == NO_ERROR) {
this->width = w;
this->height = h;
this->format = format;
this->usage = reqUsage;
mVStride = 0;
}
returnerr;
}
(3)GraphicBufferAllocator的介绍
从上面的代码中可以发现,GraphicBuffer的存储分配和GraphicBufferAllocator有关。一个小小的存储分配为什么需要经过这么多道工序呢?还是先来看GraphicBufferAllocator,代码如下所示:
[–>GraphicBufferAllocator.cpp]
GraphicBufferAllocator::GraphicBufferAllocator()
:mAllocDev(0)
{
hw_module_t const* module;
//调用hw_get_module,得到hw_module_t
interr = hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module);
if (err == 0) {
//调用gralloc_open函数,注意我们把module参数传了进去。
gralloc_open(module, &mAllocDev);
}
}
GraphicBufferAllocator在创建时,会首先调用hw_get_module取出一个hw_module_t类型的对象。从名字上看,它和硬件平台有关系。它会加载一个叫libgralloc.硬件平台名.so的动态库。比如,我的HTC G7手机上加载的库是/system/lib/hw/libgraolloc.qsd-8k.so。这个库的源代码在hardware/msm7k/libgralloc-qsd8k目录下。
这个库有什么用呢?简言之,就是为了分配一块用于显示的内存,但为什么需要这种层层封装呢?答案很简单:
封装的目的就是为了屏蔽不同硬件平台的差别。
读者可通过执行adb getprop ro.board.platform命令,得到具体手机上硬件平台的名字。图8-22总结了GraphicBufferAllocator分配内存的途径。这部分代码,读者可参考hardware/libhardware/hardware.c和hardware/msm7k/libgralloc-qsd8k/gralloc.cpp,后文将不再深入探讨和硬件平台有关的知识。
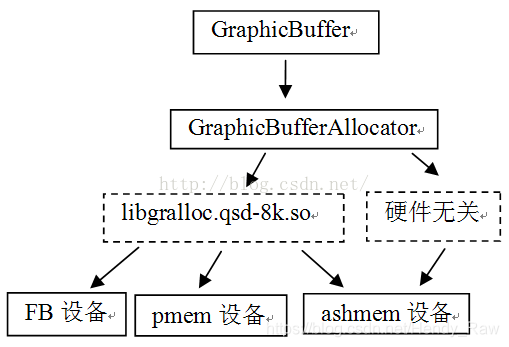
图8-22 GraphicBufferAllocator内存的分配途径
注意,这里是以G7的libgralloc.qsk-8k.so为示例的。其中pmem设备用来创建一块连续的内存,因为有些硬件设备(例如Camera)工作时需要使用一块连续的内存,对于这种情况,一般就会使用pmem设备来分配内存。
这里,仅讨论图8-22中与硬件无关的分配方式。在这种情况下,将使用ashmem分配共享内存。下面看GraphicBufferAllocator的alloc函数,其代码如下所示:
[–>GraphicBufferAllocator.cpp]
status_t GraphicBufferAllocator::alloc(uint32_tw, uint32_t h, PixelFormat format,int usage, buffer_handle_t* handle, int32_t*stride)
{
//根据前面的定义可知buffer_handle_t为native_handle_t*类型
status_t err;
if (usage & GRALLOC_USAGE_HW_MASK) {
err =mAllocDev->alloc(mAllocDev, w, h, format, usage, handle, stride);
} else {
//SW分配,可以做到和HW无关了。
err = sw_gralloc_handle_t::alloc(w, h, format, usage, handle, stride);
}
…
returnerr;
}
下面,来看软件分配的方式:
[–>GraphicBufferAllocator.cpp]
status_t sw_gralloc_handle_t::alloc(uint32_t w,uint32_t h, int format,
int usage, buffer_handle_t* pHandle, int32_t*pStride)
{
intalign = 4;
intbpp = 0;
......//格式转换
size_tbpr = (w*bpp + (align-1)) & ~(align-1);
size_tsize = bpr * h;
size_tstride = bpr / bpp;
size =(size + (PAGE_SIZE-1)) & ~(PAGE_SIZE-1);
//直接使用了ashmem创建共享内存
int fd= ashmem_create_region("sw-gralloc-buffer", size);
…
//进行内存映射,得到共享内存起始地址
void*base = mmap(0, size, prot, MAP_SHARED, fd, 0);
sw_gralloc_handle_t* hnd = new sw_gralloc_handle_t();
hnd->fd = fd;//保存文件描述符
hnd->size = size;//保存共享内存的大小
hnd->base = intptr_t(base);//intptr_t将void类型转换成int类型
hnd->prot = prot;//保存属性
*pStride = stride;
*pHandle = hnd; //pHandle就是传入的那个handle变量的指针,这里对它进行赋值
returnNO_ERROR;
}
我们知道,调用GraphicBuffer的reallocate函数后,会导致物理存储被分配。前面曾说过,Layer会创建两个GraphicBuffer,而Native Surface端也会创建两个GraphicBuffer,那么这两个GraphicBuffer是怎么建立联系的呢?为什么说native_handle_t是GraphicBuffer的精髓呢?
3. flatten和unflatten的分析
试想,Native Surface的GraphicBuffer是怎么和Layer的GraphicBuffer建立联系的:
先通过requestBuffer函数返回一个GraphicBuffer,然后这个GraphicBuffer被Native Surface保存。
这中间的过程其实是一个mini版的乾坤挪移,来看看,代码如下所示:
[–>ISurface.cpp]
//requestBuffer的响应端
status_t BnSurface::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch(code) {
case REQUEST_BUFFER: {
CHECK_INTERFACE(ISurface, data, reply);
int bufferIdx = data.readInt32();
int usage = data.readInt32();
sp<GraphicBuffer> buffer(requestBuffer(bufferIdx, usage));
......
/*
requestBuffer的返回值被写到Parcel包中,由于GraphicBuffer从
Flattenable类派生,这将导致它的flatten函数被调用
*/
return reply->write(*buffer);
}
.......
}
//再来看请求端的处理,在BpSurface中
virtual sp requestBuffer(intbufferIdx, int usage)
{
Parcel data, reply;
data.writeInterfaceToken(ISurface::getInterfaceDescriptor());
data.writeInt32(bufferIdx);
data.writeInt32(usage);
remote()->transact(REQUEST_BUFFER, data, &reply);
sp<GraphicBuffer> buffer = new GraphicBuffer();
reply.read(*buffer);//Parcel调用unflatten函数把信息反序列化到这个buffer中。
return buffer;//requestBuffer实际上返回的是本地new出来的这个GraphicBuffer
}
通过上面的代码可以发现,挪移的关键体现在flatten和unflatten函数上。请看:
(1)flatten的分析
flatten的代码如下所示:
[–>GraphicBuffer.cpp]
status_t GraphicBuffer::flatten(void* buffer,size_t size,
int fds[], size_t count) const
{
//buffer是装载数据的缓冲区,由Parcel提供
......
if(handle) {
buf[6] = handle->numFds;
buf[7] = handle->numInts;
native_handle_t const* const h = handle;
//把handle的信息也写到buffer中
memcpy(fds, h->data, h->numFds*sizeof(int));
memcpy(&buf[8], h->data + h->numFds,h->numInts*sizeof(int));
}
returnNO_ERROR;
}
flatten的工作就是把GraphicBuffer的handle变量信息写到Parcel包中。那么接收端如何使用这个包呢?这就是unflatten的工作了。
(2)unflatten分析
unflatten的代码如下所示:
[–>GraphicBuffer.cpp]
status_t GraphicBuffer::unflatten(void const*buffer, size_t size,
int fds[], size_t count)
{
......
if(numFds || numInts) {
width = buf[1];
height = buf[2];
stride = buf[3];
format = buf[4];
usage = buf[5];
native_handle* h =native_handle_create(numFds, numInts);
memcpy(h->data, fds, numFds*sizeof(int));
memcpy(h->data + numFds, &buf[8],numInts*sizeof(int));
handle = h;//根据Parcel包中的数据还原一个handle
} else{
width = height = stride = format = usage = 0;
handle = NULL;
}
mOwner= ownHandle;
returnNO_ERROR;
}
unflatten最重要的工作是,根据Parcel包中native_handle的信息,在Native Surface端构造一个对等的GraphicBuffer。这样,Native Surface端的GraphicBuffer实际上就和Layer端的GraphicBuffer管理着同一块共享内存。
- registerBuffer的分析
registerBuffer有什么用呢?上一步调用unflatten后得到了代表共享内存的文件句柄,regiserBuffer的目的就是对它进行内存映射,代码如下所示:
[–>GraphicBufferMapper.cpp]
status_tsw_gralloc_handle_t::registerBuffer(sw_gralloc_handle_t* hnd)
{
if (hnd->pid != getpid()) {
//原来是做一次内存映射操作
void* base = mmap(0, hnd->size, hnd->prot, MAP_SHARED, hnd->fd,0);
......
//base保存着共享内存的起始地址
hnd->base = intptr_t(base);
}
returnNO_ERROR;
}
- lock和unlock的分析
GraphicBuffer在使用前需要通过lock来得到内存地址,使用完后又会通过unlock释放这块地址。在SW分配方案中,这两个函数实现却非常简单,如下所示:
[–>GraphicBufferMapper.cpp]
//lock操作
int sw_gralloc_handle_t::lock(sw_gralloc_handle_t*hnd, int usage,
int l, int t, int w, int h, void** vaddr)
{
*vaddr= (void*)hnd->base;//得到共享内存的起始地址,后续作画就使用这块内存了。
returnNO_ERROR;
}
//unlock操作
status_tsw_gralloc_handle_t::unlock(sw_gralloc_handle_t* hnd)
{
returnNO_ERROR;//没有任何操作
}
对GraphicBuffer的介绍就到这里。虽然采用的是SW方式,但是相信读者也能通过树木领略到森林的风采。从应用层角度看,可以把GraphicBuffer当做一个构架在共享内存之上的数据缓冲。对想深入研究的读者,我建议可按图8-20中的流程来分析。因为流程体现了调用顺序,表达了调用者的意图和目的,只有把握了流程,分析时才不会迷失在茫茫的源码海洋中,才不会被不熟悉的知识阻拦前进的脚步。
8.4.7 深入分析Surface总结
Surface系统最难的部分,是这个Native Surface的创建和使用,它包括三个方面:
· Activity的UI和Surface的关系是怎样的?这是8.2节回答的问题。
· Activity中所使用的Surface是怎么和SurfaceFlinger挂上关系的?这是8.3节回答的问题。
· 本节对第2个问题进行了较深入的研究,分析了Surface和SurfaceFlinger之间的关系,以及生产/消费步调的中枢控制机构SharedBuffer家族和数据的承载者GraphicBuffer。
从上面分析可看出,本章前四节均围绕着这个Surface讲解,一路下来确实遇到了不少曲折和坎坷,望读者跟着源码反复阅读,体会。
2.2 SurfaceFlinger的分析
8.5 SurfaceFlinger的分析
这一节要对SurfaceFlinger进行分析。相比较而言,SurfaceFlinger不如AudioFlinger复杂。
8.5.1 SurfaceFlinger的诞生
SurfaceFlinger驻留于system_server进程,这一点和Audio系统的几个Service不太一样。它创建的位置在SystemServer的init1函数中(第4章4.3.2节的第3点)。虽然位于SystemServer这个重要进程中,但是SF创建的代码却略显波澜不惊,没有什么特别之处。SF的创建首先会调用instantiate函数,代码如下所示:
[–>SurfaceFlinger.cpp]
void SurfaceFlinger::instantiate() {
defaultServiceManager()->addService(
String16("SurfaceFlinger"), new SurfaceFlinger());
}
前面在图8-14中指出了SF,同时从BnSurfaceComposer和Thread类中派生,相关代码如下所示:
从Thread派生这件事给了我们一个很明确的提示:
· SurfaceFlinger会单独启动一个工作线程。
我们知道,Thread类的工作线程要通过调用它的run函数来创建,那这个run函数是在什么地方调用的呢?当然,最有可能的就是在构造函数中:
[–>SurfaceFlinger.cpp]
…
- onFirstRef的分析
void SurfaceFlinger::onFirstRef()
{
//真是梦里寻他千百度,果然是在onFirstRef中创建了工作线程
run(“SurfaceFlinger”,PRIORITY_URGENT_DISPLAY);
/*
mReadyToRunBarrier类型为Barrier,这个类就是封装了一个Mutex对象和一个Condition
对象。如果读者还记得第5章有关同步类的介绍,理解这个Barrier就非常简单了。下面调用的
wait函数表示要等待一个同步条件的满足。
*/
mReadyToRunBarrier.wait();
}
onFirstRef创建工作线程后,将等待一个同步条件,那么这个同步条件在哪里被触发呢?相信不用多说 大家也知道:
在工作线程中被触发,而且极有可能是在readyToRun函数中。
不清楚Thread类的读者可以复习一下与第5章有关的Thread类的知识。
- readyToRun的分析
SF的readyToRun函数将完成一些初始化工作,代码如下所示:
[–>SurfaceFlinger.cpp]
status_t SurfaceFlinger::readyToRun()
{
intdpy = 0;
{
//①GraphicPlane是什么?
GraphicPlane& plane(graphicPlane(dpy));
//②为这个GraphicPlane设置一个HAL对象——DisplayHardware
DisplayHardware* const hw = new DisplayHardware(this, dpy);
plane.setDisplayHardware(hw);
}
//创建Surface系统中的“CB”对象,按照老规矩,应该先创建一块共享内存,然后使用placment new
mServerHeap = new MemoryHeapBase(4096,
MemoryHeapBase::READ_ONLY,
"SurfaceFlingerread-only heap");
/*
注意这个“CB“对象的类型是surface_flinger_cblk_t。为什么在CB上打引号呢?因为这个对象
谈不上什么控制,只不过被用来存储一些信息罢了。其控制作用完全达不到audio_track_cblk_t
的程度。基于这样的事实,我们把前面提到的SharedBuffer家族称之为CB对象。
*/
mServerCblk=
static_cast<surface_flinger_cblk_t*>(mServerHeap->getBase());
//placementnew创建surface_flinger_cblk_t
new(mServerCblk) surface_flinger_cblk_t;
constGraphicPlane& plane(graphicPlane(dpy));
constDisplayHardware& hw = plane.displayHardware();
constuint32_t w = hw.getWidth();
constuint32_t h = hw.getHeight();
constuint32_t f = hw.getFormat();
hw.makeCurrent();
//当前只有一块屏
mServerCblk->connected|= 1<<dpy;
//屏幕在“CB”对象中的代表是display_cblk_t
display_cblk_t* dcblk = mServerCblk->displays + dpy;
memset(dcblk, 0, sizeof(display_cblk_t));
dcblk->w =plane.getWidth();
dcblk->h =plane.getHeight();
......//获取屏幕信息
//还用上了内联汇编语句。
asmvolatile ("":::"memory");
/*
下面是一些和OpenGL相关的函数调用。读者如感兴趣,可以研究一下,
至少SurfaceFlinger.cpp中所涉及的相关代码还不算难懂
*/
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, 0);
......
glOrthof(0, w, h, 0, 0, 1);
//LayerDim是Dim类型的Layer
LayerDim::initDimmer(this, w, h);
//还记得在onFirstRef函数中的wait吗?下面的open将触发这个同步条件
mReadyToRunBarrier.open();
//资源准备好后,init将启动bootanim程序,这样就见到开机动画了。
property_set("ctl.start", "bootanim");
returnNO_ERROR;
}
在上面的代码中,列出了两个关键点,下面一一进行分析。
(1)GraphicPlane的介绍
GraphicPlane是屏幕在SF代码中的对应物,根据前面的介绍,目前Android只支持一块屏幕,所以SF定义了一个一元数组:
GraphicPlane mGraphicPlanes[1];
GraphicPlane虽无什么特别之处,但它有一个重要的函数,叫setDisplayHardware,这个函数把代表显示设备的HAL对象和GraphicPlane关联起来。这也是下面要介绍的第二个关键点DisplayHardware。
(2)DisplayHardware的介绍
从代码上看,这个和显示相关的HAL对象是在工作线程中new出来的,先看它的构造函数,代码如下所示:
[–>DisplayHardware.cpp]
DisplayHardware::DisplayHardware(
const sp<SurfaceFlinger>& flinger,
uint32_t dpy)
:DisplayHardwareBase(flinger, dpy)
{
init(dpy); //最重要的是这个init函数。
}
init函数非常重要,应进去看看。下面先思考一个问题。
前面在介绍FrameBuffer时说过,显示这一块需要使用FrameBuffer,但在GraphicBuffer中用的却是ashmem创建的共享内存。也就是说,之前在共享内存中绘制的图像和FrameBuffer没有什么关系。那么FrameBuffer是在哪里创建的呢?
答案就在init函数中,代码如下所示:
[–>DisplayHardware.cpp]
void DisplayHardware::init(uint32_t dpy)
{
//FrameBufferNativeWindow实现了对FrameBuffer的管理和操作,该类中创建了两个
//FrameBuffer,分别起到FrontBuffer和BackBuffer的作用。
mNativeWindow = new FramebufferNativeWindow();
framebuffer_device_t const * fbDev = mNativeWindow->getDevice();
mOverlayEngine = NULL;
hw_module_t const* module;//Overlay相关
if(hw_get_module(OVERLAY_HARDWARE_MODULE_ID, &module) == 0) {
overlay_control_open(module, &mOverlayEngine);
}
......
EGLint w, h, dummy;
EGLintnumConfigs=0;
EGLSurface surface;
EGLContext context;
mFlags= CACHED_BUFFERS;
//EGLDisplay在EGL中代表屏幕
EGLDisplay display = eglGetDisplay(EGL_DEFAULT_DISPLAY);
......
/*
surface是EGLSurface类型,下面这个函数会将EGL和Android中的Display系统绑定起来,
后续就可以利用OpenGL在这个Surface上绘画,然后通过eglSwappBuffers输出图像了。
*/
surface= eglCreateWindowSurface(display, config,
mNativeWindow.get(),NULL);
......
mDisplay = display;
mConfig = config;
mSurface = surface;
mContext = context;
mFormat = fbDev->format;
mPageFlipCount = 0;
}
根据上面的代码,现在可以回答前面的问题了:
· SF创建FrameBuffer,并将各个Surface传输的数据(通过GraphicBuffer)混合后,再由自己传输到FrameBuffer中进行显示。
本节的内容,实际上涉及另外一个比Surface更复杂的Display系统,出于篇幅和精力的原因,本书目前不打算讨论它。
8.5.2 SF工作线程的分析
SF中的工作线程就是来做图像混合的,比起AudioFlinger来,它相当简单,下面是它的代码:
[–>SurfaceFlinger.cpp]
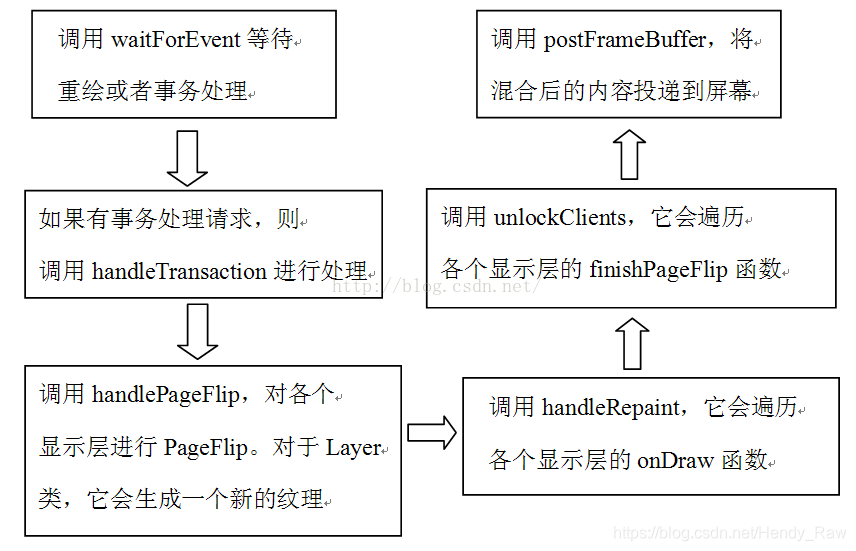
bool SurfaceFlinger::threadLoop()
{
waitForEvent();//① 等待什么事件呢?
if (UNLIKELY(mConsoleSignals)) {
handleConsoleEvents();
}
if(LIKELY(mTransactionCount == 0)) {
const uint32_t mask = eTransactionNeeded | eTraversalNeeded;
uint32_t transactionFlags = getTransactionFlags(mask);
if(LIKELY(transactionFlags)) {
//Transaction(事务)处理,放到本节最后来讨论
handleTransaction(transactionFlags);
}
}
//②处理PageFlipping工作
handlePageFlip();
constDisplayHardware& hw(graphicPlane(0).displayHardware());
if (LIKELY(hw.canDraw() && !isFrozen())) {
//③处理重绘
handleRepaint();
hw.compositionComplete();
//④投递BackBuffer
unlockClients();
postFramebuffer();
} else{
unlockClients();
usleep(16667);
}
returntrue;
}
ThreadLoop一共有四个关键点,这里,分析除Transaction外的三个关键点。
- waitForEvent
SF工作线程一上来就等待事件,它会是什么事件呢?来看代码:
[–>SurfaceFlinger.cpp]
void SurfaceFlinger::waitForEvent()
{
while(true) {
nsecs_t timeout = -1;
const nsecs_t freezeDisplayTimeout = ms2ns(5000);
......
MessageList::value_type msg = mEventQueue.waitMessage(timeout);
......//还有一些和冻屏相关的内容
if(msg != 0) {
switch (msg->what) {
//千辛万苦就等这一个重绘消息
case MessageQueue::INVALIDATE:
return;
}
}
}
}
SF收到重绘消息后,将退出等待。那么,是谁发送的这个重绘消息呢?还记得在unlockCanvasAndPost函数中调用的signal吗?它在SF端的实现代码如下:
[-->SurfaceFlinger]
void SurfaceFlinger::signal() const {
const_cast<SurfaceFlinger*>(this)->signalEvent();
}
void SurfaceFlinger::signalEvent() {
mEventQueue.invalidate(); //往消息队列中加入INVALIDATE消息
}
- 分析handlePageFlip
SF工作线程从waitForEvent中返回后,下一步要做的就是处理事务和handlePageFlip了。先看handlePageFlip,从名字上可知,它和PageFlipping工作有关。
注意:事务处理将在8.5.3节中介绍。
代码如下所示:
…
(3)handlePageFlip的总结
handlePageFlip的工作其实很简单,以Layer类型为例来总结一下:
各个Layer需要从FrontBuffer中取得新数据,并生成一张OpenGL中的纹理。纹理可以看做是一个图片,这个图片的内容就是FrontBuffer中的图像。
现在每一个Layer都准备好了新数据,下一步的工作当然就是绘制了。来看handleRepaint函数。
3. 分析handleRepaint函数
handleRepaint这个函数基本上就是按Z轴的顺序对每一层进行重绘,重绘的方法就是使用OpenGL。
嵌入式平台上用的其实是OpenGL ES。这里,还有一本书叫《OpenGL ES 2.0 Programming Guide》,它介绍了OpenGL ES的开发,读者可认真修习。
- unlockClients和postFrameBuffer的分析
在绘制完图后,还有两项工作需要做,一个涉及unlockClients函数,另外一个涉及postFrameBuffer函数,这两个函数分别干了什么呢?unlockClients的代码如下所示:
[–>SurfaceFlinger.cpp]
void SurfaceFlinger::unlockClients()
{
constLayerVector& drawingLayers(mDrawingState.layersSortedByZ);
constsize_t count = drawingLayers.size();
sp<LayerBase> const* const layers = drawingLayers.array();
for (size_t i=0 ; i<count ; ++i) {
const sp<LayerBase>& layer = layers[i];
layer->finishPageFlip();
}
}
再看Layer的finishPageFlip函数,代码如下所示:
[–>Layer.cpp]
void Layer::finishPageFlip()
{
//释放FrontBufferIndex
status_t err = lcblk->unlock( mFrontBufferIndex );
}
原来,unlockClients会释放之前占着的FrontBuffer的索引号。下面看最后一个函数postFrameBuffer,代码如下所示:
[–>SurfaceFlinger.cpp]
void SurfaceFlinger::postFramebuffer()
{
if(!mInvalidRegion.isEmpty()) {
const DisplayHardware& hw(graphicPlane(0).displayHardware());
const nsecs_t now = systemTime();
mDebugInSwapBuffers = now;
//调用这个函数后,混合后的图像就会传递到屏幕中显示了
hw.flip(mInvalidRegion);
mLastSwapBufferTime = systemTime() - now;
mDebugInSwapBuffers = 0;
mInvalidRegion.clear();
}
}
flip将调用在DisplayHardware一节中提到的eglSwapBuffer函数,来完成FrameBuffer的PageFlip操作,代码如下所示:
[–>DisplayHardware.cpp]
void DisplayHardware::flip(const Region&dirty) const
{
checkGLErrors();
EGLDisplay dpy = mDisplay;
EGLSurface surface = mSurface;
......
if(mFlags & PARTIAL_UPDATES) {
mNativeWindow->setUpdateRectangle(dirty.getBounds());
}
mPageFlipCount++;
eglSwapBuffers(dpy, surface);//PageFlipping,此后图像终于显示在屏幕上了!
}
8.5.3 Transaction的分析
Transaction是“事务”的意思。在我脑海中,关于事务的知识来自于数据库。在数据库操作中,事务意味着一次可以提交多个SQL语句,然后一个commit就可让它们集中执行,而且数据库中的事务还可以回滚,即恢复到事务提交前的状态。
SurfaceFlinger为什么需要事务呢?从上面对数据库事务的描述来看,是不是意味着一次执行多个请求呢?如直接盯着SF的源码来分析,可能不太容易搞清楚事务的前因后果,我想还是用老办法,从一个例子入手吧。
在WindowManagerService.java中,有一个函数之前分析过,现在再看看,代码如下所示:
[–>WindowManagerService.java::WinState]
Surface createSurfaceLocked() {
Surface.openTransaction(); //开始一次transaction
try {
try {
mSurfaceX = mFrame.left + mXOffset;
mSurfaceY = mFrame.top + mYOffset;
//设置Surface的位置
mSurface.setPosition(mSurfaceX, mSurfaceY);
......
}
}finally {
Surface.closeTransaction(); //关闭这次事务
}
这个例子很好地展示了事务的调用流程,它会依次调用:
· openTransaction
· setPosition
· closeTransaction
下面就来分析这几个函数的调用。
- openTransaction的分析
看JNI对应的函数,代码如下所示:
[–>android_View_Surface.cpp]
static void Surface_openTransaction(JNIEnv* env,jobject clazz)
{
//调用SurfaceComposerClient的openGlobalTransaction函数
SurfaceComposerClient::openGlobalTransaction();
}
下面转到SurfaceComposerClient,代码如下所示:
[–>SurfaceComposerClient.cpp]
voidSurfaceComposerClient::openGlobalTransaction()
{
Mutex::Autolock _l(gLock);
......
constsize_t N = gActiveConnections.size();
for(size_t i=0; i<N; i++) {
sp<SurfaceComposerClient>client(gActiveConnections.valueAt(i).promote());
//gOpenTransactions存储当前提交事务请求的Client
if(client != 0 && gOpenTransactions.indexOf(client) < 0) {
//Client是保存在全局变量gActiveConnections中的SurfaceComposerClient
//对象,调用它的openTransaction。
if (client->openTransaction() == NO_ERROR) {
if (gOpenTransactions.add(client) < 0) {
client->closeTransaction();
}
}
......
}
}
}
上面是一个静态函数,内部调用了各个SurfaceComposerClient对象的openTranscation,代码如下所示:
[–>SurfaceComposerClient.cpp]
status_tSurfaceComposerClient::openTransaction()
{
if(mStatus != NO_ERROR)
return mStatus;
Mutex::Autolock _l(mLock);
mTransactionOpen++; //一个计数值,用来控制事务的提交。
if(mPrebuiltLayerState == 0) {
mPrebuiltLayerState = new layer_state_t;
}
returnNO_ERROR;
}
layer_state_t是用来保存Surface的一些信息的,比如位置、宽、高等信息。实际上,调用的setPosition等函数,就是为了改变这个layer_state_t中的值。
- setPosition的分析
上文说过,SFC中有一个layer_state_t对象用来保存Surface的各种信息。这里以setPosition为例,来看它的使用情况。这个函数是用来改变surface在屏幕上的位置的,代码如下所示:
[–>android_View_Surface.cpp]
static void Surface_setPosition(JNIEnv* env,jobject clazz, jint x, jint y)
{
constsp<SurfaceControl>& surface(getSurfaceControl(env, clazz));
if(surface == 0) return;
status_t err = surface->setPosition(x, y);
}
[–>Surface.cpp]
status_t SurfaceControl::setPosition(int32_t x,int32_t y) {
constsp<SurfaceComposerClient>& client(mClient);
status_t err = validate();
if (err < 0) return err;
//调用SurfaceComposerClient的setPosition函数
returnclient->setPosition(mToken, x, y);
}
[–>SurfaceComposerClient.cpp]
status_tSurfaceComposerClient::setPosition(SurfaceID id, int32_t x, int32_t y)
{
layer_state_t* s = _lockLayerState(id); //找到对应的layer_state_t
if(!s) return BAD_INDEX;
s->what |= ISurfaceComposer::ePositionChanged;
s->x = x;
s->y = y; //上面几句修改了这块layer的参数
_unlockLayerState(); //该函数将unlock一个同步对象,其他没有做什么工作
returnNO_ERROR;
}
setPosition就是修改了layer_state_t中的一些参数,那么,这个状态是什么时候传递到SurfaceFlinger中的呢?
- 分析closeTransaction
相信读者此时已明白为什么叫“事务”了。原来,在openTransaction和closeTransaction中可以有很多操作,然后由closeTransaction一次性地把这些修改提交到SF上,来看代码:
[–>android_View_Surface.cpp]
static void Surface_closeTransaction(JNIEnv*env, jobject clazz)
{
SurfaceComposerClient::closeGlobalTransaction();
}
[–>SurfaceComposerClient.cpp]
voidSurfaceComposerClient::closeGlobalTransaction()
{
…
const size_t N = clients.size();
spsm(getComposerService());
//①先调用SF的openGlobalTransaction
sm->openGlobalTransaction();
for (size_t i=0; i<N; i++) {
//②然后调用每个SurfaceComposerClient对象的closeTransaction
clients[i]->closeTransaction();
}
//③最后调用SF的closeGlobalTransaction
sm->closeGlobalTransaction();
}
上面一共列出了三个函数,它们都是跨进程的调用,下面对其一一进行分析。
(1)SurfaceFlinger的openGlobalTransaction分析
这个函数其实很简单,略看就行了。
[–>SurfaceFlinger.cpp]
void SurfaceFlinger::openGlobalTransaction()
{
android_atomic_inc(&mTransactionCount);//又是一个计数控制
}
(2)SurfaceComposerClient的closeTransaction分析
代码如下所示:
[–>SurfaceComposerClient.cpp]
status_tSurfaceComposerClient::closeTransaction()
{
if(mStatus != NO_ERROR)
return mStatus;
Mutex::Autolock _l(mLock);
…
constssize_t count = mStates.size();
if (count) {
//mStates是这个SurfaceComposerClient中保存的所有layer_state_t数组,也就是
//每个Surface一个。然后调用跨进程的setState
mClient->setState(count, mStates.array());
mStates.clear();
}
returnNO_ERROR;
}
BClient的setState,最终会转到SF的setClientState上,代码如下所示:
[–>SurfaceFlinger.cpp]
status_t SurfaceFlinger::setClientState(ClientIDcid, int32_t count,
const layer_state_t*states)
{
Mutex::Autolock _l(mStateLock);
uint32_t flags = 0;
cid<<= 16;
for(int i=0 ; i<count ; i++) {
const layer_state_t& s = states[i];
sp<LayerBaseClient> layer(getLayerUser_l(s.surface | cid));
if(layer != 0) {
const uint32_t what = s.what;
if (what & ePositionChanged) {
if (layer->setPosition(s.x, s.y))
//eTraversalNeeded表示需要遍历所有显示层
flags |= eTraversalNeeded;
}
....
if(flags) {
setTransactionFlags(flags);//这里将会触发threadLoop的事件。
}
returnNO_ERROR;
}
[–>SurfaceFlinger.cpp]
uint32_tSurfaceFlinger::setTransactionFlags(uint32_t flags, nsecs_t delay)
{
uint32_t old = android_atomic_or(flags, &mTransactionFlags);
if((old & flags)==0) {
if(delay > 0) {
signalDelayedEvent(delay);
}else {
signalEvent(); //设置完mTransactionFlags后,触发事件。
}
}
returnold;
}
(3)SurfaceFlinger的closeGlobalTransaction分析
来看代码:
[–>SurfaceFlinger.cpp]
void SurfaceFlinger::closeGlobalTransaction()
{
if (android_atomic_dec(&mTransactionCount) ==1) {
//注意下面语句的执行条件,当mTransactionCount变为零时才执行,这意味着
//openGlobalTransaction两次的话,只有最后一个closeGlobalTransaction调用
//才会真正地提交事务
signalEvent();
Mutex::Autolock _l(mStateLock);
//如果这次事务涉及尺寸调整,则需要等一段时间
while (mResizeTransationPending) {
status_t err = mTransactionCV.waitRelative(mStateLock, s2ns(5));
if (CC_UNLIKELY(err != NO_ERROR)) {
mResizeTransationPending = false;
break;
}
}
}
}
关于事务的目的,相信读者已经比较清楚了:
· 就是将一些控制操作(例如setPosition)的修改结果,一次性地传递给SF进行处理。
那么,哪些操作需要通过事务来传递呢?通过查看Surface.h可以知道,下面这些操作需要通过事务来传递(这里只列出了几个经常用的函数):setPosition、setAlpha、show/hide、setSize、setFlag等。
由于这些修改不像重绘那么简单,有时它会涉及其他的显示层,例如在显示层A的位置调整后,之前被A遮住的显示层B,现在可能变得可见了。对于这种情况,所提交的事务会设置eTraversalNeeded标志,这个标志表示要遍历所有显示层进行处理。关于这一点,来看工作线程中的事务处理。
- 工作线程中的事务处理
还是从代码入手分析,如下所示:
[–>SurfaceFlinger.cpp]
bool SurfaceFlinger::threadLoop()
{
waitForEvent();
if(LIKELY(mTransactionCount == 0)) {
const uint32_t mask = eTransactionNeeded | eTraversalNeeded;
uint32_ttransactionFlags = getTransactionFlags(mask);
if(LIKELY(transactionFlags)) {
handleTransaction(transactionFlags);
}
}
…
}
getTransactionFlags函数的实现蛮有意思,不妨看看其代码,如下所示:
[–>SurfaceFlinger.cpp]
uint32_t SurfaceFlinger::getTransactionFlags(uint32_tflags)
{
//先通过原子操作去掉mTransactionFlags中对应的位。
//而后原子操作返回的旧值和flags进行与操作
return android_atomic_and(~flags,&mTransactionFlags) & flags;
}
getTransactionFlags所做的工作不仅仅是get那么简单,它还设置了mTransactionFlags,从这个角度来看,getTransactionFlags这个名字有点名不副实。
接着来看最重要的handleTransaction函数,代码如下所示:
[–>SurfaceFlinger.cpp]
void SurfaceFlinger::handleTransaction(uint32_ttransactionFlags)
{
Vector< sp > ditchedLayers;
{
Mutex::Autolock _l(mStateLock);
//调用handleTransactionLocked函数处理
handleTransactionLocked(transactionFlags, ditchedLayers);
}
constsize_t count = ditchedLayers.size();
for(size_t i=0 ; i<count ; i++) {
if(ditchedLayers[i] != 0) {
//ditch是丢弃的意思,有些显示层可能被hide了,所以这里做些收尾的工作
ditchedLayers[i]->ditch();
}
}
}
[–>SurfaceFlinger.cpp]
void SurfaceFlinger::handleTransactionLocked(
uint32_t transactionFlags, Vector< sp<LayerBase> >&ditchedLayers)
{
//这里使用了mCurrentState,它的layersSortedByZ数组存储了SF中所有的显示层
constLayerVector& currentLayers(mCurrentState.layersSortedByZ);
constsize_t count = currentLayers.size();
constbool layersNeedTransaction = transactionFlags & eTraversalNeeded;
//如果需要遍历所有显示的话。
if(layersNeedTransaction) {
for (size_t i=0 ; i<count ; i++) {
const sp<LayerBase>& layer = currentLayers[i];
uint32_t trFlags = layer->getTransactionFlags(eTransactionNeeded);
if (!trFlags) continue;
//调用各个显示层的doTransaction函数。
constuint32_t flags = layer->doTransaction(0);
if (flags & Layer::eVisibleRegion)
mVisibleRegionsDirty = true;
}
}
if(transactionFlags & eTransactionNeeded) {
if(mCurrentState.orientation != mDrawingState.orientation) {
//横竖屏如果发生切换,需要对应变换设置。
const int dpy = 0;
const int orientation = mCurrentState.orientation;
const uint32_t type = mCurrentState.orientationType;
GraphicPlane& plane(graphicPlane(dpy));
plane.setOrientation(orientation);
......
}
/*
mLayersRemoved变量在显示层被移除的时候设置,例如removeLayer函数,这些函数
也会触发handleTranscation函数的执行
*/
if(mLayersRemoved) {
mLayersRemoved = false;
mVisibleRegionsDirty = true;
const LayerVector& previousLayers(mDrawingState.layersSortedByZ);
const size_t count = previousLayers.size();
for (size_t i=0 ; i<count ; i++) {
const sp<LayerBase>& layer(previousLayers[i]);
if (currentLayers.indexOf( layer ) < 0) {
ditchedLayers.add(layer);
mDirtyRegionRemovedLayer.orSelf(layer->visibleRegionScreen);
}
}
}
free_resources_l();
}
//提交事务处理,有必要进去看看。
commitTransaction();
}
每个显示层对事务的具体处理,都在它们的doTranscation函数中,读者若有兴趣,可进去看看。需要说明的是,每个显示层内部也有一个状态变量,doTransaction会更新这些状态变量。
回到上面的函数,最后它将调用commitTransaction提交事务,代码如下所示:
[–>SurfaceFlinger.cpp]
void SurfaceFlinger::commitTransaction()
{
//mDrawingState将使用更新后的mCurrentState
mDrawingState = mCurrentState;
mResizeTransationPending = false;
//触发一个条件变量,这样等待在closeGlobalTransaction函数中的线程可以放心地返回了。
mTransactionCV.broadcast();
}
8.5.4 SurfaceFlinger的总结
通过前面的分析,使我们感受了SurfaceFlinger的风采。从整体上看,SurfaceFlinger不如AudioFlinger复杂,它的工作集中在工作线程中,下面用图8-23来总线一下SF工作线程:
8.6.2 ViewRoot的你问我答
ViewRoot是Surfac系统甚至UI系统中一个非常关键的类,下面把网上一些关于ViewRoot的问题做个总结,希望这样能帮助读者对ViewRoot有更加清楚的认识。
· ViewRoot和View类的关系是什么?
ViewRoot是View视图体系的根。每一个Window(注意是Window,比如PhoneWindow)有一个ViewRoot,它的作用是处理layout和View视图体系的绘制。那么视图体系又是什么呢?它包括Views和ViewGroups,也就是SDK中能看到的View类都属于视图体系。根据前面的分析可知,这些View是需要通过draw画出来的。而ViewRoot就是用来draw它们的,ViewRoot本身没有draw/onDraw函数。
· ViewRoot和它所控制的View及其子View使用同一个Canvas吗?
这个问题的答案就很简单了,我们在ViewRoot的performTraversals中见过。ViewRoot提供Canvas给它所控制的View,所以它们使用同一个Canvas。但Canvas使用的内存却不是固定的,而是通过Surface的lockCanvas得到的。
· View、Surface和Canvas之间的关系是怎样的?我认为,每一个view将和一个canvas,以及一个surface绑定到一起(这里的“我”表示提问人)。
这个问题的答案也很简单。一个Window将和一个Surface绑定在一起,绘制前ViewRoot会从Surface中lock出一个Canvas。
· Canvas有一个bitmap,那么绘制UI时,数据是画在Canvas的这个bitmap中吗?
答案是肯定的,bitmap实际上包括了一块内存,绘制的数据最终都在这块内存上。
· 同一个ViewRoot下,不同类型的View(不同类型指不同的UI单元,例如按钮、文本框等)使用同一个Surface吗?
是的,但是SurfaceView要除外。因为SurfaceView的绘制一般在单独的线程上,并且由应用层主动调用lockCanvas、draw和unlockCanvasAndPost来完成绘制流程。应用层相当于抛开了ViewRoot的控制,直接和屏幕打交道,这在camera、video方面用得最多。
智能推荐
vue引入原生高德地图_前端引入原生地图-程序员宅基地
文章浏览阅读556次,点赞2次,收藏3次。由于工作上的需要,今天捣鼓了半天高德地图。如果定制化开发需求不太高的话,可以用vue-amap,这个我就不多说了,详细就看官网 https://elemefe.github.io/vue-amap/#/zh-cn/introduction/install然而我们公司需要英文版的高德,我看vue-amap中好像没有这方面的配置,而且还有一些其他的定制化开发需求,然后就只用原生的高德。其实原生的引入也不复杂,但是有几个坑要填一下。1. index.html注意,引入的高德js一定要放在头部而_前端引入原生地图
ViewGroup重写大法 (一)-程序员宅基地
文章浏览阅读104次。本文介绍ViewGroup重写,我们所熟知的LinearLayout,RelativeLayout,FrameLayout等等,所有的容器类都是ViewGroup的子类,ViewGroup又继承View。我们在熟练应用这些现成的系统布局的时候可能有时候就不能满足我们自己的需求了,这是我们就要自己重写一个容器来实现效果。ViewGroup重写可以达到各种效果,下面写一个简单的重写一个Vi..._viewgroup 重写
Stm32学习笔记,3万字超详细_stm32笔记-程序员宅基地
文章浏览阅读1.8w次,点赞279次,收藏1.5k次。本文章主要记录本人在学习stm32过程中的笔记,也插入了不少的例程代码,方便到时候CV。绝大多数内容为本人手写,小部分来自stm32官方的中文参考手册以及网上其他文章;代码部分大多来自江科大和正点原子的例程,注释是我自己添加;配图来自江科大/正点原子/中文参考手册。笔记内容都是平时自己一点点添加,不知不觉都已经这么长了。其实每一个标题其实都可以发一篇,但是这样搞太琐碎了,所以还是就这样吧。_stm32笔记
CTS(13)---CTS 测试之Media相关测试failed 小结(一)_mediacodec框架 cts-程序员宅基地
文章浏览阅读1.8k次。Android o CTS 测试之Media相关测试failed 小结(一)CTSCTS 即兼容性测试套件,CTS 在桌面设备上运行,并直接在连接的设备或模拟器上执行测试用例。CTS 是一套单元测试,旨在集成到工程师构建设备的日常工作流程(例如通过连续构建系统)中。其目的是尽早发现不兼容性,并确保软件在整个开发过程中保持兼容性。CTS 是一个自动化测试工具,其中包括两个主要软件组件:CTS tra..._mediacodec框架 cts
chosen.js插件使用,回显,动态添加选项-程序员宅基地
文章浏览阅读4.5k次。官网:https://harvesthq.github.io/chosen/实例化$(".chosen-select").chosen({disable_search_threshold: 10});赋值var optValue = $(".chosen-select").val();回显1.设置回显的值$(".chosen-select").val(“opt1”);2.触发cho..._chosen.js
C++ uint8_t数据串如何按位写入_unit8_t 集合 赋值 c++-程序员宅基地
文章浏览阅读1.9k次。撸码不易,网上找不到,索性自己写,且撸且珍惜!void bitsWrite(uint8_t* buff, int pos, int size, uint32_t value){ uint32_t index[] = { 0x80000000, 0x40000000, 0x20000000, 0x10000000, 0x8000000, 0x4000000, 0x2000000, 0x1000000, 0x800000, 0x400000, 0_unit8_t 集合 赋值 c++
随便推点
Javaweb框架 思维导图_javaweb框架图-程序员宅基地
文章浏览阅读748次。javaweb知识点_javaweb框架图
adb的升级与版本更新_adb iptabls怎么升级-程序员宅基地
文章浏览阅读1.1w次,点赞3次,收藏16次。adb是没有自动升级的命令的,如果想要更新adb的版本,我们可以在网上找到自己想要的版本进行更新给大家提供几个版本https://pan.baidu.com/s/1yd0dsmWn5CK08MlyuubR7g&shfl=shareset 提取码: 94z81、下载解压后我们可以找到下面几个文件,并复制2、找到adb安装的文件夹下的platform-tools文件夹,我这里是..._adb iptabls怎么升级
微信苹果版删除所有的聊天记录的图文教程_mac微信怎么删除聊天列表-程序员宅基地
文章浏览阅读3.8k次。很多用户可能都知道怎么在Windows系统上删除微信的聊天记录,那么苹果电脑上的微信软件怎么删除所有的聊天记录呢?下面小编就专门来给大家讲下微信mac版删除所有的聊天记录的图文教程。点击后会弹出提示窗口,点击这里的确认按钮就可以将其清理掉了。在这里选择要清理的数据,然后点击下方右边的清理按钮就行了。在mac上打开微信后,点击左下角的横线图标。然后再点击这里的管理微信聊天数据按钮。打开了设置窗口,点击上方的“通用”。在这里点击下方的前往清理按钮。点击弹出菜单里的“设置”。_mac微信怎么删除聊天列表
【报错笔记】数据类型转换时报错:Request processing failed;nested exception is java.lang.NumberFormatException:..._request processing failed; nested exception is jav-程序员宅基地
文章浏览阅读7.7k次。数据类型转换时报错:Request processing failed;nested exception is java.lang.NumberFormatException:For input String “20151512345”报错原因:数字格式异常,接着后面有 For input string: “201515612343” 提示,这就告诉我们你当前想把 “201515612343” 转换成数字类型时出错了。解决方案:使用2015151612343这个数字太大了,所以直接使用string_request processing failed; nested exception is java.lang.numberformatexcepti
qml 自定义消息框_Qt qml 自定义消息提示框-程序员宅基地
文章浏览阅读387次。版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本文链接:https://blog.csdn.net/a844651990/article/details/78376767Qt qml 自定义消息提示框QtQuick有提供比较传统的信息提示框MessageDialog,但是实际开发过程并不太能满足我们的需求。下面是根据controls2模块中..._qml 自定义 messagedialog
Redis.conf 默认出厂内容_默认出厂的原始redis.conf文件全部内容-程序员宅基地
文章浏览阅读599次。# Redis configuration file example.## Note that in order to read the configuration file, Redis must be# started with the file path as first argument:## ./redis-server /path/to/redis.conf # Note on units: when memory size is needed, it is pos._默认出厂的原始redis.conf文件全部内容